Dalechampia chlorotic mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000900175.1 |
| Isolate |
Venezuela |
| Release date |
2015/2/22 |
| Submitter |
Fiallo-Olive,E., Chirinos,D.T., Geraud-Pouey,F., Moriones,E., Navas-Castillo,J., Chirinos,D. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
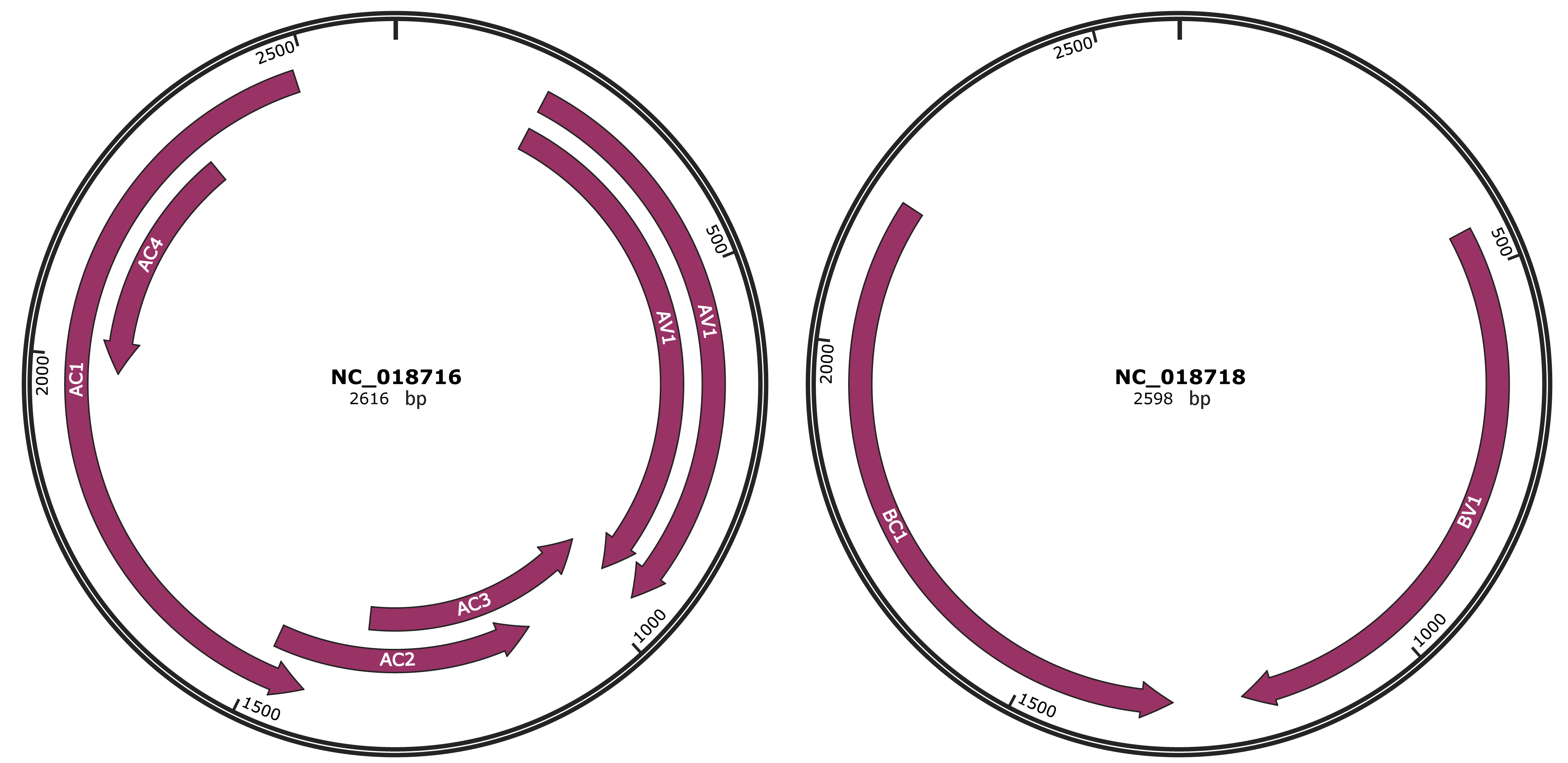
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTCGCTTGGGCCCGGCCCAGGTCCAAGCGCTCTCGTTTTTATTTGATTCCTCTCTGGGACCACTTAAATACTCTTGACCAATCATATTGCGTCTGACGCGCCTACATATTTTGACTTGCTGACTAAGTAGTGGTCCCTTGTATTTAAGTGATATTGACAGAGCGTTTAATTTAATTTGAAAATGCCTAAGCGGGATATCCCATGGCGTTCAATGGCGGGAACTTCAAAGGTTAGCCGCTCTGTCAATCGTTCCCCTCGTGGTGGATCGGGCCCTAAGTTTGACAAGGCCTCAGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGAACGTTGAGAGGGCCCGATGTCCCCAAGGGATGTGAAGGTCCATGTAAGGTTCAGTCATACGAGCAGCGACATGACATCTCTCATGTTGGCAAGGTCATGTGTATATCTGACGTGACACGTGGTAACGGTATAACCCATCGTGTTGGTAAGCGTTTCTGTGTTAAGTCTGTATATATTCTTGGGAAGATATGGATGGATGAGAATATCAAGCTGAAGAACCACACGAACAGCGTCATGTTTTGGCTTGTTCGAGACCGGAGACCCTATGGAACCCCTATGGACTTTGGTCAAGTCTTCAACATGTTCGACAACGAGCCTAGTACTGCTACTGTTAAGAACGATCTGCGTGATCGTTATCAGGTGATGCACAGGTTCTATGCTAAGGTCACTGGTGGACAGTACGCAAGCAACGAGCAGGCATTGGTTAGGCGCTTCTGGAAGGTCAACAACTACGTGGTATACAACCATCAGGAAGCAGGGAAATACGAGAATCATACGGAGAACGCCTTGTTATTGTATATGGCATGTACTCATGCATCAAACCCTGTGTATGCAACTTTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAATTTTGAATTTTATATCATGATTCTCGAGTACAGCATTTACATATGGTCTATTAACGGCGAAGCTAACAGCATCAATTACATGATTAATACCAATTACTCCTAACCTATCTAAGTACAACAACACTAAATGTCTAAACCTATTTAAATAAATCTGCCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGTTGAAGAAGGCTCTGAGAAGACCCAATTCCTTCCTCAGGTTGTGGTTGAACCTGATCTGGATGTGGTACACTCTGTTCCTGGTGTACATAGGATCCTCTACTCTGGTGATCTTGAAATAGAGGGGATTTGGAACCTCCCAAATAAAAACGGAATTCTCTGCCTGAGCCGCAGTGATGCTCTCCCCGGTGCGTGAATCCATGGTCTATGCAGTTGATGTGGAGAAATATGGAACAGCCGCAGTTCAAGTCGAGTCGCCTTCTACGTATGGCTCTTCTTTTACTGGCTCTGTGCTGTGCCTTGATAGAGGGGGGCTTCGAGGAAGACGAATTTCGCATTTTTAAGCGTCCACGCCTTCAGACCTGCATTTTCCTCTTTCTCGAGGAAATCTTTATAGCTGCACCCCTCTCCTGGATTGCACAGCACGATTGATGGGATCCCTCCTTTAATTTGAACTGGCTTTCCATATTTACAGTTGGATTGCCAATCCTTTTGGGCCCCAATCAACTCTTTCCAGTGCTTTAGCTTTAGGTACTGCGGAGTGACATCATCGATAACGTTATACTCCACATCATTGGAGTAAACCCTAGCATTGAAATCAAGATGACCGCTCAGATAATTATGTGTACCTAAAGCTCTGGCCCACATTGTCTTTCCCGTTCTAGAACCCCCTTCGACGATCAAACTAATAGGACGTTCTGGCCGCGCAGCGGCATCAACACTGAAATAGTCATCAGCCCATTCTTGCATCTCGTCTGGCACAGCAGTAAATGAAGATAGCTGAAATGGAGGGACCCACGGAGGTGGAGGTTTAGCAAATATACGTTCTAGGTTTGAACGTAACGTGTGCTGCTGGAGCACGAAGTCTTTGGGCTGCTCTTCTCTGAGTATATTGAGGGCCTCGGAGACAGAGTTTGAGTTGAGAACCTTGGCATAGGAGTCATTGGCAGATTGTTGACCTCCTCTGGAGGAACGGGGATCGATTTGAAATTCTCCAAAATCAATGAAGTCTCCGTCTTTCTCCACGTAGGTCTTGACATCAGATGCTGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGAGACGAGGTCGAAGAATCTTTCATTAGCACATTGGTATTTACCTTCGAACTGGATAAGCACATGGAGATGAGGCTCCCCATTTTCGTGTAATTCTCTGGACACACGAATAAACTTGATATTTGTAGGTGTTTTTAACTTCTGTAATTGCAAAAGAGCCCCTTCTTTTGTTAAAGAGCACCTAGGGTATGTGAGGAAATAGTTTTTGGCGTTTATGCGAAATTTACGAGGAGGCCCCATAACTTTCAATATTTGCAAAACGAACCGGTGTATAGAAAACTGGCTGATATGAACTGGTGTATGGTGTGCTACTTATAGAAGTCCTCTCTATTTCATTTGTAGGGGCATTTTCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCTGTTTTTGGTTTCTCGGCCCAGGCCCAGGCGCGCGTGTTTCTCTTGGGCCCGGCCCTGGTCCAAGCGCTGCTATATTGCTGCCCAATCATATGATGTCTGAGGAGGCTGTGTATTAAGAACTTCGCAGCAAAGGCGTGGTGGTCCCTTTTCTTTGGTGACTGTGCACTGTCATTTTCAGTGTCTGACTTTAATTTAAATATCTTGGCGCTCTTTTGTAATCAGCTGTTATACACGTGTCAGCCTAACTTTGGGCAAATGGCGAAAATGACAGGACATATTTTCAGTGCGTTTTACTTCGAGGAGCATTAACCAATTGCATTTGGAGGAGAATGTTTAACTAATTCATTTAAGCACCGTCAGTTAATATTTAAGAACGCACTGATGGAAATGGATATCATGTTAGCAACAGTTTAGGAAGTGCATTTTAAACATGTATCCATCTAGATATAGACGTGGTTGGTCGTCTACCCAACGACGTGGTTATTCTCGACAGTCATTGATGAAACGTTCATATGATGTGAAACGTATGGATGGGAGACGACAGCATAGTAATTCAAACAAGGGCCGTGATGAGTCAAAGCTTTCACTTCAACGGATTCATGAAGACCAGTTTGGGCCAGGATTTGTAATGAGCCATAACACGGCCCTGTCCACATTCATCACGTTCCCCAGTCTAGGAAGAAATGGATCCAGCCGAACAAGGTCCTATATTAAATTAAGGCGTTTACGTTACAAGGGGACTCTGAAGATCGAGCGTGAGCATGGCGATGTCAACATGGATGCTCCCACTCCTAAGATTGAAGGTGTATTTTCTATGGTTATCGTGGTTGATCGTAAACCACATTTGAATCCATCTGGGACTCTGCACTCATTTGATGAGTTATTTGGAGCAAGGATTCATAGCCATGGTAATTTAGCAATCAGTACTGCATTGAAGGATCGTTTCTATATAAGGCATGTCTTGAAACGTGTCATATCAGTTGACAAGGACTCCTTAATGGTTGACCTTGAGGGCACGACGACCTTGTCCAACAGGCGTTTTACTTGTTGGTCTTCTTTTAAAGATTTAGAACGTGATGCATGTACTGGTGTTTATGCAAATATAAGCAAGAACGCCTTACTAGTCTACTACTGCTGGATGTCGGATGCTATGTCTAAGGCATCAACATTTGTATCGTTTGACCTTGATTATATTGGATAAGTTAGCTAGATTTGTATAACTTCAATGACACATCTGTAATAACTATCAATGATTAAACTCAAAATAGAAATAAAATATCCCATATTTTATTTATCTCAATGATTTCGGTATCGAAGGAGAACAGTTTGTGTTAATACACTCCTGTACCGCTGTCCTCACAATCTCGTTTAACTGGGACATGGACATGGTTATGTTGGATTGTGTTCTCTGGAGTCCAACGACTGAGGCAGACTCTCCTGGGTCTAATATTGGCGTCGATAATCTGTTTAGCTCTCTGTATGGACGGGAAGCGTCTGTAATATCCGTATCCACAGTCGAATGGGCTTGTCCTATTGCACTCCTTGAGGCCCATGACTCTCCTGGCCCTATTTCTATTGGGCCGTTGTAGCCATGTTTCGAACAGGATGTGGATCGGATCATTCTTCTCTCCCATTTTCCATAGCCCACGTGAGCAAAATCGACATCCTTGTCTGTAAACTGTTTGGACAGGATCTTCACTGTTGGTGCTCGGAATGGGATATCCACTGAATGTTTAGCTGTAGACAGTTTCAGCTTACCCTTGAATTTTGCGAAGTGGGTTGCTTGGTGAACATTTGAATCGCTAACCCTGTAATATAGCTTCCATGGAATTGGGTCTTTGAGAGAGAAGAATGAGGAAGAGAAATAGTGGAGATCTATGTTACACCTGATTGGGAAAGTCCACGACGCCTGTAAGGATTCATTGTCCGTCATCCTTTTGTCGTGAATCTCCACTATTACAGTTCCAGCAGCGTTAATGGGTACTTGCTGTCTGTATTCTATCACGCAATGGTCGATTTTCATACAACTACGACTGAGCCTAGCAGTTAATTGAGCTGCTGTAGAAGGAAACTGCAAGACGATCTCAGTTAGGTCATGAGACAGCTGATACTCATCTCTATGCGATTCTATATAGTTAAATGCGTTCGGCGCAACTGCCAACTGAGACTCCATTTATGGAAATACTGTCCGCGCAGCGGCACTGTTTCCGGTGATAAACTGGAGAGACTGTTTATCGAGGGAGATAACCTTCTTCTGGAAGTTTAGAGCTGAGTCTGATTTATGAGGGGGAGAGATGTGATATCTTATAAATTTCAGGAGAATAGGAGAGATTAGTACAAAAATAATTATTTAGCACTGGGAAGTATCAACATCACTGATGACAGGCTTATTTATAGAGGAAGGCAGGTTAAACGACGTCGAATGGCAAAATAGCAATTTTAGTCCCTCACACCAGTGCACATTTACCAAACCAACTGGTGTATGGAAAACTGGCTGATATGAACTGGTGTATGGTGTGCTACTTATAGAAGTCCTCTCTATTTCATTTGTAGGGGCATTTTCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_006860596.1
|
|
Location
|
202-957 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATATCCCATGGCGTTCAATGGCGGGAACTTCAAAGGTTAGCCGCTCTGTCAATCGTTCCCCTCGTGGTGGATCGGGCCCTAAGTTTGACAAGGCCTCAGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGAACGTTGAGAGGGCCCGATGTCCCCAAGGGATGTGAAGGTCCATGTAAGGTTCAGTCATACGAGCAGCGACATGACATCTCTCATGTTGGCAAGGTCATGTGTATATCTGACGTGACACGTGGTAACGGTATAACCCATCGTGTTGGTAAGCGTTTCTGTGTTAAGTCTGTATATATTCTTGGGAAGATATGGATGGATGAGAATATCAAGCTGAAGAACCACACGAACAGCGTCATGTTTTGGCTTGTTCGAGACCGGAGACCCTATGGAACCCCTATGGACTTTGGTCAAGTCTTCAACATGTTCGACAACGAGCCTAGTACTGCTACTGTTAAGAACGATCTGCGTGATCGTTATCAGGTGATGCACAGGTTCTATGCTAAGGTCACTGGTGGACAGTACGCAAGCAACGAGCAGGCATTGGTTAGGCGCTTCTGGAAGGTCAACAACTACGTGGTATACAACCATCAGGAAGCAGGGAAATACGAGAATCATACGGAGAACGCCTTGTTATTGTATATGGCATGTACTCATGCATCAAACCCTGTGTATGCAACTTTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDIPWRSMAGTSKVSRSVNRSPRGGSGPKFDKASAWVNRPMYRKPRIYRTLRGPDVPKGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYAKVTGGQYASNEQALVRRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_006860597.1
|
|
Location
|
954-1352 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGAGCATCACTGCGGCTCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCACCAGAGTAGAGGATCCTATGTACACCAGGAACAGAGTGTACCACATCCAGATCAGGTTCAACCACAACCTGAGGAAGGAATTGGGTCTTCTCAGAGCCTTCTTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGCAGATTTATTTAAATAGGTTTAGACATTTAGTGTTGTTGTACTTAGATAGGTTAGGAGTAATTGGTATTAATCATGTAATTGATGCTGTTAGCTTCGCCGTTAATAGACCATATGTAAATGCTGTACTCGAGAATCATGATATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGESITAAQAENSVFIWEVPNPLYFKITRVEDPMYTRNRVYHIQIRFNHNLRKELGLLRAFFNFQVWTTSLTASGQIYLNRFRHLVLLYLDRLGVIGINHVIDAVSFAVNRPYVNAVLENHDIKFKIY |
|
NCBI Accession
|
YP_006860598.1
|
|
Location
|
1099-1488 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGAAATTCGTCTTCCTCGAAGCCCCCCTCTATCAAGGCACAGCACAGAGCCAGTAAAAGAAGAGCCATACGTAGAAGGCGACTCGACTTGAACTGCGGCTGTTCCATATTTCTCCACATCAACTGCATAGACCATGGATTCACGCACCGGGGAGAGCATCACTGCGGCTCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCACCAGAGTAGAGGATCCTATGTACACCAGGAACAGAGTGTACCACATCCAGATCAGGTTCAACCACAACCTGAGGAAGGAATTGGGTCTTCTCAGAGCCTTCTTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGCAGATTTATTTAAATAG |
|
Protein Sequence
|
MRNSSSSKPPSIKAQHRASKRRAIRRRRLDLNCGCSIFLHINCIDHGFTHRGEHHCGSGREFRFYLGGSKSPLFQDHQSRGSYVHQEQSVPHPDQVQPQPEEGIGSSQSLLQLPSLDDFSDSFWADLFK |
|
NCBI Accession
|
YP_006860599.1
|
|
Location
|
1430-2485 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGGGCCTCCTCGTAAATTTCGCATAAACGCCAAAAACTATTTCCTCACATACCCTAGGTGCTCTTTAACAAAAGAAGGGGCTCTTTTGCAATTACAGAAGTTAAAAACACCTACAAATATCAAGTTTATTCGTGTGTCCAGAGAATTACACGAAAATGGGGAGCCTCATCTCCATGTGCTTATCCAGTTCGAAGGTAAATACCAATGTGCTAATGAAAGATTCTTCGACCTCGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAGCATCTGATGTCAAGACCTACGTGGAGAAAGACGGAGACTTCATTGATTTTGGAGAATTTCAAATCGATCCCCGTTCCTCCAGAGGAGGTCAACAATCTGCCAATGACTCCTATGCCAAGGTTCTCAACTCAAACTCTGTCTCCGAGGCCCTCAATATACTCAGAGAAGAGCAGCCCAAAGACTTCGTGCTCCAGCAGCACACGTTACGTTCAAACCTAGAACGTATATTTGCTAAACCTCCACCTCCGTGGGTCCCTCCATTTCAGCTATCTTCATTTACTGCTGTGCCAGACGAGATGCAAGAATGGGCTGATGACTATTTCAGTGTTGATGCCGCTGCGCGGCCAGAACGTCCTATTAGTTTGATCGTCGAAGGGGGTTCTAGAACGGGAAAGACAATGTGGGCCAGAGCTTTAGGTACACATAATTATCTGAGCGGTCATCTTGATTTCAATGCTAGGGTTTACTCCAATGATGTGGAGTATAACGTTATCGATGATGTCACTCCGCAGTACCTAAAGCTAAAGCACTGGAAAGAGTTGATTGGGGCCCAAAAGGATTGGCAATCCAACTGTAAATATGGAAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTGTGCAATCCAGGAGAGGGGTGCAGCTATAAAGATTTCCTCGAGAAAGAGGAAAATGCAGGTCTGAAGGCGTGGACGCTTAAAAATGCGAAATTCGTCTTCCTCGAAGCCCCCCTCTATCAAGGCACAGCACAGAGCCAGTAA |
|
Protein Sequence
|
MGPPRKFRINAKNYFLTYPRCSLTKEGALLQLQKLKTPTNIKFIRVSRELHENGEPHLHVLIQFEGKYQCANERFFDLVSPTRSAHFHPNIQGAKSASDVKTYVEKDGDFIDFGEFQIDPRSSRGGQQSANDSYAKVLNSNSVSEALNILREEQPKDFVLQQHTLRSNLERIFAKPPPPWVPPFQLSSFTAVPDEMQEWADDYFSVDAAARPERPISLIVEGGSRTGKTMWARALGTHNYLSGHLDFNARVYSNDVEYNVIDDVTPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGCSYKDFLEKEENAGLKAWTLKNAKFVFLEAPLYQGTAQSQ |
|
NCBI Accession
|
YP_006860600.1
|
|
Location
|
1978-2328 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTTATCCAGTTCGAAGGTAAATACCAATGTGCTAATGAAAGATTCTTCGACCTCGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAGCATCTGATGTCAAGACCTACGTGGAGAAAGACGGAGACTTCATTGATTTTGGAGAATTTCAAATCGATCCCCGTTCCTCCAGAGGAGGTCAACAATCTGCCAATGACTCCTATGCCAAGGTTCTCAACTCAAACTCTGTCTCCGAGGCCCTCAATATACTCAGAGAAGAGCAGCCCAAAGACTTCGTGCTCCAGCAGCACACGTTACGTTCAAACCTAG |
|
Protein Sequence
|
MGSLISMCLSSSKVNTNVLMKDSSTSSPQPGQHISIQTFRELNQHLMSRPTWRKTETSLILENFKSIPVPPEEVNNLPMTPMPRFSTQTLSPRPSIYSEKSSPKTSCSSSTRYVQT |
|
NCBI Accession
|
YP_006860606.1
|
|
Location
|
447-1217 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCATCTAGATATAGACGTGGTTGGTCGTCTACCCAACGACGTGGTTATTCTCGACAGTCATTGATGAAACGTTCATATGATGTGAAACGTATGGATGGGAGACGACAGCATAGTAATTCAAACAAGGGCCGTGATGAGTCAAAGCTTTCACTTCAACGGATTCATGAAGACCAGTTTGGGCCAGGATTTGTAATGAGCCATAACACGGCCCTGTCCACATTCATCACGTTCCCCAGTCTAGGAAGAAATGGATCCAGCCGAACAAGGTCCTATATTAAATTAAGGCGTTTACGTTACAAGGGGACTCTGAAGATCGAGCGTGAGCATGGCGATGTCAACATGGATGCTCCCACTCCTAAGATTGAAGGTGTATTTTCTATGGTTATCGTGGTTGATCGTAAACCACATTTGAATCCATCTGGGACTCTGCACTCATTTGATGAGTTATTTGGAGCAAGGATTCATAGCCATGGTAATTTAGCAATCAGTACTGCATTGAAGGATCGTTTCTATATAAGGCATGTCTTGAAACGTGTCATATCAGTTGACAAGGACTCCTTAATGGTTGACCTTGAGGGCACGACGACCTTGTCCAACAGGCGTTTTACTTGTTGGTCTTCTTTTAAAGATTTAGAACGTGATGCATGTACTGGTGTTTATGCAAATATAAGCAAGAACGCCTTACTAGTCTACTACTGCTGGATGTCGGATGCTATGTCTAAGGCATCAACATTTGTATCGTTTGACCTTGATTATATTGGATAA |
|
Protein Sequence
|
MYPSRYRRGWSSTQRRGYSRQSLMKRSYDVKRMDGRRQHSNSNKGRDESKLSLQRIHEDQFGPGFVMSHNTALSTFITFPSLGRNGSSRTRSYIKLRRLRYKGTLKIEREHGDVNMDAPTPKIEGVFSMVIVVDRKPHLNPSGTLHSFDELFGARIHSHGNLAISTALKDRFYIRHVLKRVISVDKDSLMVDLEGTTTLSNRRFTCWSSFKDLERDACTGVYANISKNALLVYYCWMSDAMSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_006860607.1
|
|
Location
|
1308-2189 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAGTCTCAGTTGGCAGTTGCGCCGAACGCATTTAACTATATAGAATCGCATAGAGATGAGTATCAGCTGTCTCATGACCTAACTGAGATCGTCTTGCAGTTTCCTTCTACAGCAGCTCAATTAACTGCTAGGCTCAGTCGTAGTTGTATGAAAATCGACCATTGCGTGATAGAATACAGACAGCAAGTACCCATTAACGCTGCTGGAACTGTAATAGTGGAGATTCACGACAAAAGGATGACGGACAATGAATCCTTACAGGCGTCGTGGACTTTCCCAATCAGGTGTAACATAGATCTCCACTATTTCTCTTCCTCATTCTTCTCTCTCAAAGACCCAATTCCATGGAAGCTATATTACAGGGTTAGCGATTCAAATGTTCACCAAGCAACCCACTTCGCAAAATTCAAGGGTAAGCTGAAACTGTCTACAGCTAAACATTCAGTGGATATCCCATTCCGAGCACCAACAGTGAAGATCCTGTCCAAACAGTTTACAGACAAGGATGTCGATTTTGCTCACGTGGGCTATGGAAAATGGGAGAGAAGAATGATCCGATCCACATCCTGTTCGAAACATGGCTACAACGGCCCAATAGAAATAGGGCCAGGAGAGTCATGGGCCTCAAGGAGTGCAATAGGACAAGCCCATTCGACTGTGGATACGGATATTACAGACGCTTCCCGTCCATACAGAGAGCTAAACAGATTATCGACGCCAATATTAGACCCAGGAGAGTCTGCCTCAGTCGTTGGACTCCAGAGAACACAATCCAACATAACCATGTCCATGTCCCAGTTAAACGAGATTGTGAGGACAGCGGTACAGGAGTGTATTAACACAAACTGTTCTCCTTCGATACCGAAATCATTGAGATAA |
|
Protein Sequence
|
MESQLAVAPNAFNYIESHRDEYQLSHDLTEIVLQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINAAGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDSNVHQATHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFAHVGYGKWERRMIRSTSCSKHGYNGPIEIGPGESWASRSAIGQAHSTVDTDITDASRPYRELNRLSTPILDPGESASVVGLQRTQSNITMSMSQLNEIVRTAVQECINTNCSPSIPKSLR |