Digitaria streak virus
Basic Information
| Genus | Mastrevirus |
|---|---|
| NCBI Assembly | GCF_000838685.1 |
| Release date | 2015/2/12 |
| Submitter | Donson,J., Accotto,G.P., Boulton,M.I., Mullineaux,P.M., Davies,J.W. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
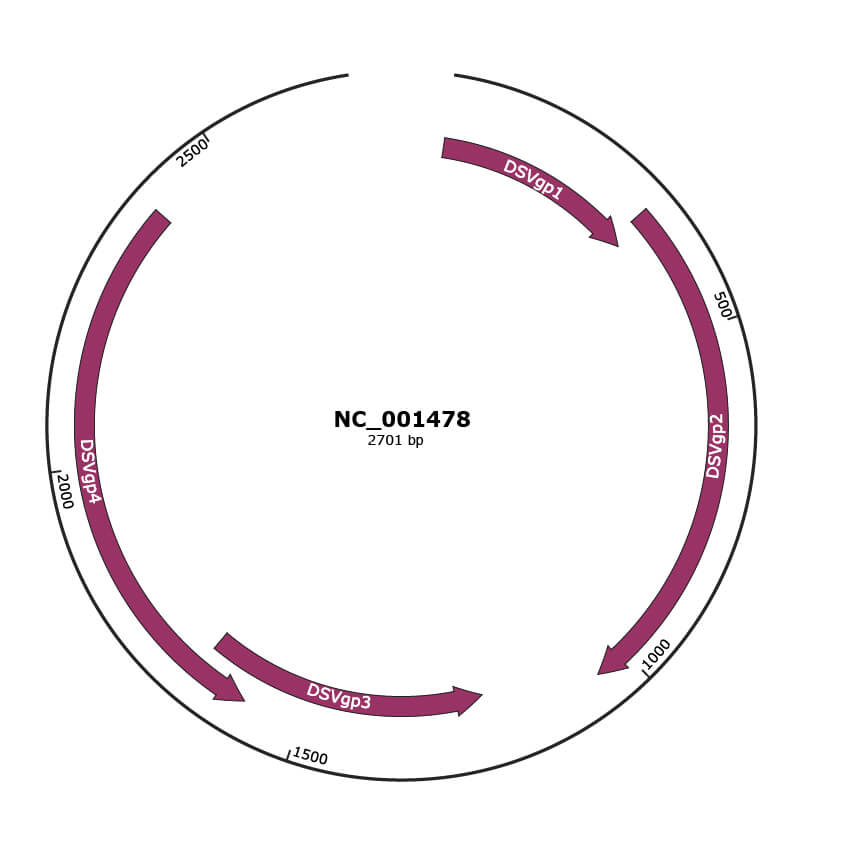
JBrowse
Genome
NC_001478
Gene Information
| NCBI Accession | NP_040962.1 |
|---|---|
| Location | 1-330 |
| Protein Name | movement protein |
| Coding Region | ATGGAGTGGTACCAGAGTGACACTGGCAATCAAAAGCCTCAAAGTCCCACGCAAGCTCCGTCTTTGCCGTGGAGTCGTCTCGGTGAGATAGCTATATTGACACTATTAGCAGTGCTTTGCATTTACCTGCTTTACATTTGGGTGCTGAGAGATCTTATCTTTGTTGTAAGATCTAACCGAGGACGCGTAGCGGAGGAGCTTGAATTTGGTCCCGCCGAGACAAGGAGCGCTTTGGCACAAAGCGCGGTGGTACCTAGATCTGAAGTTGTCCCGTCACAAGGAGCGGACCCTCCCGCTACTGAAAGCCATCTGCCATGTCTTCATCGATGA |
| Protein Sequence | MEWYQSDTGNQKPQSPTQAPSLPWSRLGEIAILTLLAVLCIYLLYIWVLRDLIFVVRSNRGRVAEELEFGPAETRSALAQSAVVPRSEVVPSQGADPPATESHLPCLHR |
| NCBI Accession | NP_040963.1 |
|---|---|
| Location | 315-1049 |
| Protein Name | coat protein |
| Coding Region | ATGTCTTCATCGATGAAGAGGAAGAGGACCGATGAGGGGAGCGGCTCCCGTCGCTTCACTAAGAAGAAATCCGCCGCGAAGGGGCGGACTAGCTCGTCAAGAGCTATTCGTCCCGCCCTCCAAATTCAAAGTTTTGTGTCTGCAGGTGCAGCCACAATTGCTGTTCCCACTGGCGGAGTATGTCATCTACTGAGCTCCTACAGCCGAGGCTCCGGCGAAGGAGACCGGCACACCAACGAGACTGTCACGTACAAAGCCGCATTCGACTACCACTTCAGTGCTAACGCTGGACCCTGCGCATACTCCAGTATTGGAGTAGGTGTCTTGTGGTTGGTGTATGACGCACAACCCAGTGGTCAGGTACCAGCGGTAACTGACATATTTCCGCATGATACAACCCTACAGTCCTTTCCATACACCTGGAAGGTGGGAAGGGAAGTGTGTCACCGCTTCGTGGTGAAACGCCGGTGGTGTTTCACAATGGAGACCAACGGGCGCATCGGTAGTGACAAACCTCCAAGCAACGCAGTCTGGCCTCCGTGCAAGCGGAGTATTTACTTCCACAAGTTCGCGACAGGACTCGGCGTCAAGACCGAGTGGAAGAATACAACGGATGGTGGCGTAGGCAGCATCAAGAAGGGTGCCCTGTACTTTGTAATAGCCCCTGGCTCGGGCATAGATTTTACACTGTTCGGTACCTGCCGTATGTACTTTAAGAGTGTGGGCAACCAGTAA |
| Protein Sequence | MSSSMKRKRTDEGSGSRRFTKKKSAAKGRTSSSRAIRPALQIQSFVSAGAATIAVPTGGVCHLLSSYSRGSGEGDRHTNETVTYKAAFDYHFSANAGPCAYSSIGVGVLWLVYDAQPSGQVPAVTDIFPHDTTLQSFPYTWKVGREVCHRFVVKRRWCFTMETNGRIGSDKPPSNAVWPPCKRSIYFHKFATGLGVKTEWKNTTDGGVGSIKKGALYFVIAPGSGIDFTLFGTCRMYFKSVGNQ |
| NCBI Accession | NP_040964.1 |
|---|---|
| Location | 1220->1666 |
| Protein Name | replication-associated protein B |
| Coding Region | GTCACGGATGGGGTCAGAAAACGCAGCCTCTACATCCTCGGTCCAACAAGAACTGGAAAGTCTACTTGGGCCAGAGGCCTAGGTAGACATAATTACTGGCAAAATAATGTAGACTGGGCTTCTTATGACGAGGAAGCCCAGTTCAATGTCATTGATGACATACCATTCAAGTTCTGTCCTTGTTGGAAACAGTTGATTGGTTGTCAGAAAGAATACGTCGTCAACCCTAAGTATGGTAAAAAGAAGCGTGTTGCTTCTAAATCCATACCATCAATAATCCTCACCAATCCGGATGAAGATTGGATGAAAGACATGACTCCAGCGCAGCTGTCGTACTTCGAAGCCAATACCGTCATTTACAAAATGACTGAAGGGGAAAGGTTCTTCAGCTACGCAGAAGGGCCAGCTACAGCGTCACTCGCTTCGCTCGACGACGCGCCGGCGTAA |
| Protein Sequence | VTDGVRKRSLYILGPTRTGKSTWARGLGRHNYWQNNVDWASYDEEAQFNVIDDIPFKFCPCWKQLIGCQKEYVVNPKYGKKKRVASKSIPSIILTNPDEDWMKDMTPAQLSYFEANTVIYKMTEGERFFSYAEGPATASLASLDDAPA |
| NCBI Accession | NP_040965.1 |
|---|---|
| Location | 1585-2385 |
| Protein Name | replication associated protein A |
| Coding Region | ATGGCTGCAAACCGTTCATTCAGGCACAGGAATGCTAACACATTCCTGACCTATTCCAAGTGCGATCACTCTCCTCAGCTCATAGCTGATCATCTCTGGGATCTCCTTAAGTCTTGGAATCCCATTTACATCCTTGTTGCATCCGAGCATCATGCAGATGGATCATTGCATAGTCATGCACTGGTTCAAACTGAGAAGCAGGTAAACACCACGAACCAGAGGTTCTTTGACATTCTTGAGTTCCACCCAAATATTCAGAGTGCAAAGAGCGTCAACAAGGTCAGGACATACATACTGAAAAACCCAGTGGAGAAATTTGAGAGAGGTACTTTTGTCCCAAGAAAATCACCATTTCTTGGGGAGAGTTCATCTTCCGAGAAGAAACACAATAAGGACGATGTCATGCGTGACATCATTGATCATGCTACATCAAAGGAAGAGTACCTCTCCATGGTGCAGAAGGCTCTGCCTTATGACTGGGCTACAAAGCTGTCGTACTTCGAGTACTCAGCTGATAGATTGTTCCCAGTTGAGGCTGCACCATTCATCAATCCTCATCCTCCGTCTGAGCCTGACCTCTTGTGCCAAGAGACCATCACAGATTGGCTTCAGAATGACCTCTTTCAGGTCAGTGCTGAAGCTTATTGCTTGTTGAACCCTACCTGTTATACCCGCGAGGAAGCTATCTCTGACTTACAATGGATGTCTGATTACACTAGGTCACGGATGGGGTCAGAAAACGCAGCCTCTACATCCTCGGTCCAACAAGAACTGGAAAGTCTACTTGGGCCAGAGGCCTAG |
| Protein Sequence | MAANRSFRHRNANTFLTYSKCDHSPQLIADHLWDLLKSWNPIYILVASEHHADGSLHSHALVQTEKQVNTTNQRFFDILEFHPNIQSAKSVNKVRTYILKNPVEKFERGTFVPRKSPFLGESSSSEKKHNKDDVMRDIIDHATSKEEYLSMVQKALPYDWATKLSYFEYSADRLFPVEAAPFINPHPPSEPDLLCQETITDWLQNDLFQVSAEAYCLLNPTCYTREEAISDLQWMSDYTRSRMGSENAASTSSVQQELESLLGPEA |
References More References in PubMed
| 1 |
Twenty years of evolution and diversification of digitaria streak virus in Digitaria setigera. Ortega-Del Campo S, et al. Virus Evol. 2021 Oct 13;7(2):veab083. doi: 10.1093/ve/veab083. eCollection 2021. PMID: 34659796 |
|---|---|
| 2 |
Mullineaux PM, et al. Nucleic Acids Res. 1990 Dec 25;18(24):7259-65. doi: 10.1093/nar/18.24.7259. PMID: 2175430 |
| 3 |
Agrobacterium-mediated infectivity of cloned digitaria streak virus DNA. Donson J, et al. Virology. 1988 Jan;162(1):248-50. doi: 10.1016/0042-6822(88)90416-3. PMID: 3341112 |
| 4 |
Accotto GP, et al. EMBO J. 1989 Apr;8(4):1033-9. doi: 10.1002/j.1460-2075.1989.tb03470.x. PMID: 2472960 |
| 5 |
[No authors listed] EMBO J. 1989 Nov;8(11):3542. doi: 10.1002/j.1460-2075.1989.tb08520.x. PMID: 16453907 |
| 6 |
Oluwafemi S, et al. Arch Virol. 2014 Oct;159(10):2765-70. doi: 10.1007/s00705-014-2090-7. Epub 2014 May 6. PMID: 24796552 |
| 7 |
Splicing features in maize streak virus virion- and complementary-sense gene expression. Wright EA, et al. Plant J. 1997 Dec;12(6):1285-97. doi: 10.1046/j.1365-313x.1997.12061285.x. PMID: 9450342 |
| 8 |
Shepherd DN, et al. J Gen Virol. 2007 Jan;88(Pt 1):325-336. doi: 10.1099/vir.0.82338-0. PMID: 17170465 |
| 9 |
Serotyping and strain identification of maize streak virus isolates. Pinner MS, et al. J Gen Virol. 1990 Aug;71 ( Pt 8):1635-40. doi: 10.1099/0022-1317-71-8-1635. PMID: 1697327 |
| 10 |
Characterization of the sugarcane streak agent as a distinct geminivirus. Hughes FL, et al. Intervirology. 1991;32(1):19-27. doi: 10.1159/000150181. PMID: 2016148 |