Cowpea bright yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_013088025.1 |
| Isolate | Brazil |
| Release date | 2021/6/1 |
| Submitter | Naito,F.Y.B., Melo,F.L., Fonseca,M.E.N., Santos,C.A.F., Chanes,C.R., Ribeiro,B.M., Carvalho,R.C.P., Boiteux,L.S. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
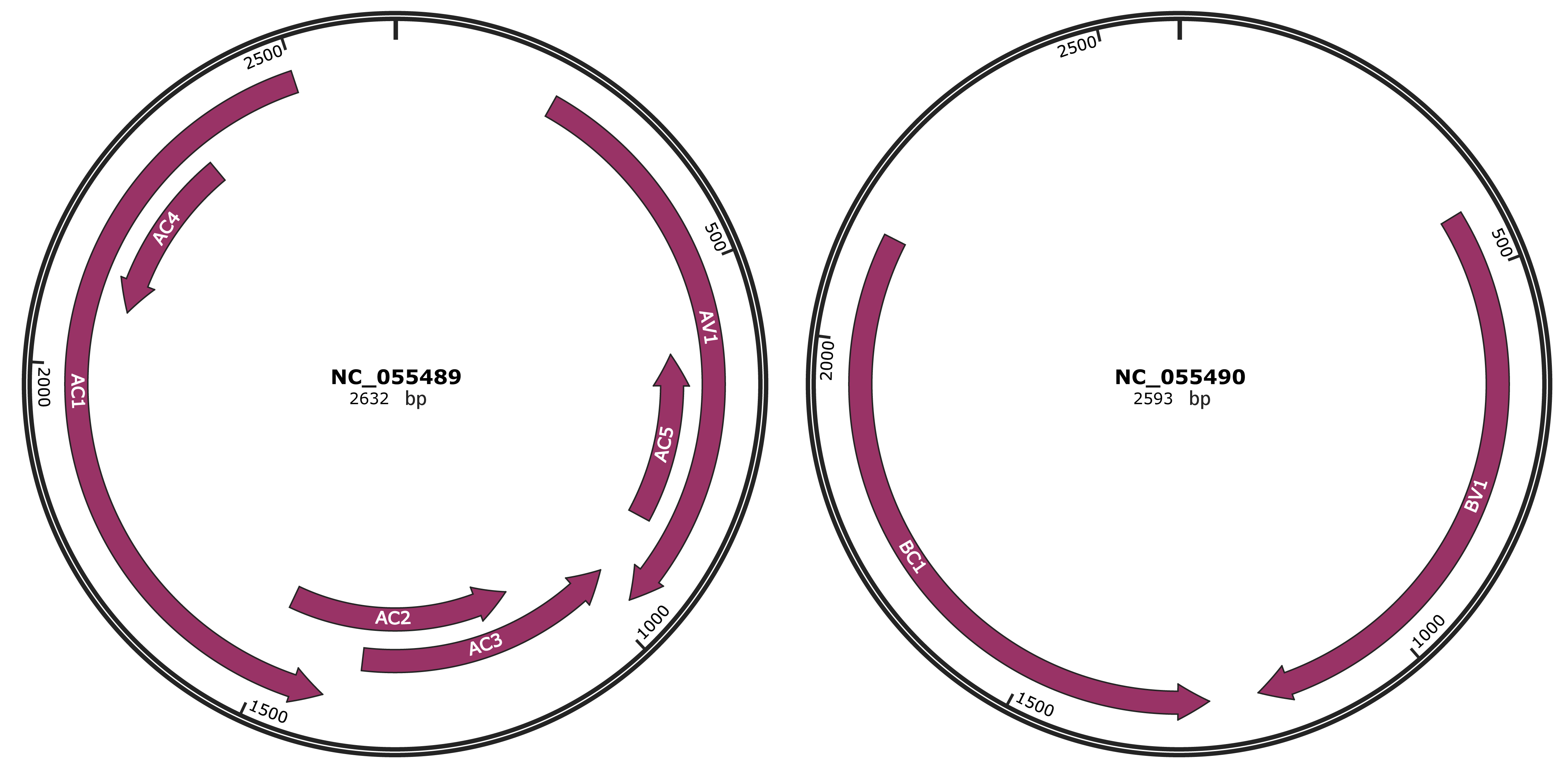
Genomic Organization
JBrowse
Genome
NC_055489
NC_055490
Gene Information
| NCBI Accession | YP_010086832.1 |
|---|---|
| Location | 215-970 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGGTCAAGCGGGATGCCCCATGGCGCCACATGTCGGGAACCTCTAAGGTTTCCCGCACTAACAATTTTTCTCCTCGTTCAGGTGGAGGCCCAAAATACAACAAGGCCGCTGAATGGATGAATAGGCCCATGTATAGGAAGCCCAGGATATATCGGATGTACAGATCCCGCGATGTTCCCAGAGGTTGTGAAGGGCCTTGTAAGGTTCAGAGTTTTGAACAGAAACATGATGTTTCCCATATTGGGAAGGTTATTTGTCTATCTGACGTGACACGTGGTGGTGGTATTACGCATCGTGTTGGAAGACGTTTTTGTGTTAAGTCTGTTTATATTTTAGGTAAGGTGTGGATGGACGAGAATATCAAGTTGAAGAACCATACTAATAGTGCTATGTTTTGGTTAGTTAGAGACTGTAGACCGTATGGTACTCCTATGGATTTTGGTCAAGTTTTTAATATGTTTGACAATGAGCCCAGTACTGCTACTGTGAAGATCGATCTTCGTGATCGTTTCCAAGTTCTGCATAAATTTTATGCAAAGGTGACTGGTGGACAGTATGCTAGCAACGAGCAGGCATTGGTTAAGCGTTTTTGGACGGACAATACCCATGTCGTCTATAATCATCAGGAAGCTGGGAAATATGAGAATCATACGCAGAATGCATTATTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACTCTGAAAATTCGGATCTATTTTTATGATTCGATATCAAATTAA |
| Protein Sequence | MVKRDAPWRHMSGTSKVSRTNNFSPRSGGGPKYNKAAEWMNRPMYRKPRIYRMYRSRDVPRGCEGPCKVQSFEQKHDVSHIGKVICLSDVTRGGGITHRVGRRFCVKSVYILGKVWMDENIKLKNHTNSAMFWLVRDCRPYGTPMDFGQVFNMFDNEPSTATVKIDLRDRFQVLHKFYAKVTGGQYASNEQALVKRFWTDNTHVVYNHQEAGKYENHTQNALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_010086833.1 |
|---|---|
| Location | 614-865 |
| Gene Name | AC5 |
| Protein Name | AC5 |
| Coding Region | ATGATTCTCATATTTCCCAGCTTCCTGATGATTATAGACGACATGGGTATTGTCCGTCCAAAAACGCTTAACCAATGCCTGCTCGTTGCTAGCATACTGTCCACCAGTCACCTTTGCATAAAATTTATGCAGAACTTGGAAACGATCACGAAGATCGATCTTCACAGTAGCAGTACTGGGCTCATTGTCAAACATATTAAAAACTTGACCAAAATCCATAGGAGTACCATACGGTCTACAGTCTCTAACTAA |
| Protein Sequence | MILIFPSFLMIIDDMGIVRPKTLNQCLLVASILSTSHLCIKFMQNLETITKIDLHSSSTGLIVKHIKNLTKIHRSTIRSTVSN |
| NCBI Accession | YP_010086834.1 |
|---|---|
| Location | 967-1365 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATTTGGGAGATATCAAATCCCCTCTATTTCAAGATAAACAAAGTCGAGGATCCTCTATACACGAGGACCAGAATATACCACATCCAGATCAGGTTCAACCACAACCTGAGGAACAAACTGGATCTTCACAAGGCATTCTTCAATTTCCAAGTCTGGACGACATCGATTCAAGCTTCTGGGACGACTTATTTAAATAGATTCAAGTATTTAGTTTCATTGTATCTAGATCGTTTAGGCGTGATTTCCATTAACAATGTAATCAGAGCTGTTCGTTTTGCAACGAACAAAACATATGTACATGAGGTATTAGACAATCATATAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGELITAHQAENGVYIWEISNPLYFKINKVEDPLYTRTRIYHIQIRFNHNLRNKLDLHKAFFNFQVWTTSIQASGTTYLNRFKYLVSLYLDRLGVISINNVIRAVRFATNKTYVHEVLDNHIIKFKIY |
| NCBI Accession | YP_010086835.1 |
|---|---|
| Location | 1112-1501 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCGAAATTCGTCTTCCTCAGCTCTCCCCTCTATCAAAGTTCAACACAGAGCAGCGAAGAAACGAGCAATCAGACGACGTCGCATTGATATAGAGTGCGGTTGCTCAATTTACGTCCACATTAACTGCGCTGGCCATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATTTGGGAGATATCAAATCCCCTCTATTTCAAGATAAACAAAGTCGAGGATCCTCTATACACGAGGACCAGAATATACCACATCCAGATCAGGTTCAACCACAACCTGAGGAACAAACTGGATCTTCACAAGGCATTCTTCAATTTCCAAGTCTGGACGACATCGATTCAAGCTTCTGGGACGACTTATTTAAATAG |
| Protein Sequence | MRNSSSSALPSIKVQHRAAKKRAIRRRRIDIECGCSIYVHINCAGHGFTHRGTHHCTSGREWRLYLGDIKSPLFQDKQSRGSSIHEDQNIPHPDQVQPQPEEQTGSSQGILQFPSLDDIDSSFWDDLFK |
| NCBI Accession | YP_010086836.1 |
|---|---|
| Location | 1413-2498 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCACCACCAAAGCGTTTTAAAATAAACGCTAAGAATTTTTTCCTTACATACCCACAATGTTCAATTGGGAAAGAGAGTGCAATTGAACAACTTCAAACACTACAAACCCCAATCAACAAAAAATATATCAGAGTCTGCAGAGAACTTCACGAGAATGGGGAACCACATCTGCATGCCCTCATTCAGTTCGAAGGGAAGTTCCAATGCACGAATTGCAGATTGTTCGACCTCAAACATCCACACACCTCTTCCGTCTCCCATCCCAATATACAGAGTGCAAAGTCATCATCTGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACGTCGAATGGGGTCATTTTCAAATCGACGGAAGATCTGCTAGAGGAGGTCAGCAGACAATTAATGATGCAGCATCGGAGGCATTAAATGCTTCTTCAAAGGAAGAAGCCATGCAAATTATCAAAGAGAAACTACCAGAGAAGTTTCTCTTCCAGTATCACAACTTATGCAGTAACCTGGATAGGATATTCAAAAGCCTCCGGAACCATGGTCTTCTCCGTTTCAACTGTCCTCATTCACTAACGTCCCAAAGCAGATGCAAGACTGGGCAGATGATTATTTCGGAAGAGATGCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATCATCGAGGGTGATTCTCGAACAGGGGAAGACAATGTGGGCACGTGCGTTAGGGACCCACAATTATTTGAGCGGGCACTTAGATTTCAATTCAAGGGTCTATTCCAATAATGCAGAGTATAACGTCATTGATGACATCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAATTGATAGGTGCCCAAAAAGACTGGCAATCAAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGGGTTCCTTGCATCATACTTTGCAATGCTGGCGAAGGGGCCAGCTATAAATCTTTCCTCGACAGAGAGGAAAATGCAAGTTTAAAAAACTGGACGCTGCATAATGCGAAATTCGTCTTCCTCAGCTCTCCCCTCTATCAAAGTTCAACACAGAGCAGCGAAGAAACGAGCAATCAGACGACGTCGCATTGA |
| Protein Sequence | MPPPKRFKINAKNFFLTYPQCSIGKESAIEQLQTLQTPINKKYIRVCRELHENGEPHLHALIQFEGKFQCTNCRLFDLKHPHTSSVSHPNIQSAKSSSDVKSYIEKDGDYVEWGHFQIDGRSARGGQQTINDAASEALNASSKEEAMQIIKEKLPEKFLFQYHNLCSNLDRIFKSLRNHGLLRFNCPHSLTSQSRCKTGQMIISEEMPLRGRRDLLVSSSRVILEQGKTMWARALGTHNYLSGHLDFNSRVYSNNAEYNVIDDIAPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGVPCIILCNAGEGASYKSFLDREENASLKNWTLHNAKFVFLSSPLYQSSTQSSEETSNQTTSH |
| NCBI Accession | YP_010086837.1 |
|---|---|
| Location | 2084-2341 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGGAACCACATCTGCATGCCCTCATTCAGTTCGAAGGGAAGTTCCAATGCACGAATTGCAGATTGTTCGACCTCAAACATCCACACACCTCTTCCGTCTCCCATCCCAATATACAGAGTGCAAAGTCATCATCTGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACGTCGAATGGGGTCATTTTCAAATCGACGGAAGATCTGCTAGAGGAGGTCAGCAGACAATTAATGATGCAGCATCGGAGGCATTAA |
| Protein Sequence | MGNHICMPSFSSKGSSNARIADCSTSNIHTPLPSPIPIYRVQSHHLMSSPTSRRTVITSNGVIFKSTEDLLEEVSRQLMMQHRRH |
| NCBI Accession | YP_010086838.1 |
|---|---|
| Location | 423-1193 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATTACAATAAAAATAGACGTGGTTTTACAACTACTTCTAGACGAGGCTATTCAAGGTATCCTTTTTCCAGACGGTCGTATAGTGTGAAAAGAATCAATGGTAAGCGTGGATCGTTTAATGGGAATAAGGCCCATGATGATAGCAAGATGTCATCCCAACGTTTACATGAAAATCAATTTGGGCCTGAATTTGTCATGGCCCATAATGCCGCTATTTCAACATATATTACGTTCCCTAAGTTGGGAAAGACTGAGCCCAACCGATCACGGTGTTATATTAAATTAAAACGTCTGCGTTTTAATGGGACTGTTAAAATTGAACGTGTTCATCATGATGTGAACATGGAAGGGTTAACACCAAAATTGAAGGTGTGTTTTCCATGGTTGTGGTTGTTGATCGTAAACCCTCATTTAAGTTCGTCAGGATGTCTGCATACATTTGATGAATTATTTGGTTCCAGGATTCACAGTCATGGTAATTTAGTCATAAGTCCGTCATGGAAAGAACGTTTTTATATTCGTCATATTTTTAGACGAGTGATTTCCGTGGAGAAGGATAGCCTCATGGTTGATGTTGAAGGAAGTACTTATTTGTCAACTAGGCGTTTTAATTGTTGGGCTACATTTAAAGATGTTGATCGTGAGTCATGTAATGGGGTATATTCTAACATAAGCAAGAATGCCCTTCTTGTCTATTATTGTTGGGTATCTGATGCTGTATCAAAGGCATCTACGTTTGTATCATTTGATCTTGATTATGTTGGGTGA |
| Protein Sequence | MYYNKNRRGFTTTSRRGYSRYPFSRRSYSVKRINGKRGSFNGNKAHDDSKMSSQRLHENQFGPEFVMAHNAAISTYITFPKLGKTEPNRSRCYIKLKRLRFNGTVKIERVHHDVNMEGLTPKLKVCFPWLWLLIVNPHLSSSGCLHTFDELFGSRIHSHGNLVISPSWKERFYIRHIFRRVISVEKDSLMVDVEGSTYLSTRRFNCWATFKDVDRESCNGVYSNISKNALLVYYCWVSDAVSKASTFVSFDLDYVG |
| NCBI Accession | YP_010086839.1 |
|---|---|
| Location | 1258-2139 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGACTCTCAATTAGTCATTCCACCATCAGCTTTCAATTACGTAGAATCGCAGCGTGATGAGTATCAACTATCTCATGACCTAACTGAGATAGTATTGCAATTCCCTTCTACAGCAGCTCAATTAAGTGCAAGAATTGGTCGTAGCTGTATGAAGATAGACCATTGCGTCATAGAATACAGACAACAAGTTCCAATTAACGCAACCGGAGCAGTTATTGTTGAAATTCATGACCAACGAATGACGGACAATGAATCATTACAAGCGTCATGGACATTTCCCATAAGATGTAACATAGATTTACATTATTTTTCGTGTTCGTTCTTCTCACTTAAAGACCCAATTCCATGGAAATTGTATTACAGAGTTAGCGACACAAATGTTCATCAGAGGACACACTTCGCCAAATTCAAGGGAAAATTAAAGATATCCACCGCAAAACATTCTGTGGATATTCCTTTCAAGCCACCAACTGTTAAAATATTATCTAAACAGTTCACAGAGAGAGACATAGATTTCTCTCACGTTGGTTATGGCAAATATGAAAGGAAATTAATCAGGTCCGTATCCACATCCAGATATGGGCTTCACAAGCCAATAACGATTCAACCAGGTGAAACATGGGCGACAAGAAGTACAGTAGGAGCCGATCCATCAGATACGGACTCTGAGATACACAACGCAATACACCCATATAAACAACTCCATAGATTGGACACAAGTCTATTAGACCCAGGTGAATCAGCGTCGATAGTTGGTGCAAGTAGGACAGAGTCCAGTATAACAATGTCAATTTCCCAATTAAACGAGCTAGTTAGAACAGCGGCACAGGAATGTATAAAAACCAATTGTACTCCTTCTCAACCTAAATCTTTAAATTAA |
| Protein Sequence | MDSQLVIPPSAFNYVESQRDEYQLSHDLTEIVLQFPSTAAQLSARIGRSCMKIDHCVIEYRQQVPINATGAVIVEIHDQRMTDNESLQASWTFPIRCNIDLHYFSCSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKISTAKHSVDIPFKPPTVKILSKQFTERDIDFSHVGYGKYERKLIRSVSTSRYGLHKPITIQPGETWATRSTVGADPSDTDSEIHNAIHPYKQLHRLDTSLLDPGESASIVGASRTESSITMSISQLNELVRTAAQECIKTNCTPSQPKSLN |
References More References in PubMed
| 1 |
Balasubramaniam M, et al. Front Plant Sci. 2024 Aug 2;15:1401526. doi: 10.3389/fpls.2024.1401526. eCollection 2024. PMID: 39157510 |
|---|---|
| 2 |
Cowpea mosaic virus: effects on host cell processes. Pouwels J, et al. Mol Plant Pathol. 2002 Nov 1;3(6):411-8. doi: 10.1046/j.1364-3703.2002.00135.x. PMID: 20569348 |
| 3 |
First Report of Soybean yellow mottle mosaic virus in Soybean in North America. Li S, et al. Plant Dis. 2009 Nov;93(11):1214. doi: 10.1094/PDIS-93-11-1214B. PMID: 30754605 |
| 4 |
Araujia sericifera New Host of Alfalfa mosaic virus in Italy. Parrella G, et al. Plant Dis. 2013 Oct;97(10):1387. doi: 10.1094/PDIS-03-13-0300-PDN. PMID: 30722152 |
| 5 |
Diagnosis of a new variant of soybean yellow mottle mosaic virus with extended host-range in India. Sandra N, et al. Virusdisease. 2015 Dec;26(4):304-14. doi: 10.1007/s13337-015-0288-2. Epub 2015 Nov 23. PMID: 26645042 |
| 6 |
Nanopore sequencing of a novel bipartite New World begomovirus infecting cowpea. Naito FYB, et al. Arch Virol. 2019 Jul;164(7):1907-1910. doi: 10.1007/s00705-019-04254-5. Epub 2019 Apr 10. PMID: 30972591 |
| 7 |
The Occurrence of Bean common mosaic virus and Cucumber mosaic virus in Yardlong Beans in Indonesia. Damayanti TA, et al. Plant Dis. 2010 Apr;94(4):478. doi: 10.1094/PDIS-94-4-0478B. PMID: 30754487 |
| 8 |
Parrella G, et al. Plant Dis. 2010 Jul;94(7):924. doi: 10.1094/PDIS-94-7-0924A. PMID: 30743579 |
| 9 |
Sun QY, et al. J Biotechnol. 2011 Sep 10;155(2):164-72. doi: 10.1016/j.jbiotec.2011.06.033. Epub 2011 Jul 5. PMID: 21762733 |