Crassocephalum yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000869725.1 |
| Isolate |
China |
| Release date |
2015/2/13 |
| Submitter |
Dong,J.H., Zhang,Z.K., Ding,M., Fang,Q., Zhou,H. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
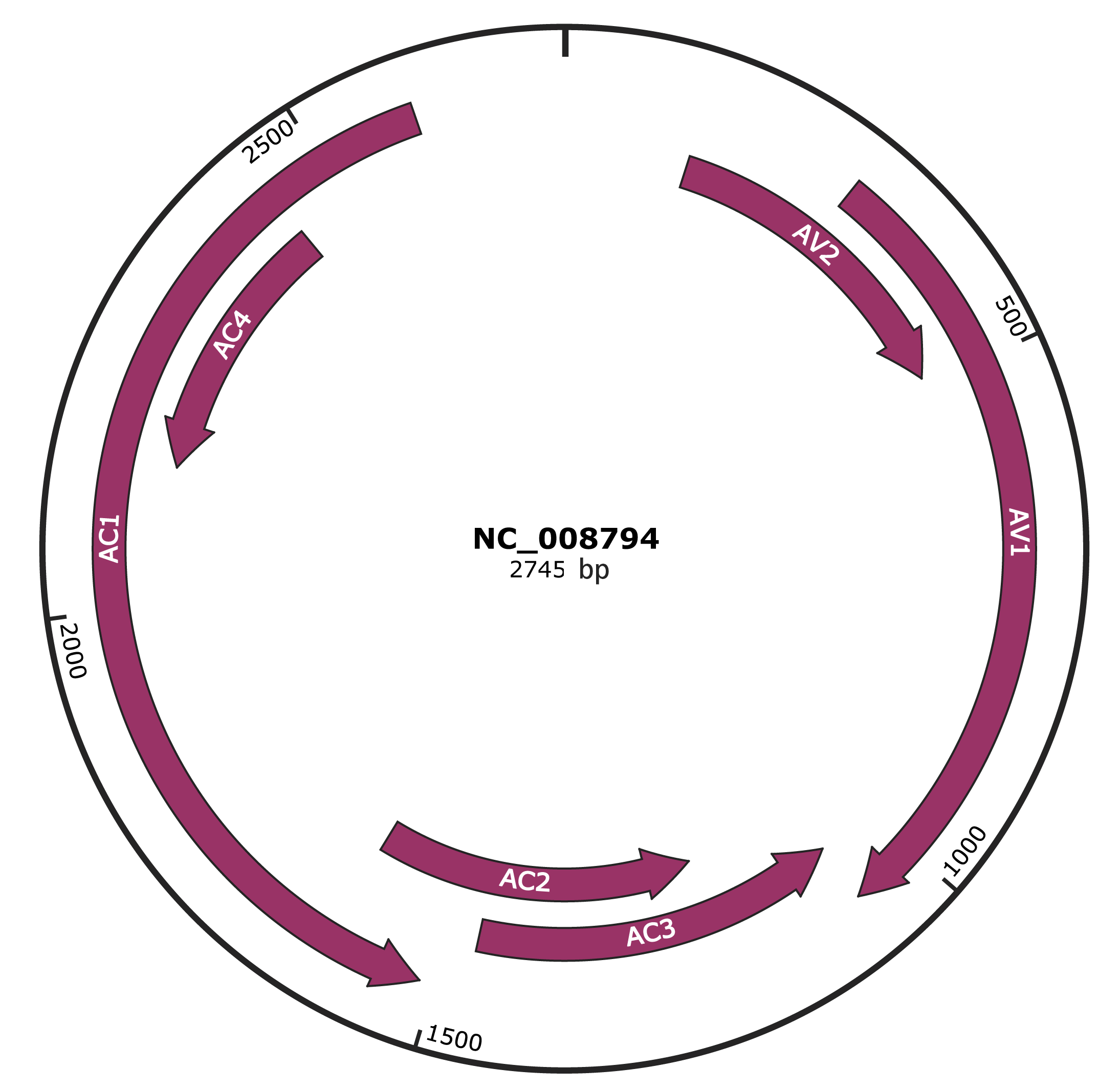
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTATAAAGTGGTCCCCACCACTAACAAATGTCCCCCAATTAGAACGCTTCCTCAAAGCTTAATTATTAAATGGTCCCCTATAAATACTTGGTCCCTACGTATTCACGTTAAAGAAATGTGGGATCCTCTTTTGAACGAGTTTCCCGAAACCGTTCACGGCTTTAGGTGTATGTTAGCAGTTAAATATCTGCAGTTAGTAGAGAAGATTAAATCGCCTGACACATTAGGGCACGATTTAATTAGGGATTTAATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGCACGCCGCCGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCCAGATCATGGGCGAACAGGCCCATGAACAGAAAGCCCAAGATGTACAGGATGTACAGAAGCCCAGATGTCCCTAGAGGATGTGAAGGCCCATGTAAGGTCCAATCTTTTGATGCTAAGAACGATATTGGTCACATGGGTAAGGTCCTATGTTTGTCCGACGTTACGAGGGGAAATGGTTTGACTCATCGGGTTGGTAAACGTTTTTGTGTCAAGTCTCTGTATTTTGTCGGTAAGATCTGGATGGACGAGAACATCAAGGTTAAGAACCACACTAACACCGTTTTGTTCTGGATCGTCCGGGACCGGCGACCCAGTGGTACCCCCAATGATTTTCAACAGGTCTTTAATGTGTATGATAATGAACCGTCTACTGCGACTGTTAAGGATGATCAGCGTGACCGCTATCAAGTCTTGCGAAGATTTCAATCAACGGTGACTGGTGGACGGTATGCTGCTAAGGAACAGGCGATAATTAGAGGATTTTATCGTGTAAATAATTATGTAGTGTACAATCACCAGGAAGCTGGGAAGTACGAGAACCATACTGAAAATGCTTTGTTGTTGTATATGGCATGTACCCATGCCTCTAATCCTGTGTATGCCACTTTGAAAGTCAGGAGTTATTTTTATGACTCAGTGACTAATTAATAAAGATTAAATTTTATTGAATAAGATTGGTCTACATATACAATGTGTTCTAATACATTCCATAATACATGATCAACCGTACGTATTACATTATTCAAACTAATTACACCCAAATTATTAAGAAACTTCAAAACTTGTGTCCTAAATACTCTTAAGAAACGACCAGTCTGAGGCTGTGAAGTCATCCAGATTCGGTAGACTAGAAAACACTTGTGTATCCCCAACGCTTTCCGCAGGTTGTAGTTGAACTGTATTTGGATGGTGATTATGTCTTCTTTCATGAGAAATGGACGGTTCTGGTGATTTATTATCTTGAAATAAAGGGGATTTTTGACCGTCCAGATATATACGCCACTCTCTGCTTGAGCTGCAGTGATAGCTTCCCCTGTGCGTGAATCCATGATCGTGACAGCCCAGTGCAATGAAGTATGAACAGCCACAAGGGAGATCAACTCGACGTCGTCTGGTTGCCTTCTTGGCGTTGCGGTGTTGCACCTTGATAGGAACCGGAGTAGAGTGGGCCTTGGAGGGTGACGAAGATCGCATTCTTTATTGCCCAATTTTTAAGTGCGTTGTTCTTTTCTTCATCCAGGAATTCTTTATAGCTGGAAGTGGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAACTGGCTTTCCGTATTTAGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGTTTTAGGTAGTGCGGATCTACGTCATCAATGACGTTGAACCAGGCATCATTGCTGTACACTTTAGGGCTCAGATCTAGATGTCCACACAAATAATTGTGTGGTCCTAATGACCTGGCCCACATGGTCTTCCCCGTCCTGCTATCACCCTCTATGACTATACTTACCGGTCTCAATGGCCGCGCAGCGGAACTGACGACATTGTCGGCAGCCCATTCATCAAGTTCTTCTGGAACTTGGTCAAAAGAAGAAGAAGAAAATGGAGAAATATATTCCTCTAATGGAGGAGTAAAAATCCTATCTAAATTACTATTTAAATTATGAAATTGTAAAACAAAATCTTTAGGGGCCTTTTCCCTCAATATATTGAGGGCCGATGTTTTGGACCCCGAATTGATTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCTCTAGCCGATCGTCCATCGATCTGGAAAATTCCATGATCAAGCACGTCTCCGTCTTTTTCCATGTATGATTTAACATCTGTTGAGCTTTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGTTTGGGGATATGAGATCGAAGAATCTTTGATTTTTACACTGGAATTTCCCTTCGAACTGGATGAGGATATGCAGGTGAGGAGTCCCATCTTCGTGTAGTTCTCTGCAGATTCTGATGAATAATTTAGTAATTGGGGTTTCTAGGGCTTTAATTTGGGAAAGTGCTTCCTCTTTGGTAAGAGAACAGTGTGGGTATGTGAGGAAATAGTTTTTGGCATTTATTCTGAATTTATTAGGAGGAGCCATTGACTGGTCAATTGGTGTCTCTCAAACTTGGCTACGCAATTGGTGTCTGGGGTCTTATTTATATGTGGACACCAAATGGCATAATTGTAAATTCTAAAGTTATATTCAAAATTCAAAATCTAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001004146.1
|
|
Location
|
136-492 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCTCTTTTGAACGAGTTTCCCGAAACCGTTCACGGCTTTAGGTGTATGTTAGCAGTTAAATATCTGCAGTTAGTAGAGAAGATTAAATCGCCTGACACATTAGGGCACGATTTAATTAGGGATTTAATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGCACGCCGCCGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCCAGATCATGGGCGAACAGGCCCATGAACAGAAAGCCCAAGATGTACAGGATGTACAGAAGCCCAGATGTCCCTAG |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAVKYLQLVEKIKSPDTLGHDLIRDLISVIRARNYVEATSRYNHFHARFEGTPPSQLRQPICEPCCCPHCPRHQSQIMGEQAHEQKAQDVQDVQKPRCP |
|
NCBI Accession
|
YP_001004147.1
|
|
Location
|
296-1066 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGCACGCCGCCGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCCAGATCATGGGCGAACAGGCCCATGAACAGAAAGCCCAAGATGTACAGGATGTACAGAAGCCCAGATGTCCCTAGAGGATGTGAAGGCCCATGTAAGGTCCAATCTTTTGATGCTAAGAACGATATTGGTCACATGGGTAAGGTCCTATGTTTGTCCGACGTTACGAGGGGAAATGGTTTGACTCATCGGGTTGGTAAACGTTTTTGTGTCAAGTCTCTGTATTTTGTCGGTAAGATCTGGATGGACGAGAACATCAAGGTTAAGAACCACACTAACACCGTTTTGTTCTGGATCGTCCGGGACCGGCGACCCAGTGGTACCCCCAATGATTTTCAACAGGTCTTTAATGTGTATGATAATGAACCGTCTACTGCGACTGTTAAGGATGATCAGCGTGACCGCTATCAAGTCTTGCGAAGATTTCAATCAACGGTGACTGGTGGACGGTATGCTGCTAAGGAACAGGCGATAATTAGAGGATTTTATCGTGTAAATAATTATGTAGTGTACAATCACCAGGAAGCTGGGAAGTACGAGAACCATACTGAAAATGCTTTGTTGTTGTATATGGCATGTACCCATGCCTCTAATCCTGTGTATGCCACTTTGAAAGTCAGGAGTTATTTTTATGACTCAGTGACTAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKARRRLNFDSPYVSRAAAPIVRVTKARSWANRPMNRKPKMYRMYRSPDVPRGCEGPCKVQSFDAKNDIGHMGKVLCLSDVTRGNGLTHRVGKRFCVKSLYFVGKIWMDENIKVKNHTNTVLFWIVRDRRPSGTPNDFQQVFNVYDNEPSTATVKDDQRDRYQVLRRFQSTVTGGRYAAKEQAIIRGFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
|
NCBI Accession
|
YP_001004148.1
|
|
Location
|
1063-1467 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAAGCTATCACTGCAGCTCAAGCAGAGAGTGGCGTATATATCTGGACGGTCAAAAATCCCCTTTATTTCAAGATAATAAATCACCAGAACCGTCCATTTCTCATGAAAGAAGACATAATCACCATCCAAATACAGTTCAACTACAACCTGCGGAAAGCGTTGGGGATACACAAGTGTTTTCTAGTCTACCGAATCTGGATGACTTCACAGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGGACACAAGTTTTGAAGTTTCTTAATAATTTGGGTGTAATTAGTTTGAATAATGTAATACGTACGGTTGATCATGTATTATGGAATGTATTAGAACACATTGTATATGTAGACCAATCTTATTCAATAAAATTTAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEAITAAQAESGVYIWTVKNPLYFKIINHQNRPFLMKEDIITIQIQFNYNLRKALGIHKCFLVYRIWMTSQPQTGRFLRVFRTQVLKFLNNLGVISLNNVIRTVDHVLWNVLEHIVYVDQSYSIKFNLY |
|
NCBI Accession
|
YP_001004149.1
|
|
Location
|
1208-1612 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGATCTTCGTCACCCTCCAAGGCCCACTCTACTCCGGTTCCTATCAAGGTGCAACACCGCAACGCCAAGAAGGCAACCAGACGACGTCGAGTTGATCTCCCTTGTGGCTGTTCATACTTCATTGCACTGGGCTGTCACGATCATGGATTCACGCACAGGGGAAGCTATCACTGCAGCTCAAGCAGAGAGTGGCGTATATATCTGGACGGTCAAAAATCCCCTTTATTTCAAGATAATAAATCACCAGAACCGTCCATTTCTCATGAAAGAAGACATAATCACCATCCAAATACAGTTCAACTACAACCTGCGGAAAGCGTTGGGGATACACAAGTGTTTTCTAGTCTACCGAATCTGGATGACTTCACAGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MRSSSPSKAHSTPVPIKVQHRNAKKATRRRRVDLPCGCSYFIALGCHDHGFTHRGSYHCSSSREWRIYLDGQKSPLFQDNKSPEPSISHERRHNHHPNTVQLQPAESVGDTQVFSSLPNLDDFTASDWSFLKSI |
|
NCBI Accession
|
YP_001004150.1
|
|
Location
|
1515-2600 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGGCTCCTCCTAATAAATTCAGAATAAATGCCAAAAACTATTTCCTCACATACCCACACTGTTCTCTTACCAAAGAGGAAGCACTTTCCCAAATTAAAGCCCTAGAAACCCCAATTACTAAATTATTCATCAGAATCTGCAGAGAACTACACGAAGATGGGACTCCTCACCTGCATATCCTCATCCAGTTCGAAGGGAAATTCCAGTGTAAAAATCAAAGATTCTTCGATCTCATATCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAACAGATGTTAAATCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAGATCGATGGACGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCGGGGTCCAAAACATCGGCCCTCAATATATTGAGGGAAAAGGCCCCTAAAGATTTTGTTTTACAATTTCATAATTTAAATAGTAATTTAGATAGGATTTTTACTCCTCCATTAGAGGAATATATTTCTCCATTTTCTTCTTCTTCTTTTGACCAAGTTCCAGAAGAACTTGATGAATGGGCTGCCGACAATGTCGTCAGTTCCGCTGCGCGGCCATTGAGACCGGTAAGTATAGTCATAGAGGGTGATAGCAGGACGGGGAAGACCATGTGGGCCAGGTCATTAGGACCACACAATTATTTGTGTGGACATCTAGATCTGAGCCCTAAAGTGTACAGCAATGATGCCTGGTTCAACGTCATTGATGACGTAGATCCGCACTACCTAAAACACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACTAAATACGGAAAGCCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCCACTTCCAGCTATAAAGAATTCCTGGATGAAGAAAAGAACAACGCACTTAAAAATTGGGCAATAAAGAATGCGATCTTCGTCACCCTCCAAGGCCCACTCTACTCCGGTTCCTATCAAGGTGCAACACCGCAACGCCAAGAAGGCAACCAGACGACGTCGAGTTGA |
|
Protein Sequence
|
MAPPNKFRINAKNYFLTYPHCSLTKEEALSQIKALETPITKLFIRICRELHEDGTPHLHILIQFEGKFQCKNQRFFDLISPNRSAHFHPNIQGAKSSTDVKSYMEKDGDVLDHGIFQIDGRSARGGCQSANDAYAEAINSGSKTSALNILREKAPKDFVLQFHNLNSNLDRIFTPPLEEYISPFSSSSFDQVPEELDEWAADNVVSSAARPLRPVSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWFNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPTSSYKEFLDEEKNNALKNWAIKNAIFVTLQGPLYSGSYQGATPQRQEGNQTTSS |
|
NCBI Accession
|
YP_001004151.1
|
|
Location
|
2150-2443 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGACTCCTCACCTGCATATCCTCATCCAGTTCGAAGGGAAATTCCAGTGTAAAAATCAAAGATTCTTCGATCTCATATCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAACAGATGTTAAATCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAGATCGATGGACGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCGGGGTCCAAAACATCGGCCCTCAATATATTGA |
|
Protein Sequence
|
MGLLTCISSSSSKGNSSVKIKDSSISYPQTGQHISIRTFRELKAQQMLNHTWKKTETCLIMEFSRSMDDRLEEVANLPTTHMPRQSIRGPKHRPSIY |