Datura leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_004788495.1 |
| Isolate | Sudan |
| Release date | 2019/6/28 |
| Submitter | Mohammed,H.S., El Siddig,M.A., El Hussein,A.A., Navas-Castillo,J., Fiallo-Olive,E., Mohammed,H. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
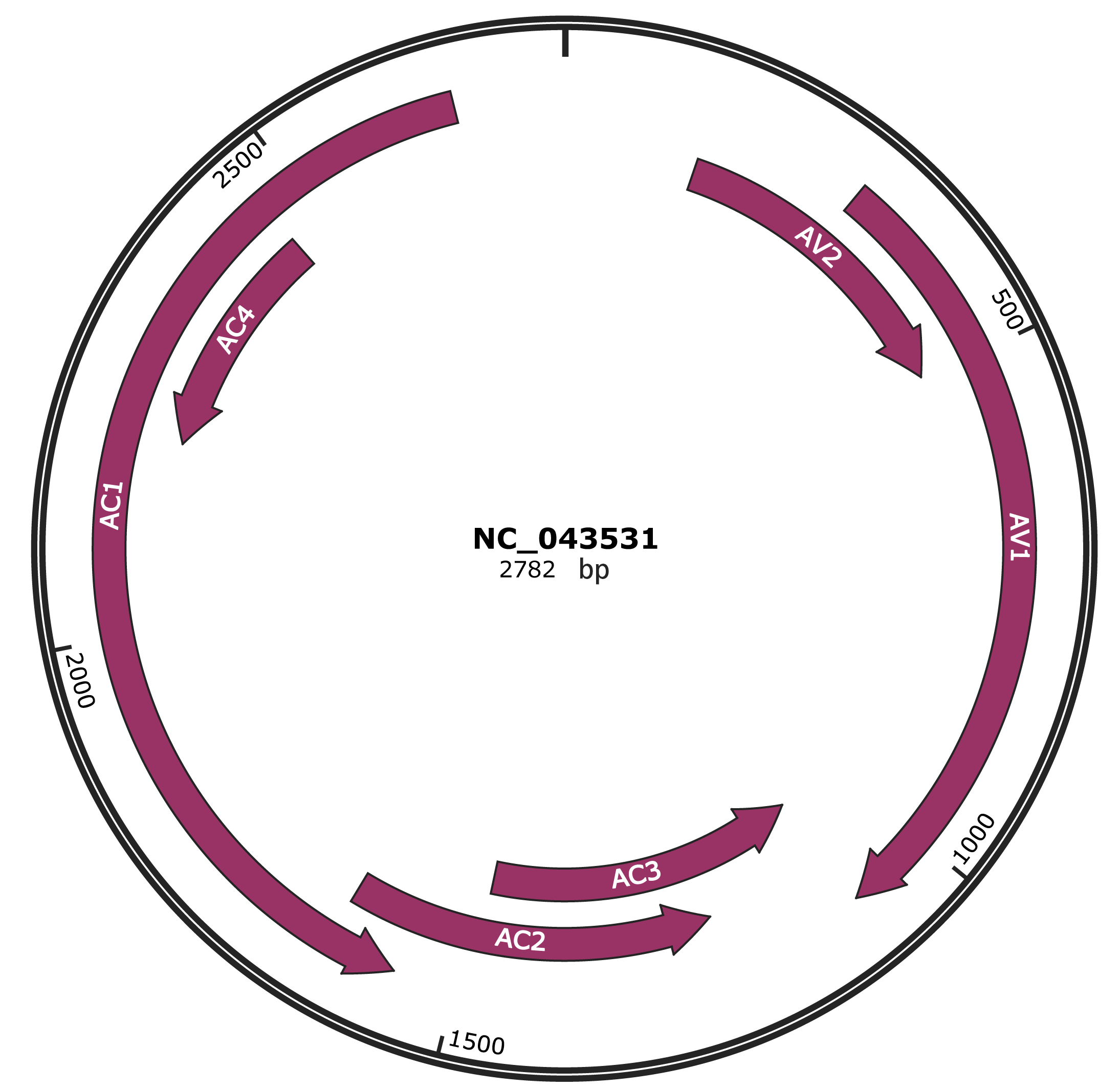
JBrowse
Genome
NC_043531
Gene Information
| NCBI Accession | YP_009666811.1 |
|---|---|
| Location | 147-497 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGACCCACTACTAAATGAATTTCCTGAATCCGTTCACGGATTTCGTTGTATGTTAGCTATTAAATATTTGCAGGCCGTTGAGGAAACGTATGAGCCCAATACTTTGGGCCACGATTTAATTAGGGATCTTATATCTGTTGTTAGGGCCCGTGACTATGTCGAAGCGACCCGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCATTGTCCAAGGCACAAACAGGCGCCGATCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAIKYLQAVEETYEPNTLGHDLIRDLISVVRARDYVEATRRYNHFHARLEGSPKAELRQPIQQPCCCPHCPRHKQAPIMDVQAHVPKAQNIQNVSKP |
| NCBI Accession | YP_009666812.1 |
|---|---|
| Location | 307-1083 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCCGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCATTGTCCAAGGCACAAACAGGCGCCGATCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGATGTTCCCCGTGGATGTGAAGGCCCATGTAAGGTGCAGTCTTATGAGCAACGGGATGATATTAAGCATACTGGTATTGTTCGTTGTGTTAGTGATGTTACTCGTGGATCCGGAATTACCCACAGAGTGGGTAAGAGGTTCTGTGTTAAATCGATATATTTTTTAGGTAAAGTCTGGATGGATGAAAATATCAAGAAGCAGAATCACACTAATCAGGTCATGTTCTTTTTGGTCCGTGATAGAAGGCCCTATGGAAACAGCCCAATGGATTTTGGACAGGTTTTTAATATGTTCGATAATGAGCCCAGTACCGCAACCGTGAAGAATGATTTGCGGGATAGGTTTCAAGTGATGAGGAAATTTCATGCTACAGTCATTGGTGGGCCCTCTGGAATGAAGGAACAGGCTTTAGTTAAGAGATTTTTTAGAATTAACAGTCATGTAACTTATAATCATCAGGAGGCAGCCAAGTACGAGAATCATACTGAAAACGCCTTGTTATTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCAACTATGAAAATACGAATCTATTTTTATGATTCGGTCAGCAATTAA |
| Protein Sequence | MSKRPGDIIISTPVSKVRRRLNFDSPYSSRAAAPIVQGTNRRRSWTYRPMYRKPRIYRMYRSPDVPRGCEGPCKVQSYEQRDDIKHTGIVRCVSDVTRGSGITHRVGKRFCVKSIYFLGKVWMDENIKKQNHTNQVMFFLVRDRRPYGNSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMRKFHATVIGGPSGMKEQALVKRFFRINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATMKIRIYFYDSVSN |
| NCBI Accession | YP_009666813.1 |
|---|---|
| Location | 1080-1484 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCGCTGAATGGCGTCTTTATCTGGGAGGTAACAAATCCCCTCTATTTCAAGATCATCCAGCACGACAACAAATCATTCGGAATGACGATGGACATAATAACCATCCAGATACGATTCAACCACAAGCTGAGGAAAGCGTTGGGACTACACCAATGCTGGATGGATTTCCAGGTCTGGACGACCTTACACCCTCAGACCTGGCATTTCTTGAGGGTATTTAAAACCCAAGTATTAAAATACCTCGATAGTTTAGGGATTATAAGTATTAATACAGTTGTAAAAGCCGTAGAGCATGTATTGTACAATGTACTCGATGGGACTGACAGTGTTGAGCAGTCTAATTTAATAAAATTTAATGTTTATTAA |
| Protein Sequence | MDSRTGELITAAQALNGVFIWEVTNPLYFKIIQHDNKSFGMTMDIITIQIRFNHKLRKALGLHQCWMDFQVWTTLHPQTWHFLRVFKTQVLKYLDSLGIISINTVVKAVEHVLYNVLDGTDSVEQSNLIKFNVY |
| NCBI Accession | YP_009666814.1 |
|---|---|
| Location | 1225-1632 |
| Gene Name | AC2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCAACCTTCATCTCCCTCGAAGAGCCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAGAGCCATCCGGCGTAAGAGGGTTGATCTAAATTGTGGGTGCTCATACTACGTACACATCAACTGCCACAACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCGCTGAATGGCGTCTTTATCTGGGAGGTAACAAATCCCCTCTATTTCAAGATCATCCAGCACGACAACAAATCATTCGGAATGACGATGGACATAATAACCATCCAGATACGATTCAACCACAAGCTGAGGAAAGCGTTGGGACTACACCAATGCTGGATGGATTTCCAGGTCTGGACGACCTTACACCCTCAGACCTGGCATTTCTTGAGGGTATTTAA |
| Protein Sequence | MQPSSPSKSHYTQVPIKVQHRAAKRRAIRRKRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSSAEWRLYLGGNKSPLFQDHPARQQIIRNDDGHNNHPDTIQPQAEESVGTTPMLDGFPGLDDLTPSDLAFLEGI |
| NCBI Accession | YP_009666815.1 |
|---|---|
| Location | 1562-2674 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGGGCACCCAAAGCCCCCAATTCCCACAGAGTTTCGAGAGCACCCAATTCAATATGCCACGTGTTAATTCCTTCCAAGTTAAAGCAAAAAACATATTCCTTACATATCCAAAATGCCCAATCCCAAAAGAGCAAATGCTCGAACTCATCAAATCCATACACTGTCCATCAGATAAATTATTTATCCGAGTGGCACAAGAAAAACACCAAGATGGGTCTCTGCATATCCATGCTCTCATCCAGTTCAAGGGTAAGGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTCATAACTCCTCCCAATTCCACCCAAATTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCATACATCGAGAAGGACGGTGATTACATCGACTGGGGTCAATTTCAGGTCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTGAATTCAGGTTCCGCTGATGTTGCTCTGGCAATAATTAGGGAGAAACTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAAAATAATTTAGATAGGATTTTTGCACCTCCAAAGGAGGTTTATGTTTCCCCTTTTCTTTCTTCTTCCTTTGATCAAGTTCCAGAGGCCATAGAGGAATGGGTGTCTGAGAATGTCATGGATGCCGCTGCGCGGCCATGGAGACCTAATAGTATTGTCATCGAGGGTGATAGCAGAACCGGCAAAACAATGTGGGCCAGGTCTCTAGGCCCACATAATTATTTGTGTGGACATCTAGACCTAAGTCCAAAGGTGTACAGTAATGATGCGTGGTACAATGTAATTGATGACGTAGACCCGCATTATTTAAAGCACTTCAAGGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACAAAGTACGGGAAGCCCATTCAAATTAAAGGGGGAATTCCAACTATCTTCCTCTGCAATCCAGGGCCCAATTCCAGCTATAAAGAGTTCCTGGACGAAGAAAAGAATTGCGCATTAAAAGCCTGGGCACTAAAAAATGCAACCTTCATCTCCCTCGAAGAGCCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAA |
| Protein Sequence | MGTQSPQFPQSFESTQFNMPRVNSFQVKAKNIFLTYPKCPIPKEQMLELIKSIHCPSDKLFIRVAQEKHQDGSLHIHALIQFKGKAQFRNPRHFDVTHPHNSSQFHPNFQGAKSSSDVKSYIEKDGDYIDWGQFQVDGRSARGGQQTANDAAAEALNSGSADVALAIIREKLPKDFIFQYHNLKNNLDRIFAPPKEVYVSPFLSSSFDQVPEAIEEWVSENVMDAAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPNSSYKEFLDEEKNCALKAWALKNATFISLEEPLYSGTNQGPTQSC |
| NCBI Accession | YP_009666816.1 |
|---|---|
| Location | 2206-2463 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGTCTCTGCATATCCATGCTCTCATCCAGTTCAAGGGTAAGGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTCATAACTCCTCCCAATTCCACCCAAATTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCATACATCGAGAAGGACGGTGATTACATCGACTGGGGTCAATTTCAGGTCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTGA |
| Protein Sequence | MGLCISMLSSSSRVRPSSETPDISMSLTLITPPNSTQISRELSPHPMSSHTSRRTVITSTGVNFRSMEDLLEEVNRQLMMLQQRP |
References More References in PubMed
| 1 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
|---|---|
| 2 |
Devaraj, et al. 3 Biotech. 2025 Aug;15(8):260. doi: 10.1007/s13205-025-04434-y. Epub 2025 Jul 19. PMID: 40693173 |
| 3 |
Mohammed HS, et al. Arch Virol. 2018 Jan;163(1):273-275. doi: 10.1007/s00705-017-3574-z. Epub 2017 Oct 4. PMID: 28980080 |
| 4 |
Biolistic inoculation of plants with tomato yellow leaf curl virus DNA. Lapidot M, et al. J Virol Methods. 2007 Sep;144(1-2):143-8. doi: 10.1016/j.jviromet.2007.04.011. Epub 2007 Jun 15. PMID: 17573131 |
| 5 |
Natural Hosts and Genetic Diversity of the Emerging Tomato Leaf Curl New Delhi Virus in Spain. Juárez M, et al. Front Microbiol. 2019 Feb 20;10:140. doi: 10.3389/fmicb.2019.00140. eCollection 2019. PMID: 30842757 |
| 6 |
Chen LF, et al. Mol Plant Pathol. 2009 May;10(3):415-30. doi: 10.1111/j.1364-3703.2009.00541.x. PMID: 19400843 |
| 7 |
Three years survey of Tomato yellow leaf curl Sardinia virus reservoir weed hosts in southern Italy. Fanigliulo A, et al. Commun Agric Appl Biol Sci. 2007;72(4):1023-8. PMID: 18396845 |
| 8 |
Prasanth G, et al. Plant Dis. 2008 Feb;92(2):311. doi: 10.1094/PDIS-92-2-0311B. PMID: 30769415 |
| 9 |
A Novel Strain of the Begomovirus Tomato Leaf Curl Sudan Virus Infecting Datura stramonium in Sudan. Mohammed HS, et al. Plant Dis. 2018 Sep;102(9):1863. doi: 10.1094/PDIS-01-18-0195-PDN. Epub 2018 Jul 6. PMID: 30125192 |
| 10 |
Current Status and New Natural Hosts of Tomato yellow leaf curl virus (TYLCV) in Spain. Jordá C, et al. Plant Dis. 2001 Apr;85(4):445. doi: 10.1094/PDIS.2001.85.4.445C. PMID: 30831991 |