Cucurbit leaf crumple virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000837305.1 |
| Isolate | USA: Imperial Valley of California |
| Release date | 2015/2/12 |
| Submitter | Guzman,P., Sudarshana,M.R., Seo,Y.-S., Rojas,M.R., Natwick,E., Turini,T., Mayberry,K., Gilbertson,R.L., Hernandez,N.A. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
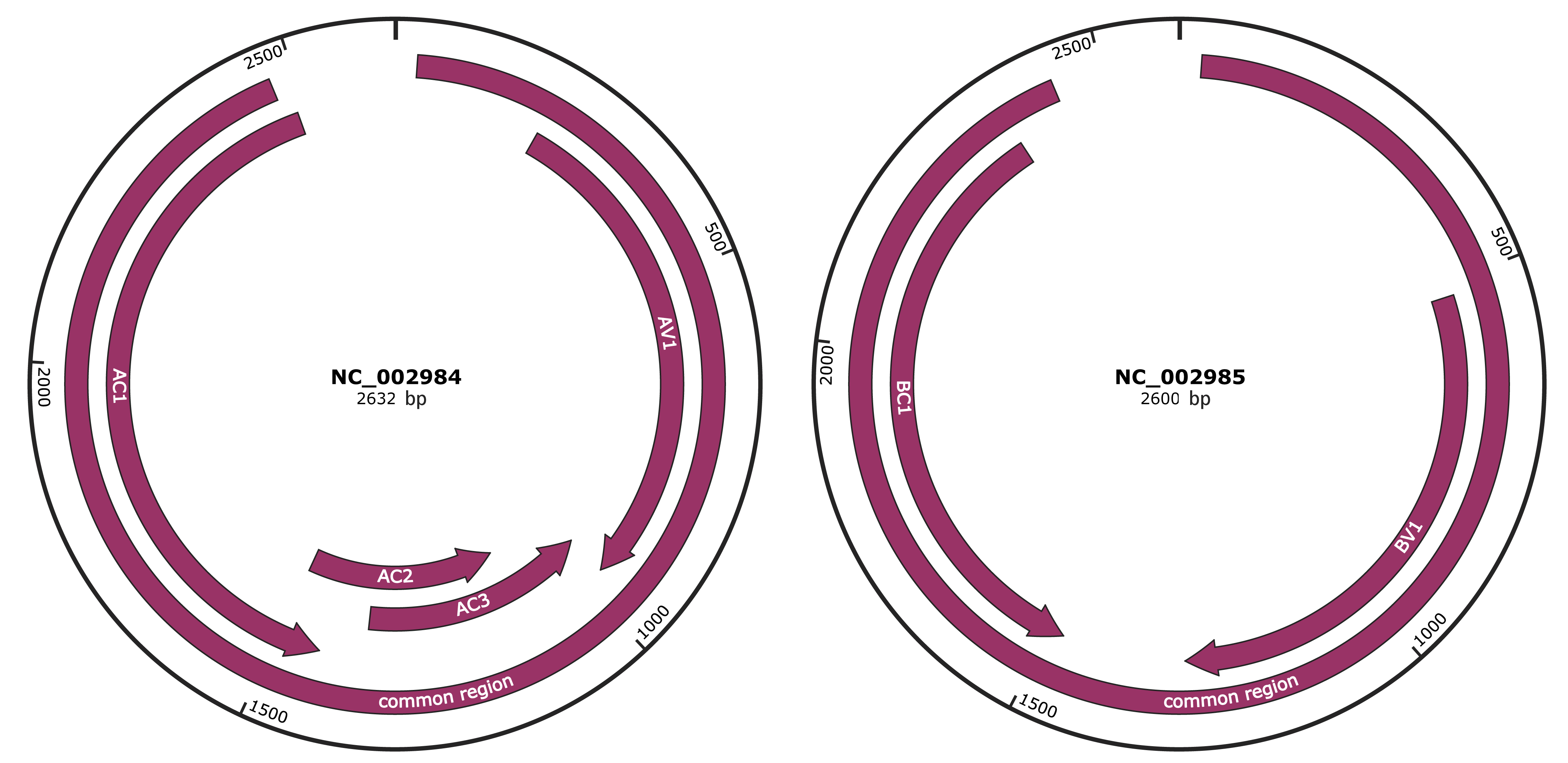
JBrowse
Genome
NC_002984
NC_002985
Gene Information
| NCBI Accession | NP_148985.1 |
|---|---|
| Location | 217-966 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCGAAGCGCGATGCCCCATGGCGTTCATTGGCGGGGACCTCAAAGGTTTCCCGCTCTGCTAACTATACTCCACGTGGAGGTCCTAAATTGGACAAGGCCGCTGTGTGGGTCAACCGGCCCATGTACCGGAAGCCCAGGATCTATCGGACATTCAAGAGTCCCGATGTTCCCAAGGGTTGTGAAGGGCCGTGTAAGGTTCAGTCTTTCGAGCAGCGGCATGATATATCTCATGTTGGGAAGGTGATGTGCATATCTGACGTGACCCGTGGTAACGGTATTACTCATCGCGTGGGGAAACGTTTTTGTGTTAAGTCTGTATATATTTTAGGGAAGATCTGGATGGACGAAAACATCAAGTTGAAGAACCACACTAACAGCGTTATTTTCTGGTTGGTAAGAGACCGTCGACCGTATAGTTCTCCTATGGATTTCGGCCAAGTGTTCAACATGTTCGACAACGAGCCTAGTACTGCAACCGTTAAGAACGATCTCCGCGATCGTTTTCAAGTGATGCACAGGTTCTATGCAAAGGTCACTGGTGGTCAATATGCGAGCAACGAGCAAGCCTTAGTTAGGCGATTTTGGAAGGTCAACAACCACGTAGTCTACAACCACCAGGAAGCAGGAAAATACGAAAATCATACTGAGAACGCTTTGTTATTGTATATGGCATGTACGCATGCCTCTAACCCCGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWRSLAGTSKVSRSANYTPRGGPKLDKAAVWVNRPMYRKPRIYRTFKSPDVPKGCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPYSSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_148986.1 |
|---|---|
| Location | 963-1361 |
| Gene Name | AC3 |
| Protein Name | Ren protein |
| Coding Region | ATGGATTCACGCACAGAGGAACGCATCACGCGGTTTCAGGCAGAGAATTCCGCTTTTATCTGGGACGTTCCAAATCCCCTCTATTTCAAGATGTACAACGTAGAGGACCCAATCTACACAACAACGAGGATATTCCACATCCAGATCAGATTCAACCACAACCTCAGGAGAGCACTAAATCTTCACAAAGCATTCCTGAACTTCCAAATCTGGACGACATTACGTCAAGTTTCTGGGACGACTTATTTAAAATGGTTTAAACATTTAGTGCTTCTGTATTTAGATAGATTAGGTGTTGTTGGACTGAATAATGTAATACGAGCTGTTGTATTTGCAACTGATAAACCATATGTAAACTATGTACTCGAAAATCATGATATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTEERITRFQAENSAFIWDVPNPLYFKMYNVEDPIYTTTRIFHIQIRFNHNLRRALNLHKAFLNFQIWTTLRQVSGTTYLKWFKHLVLLYLDRLGVVGLNNVIRAVVFATDKPYVNYVLENHDIKFKFY |
| NCBI Accession | NP_148987.1 |
|---|---|
| Location | 1102-1497 |
| Gene Name | AC2 |
| Protein Name | TrAP protein |
| Coding Region | ATGCCCAGTTCATCTTCCTCGAAGGCCCCCTCTATCAAAGCACAGCACAGAGCAGCGAAGACTAGAGCCATCCGGCGTCGACGAATAGACTTGGACTGCGGTTGTTCAATATACCTGCATTTGAACTGTGCTGATTATGGATTCACGCACAGAGGAACGCATCACGCGGTTTCAGGCAGAGAATTCCGCTTTTATCTGGGACGTTCCAAATCCCCTCTATTTCAAGATGTACAACGTAGAGGACCCAATCTACACAACAACGAGGATATTCCACATCCAGATCAGATTCAACCACAACCTCAGGAGAGCACTAAATCTTCACAAAGCATTCCTGAACTTCCAAATCTGGACGACATTACGTCAAGTTTCTGGGACGACTTATTTAAAATGGTTTAA |
| Protein Sequence | MPSSSSSKAPSIKAQHRAAKTRAIRRRRIDLDCGCSIYLHLNCADYGFTHRGTHHAVSGREFRFYLGRSKSPLFQDVQRRGPNLHNNEDIPHPDQIQPQPQESTKSSQSIPELPNLDDITSSFWDDLFKMV |
| NCBI Accession | NP_148988.1 |
|---|---|
| Location | 1433-2488 |
| Gene Name | AC1 |
| Protein Name | Rep protein |
| Coding Region | ATGCCACGGAACCCTAATTCCTTTCGTATATCAGCCAAGAACATTTTCTTAACATATCCTCAGTGCGACATTCCGAAAGATGAAGCTATTCAGATGCTTCAGCATCTTAACTGGTCAATCGTCAAACCGACGTATATCAGAGTCGCACGAGAGGAACATTCCGACGGGTTCCCGCACTTACACTGCCTCATTCAATTATCCGGTAAGTCTAACATCAAGGATGCTAGATTTTTCGACCTTGCTCACCCCAGAAGGTCTACCAGTTTTCACCCAAATGTTCAGGCAGCCAAAGACGCCAACGCCGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAGTCCGGGAAATACAAGGTCTCTGGGGGTACAAAATCTAGCAAGGACGACGTCTATCACAACGCCATCAACGCAGGAAGTGCGGGAGAGGCTCTCGACATTATAAAAGCCGGTGATCCAAAAACGTTTATTGTGAACTATCATAACATAAAGGCTAACATCGAGCGCCTCTTTCATCAGCCACCTGAAACGTGGGCATGTCCATTTCCGTTATCATCGTTCACTCTCGTTCCAGAAGAGTTACAGGAGTGGGCTGATGATTATTTTGGGAGGGATGCCGCTGCGCGGCCAATGCGAGCTAGAAGTATAATCATAGAAGGTGACTCAAGAACGGGGAAGACGATGTGGTCCCGTTCGTTAGGCAAGCACAATTATCTTAGCGGTCACCTGGATTTCAATTCTAGGGTTTACTCAAACGAAGCCGAATATAACGTCATTGATGACGTCGCTCCGCAATACCTAAAGCTAAAGCACTGGAAAGAATTGATAGGGGCCCAAAGGGATTGGCAGTCCAACTGTAAATATGGAAAGCCAGTTCAAATTAAAGGAGGAATCCCATCAATCGTGCTGTGCAATCCAGGAGAGGGGGCATCTTATAAAGATTTCCTCGATAAAGAGGAAAATGAAAGCCTAAGAGAGTGGACGATCAAAAATGCCCAGTTCATCTTCCTCGAAGGCCCCCTCTATCAAAGCACAGCACAGAGCAGCGAAGACTAG |
| Protein Sequence | MPRNPNSFRISAKNIFLTYPQCDIPKDEAIQMLQHLNWSIVKPTYIRVAREEHSDGFPHLHCLIQLSGKSNIKDARFFDLAHPRRSTSFHPNVQAAKDANAVKNYITKEGDYCESGKYKVSGGTKSSKDDVYHNAINAGSAGEALDIIKAGDPKTFIVNYHNIKANIERLFHQPPETWACPFPLSSFTLVPEELQEWADDYFGRDAAARPMRARSIIIEGDSRTGKTMWSRSLGKHNYLSGHLDFNSRVYSNEAEYNVIDDVAPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENESLREWTIKNAQFIFLEGPLYQSTAQSSED |
| NCBI Accession | NP_148989.1 |
|---|---|
| Location | 521-1291 |
| Gene Name | BV1 |
| Protein Name | Nsp protein |
| Coding Region | ATGTATTCGTCAGGCAGTAGACGTGGTCGTAGTTCTACACAACGACGGAGTTATTCACGGCGTACAGCTGTTAAACGTCATTATACTACATCACGTCTCGATGATAAACGTCGAACGAGCAATGCTGGTAAGGTACATGGTGAGGCGAAGATGTCACTGCAGCGTATACATGAGGACCAATTCGGCCCTGACTATGTGCTTCGACATAATACAGCGTTGTCGACGTTTATCACCTATCCTACTCTTCGCAAGAGTGAACCTAACCGTTCCAGGTCATATATAAAGTTAAAACGCCTGCGTTTTAAGGGAACTCTTAAGATTGAACGTGTAGAAACCGACATTAACATGGTTGGTTCACCTGCCAATATTGACGGAGTGTATTCTATCGTGATTGTGGTTGATCGTAAACCACATTTGACTTCGACTGGTTGTCTACCGACATTTGACGATTTATTTGGCGCGAGGATGCATAGTCACGGTAATTTATCAATAACGTCGTCTAATAAGCAGCGTTTCTATATCAGACATGTTATGAAGCGTGTACTATCTGTAGAGCGGAACACATTGATGATCGACATCGAAGGAACGACGACGTTTTCTAATAGGCGTTACAATTGTTGGTCCGCATTTAACGACAACGACCGTGATTCATGTAACGGTGTTTACGCTAACATCAGCAAGAACGCCATATTAGTTTATCATTGTTGGATGTCTGATGTAACGTCCAGCGCATCTACTTTTGTATCATACGACCTTGATTATTACGGATAA |
| Protein Sequence | MYSSGSRRGRSSTQRRSYSRRTAVKRHYTTSRLDDKRRTSNAGKVHGEAKMSLQRIHEDQFGPDYVLRHNTALSTFITYPTLRKSEPNRSRSYIKLKRLRFKGTLKIERVETDINMVGSPANIDGVYSIVIVVDRKPHLTSTGCLPTFDDLFGARMHSHGNLSITSSNKQRFYIRHVMKRVLSVERNTLMIDIEGTTTFSNRRYNCWSAFNDNDRDSCNGVYANISKNAILVYHCWMSDVTSSASTFVSYDLDYYG |
| NCBI Accession | NP_148990.1 |
|---|---|
| Location | 1479-2360 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGTCAACGACGTTAGCTGCGGCACCTAACGCATTTAATTACATAGAATCGCGACGGGATGAGTATCGGCTATCTCATGACCTAACAGAAATTGTCCTGCAGTTTCCGTCGACGACTTCGCAAATTACTGCGAAACTGAGTCGTAGTTGTATGAAGATCGACCACTGTGTCATAGAATACAGGCAACAGGTTCCAATTAACGCCTCAGGAACGGTGATAGTGGAGATCCACGACAAACGCATGACTGACGACGAATCGTTGCAAGCGTCGTGGACATTTCCGATCAGATGCAATATAGATCTCCACTACTTCTCTGCGTCATTCTTCTCGCTAAAAGACCCAATTCCTTGGAAGTTATACTACAAGGTGTCAGATGCAAACGTTCATCAAATGACGCATTTCGCAAAATTCAAAGGCAAGCTAAAGCTGTCGTCGGCGAAACACTCAGTTGATATCCCCTTCCGGGCACCAACGGTGAAGTTGTTGTCGAAGCAATTCTGCGAGAAAGACGTTGATTTCTGGCACGTGGGTTACGGCAAGTGGGAGAGAAGACTGGTCAAATCCGCATCACTATCAAGAACTGGACTTAAGGGTCCAATTGAAATATGCCCAGGCGAGACCTGGGCTACAAAGAGCACAATTGTTACGAACAAATCAAATGCGGATTTGGGTATATCAGAAGAATTACTCCCGTATAGAGAACTTAACAGACTAGGAACAAGTGTATTAGATCCCGGAGATTCAGTTTCAATGGTCGGAATACAAAGGTCACAATCCAACATTACCATGTCAATGTCACAGCTGAACGAGTTAGTTAAATCGACAGTTCACGAGTGTATTAACAGTAGTTGTATTCCTCCGATACCAAAATCGTTAAATTAA |
| Protein Sequence | MSTTLAAAPNAFNYIESRRDEYRLSHDLTEIVLQFPSTTSQITAKLSRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMTDDESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYKVSDANVHQMTHFAKFKGKLKLSSAKHSVDIPFRAPTVKLLSKQFCEKDVDFWHVGYGKWERRLVKSASLSRTGLKGPIEICPGETWATKSTIVTNKSNADLGISEELLPYRELNRLGTSVLDPGDSVSMVGIQRSQSNITMSMSQLNELVKSTVHECINSSCIPPIPKSLN |
References More References in PubMed
| 1 |
Kavalappara SR, et al. J Virol Methods. 2024 Sep;329:114992. doi: 10.1016/j.jviromet.2024.114992. Epub 2024 Jun 25. PMID: 38936512 |
|---|---|
| 2 |
Cucurbit Leaf Crumple Virus Is Seed Transmitted in Yellow Squash (Cucurbita pepo). Dhadly DK, et al. Plant Dis. 2025 Jan;109(1):63-72. doi: 10.1094/PDIS-06-24-1330-RE. Epub 2025 Jan 4. PMID: 39151040 |
| 3 |
Cucurbit leaf crumple virus Identified in Common Bean in Florida. Adkins S, et al. Plant Dis. 2009 Mar;93(3):320. doi: 10.1094/PDIS-93-3-0320B. PMID: 30764208 |
| 4 |
Waliullah S, et al. Int J Mol Sci. 2020 Mar 4;21(5):1756. doi: 10.3390/ijms21051756. PMID: 32143404 |
| 5 |
Gadhave KR, et al. Phytopathology. 2020 Jun;110(6):1235-1241. doi: 10.1094/PHYTO-09-19-0337-R. Epub 2020 Apr 16. PMID: 32096698 |
| 6 |
Hagen C, et al. Plant Dis. 2008 May;92(5):781-793. doi: 10.1094/PDIS-92-5-0781. PMID: 30769582 |
| 7 |
Detection of Cucurbit leaf crumple virus in Florida Cucurbits. Akad F, et al. Plant Dis. 2008 Apr;92(4):648. doi: 10.1094/PDIS-92-4-0648C. PMID: 30769620 |
| 8 |
Kuo YW, et al. Plant Dis. 2007 Mar;91(3):330. doi: 10.1094/PDIS-91-3-0330B. PMID: 30780592 |
| 9 |
Jailani AAK, et al. Int J Mol Sci. 2025 Oct 31;26(21):10611. doi: 10.3390/ijms262110611. PMID: 41226647 |
| 10 |
Hagen C, et al. Phytopathology. 2008 Sep;98(9):1029-37. doi: 10.1094/PHYTO-98-9-1029. PMID: 18943741 |