Cotton leaf curl Multan virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000839845.1 |
| Isolate | India: Rajasthan, Sriganganagar |
| Release date | 2015/2/12 |
| Submitter | Radhakrishnan,G., Malathi,V.G., Varma,A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
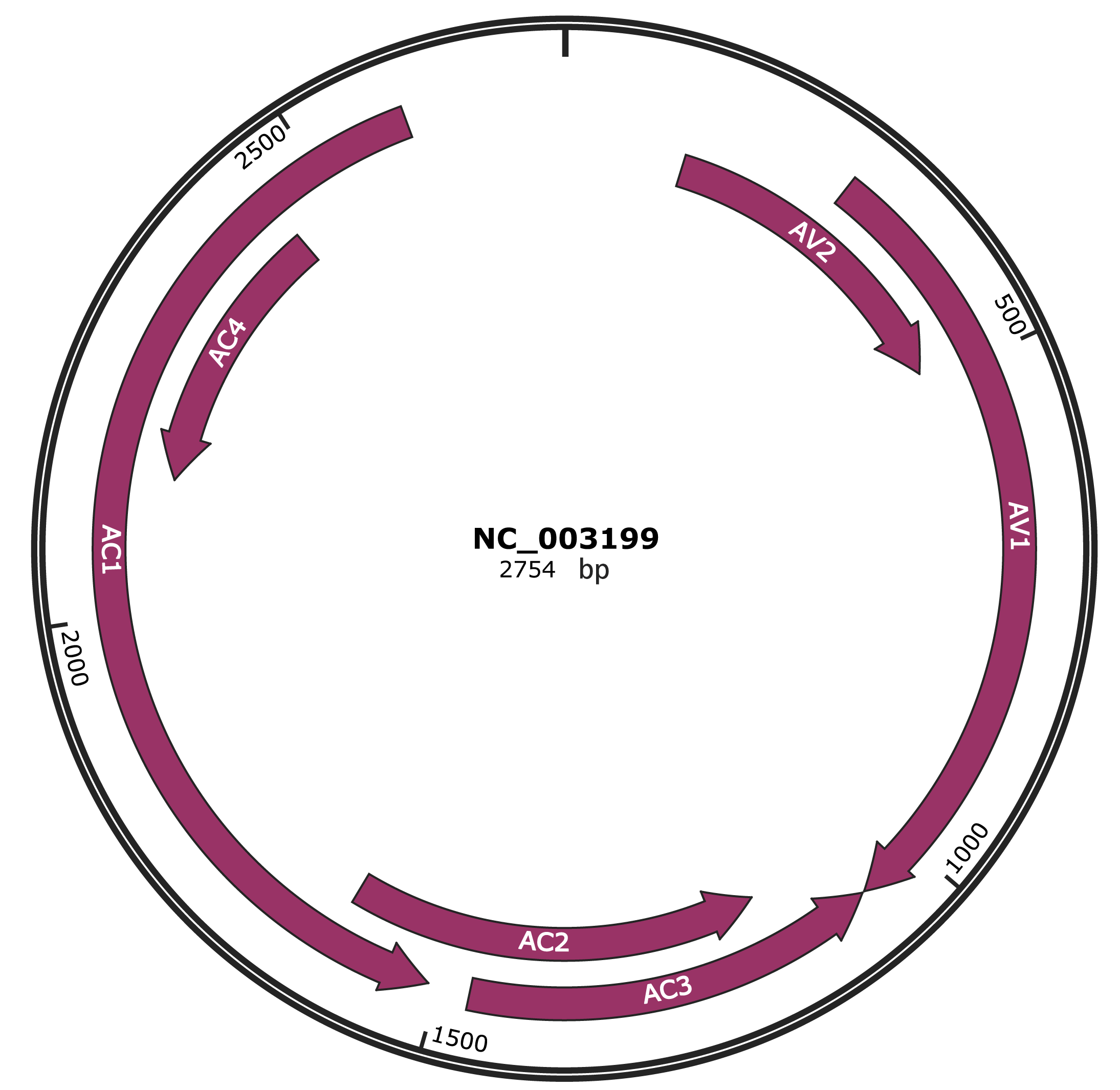
JBrowse
Genome
NC_003199
Gene Information
| NCBI Accession | NP_443740.1 |
|---|---|
| Location | 132-488 |
| Gene Name | AV2 |
| Protein Name | movement/pre-coat protein |
| Coding Region | ATGTGGGATCCACTATTAAACGAATTCCCTGATACGGTTCACGGGTTTCGGTGTATGCTTTCTGTGAAATATTTGCAACTTTTGTCGCAGGATTATTCACCGGATACGCTTGGGTACGAGTTAATACGGGATTTAATTTGTATTTTACGCTCCCGTAGTTATGTCGAAGCGAGCTGCCGATATCGTCATTTCTACGCCCGCGTCGAAAGTACGCCGGCGTCTGAACTTCGGCAGCCCATACACCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAACAACAGGCATGGACAAACAGGCCTATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTTCCTAG |
| Protein Sequence | MWDPLLNEFPDTVHGFRCMLSVKYLQLLSQDYSPDTLGYELIRDLICILRSRSYVEASCRYRHFYARVESTPASELRQPIHQPCCCPHCPRHKTTGMDKQAYEQEAQDVQDVQKSRCS |
| NCBI Accession | NP_443741.1 |
|---|---|
| Location | 292-1062 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGAGCTGCCGATATCGTCATTTCTACGCCCGCGTCGAAAGTACGCCGGCGTCTGAACTTCGGCAGCCCATACACCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAACAACAGGCATGGACAAACAGGCCTATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTTCCTAGAGGATGTGAAGGTCCATGTAAGGTTCAGTCGTTTGAGTCCAGACATGATATTCAGCATATAGGTAAAGTAATGTGTGTTAGTGATGTTACTCGTGGTACTGGGCTGACCCATAGAGTTGGTAAGAGATTTTGTGTCAAGTCTGTTTATGTGTTGGGTAAGATATGGATGGATGAGAACATTAAGACGAAGAATCACACGAATAGTGTGATGTTTTTCTTGGTTAGAGATCGTAGACCTGTTGATAAACCTCAAGATTTTGGAGAGGTATTTAATATGTTTGATAATGAGCCCAGTACGGCGACTGTGAAGAATGTTCATCGTGATAGGTATCAAGTTCTGCGCAAATGGTATGCAACTGTCACCGGTGGACAATACGCTTCAAAGGAACAGGCTTTGGTCAAGAAGTTTGTCAGAGTTAACAATTATGTTGTTTACAATCAACAGGAAGCAGGAAAATACGAGAATCATACGGAAAATGCGTTAATGCTTTATATGGCTTGTACTCACGCTAGCAACCCTGTTTATGCTACGTTGAAGATTAGGATATATTTTTATGACTCTGTAACGAATTGA |
| Protein Sequence | MSKRAADIVISTPASKVRRRLNFGSPYTSRAAAPIVRVTKQQAWTNRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWYATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | NP_443742.1 |
|---|---|
| Location | 1065-1469 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGGGAATGGCGCATATATCTGGGAGGTTCCAAATCCCCTTTATTTCAAGATCATCAGCCACGTCAACCGTCCATTCACGACGAATATGGACATACTCACGATCAGGATCCAGTTCAACTACAACACGCGGAAAGCTCTGGGACTGCACAAGTGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCTTTTCTTAAGGGTATTCAAAAACCAAGTCCTCAAATATCTGAACAATCTCGGTGTAATTTCAATTAATTTAGTTATTAAAGCTGTAGAACATGTATTGTACAATGTAATCCAACAAACTATGTATGTAGATCAATATTCAGAAATAAAATTTAAACTTTATTAA |
| Protein Sequence | MDSRTGEPITAAQAGNGAYIWEVPNPLYFKIISHVNRPFTTNMDILTIRIQFNYNTRKALGLHKCFLTFRIWTTLQPQTGLFLRVFKNQVLKYLNNLGVISINLVIKAVEHVLYNVIQQTMYVDQYSEIKFKLY |
| NCBI Accession | NP_443743.1 |
|---|---|
| Location | 1162-1614 |
| Gene Name | AC2 |
| Protein Name | transcription activator protein |
| Coding Region | ATGCGATCTTCATCACACTTGATAGACCCATGTACTCAGGTACCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACAGGAGGAGGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTGTCAATCAACTGCCACAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGGGAATGGCGCATATATCTGGGAGGTTCCAAATCCCCTTTATTTCAAGATCATCAGCCACGTCAACCGTCCATTCACGACGAATATGGACATACTCACGATCAGGATCCAGTTCAACTACAACACGCGGAAAGCTCTGGGACTGCACAAGTGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCTTTTCTTAAGGGTATTCAAAAACCAAGTCCTCAAATATCTGAACAATCTCGGTGTAATTTCAATTAA |
| Protein Sequence | MRSSSHLIDPCTQVPIKVQHREAKRRNRRRRVDLECGCSYYLSINCHNHGFTHRGTHHCSSSREWRIYLGGSKSPLFQDHQPRQPSIHDEYGHTHDQDPVQLQHAESSGTAQVFSNLPNLDDLTASDWSFLKGIQKPSPQISEQSRCNFN |
| NCBI Accession | NP_443744.1 |
|---|---|
| Location | 1511-2599 |
| Gene Name | AC1 |
| Protein Name | replication initiator protein |
| Coding Region | ATGCCTCCAAAGCGGAACGGTATTTATTCCAAAAACTATTTCATCACTTATCCCAAATGTTCTCTCACCAAAGAGGAAGCACTTTCCCAATTATTAAATATACAAACCCCAACTTCAAAAAAATATATTAGAATCTGCAGAGAGCTTCACGAAGATGGGACTCCTCACTTGCATGTTCTCATCCAGTTCGAAGGGAATTTCAAGTGCCAGAATATGCGATTCTTCGACTTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACACCGAGAAGGACGGGGACATTCTCGACTGGGGGCAATTTCAGATCGACGGAAGGTCAGCAAGAGGAGGGCAACAGACAGCCAATGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCGGAGGCTCTTAGAGTCATTAAGGAACTAGCTCCTAAGGATTTTGTACTGCAATTTCATAATTTAAATGCAAATCTAGACAGAATCTTTCAGGAGCCACCAGCTCCTTATGTTTCTCCTTTTTCCTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGTGTGGGCTGCCGAGAACGTCGTCAGTGCCGCTGCGCGGGCCAATAGACCAATAAGTGTAGTGATTGAGGGTGACAGTAGGACGGGGAAGACGATGTGGGCCAGATCATTAGGTCCACATAATTATCTGTGTGGACATCTAGATCTGAGCCCAAGGGTATACAGTAATGACGCCTGGTTTAACGTCATTGATGACGTCAACCCACATTACCTAAAGCACTTTAAGGAGTTCATGGGGGCCCAAAAGGACTGGCAATCAAATACAAAATACGGGAAGCCAGTTCAAATTAAAGGCGGAATTCCCACCATCTTCCTCTGCAATCCAGGACCCAATTCTAGCTATAAAGAGTTTTTGGATGAAGAGAAGAATTCTGCACTAAAAAATTGGGCTTTAAAGAATGCGATCTTCATCACACTTGATAGACCCATGTACTCAGGTACCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACAGGAGGAGGAGAGTAGATCTTGA |
| Protein Sequence | MPPKRNGIYSKNYFITYPKCSLTKEEALSQLLNIQTPTSKKYIRICRELHEDGTPHLHVLIQFEGNFKCQNMRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYTEKDGDILDWGQFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDFVLQFHNLNANLDRIFQEPPAPYVSPFSSSSFDQVPEELEVWAAENVVSAAARANRPISVVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPRVYSNDAWFNVIDDVNPHYLKHFKEFMGAQKDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALKNWALKNAIFITLDRPMYSGTNQSTAQGSEEAQQEEESRS |
| NCBI Accession | NP_443745.1 |
|---|---|
| Location | 2143-2445 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGACTCCTCACTTGCATGTTCTCATCCAGTTCGAAGGGAATTTCAAGTGCCAGAATATGCGATTCTTCGACTTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACACCGAGAAGGACGGGGACATTCTCGACTGGGGGCAATTTCAGATCGACGGAAGGTCAGCAAGAGGAGGGCAACAGACAGCCAATGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCGGAGGCTCTTAGAGTCATTAAGGAACTAG |
| Protein Sequence | MGLLTCMFSSSSKGISSARICDSSTWSPQAGQHISIRTYRELNPAPTSNPTPRRTGTFSTGGNFRSTEGQQEEGNRQPMTLTPQHLTREVSRRLLESLRN |
References More References in PubMed
| 1 |
Chen N, et al. J Exp Bot. 2024 Sep 27;75(18):5819-5838. doi: 10.1093/jxb/erae257. PMID: 38829390 |
|---|---|
| 2 |
LbCas12a mediated suppression of Cotton leaf curl Multan virus. Ashraf S, et al. Front Plant Sci. 2023 Aug 11;14:1233295. doi: 10.3389/fpls.2023.1233295. eCollection 2023. PMID: 37636103 |
| 3 |
Cotton leaf curl Multan virus C4 protein suppresses autophagy to facilitate viral infection. Yang M, et al. Plant Physiol. 2023 Aug 31;193(1):708-720. doi: 10.1093/plphys/kiad235. PMID: 37073495 |
| 4 |
Chen T, et al. Front Vet Sci. 2024 Aug 28;11:1417590. doi: 10.3389/fvets.2024.1417590. eCollection 2024. PMID: 39263677 |
| 5 |
Khan MF, et al. Metabolites. 2023 Nov 12;13(11):1148. doi: 10.3390/metabo13111148. PMID: 37999244 |
| 6 |
Farooq T, et al. Front Plant Sci. 2022 Nov 14;13:1040547. doi: 10.3389/fpls.2022.1040547. eCollection 2022. PMID: 36452094 |
| 7 |
Wang J, et al. Front Plant Sci. 2016 Aug 4;7:1162. doi: 10.3389/fpls.2016.01162. eCollection 2016. PMID: 27540385 |
| 8 |
Jain H, et al. J Mol Evol. 2024 Dec;92(6):891-911. doi: 10.1007/s00239-024-10216-6. Epub 2024 Nov 14. PMID: 39542922 |
| 9 |
Yogindran S, et al. Mol Biol Rep. 2021 Mar;48(3):2143-2152. doi: 10.1007/s11033-021-06223-1. Epub 2021 Feb 26. PMID: 33635470 |
| 10 |
Zubair M, et al. Viruses. 2017 Sep 29;9(10):280. doi: 10.3390/v9100280. PMID: 28961220 |