Dicliptera yellow mottle Cuba virus
Basic Information
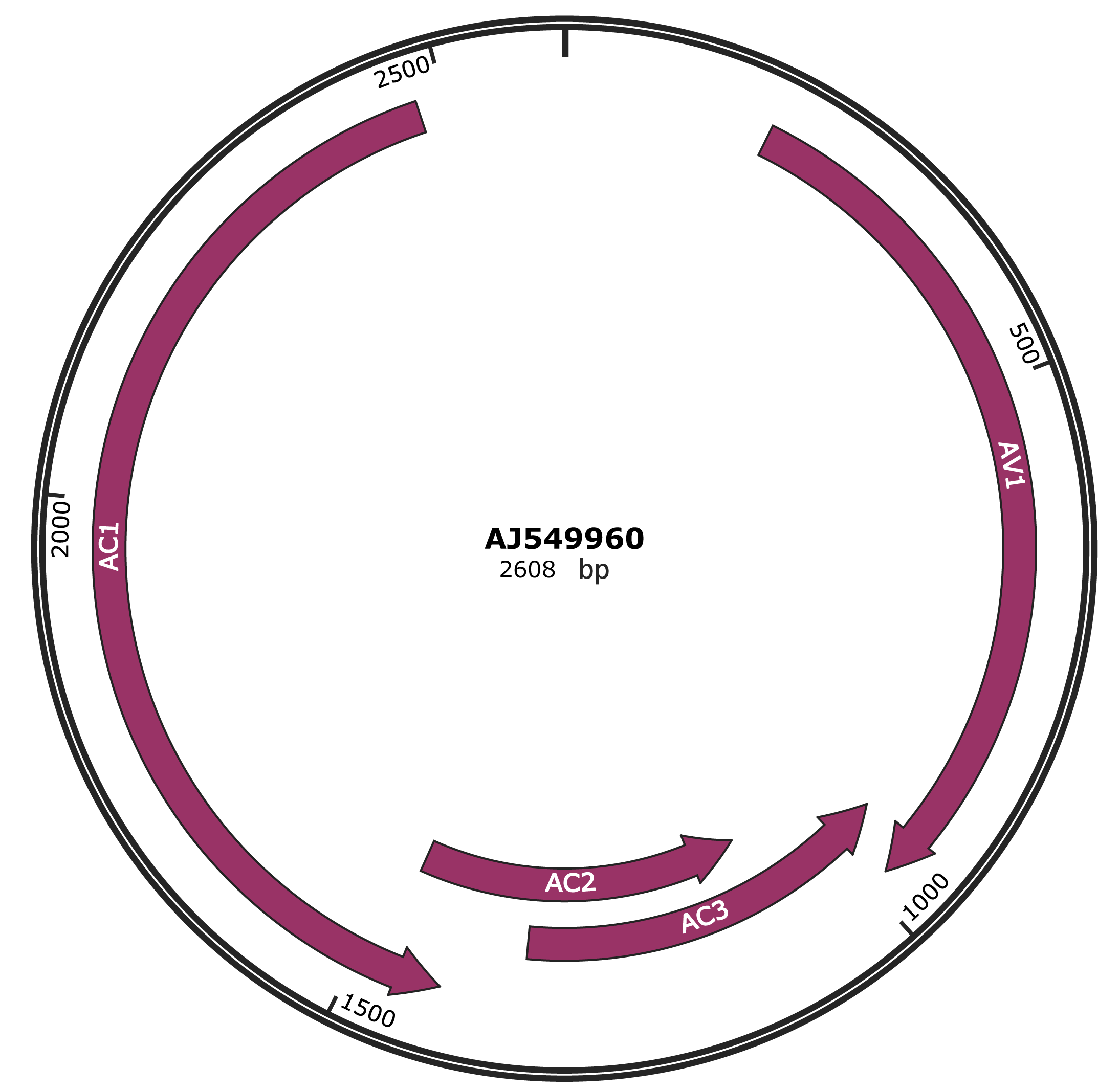
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGTCGGTCCCACTACTTTTCCGTACTCTCTGGTGGTCCCCCCTCTCTTTAATTTGAATTAAATGTTTGTGGACCAATCATATTGCATGTGCAGAGTCTAGATATTTGTGTTACTACTTGCTGATTAAGTTTAGTGGGCCTATAAAATTCAAATTAAAGCCCATTCTCAATAATTCAAAATGTCTAAGAGGGATGCCCCATGGCGTATGATGGTGGGTCCCTCTAAGGTTAGACGTACTCTCAATTTCTCACCTGGTGCTGGTTTGGGCTCAAAGTCCAATAGGGCTTCTTCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGAATGTACAGAACTCCTGATGTGCCCAAAGGGTGTGAAGGCCCATGTAAGGTCCAGTCTTATGAGCAGCGACATGACATCTCACATGTTGGTAAGGTGATGTGCATATCTGATGTGACACGTGGTAATGGTATTACTCACCGTGTGGGGAAACGTTTTTGTGTTAAGTCTGTGTACATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACCAATAGTGTCATGTTTTGGGTGGTTAGAGACAGGAGACCATATGGCACTCCTATGGATTTTGGTCAGGTGTTTAACATGTTTGATAATGAGCCCAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGTTATCAAGTCATGCATAAGTTCTATGCCAAGGTGACAGGTGGACAGTATGCCAGCAATGAGCAGGCTTTGGTGAAGCGTTTCTGGAAGGTGAATAATCATGTAGTGTACAATCATCAAGAAGCAGGGAAATATGAAAATCATACAGAGAATGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATTATGAATTTAATAAAATTTGAATTTTATTTCATGATTTTCTAGTACATCTGTTACATACGATTTGTCTGTTGCATAATGAACAGCTCTAATGACATTGTTAATTGAAATAACACCTATATTATCTAAATATGACAATACAAGGAATTTGAATCTATTTAAATAAATCATCCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGTTGAAGAAGGCTTTGTGAAGATCCAATTTCTTCCGAAGGTTGTAATTGAACCTGATTTGAAGGTGATACACCCTGCTGCGTGTGTACATTGGATCCTCTACTTGGAGTATCTTGAAATAGAGGGGATTTGGAACTTCCCAAATAAAAACGCCACTCGTTGCTTGAACTGCAGTGATGGTTCCCCCTGTGCGTGAATCCATGATTAGCACAATTAATGTGTATGTATATTGAACAACCACAATTGAGGTCAACTCTTCTTCGTCGGATTGCTCTTTTTTTAGCTCTCTTGTGAATTGGTTTGATAGAGGGGCAATGTGAGGGTGATGAAGATCGCATTATGAATGGTCCAATTATGTAAACCTTTATTTTCCTCTTTGTTTAGGAAATCTTTATAGCTGGAGCCCTCACCAGGATTGCATAGCACGATTGATGGTATACCTCCTTTAATTTGAACTGGCTTTCCATATTTACAGTTTGACTGCCAGTCTTTCTGGGCCCCAATTAAGTCTTCCCCGTGCTTTAATTTCAAATAATTAGGGCTGACATCATCAATGACGTTGTATTCCACGTCATTTGAATATACCCTAGAATTGAAATCCAGATGACCTGATAGATAGTTATGTTTGCCTAGAGTCCTGGCCCACATTGTCTTGCCTGTTCTTGAATCACCTTCGACGATGATACTAATAGGTCTCTCCGGCCGCGCAGCGGCACTCATGCCAAAATAATTGTCTGCCCATTCCTGCATTTCTTCTGGTACGTTAGTGAAGGAAGAAAGTTGAAACGGAGGGACCCACGGTTCTGGTGCTTTCATGAAAATCTTAGTTGCATTTGTAACCAGATTATGATGTTGGAGGAAGAAGTGCTGAGGTTGTTCCTCTTTTAATATTTGAAGTGCCTCAATTGCAGAAGATGCATTTAATGCCTTTGCATATGTATCGTTAACTGATTGGCAACCTCCTCTAGCACTTCTACCGTCGACCTGGAAAACTCCCCATTCAATTGTATCTCCGTCCTTGTTGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAAACCAGATCGAAGAATCTGTTATTTTTGCAGTTGAACTTTCCTTCGAACTGGATGAGCACATGAAGATGAGTCTCCCCATTTTCATGGAGTTCTCTACAAATCTTGATAAACTTCTTGTTAACTGGAGTAGATATGCTTTGTATTTGTGTTAGTGCTTCTTCTTTGCTAAGAGAACACTGTGGATATGTGAGGAAATAATTTTTGGCATTCACTGAAATCGTATAACTGATTGGCATATTTGTAATATGATATTGGTACCAGTTTGAGCTCTCTTCAAATGTCTATATAATTGGTAGAACTGGTAGACTATATATACATAAACCTTCTTTAAGGGATTAGCAACACGTTGCGGCCATCCGATATAATATT
Gene Information
|
NCBI Accession
|
CAD79312.1
|
|
Location
|
191-979 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCTAAGAGGGATGCCCCATGGCGTATGATGGTGGGTCCCTCTAAGGTTAGACGTACTCTCAATTTCTCACCTGGTGCTGGTTTGGGCTCAAAGTCCAATAGGGCTTCTTCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGAATGTACAGAACTCCTGATGTGCCCAAAGGGTGTGAAGGCCCATGTAAGGTCCAGTCTTATGAGCAGCGACATGACATCTCACATGTTGGTAAGGTGATGTGCATATCTGATGTGACACGTGGTAATGGTATTACTCACCGTGTGGGGAAACGTTTTTGTGTTAAGTCTGTGTACATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACCAATAGTGTCATGTTTTGGGTGGTTAGAGACAGGAGACCATATGGCACTCCTATGGATTTTGGTCAGGTGTTTAACATGTTTGATAATGAGCCCAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGTTATCAAGTCATGCATAAGTTCTATGCCAAGGTGACAGGTGGACAGTATGCCAGCAATGAGCAGGCTTTGGTGAAGCGTTTCTGGAAGGTGAATAATCATGTAGTGTACAATCATCAAGAAGCAGGGAAATATGAAAATCATACAGAGAATGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATTATGAATTTAATAAAATTTGAATTTTATTTCATGATTTTCTAG |
|
Protein Sequence
|
MSKRDAPWRMMVGPSKVRRTLNFSPGAGLGSKSNRASSWVNRPMYRKPRIYRMYRTPDVPKGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWVVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMNLIKFEFYFMIF |
|
NCBI Accession
|
CAD79313.1
|
|
Location
|
944-1342 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhacement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGGAACCATCACTGCAGTTCAAGCAACGAGTGGCGTTTTTATTTGGGAAGTTCCAAATCCCCTCTATTTCAAGATACTCCAAGTAGAGGATCCAATGTACACACGCAGCAGGGTGTATCACCTTCAAATCAGGTTCAATTACAACCTTCGGAAGAAATTGGATCTTCACAAAGCCTTCTTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGATGATTTATTTAAATAGATTCAAATTCCTTGTATTGTCATATTTAGATAATATAGGTGTTATTTCAATTAACAATGTCATTAGAGCTGTTCATTATGCAACAGACAAATCGTATGTAACAGATGTACTAGAAAATCATGAAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGGTITAVQATSGVFIWEVPNPLYFKILQVEDPMYTRSRVYHLQIRFNYNLRKKLDLHKAFFNFQVWTTSLTASGMIYLNRFKFLVLSYLDNIGVISINNVIRAVHYATDKSYVTDVLENHEIKFKFY |
|
NCBI Accession
|
CAD79314.1
|
|
Location
|
1089-1478 |
|
Gene Name
|
AC2 |
|
Protein Name
|
Trans-activating protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACATTGCCCCTCTATCAAACCAATTCACAAGAGAGCTAAAAAAAGAGCAATCCGACGAAGAAGAGTTGACCTCAATTGTGGTTGTTCAATATACATACACATTAATTGTGCTAATCATGGATTCACGCACAGGGGGAACCATCACTGCAGTTCAAGCAACGAGTGGCGTTTTTATTTGGGAAGTTCCAAATCCCCTCTATTTCAAGATACTCCAAGTAGAGGATCCAATGTACACACGCAGCAGGGTGTATCACCTTCAAATCAGGTTCAATTACAACCTTCGGAAGAAATTGGATCTTCACAAAGCCTTCTTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGATGATTTATTTAAATAG |
|
Protein Sequence
|
MRSSSPSHCPSIKPIHKRAKKRAIRRRRVDLNCGCSIYIHINCANHGFTHRGNHHCSSSNEWRFYLGSSKSPLFQDTPSRGSNVHTQQGVSPSNQVQLQPSEEIGSSQSLLQLPSLDDFSDSFWDDLFK |
|
NCBI Accession
|
CAD79315.1
|
|
Location
|
1420-2475 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCAATCAGTTATACGATTTCAGTGAATGCCAAAAATTATTTCCTCACATATCCACAGTGTTCTCTTAGCAAAGAAGAAGCACTAACACAAATACAAAGCATATCTACTCCAGTTAACAAGAAGTTTATCAAGATTTGTAGAGAACTCCATGAAAATGGGGAGACTCATCTTCATGTGCTCATCCAGTTCGAAGGAAAGTTCAACTGCAAAAATAACAGATTCTTCGATCTGGTTTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCAACAAGGACGGAGATACAATTGAATGGGGAGTTTTCCAGGTCGACGGTAGAAGTGCTAGAGGAGGTTGCCAATCAGTTAACGATACATATGCAAAGGCATTAAATGCATCTTCTGCAATTGAGGCACTTCAAATATTAAAAGAGGAACAACCTCAGCACTTCTTCCTCCAACATCATAATCTGGTTACAAATGCAACTAAGATTTTCATGAAAGCACCAGAACCGTGGGTCCCTCCGTTTCAACTTTCTTCCTTCACTAACGTACCAGAAGAAATGCAGGAATGGGCAGACAATTATTTTGGCATGAGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATCGTCGAAGGTGATTCAAGAACAGGCAAGACAATGTGGGCCAGGACTCTAGGCAAACATAACTATCTATCAGGTCATCTGGATTTCAATTCTAGGGTATATTCAAATGACGTGGAATACAACGTCATTGATGATGTCAGCCCTAATTATTTGAAATTAAAGCACGGGGAAGACTTAATTGGGGCCCAGAAAGACTGGCAGTCAAACTGTAAATATGGAAAGCCAGTTCAAATTAAAGGAGGTATACCATCAATCGTGCTATGCAATCCTGGTGAGGGCTCCAGCTATAAAGATTTCCTAAACAAAGAGGAAAATAAAGGTTTACATAATTGGACCATTCATAATGCGATCTTCATCACCCTCACATTGCCCCTCTATCAAACCAATTCACAAGAGAGCTAA |
|
Protein Sequence
|
MPISYTISVNAKNYFLTYPQCSLSKEEALTQIQSISTPVNKKFIKICRELHENGETHLHVLIQFEGKFNCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYINKDGDTIEWGVFQVDGRSARGGCQSVNDTYAKALNASSAIEALQILKEEQPQHFFLQHHNLVTNATKIFMKAPEPWVPPFQLSSFTNVPEEMQEWADNYFGMSAAARPERPISIIVEGDSRTGKTMWARTLGKHNYLSGHLDFNSRVYSNDVEYNVIDDVSPNYLKLKHGEDLIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKDFLNKEENKGLHNWTIHNAIFITLTLPLYQTNSQES |