Dolichos yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_001343705.1 |
| Isolate | India |
| Release date | 2015/10/17 |
| Submitter | Akram,M., Naimuddin, Agnihotri,A.K., Gupta,S. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
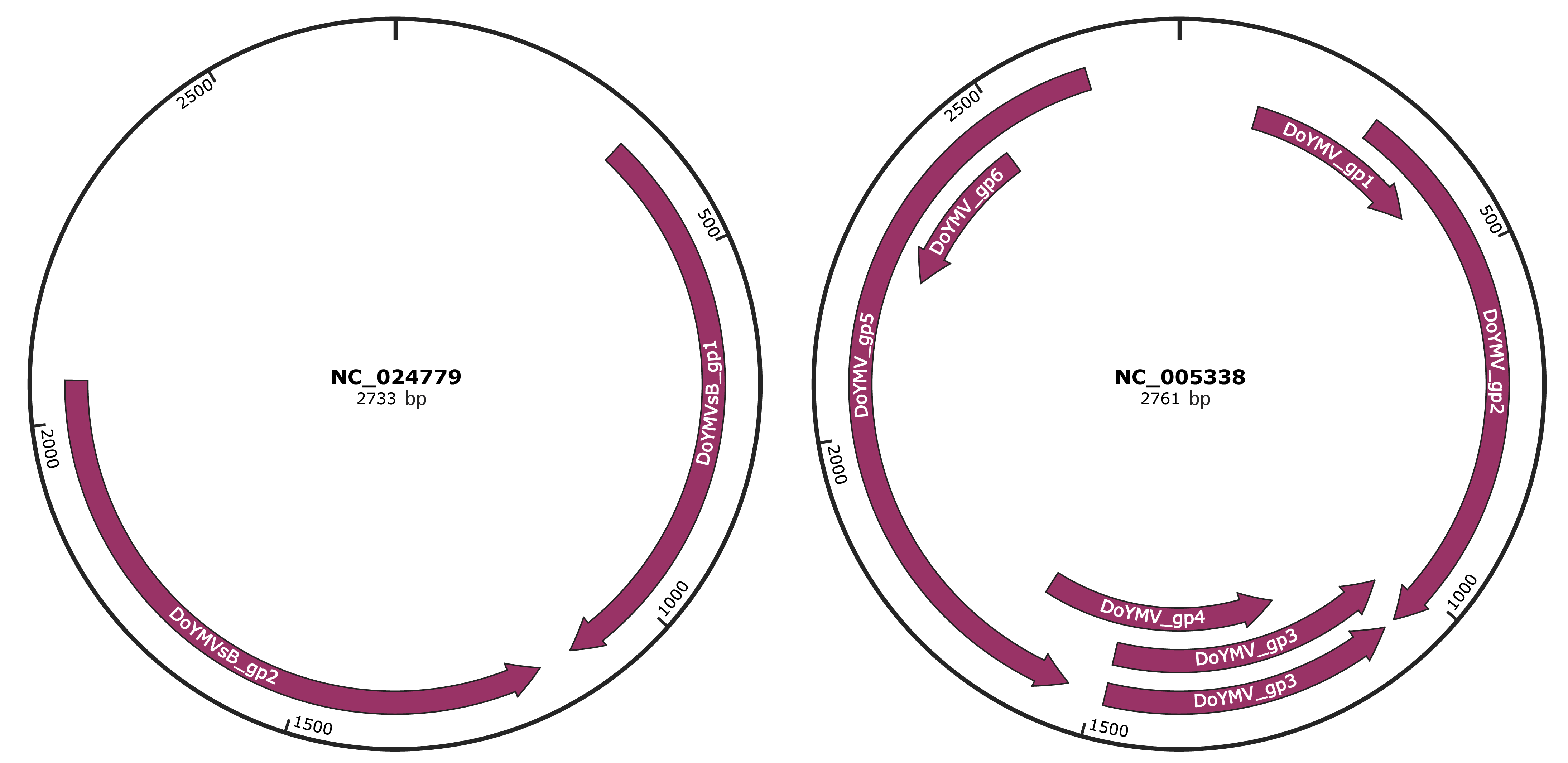
JBrowse
Genome
NC_024779
NC_005338
Gene Information
| NCBI Accession | YP_009055065.1 |
|---|---|
| Location | 329-1114 |
| Protein Name | BV1 |
| Coding Region | ATGTATCGCTCACGATCAACTCCCCTATCTGCTCGACGACCTCTGGTCAACCCGTTCGTCCGAGAACGGCAATTTGTTCCTCGTCGAACACCACGTTTTTTCAGAAAACGAGTTCATGCGACTCATCGTACGAGTCGCCGCCTATCTTACGAAAGAGTTGATCGTCCTATGTCCTTCAATGTCGTCGTTGAACGCCAACATGGTGATCATATGGCCCTGGTGAATAACCAGGACATTACATCTTTTATTGGCTATCCTATTCGTGGGTTCAACGAGGGACGATGCAGAGACTATATCAAGCTTCTGACACTCAATGTGTCAGGTATGATAACAGTCCGTTCGTTATCGACTGACGCCCCTATGTCCAGTAATGGCATCGTCAACGGAACCTTTGTTCTCTCGTTCGTATTGGACAAGAAGCCATATCTCCCTGATGGCGTTAACACGCTGCCCTCATTTGCGGAGCTATTTGGTCCATTCTCAGCGGCGTATTTCAACTTACGCCTGCTGGATTCTCAAAGAGAGAGGTTCAGATTATTGGGCAGCGTAAAGAAACATGTGTCATGTGGCGCTGATGAAGTAGAAGTCCCGTTCAAGTTCAAGAGGACCTTGTCGACAACAAGGTCTACTATGTGGGCCACGTTCAAGGACGTGGATATGGGCAATAGTGGAGGAAATTATAGAAATATCAGCAAGAACGCCATTTTAGTTAGTTATGCATTCGTTTCAATGCATAACATAAAGTGTGAACCATATGTACAATACGAACTGTCATATTTTGGTTAA |
| Protein Sequence | MYRSRSTPLSARRPLVNPFVRERQFVPRRTPRFFRKRVHATHRTSRRLSYERVDRPMSFNVVVERQHGDHMALVNNQDITSFIGYPIRGFNEGRCRDYIKLLTLNVSGMITVRSLSTDAPMSSNGIVNGTFVLSFVLDKKPYLPDGVNTLPSFAELFGPFSAAYFNLRLLDSQRERFRLLGSVKKHVSCGADEVEVPFKFKRTLSTTRSTMWATFKDVDMGNSGGNYRNISKNAILVSYAFVSMHNIKCEPYVQYELSYFG |
| NCBI Accession | YP_009055066.1 |
|---|---|
| Location | 1162-2055 |
| Protein Name | BC1 |
| Coding Region | ATGGAAGCATTCAACGGCGCGGTCGTGAACAACCGCTATATAGAGTCCAAGCGCTGTGAATATCGGCTGACGAATAATGAGACACCGATCACTCTTCAGTTTCCTTCATCGTTTGAGCAGACAAAGGTGCGAATGATGGGAAAGTGCATGAAGGTCGATCATATAGTGATCGAATACAGGAATCAGGTGCCTTTTAATGCGAAGGGGTCGGTTATCGTCACCATACGCGATAACAGGTTGAGTGACGACGAGGCGTCACAGGCGGCTTTTACCTTTCCCATAGGCTGCAACGTCGACCTACATTATTTTTCCTCCTCCTTCTTCTCCTTGAAGGACGAGACTCCCTGGGAGCTTTTGTATAGAGTGGAAGACTCAAATGTGGTCGACGGAACGACATTCGCACAGATTAAGGCGAAGCTGAAATTGTCGTCAGCCAAACACTCCACAGACATAACCTTCAAGCCTCCGACGATTAACATTCTGTCAAAGAACTACACAAAGGATTGTGTAGATTTCTGGTCAGTGGACAAACCCAAAGCTGTTCGGAGGCTTCTCCAGCCCGCAGCTGTTAATGGGCCAAGAGCCCACCAGATCAAATTAATGCCAGGAGAGACTTGGGCAACGCGGTCCACGATTGGCAGATCCGCATCTATGCGATATGACGTGGATACGACATCAGGCCCAAAGTCTGAATTGGGCCTGAACACTTATTCAGACGCGGAGTTTCCTCTTAGACACTTGCACAAATTACCCGAGACATCATTAGACCCCGGAGATTCAATTTCGCAAACAAATTCGATGAATTTGTCCAAGGCAGATATAGAGAACATAGTAGAGTCGACAGTTAATAAATGTTTGATAAAACAACGCACTGATGTCAGTAAAGCGTTGTGA |
| Protein Sequence | MEAFNGAVVNNRYIESKRCEYRLTNNETPITLQFPSSFEQTKVRMMGKCMKVDHIVIEYRNQVPFNAKGSVIVTIRDNRLSDDEASQAAFTFPIGCNVDLHYFSSSFFSLKDETPWELLYRVEDSNVVDGTTFAQIKAKLKLSSAKHSTDITFKPPTINILSKNYTKDCVDFWSVDKPKAVRRLLQPAAVNGPRAHQIKLMPGETWATRSTIGRSASMRYDVDTTSGPKSELGLNTYSDAEFPLRHLHKLPETSLDPGDSISQTNSMNLSKADIENIVESTVNKCLIKQRTDVSKAL |
| NCBI Accession | YP_009029988.1 |
|---|---|
| Location | 123-410 |
| Protein Name | AV2 |
| Coding Region | ATGTGGGTCCCATTAGTCAATGACTTTCCTGACACACTGCATGGATTGCGGTGTATGTTAGCTGTGAAATTTGTGCAGGAATTATTGGAGAGCTATCCGCGTGACTCTAATGGGCGCATCCTATTGGAGGAACTAATCCGGGTGTTGCGTTGTAAACGTTATGCCAAAGCGCAATTTCGATATGGCGTTTTCTACTCCAAGACCCAGCGTACGGCGAAGGCTCAACTTCGACACCCCATCTGCAACACCGATGTCAGTTCGTCGAACTCCGAGCACCAGTCGTCGTAG |
| Protein Sequence | MWVPLVNDFPDTLHGLRCMLAVKFVQELLESYPRDSNGRILLEELIRVLRCKRYAKAQFRYGVFYSKTQRTAKAQLRHPICNTDVSSSNSEHQSS |
| NCBI Accession | YP_009029989.1 |
|---|---|
| Location | 283-1056 |
| Protein Name | AV1 |
| Coding Region | ATGCCAAAGCGCAATTTCGATATGGCGTTTTCTACTCCAAGACCCAGCGTACGGCGAAGGCTCAACTTCGACACCCCATCTGCAACACCGATGTCAGTTCGTCGAACTCCGAGCACCAGTCGTCGTAGAGCATGGACCAATCGTCCAATGAATCGCAAACCGCGCATATATCGTCTATATCGCTCACGCGATGTACCATATGGGTGCGAGGGACCATGTAAAGTTCAATCCTTTGAACAACGGCATGATATCAGTCATACTGGTAAGGTCCTGTGTGTTTCCGATGTCACTAGAGGAAACAACCTTACTCATCGTGTTGGTAAACGATTTTGTGTTAAATCTGTTTACATTATTGGCAAAATTTGGATGGACGAGAACATTAAGACAAAGAACCATACAAACACAGTCATGTTTTGGCTAGTTCGTGATCGACGACCTTTTGGAACCCCAATGGACTTAGGGCAAGTGTTCAACATGTATGATAATGAACCCTCGACCGCCACTATCAAAAACGATCTTCGTGATCGTTACCAAGTTTTACGTAAGTTCGATTCAACTGTCACCGGAGGTCAATATGCGTCGAGGGAAGCAAATGTTATCAAGAGATTTTGGCGTGTCAACAATTATGTGGTGTACAACCACCAAGAAGCTGCTAAGTATGAAAATCATACTGAAAATGCATTATTATTGTATATGGCATGTACTCATGCCTCAAACCCAGTGTATGCAACATTAAAGATCAGGATCTATTTCTATGATTCTATCTCAAATTAA |
| Protein Sequence | MPKRNFDMAFSTPRPSVRRRLNFDTPSATPMSVRRTPSTSRRRAWTNRPMNRKPRIYRLYRSRDVPYGCEGPCKVQSFEQRHDISHTGKVLCVSDVTRGNNLTHRVGKRFCVKSVYIIGKIWMDENIKTKNHTNTVMFWLVRDRRPFGTPMDLGQVFNMYDNEPSTATIKNDLRDRYQVLRKFDSTVTGGQYASREANVIKRFWRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_009029990.1 |
|---|---|
| Location | 1073-1483 |
| Protein Name | AC3 |
| Coding Region | ATGACGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAACTACAGAGTGGCGTGTTTATCTGGGAGCTAAAGAATCCCCTGTCTTTCAAGATCCTGGAGCATCACGAGGGATTCATGTTCGATCCGAACCAACACAGAACCAAGATCCGCATAATGTTCAACCACGGGTTGAAGAAAGCGTTGGGGATACACAAGGCATTCTTGGATTTAGTGATTTACCATCGATTGACTCCGCAATCTGGGCGGATCTTGAATGTATTCAGGAACTTCCTTTTTAGATTTTTAAATAATTTAGGAATTATTTCGATGAACAATGTATTACGCAGTTGCGAATATGTATTGTATGATGTATTTCAGCGAGTCGAAGCTGTTGATTTCGAATTTAATGTACAATGGAAGTTATATTAA |
| Protein Sequence | MTDSRTGESITAAQLQSGVFIWELKNPLSFKILEHHEGFMFDPNQHRTKIRIMFNHGLKKALGIHKAFLDLVIYHRLTPQSGRILNVFRNFLFRFLNNLGIISMNNVLRSCEYVLYDVFQRVEAVDFEFNVQWKLY |
| NCBI Accession | YP_009029991.1 |
|---|---|
| Location | 1203-1631 |
| Protein Name | AC2 |
| Coding Region | ATGCGGTCTTCATCACCCTCGAACAGCCATTGTTCTCTACCGAGCATCAAGGCACAGCATCGACAAGCGAAGAAGCGCAAAACGATTCGGCGTAAGCGAATCGATCTGACCTGTGGCTGTTCGTATTACCTGAATATCAACTGCCGGAATGACGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAACTACAGAGTGGCGTGTTTATCTGGGAGCTAAAGAATCCCCTGTCTTTCAAGATCCTGGAGCATCACGAGGGATTCATGTTCGATCCGAACCAACACAGAACCAAGATCCGCATAATGTTCAACCACGGGTTGAAGAAAGCGTTGGGGATACACAAGGCATTCTTGGATTTAGTGATTTACCATCGATTGACTCCGCAATCTGGGCGGATCTTGAATGTATTCAGGAACTTCCTTTTTAG |
| Protein Sequence | MRSSSPSNSHCSLPSIKAQHRQAKKRKTIRRKRIDLTCGCSYYLNINCRNDGFTHRGIHHCSSTTEWRVYLGAKESPVFQDPGASRGIHVRSEPTQNQDPHNVQPRVEESVGDTQGILGFSDLPSIDSAIWADLECIQELPF |
| NCBI Accession | YP_009029992.1 |
|---|---|
| Location | 1537-2634 |
| Protein Name | AC1 |
| Coding Region | ATGAGAGCTCCAGGCTTCCGCATATCTGCCAGAAATATATTTCTGACCTACCCCAAATGCTCTCTCTCAAAGGAAGAAGCTCTCGAGCAGCTCTGTCGCATCGAGTGTCCGTCGGACAAATTGTTCATCAGAGTGGCACAAGAAGCACATCAAGATGGGACTATGCATCTCCATGCCCTCGTCCAGTTCAAGGGTAAGGCCCAGTTCCGAAATGCAAGACATTTCGACCTTACCCATCCTCATAGCACACAGGTTTTCCATGGAAATGTCCAGGGAGCAAAGAGCTCATCTGATGTCAAATCCTACATCACCAAGGACGGTGATTACGTCGACTGGGGAACATTTCAGATCGACGGACGATCTGCTAGAGGAGGTCGTCAGACAGCTGACGATGCTGTAGCATCGGCGTTGAATTCCGGTACGGTTCAAGGTGCTCTGAACATTATCAAAGAATTACTTCCACACAATTATGTGTTCCAGTATCATAATCTGAGATGTAACCTTGAACGAATATTCGCTCCTCCGATTGCAGTTTACACGTCATATTACAAGCCTGCCGACTTTAGTCAAGTGCCGTCTGTTATGACAGAATGGGCAGAAAATAACGTTGTTGATCCTTCGTGGAGGAGCGACCCCGCTGCGCGGCCGAGAAGACCGATGAGCATCGTTGTTGAAGGAGCAACAAGAACAGGGAAGACGTTATGGGCACGGTCATTAGGAGTCCATAATTACATGTGTGGACACCTGGATCTTAGCCCTAAGATATTTTCAAATGATGCTTGGTATAACGTCATTGATGACGTTGATCCGCATTATCTAAAGCATTTTAAAGAGTTTATGGGGGCCCAGATGGACTGGCAAAGCAACATCAAATACGGTAAGCCCACTCAAATTAAAGGTGGGATACCCACCATCTTTCTTTGCAATCCAGGACCACGTTCGTCCTATAAAGAGTTCCTTGATGAGGAACAGAACGAATCATTGAAGGAGTGGGCTTACAAGAATGCGGTCTTCATCACCCTCGAACAGCCATTGTTCTCTACCGAGCATCAAGGCACAGCATCGACAAGCGAAGAAGCGCAAAACGATTCGGCGTAA |
| Protein Sequence | MRAPGFRISARNIFLTYPKCSLSKEEALEQLCRIECPSDKLFIRVAQEAHQDGTMHLHALVQFKGKAQFRNARHFDLTHPHSTQVFHGNVQGAKSSSDVKSYITKDGDYVDWGTFQIDGRSARGGRQTADDAVASALNSGTVQGALNIIKELLPHNYVFQYHNLRCNLERIFAPPIAVYTSYYKPADFSQVPSVMTEWAENNVVDPSWRSDPAARPRRPMSIVVEGATRTGKTLWARSLGVHNYMCGHLDLSPKIFSNDAWYNVIDDVDPHYLKHFKEFMGAQMDWQSNIKYGKPTQIKGGIPTIFLCNPGPRSSYKEFLDEEQNESLKEWAYKNAVFITLEQPLFSTEHQGTASTSEEAQNDSA |
| NCBI Accession | YP_009029993.1 |
|---|---|
| Location | 2235-2480 |
| Protein Name | AC4 |
| Coding Region | ATGGGACTATGCATCTCCATGCCCTCGTCCAGTTCAAGGGTAAGGCCCAGTTCCGAAATGCAAGACATTTCGACCTTACCCATCCTCATAGCACACAGGTTTTCCATGGAAATGTCCAGGGAGCAAAGAGCTCATCTGATGTCAAATCCTACATCACCAAGGACGGTGATTACGTCGACTGGGGAACATTTCAGATCGACGGACGATCTGCTAGAGGAGGTCGTCAGACAGCTGACGATGCTGTAG |
| Protein Sequence | MGLCISMPSSSSRVRPSSEMQDISTLPILIAHRFSMEMSREQRAHLMSNPTSPRTVITSTGEHFRSTDDLLEEVVRQLTML |
References More References in PubMed
| 1 |
Transovarial Transmission of Dolichos Yellow Mosaic Virus by Its Vector, Bemisia tabaci Asia II 1. Ghosh A, et al. Front Microbiol. 2021 Oct 25;12:755155. doi: 10.3389/fmicb.2021.755155. eCollection 2021. PMID: 34759905 |
|---|---|
| 2 |
Sandra N, et al. Front Plant Sci. 2024 May 14;15:1376284. doi: 10.3389/fpls.2024.1376284. eCollection 2024. PMID: 38807782 |
| 3 |
Suruthi V, et al. Virusdisease. 2018 Dec;29(4):506-512. doi: 10.1007/s13337-018-0494-9. Epub 2018 Sep 25. PMID: 30539054 |
| 4 |
First Report of Herbacious Hosts for Citrus yellow mosaic badna virus from India. Aparna GS, et al. Plant Dis. 2002 Aug;86(8):920. doi: 10.1094/PDIS.2002.86.8.920A. PMID: 30818652 |
| 5 |
Legume yellow mosaic viruses: genetically isolated begomoviruses. Qazi J, et al. Mol Plant Pathol. 2007 Jul;8(4):343-8. doi: 10.1111/j.1364-3703.2007.00402.x. PMID: 20507504 |
| 6 |
Singh SK, et al. Bioresour Technol. 2006 Oct;97(15):1807-14. doi: 10.1016/j.biortech.2005.09.004. Epub 2005 Oct 18. PMID: 16242317 |
| 7 |
Rai N, et al. Appl Biochem Biotechnol. 2016 Mar;178(5):876-90. doi: 10.1007/s12010-015-1915-5. Epub 2015 Nov 5. PMID: 26541159 |