Miscanthus streak virus
Basic Information
| Genus | Mastrevirus |
|---|---|
| NCBI Assembly | GCF_000839945.1 |
| Release date | 2015/2/12 |
| Submitter | Chatani,M., Matsumoto,Y., Mizuta,H., Ikegami,M., Boulton,M.I., Davies,J.W. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
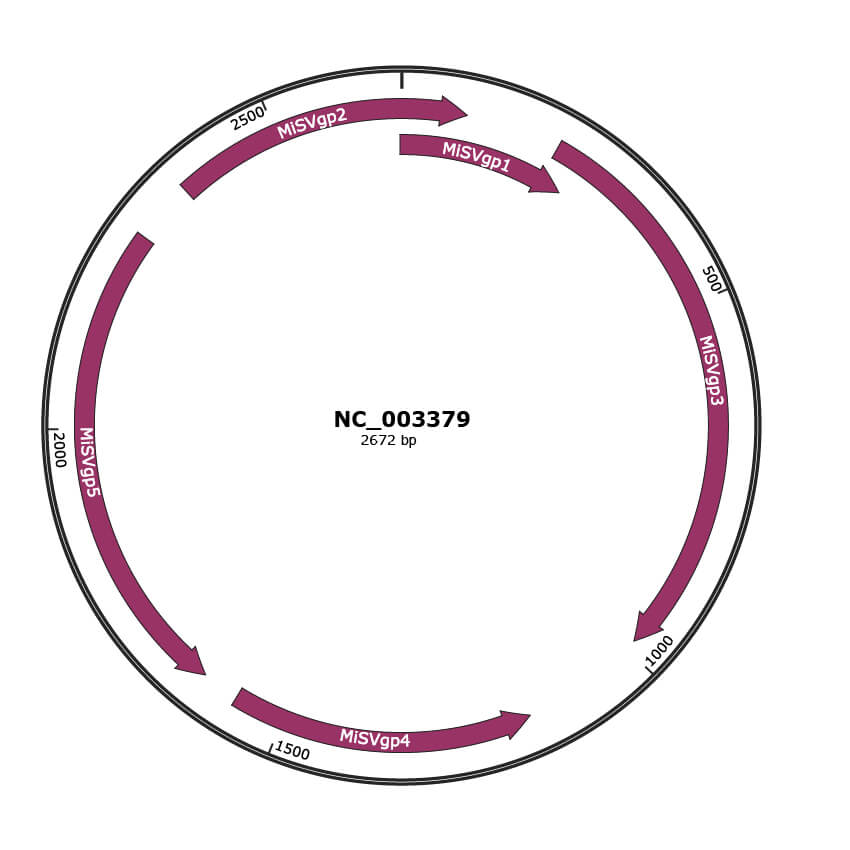
JBrowse
Genome
NC_003379
Gene Information
| NCBI Accession | NP_569143.1 |
|---|---|
| Location | join(2357-2672,1-89) |
| Protein Name | hypothetical protein |
| Coding Region | ATGGGCTGCGTATTTATAATGGGCCGGCGGGGGAGCGAAACCAATAATATTACCGCTCCCCCTCCCTGGCCCATTAGTAGGCCCCTTGCCTCGGTGCGCTGCGCCTTTGGTCCCCGTTCCTTGCCGCCTTTGGCAGAAGATCGCACTCAGGCTGCTGTAAAATGGCACCGCCATTTGAGTGTTTTTGCTTTGGTGCCTTTGGTTTGCGGCTTTAAAAAGAGGCGGAGGCTCAGAGATCGCACCAAAACCAAAGGTACGCAGGTTGCTTGTCTTCGAACTTGGGTCATTAAGTTTTGCTTCGTTTGTAAGTTTTTATGGATCCCTATGGTAGCCGTCCTAGCCATCCTGATGATGGTGCACTGCATGGTATACTTGTGGCATTTATTGCGGTGCTTTGCCTCATAG |
| Protein Sequence | MGCVFIMGRRGSETNNITAPPPWPISRPLASVRCAFGPRSLPPLAEDRTQAAVKWHRHLSVFALVPLVCGFKKRRRLRDRTKTKGTQVACLRTWVIKFCFVCKFLWIPMVAVLAILMMVHCMVYLWHLLRCFAS |
| NCBI Accession | NP_569144.1 |
|---|---|
| Location | join(2671-2672,1-253) |
| Protein Name | hypothetical protein |
| Coding Region | ATGGATCCCTATGGTAGCCGTCCTAGCCATCCTGATGATGGTGCACTGCATGGTATACTTGTGGCATTTATTGCGGTGCTTTGCCTCATAGGTTGCCTTTGGGCAGCATACCGACTGTTCCTTAAGGAGTGCCTTACTGATTGCAGTCAGCACACTTCATCAGGCGTCGTCGCGGGTCCTCGTCCGGCTGCAACAGGTCCTACTGCTGTTGTTGTACATAATGGTGCAGAAGCGCAAAGATCTTCGGCGTTCTGA |
| Protein Sequence | MDPYGSRPSHPDDGALHGILVAFIAVLCLIGCLWAAYRLFLKECLTDCSQHTSSGVVAGPRPAATGPTAVVVHNGAEAQRSSAF |
| NCBI Accession | NP_569145.1 |
|---|---|
| Location | 219-986 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGTGCAGAAGCGCAAAGATCTTCGGCGTTCTGATGCCGGTTCTGCCGTTCGGGCCAAACTGCATAAGGCCTCGACTGGGAAGGCCTTCCCTGTAGGGAAGCGGGCTCCTCTGCAGATACGGTCCTATGCATGGGAGACGCCTGCCACGGCGACCACCCCTTCCGGACCTATCAGTATTACTGACGGTACCATCTTCATGTGTAACACCATTGACCCTGGGACTGGAGACGATCAGAGATCGCGGCATACCACGATGCTCTATAAGATGTCATTGAACGTGGTGCTCTGGCCTGGTGCGACTACGGCCCAAATAGTTGGGCCTTTCCGCGTGAACTTCTGGCTTGTGTATGATGCTGCCCCGACTGGAGTTGTCCCGAAGCTGACGGACATCTTTGACGTGGCCTATCCGAAGTGGGGAAACACTTGGCAGGTTTCCCGCTCTAATGTGCATAGGTTCATAGTTAAGCGTAAATGGAAGGTGGACTACCAGTCCTCTGGCGTCCCTGTTGGCAAGAGACAGAGCAGCGGTGTTGAATACGCCCCTGTTAATAATGTGGTGGAGTGCAACAAGTTCTTCGAGAAGCTGCGTGTGAAGACCGAATGGGCGAACACCTCTACCGGTGCAATTGGGGACGTGAAGAAGGGTGCGTTGTACCTGTGTGCCAATACCCGGCAGATGCCTGCTGGTGACTCAGTCACCACGAGTTGTACCACCATGATGCAAGGGTCTACCCGATTGTACTTCAAAGTGCTGGGGAACCAGTAA |
| Protein Sequence | MVQKRKDLRRSDAGSAVRAKLHKASTGKAFPVGKRAPLQIRSYAWETPATATTPSGPISITDGTIFMCNTIDPGTGDDQRSRHTTMLYKMSLNVVLWPGATTAQIVGPFRVNFWLVYDAAPTGVVPKLTDIFDVAYPKWGNTWQVSRSNVHRFIVKRKWKVDYQSSGVPVGKRQSSGVEYAPVNNVVECNKFFEKLRVKTEWANTSTGAIGDVKKGALYLCANTRQMPAGDSVTTSCTTMMQGSTRLYFKVLGNQ |
| NCBI Accession | NP_569146.1 |
|---|---|
| Location | 1159->1568 |
| Protein Name | hypothetical protein |
| Coding Region | CAGCCTAACGGGCCGCGGAGACCACGAAGCATATACATCTGCGGCCCAAGCCGAACTGGAAAGACCACTTGGGCCAGAAACATCGGGAGGCACAACTACTACAACTCAACCGTAGACTTCACACACTATGACAAAGATGCAATCTACAACGTCATCGACGATGTGCCTTTCAAGTTCTTGCCGCAGTGGAAGGCGCTGGTGGGAGCACAGCGTGACTACATAGTGAATCCCAAGTACGGTAAGAAGAAGAAAATCCCTGGGGGAATCCCGTCCATCATTCTAACCAATGACGACGAAGACTGGATCAAGGACATGAAACCTGCACAAGTGGAGTACCTGCACGCGAACGCCCACGTACATTACATGTACGAAGGACAGAAGTTCTACGTCCTGCCGGCCGAAGAGTGA |
| Protein Sequence | QPNGPRRPRSIYICGPSRTGKTTWARNIGRHNYYNSTVDFTHYDKDAIYNVIDDVPFKFLPQWKALVGAQRDYIVNPKYGKKKKIPGGIPSIILTNDDEDWIKDMKPAQVEYLHANAHVHYMYEGQKFYVLPAEE |
| NCBI Accession | NP_569147.1 |
|---|---|
| Location | 1620-2273 |
| Protein Name | hypothetical protein |
| Coding Region | ATGAGGGCACCTGCATCATCTGCAGCATCCAACCGTCCTGGTCCTTCAAACCATCCAACACCACGTTGGAACAGCAAGCAATTCTTCCTTACCTATCCACACTGCAACCTAACACCATCCGAGCTGATGAAGGAATTGTTCTCTCGCCTGACCGAGAAAATTCCAGGATACATTAAGGTATCCCAAGAGTTCCATAAGGACGGGGACCCGCATCTCCATGTCCTTATACAGCTAAACACCAAACTATGCACAAGGAACCCCAAGTTCTTTGATGTTCAGGGTTTCCACCCAAACATTCAGCCCGTCAGAGATGCTGAAAAGGTTTTCGGATACATATCCAAAACCAACGGTGACTCTGATGAAATGGGTGAACTCCAACTCAGGATCAAGAAACCCGAGAAGCCTACCCGTGATCAAAGGATGGCTATGATAATAGCCTCCTCCACCAATAGGAATGAATACCTGTCCATGGTCCGTAAAGAATTCCCATTTGACTGGGCCATCAGACTCCAGCAGTTTGAATACAGTGCAGCAGCCTTGTTTACCGAACCACCTCCGGTATATCAGTCACCGTTCCCAAATGAGCAGATCGTCTGTCCGCCGGAGCTCGTTGACATCATAGACCAGGAATGGAACCAGGTAACTACCGATTAA |
| Protein Sequence | MRAPASSAASNRPGPSNHPTPRWNSKQFFLTYPHCNLTPSELMKELFSRLTEKIPGYIKVSQEFHKDGDPHLHVLIQLNTKLCTRNPKFFDVQGFHPNIQPVRDAEKVFGYISKTNGDSDEMGELQLRIKKPEKPTRDQRMAMIIASSTNRNEYLSMVRKEFPFDWAIRLQQFEYSAAALFTEPPPVYQSPFPNEQIVCPPELVDIIDQEWNQVTTD |
References More References in PubMed
| 1 |
The nucleotide sequence and genome structure of the geminivirus miscanthus streak virus. Chatani M, et al. J Gen Virol. 1991 Oct;72 ( Pt 10):2325-31. doi: 10.1099/0022-1317-72-10-2325. PMID: 1919519 |
|---|---|
| 2 |
Mollov D, et al. Plant Dis. 2025 Sep;109(9):1944-1949. doi: 10.1094/PDIS-11-24-2359-RE. Epub 2025 Sep 16. PMID: 40065195 |
| 3 |
Transposition of the maize Ds element from a viral vector to the rice genome. Sugimoto K, et al. Plant J. 1994 Jun;5(6):863-71. doi: 10.1046/j.1365-313x.1994.5060863.x. PMID: 8054991 |
| 4 |
Molecular cloning and physical mapping of the DNA of Miscanthus streak geminivirus. Ikegami M, et al. Intervirology. 1989;30(6):340-5. doi: 10.1159/000150112. PMID: 2621064 |