Desmodium mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_003029545.2 |
| Isolate | Uganda |
| Release date | 2018/12/27 |
| Submitter | Mollel,H.G., Sseruwagi,P., Ndunguru,J., Alicai,T., Colvin,J., Navas-Castillo,J., Fiallo-Olive,E. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
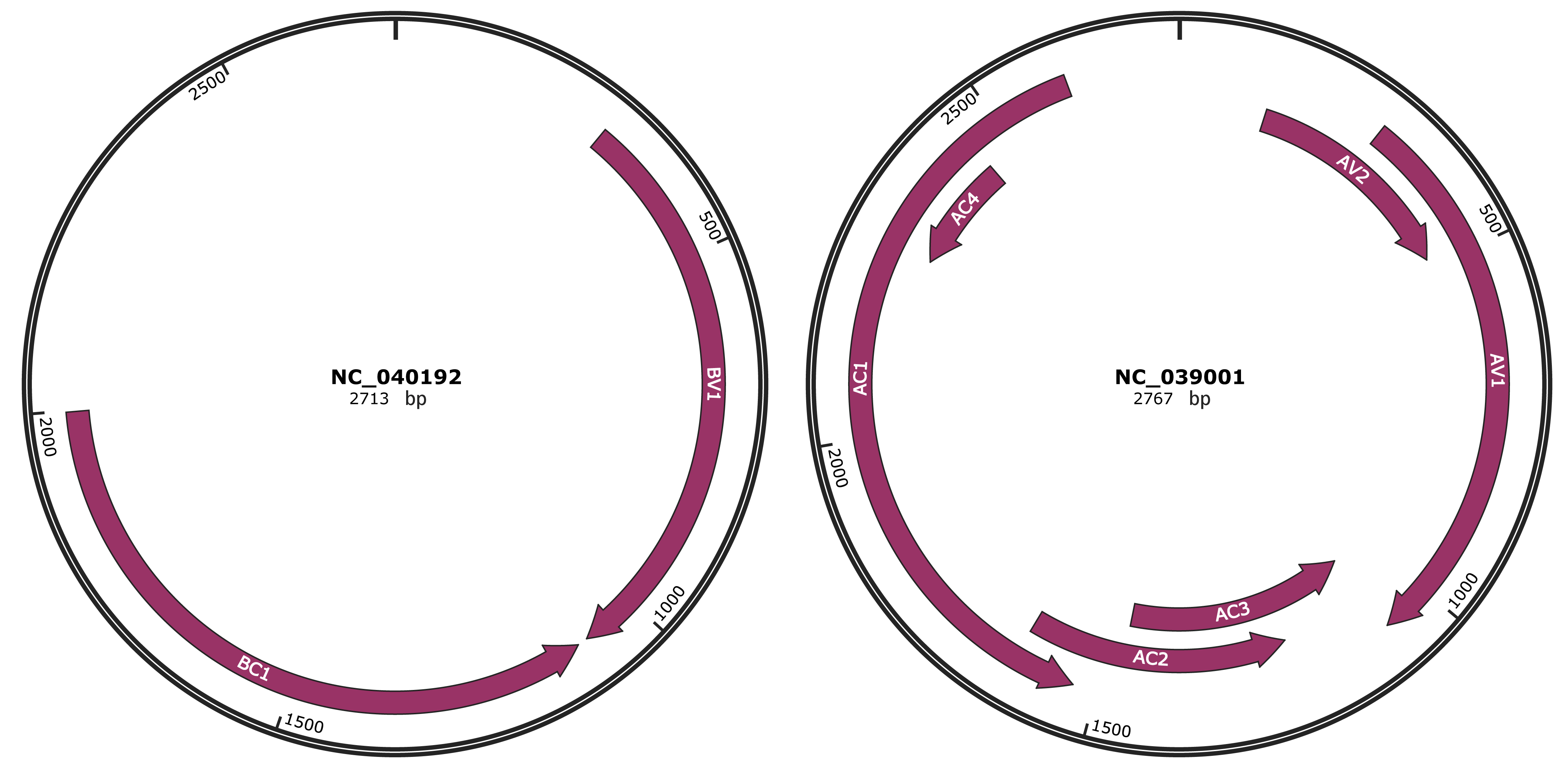
JBrowse
Genome
NC_040192
NC_039001
Gene Information
| NCBI Accession | YP_009547944.1 |
|---|---|
| Location | 299-1078 |
| Gene Name | BV1 |
| Protein Name | NSP |
| Coding Region | ATGTGGTCTCCTAGATTTAAGGGAAGACGGAGGTTTGACCGGTCTAAGGTTTCCGGTTACCGGATACCAACTACAACGCCTTCTAGGCGTTACAAGAGTCAAGGTTTTTCTCGTGGTGGTGTTTCTCGTTCTCTGACGTATGAACGTGTTGAGCGCCCGTTGGGCTACAAGTGTTTAATGGAACGACATCATGGTGATGCGTTCGCCTTGACCAGTAATTGTGATACTACGTCATTCATTAGTTACCCTGTACGTGCCCTCTCTGGAGAAGGACGTTCTCGTGACTACATTAAATTGCTAAGCATACGTGCATCAGGCGTCATTAATGTTAAAGGCCTGGTTAAACATGACGCCATGGAGAGGTCGACAAACTTCTCTGGCGTTTTTGTGATGGCGTTGGTGATGGACATGAAGCCATATTTGCCGGAAGGAAGCAACCAACTCCCCTCGTTTGTGGAGTTGTTTGGACCCTATTCATCTGCATATGTGACTCTTCGTTTGTTGGACAATCAAACCAGTAGGTTTAGGATACTAACGAGCGTGAGCAAAATGGTGTACACGCAGGACGATAGTAGAGTCCTCCAGTTTAAGTGTTATAGGCGTTTTACGCACTCGAGGTATCCCATATGGGCCTCATTTTACGACCATGACATCGGTAATAGTGGGGGAAATTATAGGAATATTTCTAGGAATGCGGTGTTAGTCAGCTATGCATTTGTATCGGAACAGTCGATGTCATGTGTACCATTTGTTCAATTGGAAACGCGTTATATTGGATAA |
| Protein Sequence | MWSPRFKGRRRFDRSKVSGYRIPTTTPSRRYKSQGFSRGGVSRSLTYERVERPLGYKCLMERHHGDAFALTSNCDTTSFISYPVRALSGEGRSRDYIKLLSIRASGVINVKGLVKHDAMERSTNFSGVFVMALVMDMKPYLPEGSNQLPSFVELFGPYSSAYVTLRLLDNQTSRFRILTSVSKMVYTQDDSRVLQFKCYRRFTHSRYPIWASFYDHDIGNSGGNYRNISRNAVLVSYAFVSEQSMSCVPFVQLETRYIG |
| NCBI Accession | YP_009547945.1 |
|---|---|
| Location | 1093-1998 |
| Gene Name | BC1 |
| Protein Name | MP |
| Coding Region | ATGGACACTTCAATTCCAGTGATGCATAGCGAATACATTCAAAGCACAAGGTCTGAATACAGACTTACAAATAACGAAACCCCAATTTCGTTACAATTCCCGTCATCACTGGAAAAGGTACGAGTCCGAATAATGGGAAAATGCATGAAGGTCGACCACGTAATCATCGAATACCGTAACCAGGTTCCGTTTAATGCCCAAGGCTCGGTGATTGTCACAATCCGTGACACAAGGCTTAGCGAAGAACAACAAGACCAAGCCCAGTTCACATTTCCTATAGGCTGTAATGTCGACCTACATTACTTCTCCGCCTCCTTCTTCTCCCTAGAAGATAAAGCACCGTGGGAGTTATTTTACAAAGTAGAGGACTCAAATGTGAAGGACGGAGTAACGTTTGCGCAAATCAAGGCCAAGCTTAAGTTATCATCCGCAACGCACTCAACGGACATAAGGTTTAAGCAACCCACAATAAAAATCCTCTCAAAGGATTACAACGCGGACTGTGTGGACTTCTGGTCCGTTGGAAAGCCCAAACCGATTAGGCGACTCATTAACCCAGGCCCAACAACAGAGTCCAGTCTTGCAGGGCATTACCGGGCCGTTCAAATACAACCCGGTGAAACATGGGCCACCAAATCGACTATAGGCAGGTCTTCGTCCATGCGACTAACAACGTCGCAACCAATGCATACGGGTTCCACCTTACGCACACAGAGTGCTTGTTCCGACGCGGAGTTCCCCTTACAAGGACTGCACAAGCTACCTGAAGCATCACTAGACCCAGGAGATTCAATTTCCCAAACAACGTCAAATGCGCTCAGCAAGGCGGACATTGAGTCCATTGTAGAACAAACTGTAAATAAGTGCTTAATCGCACAAAGAGGCAGTAGCCTTAAAAACTTGTAA |
| Protein Sequence | MDTSIPVMHSEYIQSTRSEYRLTNNETPISLQFPSSLEKVRVRIMGKCMKVDHVIIEYRNQVPFNAQGSVIVTIRDTRLSEEQQDQAQFTFPIGCNVDLHYFSASFFSLEDKAPWELFYKVEDSNVKDGVTFAQIKAKLKLSSATHSTDIRFKQPTIKILSKDYNADCVDFWSVGKPKPIRRLINPGPTTESSLAGHYRAVQIQPGETWATKSTIGRSSSMRLTTSQPMHTGSTLRTQSACSDAEFPLQGLHKLPEASLDPGDSISQTTSNALSKADIESIVEQTVNKCLIAQRGSSLKNL |
| NCBI Accession | YP_009508449.1 |
|---|---|
| Location | 137-487 |
| Gene Name | AV2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGACCCTCTTGAACATCCATTCCCCCATACCGTTTACGGTGTCAGGTGTATGCTTGCGGTGAAATACGTGCAACTTGTGATTGCCACGTATCCCGTCGATAGTATTGGGGAGGATCTTTTACGCCGTCTAATTCAGATTCTACGGTGCAGGAACCATGACGAAGCGGAGTTACGATACAGCCTTCTCTACGCCGATGTCGAGCGCACGGAGGCGTCTGACCTTCGCAACCCCTCTGGCGCTCCCTGCACCTGCCGGAGCTGCCCCAAACACGTACAAACGAAGGGCCTGGAGGAACCGGCCCATGTACAGGAAGCCCAAGATATACAGGGTTTACCGTTCAAGTGA |
| Protein Sequence | MWDPLEHPFPHTVYGVRCMLAVKYVQLVIATYPVDSIGEDLLRRLIQILRCRNHDEAELRYSLLYADVERTEASDLRNPSGAPCTCRSCPKHVQTKGLEEPAHVQEAQDIQGLPFK |
| NCBI Accession | YP_009508450.1 |
|---|---|
| Location | 297-1070 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGACGAAGCGGAGTTACGATACAGCCTTCTCTACGCCGATGTCGAGCGCACGGAGGCGTCTGACCTTCGCAACCCCTCTGGCGCTCCCTGCACCTGCCGGAGCTGCCCCAAACACGTACAAACGAAGGGCCTGGAGGAACCGGCCCATGTACAGGAAGCCCAAGATATACAGGGTTTACCGTTCAAGTGATGTACCCAAGGGCTGTGAAGGCCCCTGTAAGGTCCAGTCTTATGACCAGAGGTTTGATTGTAAACACACTGGTAGTGTTCTCTGTGTGTCAGATATTACCCGTGGTAGTGGCTTGACTCATCGCGTAGGCAAACGCTTTTGCGTGAAGTCCATCATGTTTAGGGGTAAAGTCTGGATGGACGATAACATCAAATCTAAGAGTCATACGAACCATGTGATGTTTTTTTTGGTTCGTGACCGACGCCCGTATGGAACTCCACCTGACTTTGGTCAAGTGTTTAACATGTTTGACAATGAGCCTACCACTGCTACTGTGAAACAAGATTTCCGTGATCGTTTTCAAGTAAAGAGGCGTTGGTGGGTTGGTGTAACCGGTGGACAGTATGCGTCGAAGGAACAGGCGATAGTCAACAAGTTCGTTTATTTAAACAATTATGTTGTTTACAATCACCAAGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCTATGTTATTGTATATGGCATGTACTCATGCATCAAACCCTGTGTATGCAACTCTAAAAATACGGGTGTATTTTTATGACTCAATTGGCAATTAA |
| Protein Sequence | MTKRSYDTAFSTPMSSARRRLTFATPLALPAPAGAAPNTYKRRAWRNRPMYRKPKIYRVYRSSDVPKGCEGPCKVQSYDQRFDCKHTGSVLCVSDITRGSGLTHRVGKRFCVKSIMFRGKVWMDDNIKSKSHTNHVMFFLVRDRRPYGTPPDFGQVFNMFDNEPTTATVKQDFRDRFQVKRRWWVGVTGGQYASKEQAIVNKFVYLNNYVVYNHQEAGKYENHTENAMLLYMACTHASNPVYATLKIRVYFYDSIGN |
| NCBI Accession | YP_009508451.1 |
|---|---|
| Location | 1067-1471 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAAAGGAGTTACTCACTCCATCGGAAGCAGAGCGTGGCGAGTATATCTGGGAGCTGAACAATCCCCTGTCTTTCAAACTCCTCCGAGAAGACTATGGGGTGATGAACCAACCTTACGACCACCTGAAGGTTCGCATAATGTTCAACCACTGCCTCAAGAAGAGGTTGGAGATTCACAAGTGCTTCCTCACCTGGACGATATCACTCCACTCACAAGCGATGAACTCGCGTTTCTTTGGGGCGTTTAAATATTTAGTTAAGGTGTATTTAAAACGCTTAGGTGTTATTTCCATTAATAATGTAATTCGAGCTGTGAATCATGTATTGTTCGACCAACTCACAAATGTAATCGAATGCGATTTGCAACATGAAATAAAATTCAACATTTATTAA |
| Protein Sequence | MDSRTKELLTPSEAERGEYIWELNNPLSFKLLREDYGVMNQPYDHLKVRIMFNHCLKKRLEIHKCFLTWTISLHSQAMNSRFFGAFKYLVKVYLKRLGVISINNVIRAVNHVLFDQLTNVIECDLQHEIKFNIY |
| NCBI Accession | YP_009508452.1 |
|---|---|
| Location | 1212-1622 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGCGATATTCTACACCATCAAAGAGCCACTGTTCTCCTCCGAGCATCAAGGCTCAACACAGCAAGGCGAAACGGCAGAGGGCGACTAGGAGACGCCGAATAGATTGTCCGTGCGGGTGCTCGATATACGTACACATCAACTGTAGCCACAATGGATTCACGCACAAAGGAGTTACTCACTCCATCGGAAGCAGAGCGTGGCGAGTATATCTGGGAGCTGAACAATCCCCTGTCTTTCAAACTCCTCCGAGAAGACTATGGGGTGATGAACCAACCTTACGACCACCTGAAGGTTCGCATAATGTTCAACCACTGCCTCAAGAAGAGGTTGGAGATTCACAAGTGCTTCCTCACCTGGACGATATCACTCCACTCACAAGCGATGAACTCGCGTTTCTTTGGGGCGTTTAA |
| Protein Sequence | MRYSTPSKSHCSPPSIKAQHSKAKRQRATRRRRIDCPCGCSIYVHINCSHNGFTHKGVTHSIGSRAWRVYLGAEQSPVFQTPPRRLWGDEPTLRPPEGSHNVQPLPQEEVGDSQVLPHLDDITPLTSDELAFLWGV |
| NCBI Accession | YP_009508453.1 |
|---|---|
| Location | 1534-2610 |
| Gene Name | AC1 |
| Protein Name | Rep |
| Coding Region | ATGCCACGGAGAGGGTCTTTTTGTGTGAAGGCAAAAAATATTTTCCTCACATATCCCAGGTGCGCTCTCACAAAGGAGGAAACACTTTCCCAATTACAAAACATACACTGTTCTTCTAACAAGAAATTTATCAAGATAGCTCGTGAACTACACGAGGATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAGGGAAAGTGTCAAATCACTAACCAGAAACACTTCGACCTCGTATCCCCAGTGCGATCAACACATTACCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAAAAATACATTGATAAAGATGGAGATACCCTAGACTGGGGAACGTTTCAGATCGACGGTCGAAGTGCTAGAGGAGGTTGCCAAAATGCAAACGACACGTGCGCAAATGCATTAAATGCAGGTTCAGCGGAAGCTGCATTAGCCATCATTAAGGAGCAGCTTCCCAAGGATTATATTTTCCAATATCACAATCTCATGGGCAACCTCGAACGCATATTCACACCTAAAACGGCGATATACAAATCGCCCTTTACTGTTGAACAATTTAACAATGTGCCAGAAGTATTAACTCGCTGGGCTGCTGAAAATGTGAAGGATTCCGCTGCGCGGCCGATGAGACCTATAAGCATCGTTCTTGAGGGTGAGTCTAGAACAGGGAAGACCATGTGGGCCAGGGCGTTGGGTAGGCACAATTACCTATGTGGCCATTTGGATCTTAGCGCCAAGGTCTATTCAAACGATGCGTGGTACAACGTAATCGATGACGTAGATCCGCACTATCTAAAGCACCTAAAGGAATTCATGGGGGCCCAGAAGGACTGGCAAAGCAACGTGAAATACGGAAAGCCCACTCAAATTAAAGGAGGCATTCCCACGATATTTCTGTGCAACGCGGGGCCCAAATCTTCCTATAAAGAATATTTGGAAGAGGAGCATAATGCACCGCTAAAGGAGTGGGCAAGCAAGAATGCGATATTCTACACCATCAAAGAGCCACTGTTCTCCTCCGAGCATCAAGGCTCAACACAGCAAGGCGAAACGGCAGAGGGCGACTAG |
| Protein Sequence | MPRRGSFCVKAKNIFLTYPRCALTKEETLSQLQNIHCSSNKKFIKIARELHEDGEPHLHVLIQFEGKCQITNQKHFDLVSPVRSTHYHPNIQGAKSSSDVKKYIDKDGDTLDWGTFQIDGRSARGGCQNANDTCANALNAGSAEAALAIIKEQLPKDYIFQYHNLMGNLERIFTPKTAIYKSPFTVEQFNNVPEVLTRWAAENVKDSAARPMRPISIVLEGESRTGKTMWARALGRHNYLCGHLDLSAKVYSNDAWYNVIDDVDPHYLKHLKEFMGAQKDWQSNVKYGKPTQIKGGIPTIFLCNAGPKSSYKEYLEEEHNAPLKEWASKNAIFYTIKEPLFSSEHQGSTQQGETAEGD |
| NCBI Accession | YP_009508454.1 |
|---|---|
| Location | 2277-2453 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAGGGAAAGTGTCAAATCACTAACCAGAAACACTTCGACCTCGTATCCCCAGTGCGATCAACACATTACCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAAAAATACATTGATAAAGATGGAGATACCCTAG |
| Protein Sequence | MGNHISMCLSSLRESVKSLTRNTSTSYPQCDQHITIRTFRELNQAPTSKNTLIKMEIP |
References More References in PubMed
| 1 |
Desmodium mottle virus, the first legumovirus (genus Begomovirus) from East Africa. Mollel HG, et al. Arch Virol. 2017 Jun;162(6):1799-1803. doi: 10.1007/s00705-017-3289-1. Epub 2017 Feb 27. PMID: 28243802 |
|---|---|
| 2 |
Refined structure of desmodium yellow mottle tymovirus at 2.7 A resolution. Larson SB, et al. J Mol Biol. 2000 Aug 18;301(3):625-42. doi: 10.1006/jmbi.2000.3983. PMID: 10966774 |
| 3 |
Potential Primary Inoculum Sources of Bean pod mottle virus in Iowa. Krell RK, et al. Plant Dis. 2003 Dec;87(12):1416-1422. doi: 10.1094/PDIS.2003.87.12.1416. PMID: 30812381 |
| 4 |
Bradshaw JD, et al. J Econ Entomol. 2007 Jun;100(3):808-14. doi: 10.1603/0022-0493(2007)100[808:npoctc]2.0.co;2. PMID: 17598542 |
| 5 |
Hernández-Zepeda C, et al. Virus Genes. 2007 Dec;35(3):825-33. doi: 10.1007/s11262-007-0149-1. Epub 2007 Aug 8. PMID: 17682933 |
| 6 |
A comparison of certain properties of desmodium yellow mottle and turnip yellow mosaic viruses. Scott HA, et al. Virology. 1972 Nov;50(2):613-4. doi: 10.1016/0042-6822(72)90414-x. PMID: 4629044 |
| 7 |
Complete nucleotide sequence and experimental host range of Okra mosaic virus. Stephan D, et al. Virus Genes. 2008 Feb;36(1):231-40. doi: 10.1007/s11262-007-0181-1. Epub 2007 Nov 30. PMID: 18049886 |
| 8 |
Landscape epidemiology of bean pod mottle comovirus: molecular evidence of heterogeneous sources. Bradshaw JD, et al. Arch Virol. 2011 Sep;156(9):1615-9. doi: 10.1007/s00705-011-1005-0. Epub 2011 May 12. PMID: 21562882 |
| 9 |
Paul HL, et al. Intervirology. 1980;13(2):99-109. doi: 10.1159/000149114. PMID: 7372445 |