Cotton chlorotic spot virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002867455.1 |
| Isolate |
Brazil |
| Release date |
2018/8/26 |
| Submitter |
de Almeida,M.M., Jain,S., Barroso,P.A., Hoffmann,L.V., de Lucena,M.G., Resende Rde,O., Inoue-Nagata,A.K., Almeida,M.M.S., Barroso,P.A.V., Lucena,M.G., Resende,R.O. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
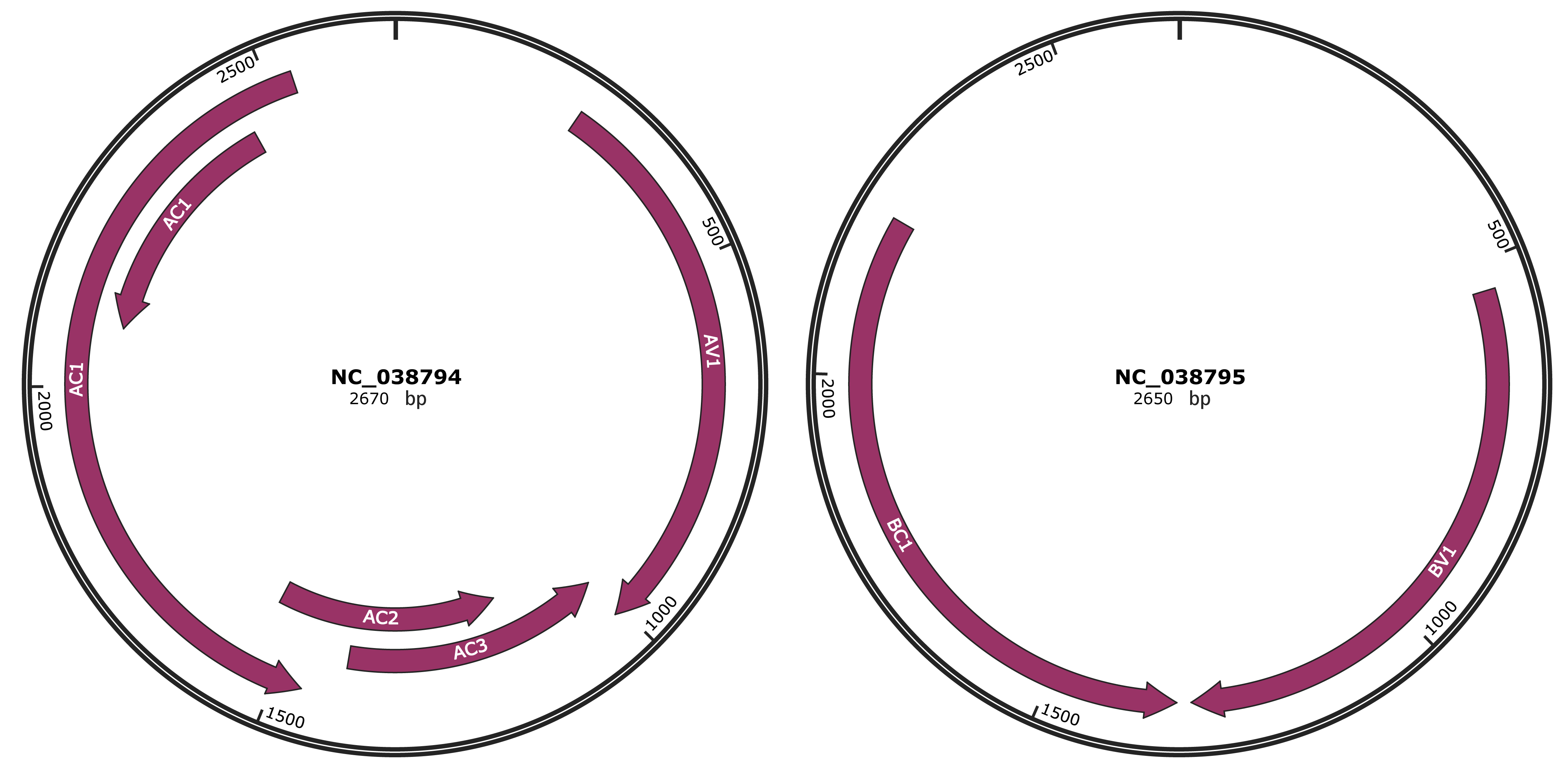
JBrowse
Genome
ACTGATGGCCGCGCGATTTTGGAGTCCGCCTACGTGGCGCGATCTAGGCCGTCCCCCCAGTTGGAGTCCAGACAAGGTTCCGTAAAATGCGGCGCGTTGTCGACTAAAGTGGTCCAGATTACAGAAACGACAAATTTGTTAACCAATCAAAATTTGTCCACGTAGCTTATTTAATTTAAACAACTTGGGCGCTAAGTTTGACACGGTTATATAACTGGCCCATTAAAGTCTTGATGGATCAGGCTTTGTTTAAAGATGCCTAAGCGGGAAGCCCCATGGCGATTGATGGCGGGTACCTCAAAGATTAGCCGCTCTACCAATTTAAATTCGCGTAGAGGAAATGGGTCAACATTCAATAAGGCCGATGCTTGGGTTAATAGGCCGATGTACAGGAAGCCCAAGATATATCGAATAATGAGAACGCCCGACGTTCCACGAGGATGTGAAGGCCCATGTAAGGTCCAGTCGTATGAGCAGCGTCACGATATCTCTCACGCTGGAAAGGTGATTTGTGTATCTGATGTGACACGTGGTAATGGTATTACTCACCGTGTCGGAAAACGTTTCTGTGTTAAGTCTGTATATATTTTAGGGAAGATTTGGATGGATGAGAACATTAAACTGAAGAATCACACGAACAGCGTTATGTTCTGGTTAGTTAGGGACAGGAGACCAAACGGAACACCCATGGATTTTGGGCATTTATTTAATATGTTTGACAACGAGCCCAGTACTGCCACGATTAAGAACGATCTACGTGATCGTTTCCAGGTTATGCATAGATTCTATGCCAAGGTGACAGGTGGACAATATGCTAGCAACGAACAGGCTTTGGTCAAGAGGTTCTGGAAGGTCAACAACCACGTGGTGTATAATAATCAAGAAGCCGCTCGCTACGAGAATCATACTGAGAACGCATTGTTATTGTATATGGCATGTACACATGCTTCGAACCCCGTGTATGCAACTTTGAAAATTCGAATCTATTTTTATGATTCGATATCAAATTAATAAAGTTTAAATTTTATTGAATGATTTTCAAGTACATGACTCACATATGATTTGTCTGTTGCAAAGCGAACAGCTCTTATTACATTATTAAGACAAATGACACCTAATTGATCTAGATACATATTAACTAAGAATTTAAACCTAGCTAAATATGTCGTCCCAGAAGCTGTCATTGATTTCGTCCAGACTTGGAAGTTCAGGAACGCCTTGTGGAGATCCAATACTTTCCTCAGGTTGTGATTGAACCGGATGCTGACGTGATAAATTCTGGTGTTGGTGAACGGTGGGTCTTCCACCCTGGTTATCTTGAAATAAAGGGGATTTTGCACTTCCCAGATAAACACGCCATTCTCCGCTTGAAGTGGCGTGATGAATTCCCCTGTGCGTGAATCCATGTCCCTCGCAGTTGAGGTGTATGAAGAAGGAACAACCACAGGCTAAATCTACACGCTTACGGCGAATGGCCCTCCTCTTGGCTTGCCTGTGTCTGATCTTGATAGAGGGGGGAGTTGAGGAAGATGAATTTAGCATTGTGAAGTGTCCAATTCTTGAGAGCAACATTTTCCTCTTTATCGAGGAAATCTTTATAGCTGGACCCTTCACCAGGATTGCAAAGCACGATTGAGGGAATCCCTCCTTTAATTTGAACAGGCTTTCCGTACTTGCAATTTGATTGCCAGTCTTTTTGTGCACCAATCAACTCCTTCCAATGCTTCATCTTCAGATATTGCGGGTTGATGTCATCGATGACGTTATACTCCGCATTGTTTGAGTAAACCCTTGAATTGAAGTCCAAGTGTCCACTCAAATAATTATGTGGGCCTAAAGCACGAGCCCACATTGTCTTCCCCGTTCGACTATCACCCTCGATGATTATACTAATAGGACGTTCCGGCCGCGCAGCGTGATCAACTCCAAAAAAACTATCTGCCCATTCTTGCATATCGTCTGGAACGTTGACAAAGGAGGAAAGTTGATATGGAGGAATCCATGGTTCCGGGGCTTTTTTAAAGATCCGATCCAGGTTTGATCGGATGTTATGATATTGAACTATGAACGTTTTTGGATCACCATCCTTTATAATGTCAAGAGCCTCCGTCGCAGTTCCCGAATTGACAGCGTTTCGGTAGACGTCATCTTTATTGGCCTTGGTACCCCCATATGGTTTGTATTGTCCGGATTCACAAAAATCACCTCCTTTGGTGATGTAATTTTTGACGGCATCGGAGTTTTTGGCCGGTTGTACGTTTGGGTGAAAACTGGCAGACCTTCTGGGGTGAGTAATGTCGAAAAACCTAACATCCTTGATGTTTGGCTTTCCTGATAATTGGACAAGACAGTGGAGATGTGGGTTTCCGTCACTGTGTTCCTCTCTGGCCACCCTGATGTATGTCGGTTTGACGACTCTCCACTGTAGATTTTGAAGCATTTGAAGAACTTCATCTTTTGGTATGTCACACTGTGGATATGTGACAAAAATATTTTTTGACTGCACGCGTAATTCTTTTGGTTGTCGTGGCATTTTTGTAAATATATAGAGGACTCTTTGTTGGGACTCCGTCCGTACCAGGACTCTCTCAACTTCTGTGATATTTTGCGGAGTCCTGGAGTCCCATTTATACTAGAACTCCCAGACCCGCGGCCATCAACTATAATATT
ACTGATGGCCGCGCGATTTTGGAGTCCGCCTACGTGGCGCGATCTAGGCCGTCCCCCCCAGTTGGAGTCCAGACAAGGTTCCGTAAAATGCGGCGCGTTGTCGGATGTAGTGTTTTTATGACCGTATGATTCATATTTCATGAATTACGTGGCACATTTATATCGGCGCGATTATTTTAACGAATTTAGTTTAGCGCTATTTTGAAATCCGTGAATTTGATTGAGCGCGTTTTTTACGTCCGCCAATGAAAAACGCTCTTTATGGAAATAAAGTTGATGTTATATGATACATTTATGGCCATTGGATAATGCCTAGTTAAATCTGAATAAGTTTTTAAAATTTGAAGTGTGGAAAAATTAAATGACCATTTTCGTACCAATCATATGTCAGGTGGCAGACTGTACGAAATATTTAATGGACCAATGAAATTTCATGATGAACGCTTATAAATCATTTAATGCGTCATGATTTTATATATATTGATAATAATCGCCTAATTGGATAATCGGATAATATTGGTTTTCATTATTCTTGAAAATGTATCCATCTAAATATAGAACAGGAATGTCAACTACTTATCGGCGAAGTTCTACACGGAATCCTGTGTACAAGCGTGCATATGTTGTTAAAAGAGGCAAATGGAAACGTGGTGTTAACAACACAAGGAATTCACATGATGGTGTAAAAATGAAAGAACAGCGAATGCATGAGAATCAGTTTGGGCCTGAGTTTGTAATGGGCCATAACACGGCAATTGCAACGTATATCAATTTTCCTAATCTCGTGAAGACGGAGCCCAATCGTTCCCGGTCGTATATTAAGATTAAACGATTGAGTTTTAAGGGAACAGTTAAGATTGACCGTGTTCCTGTTGATATGAGCATTGAAGGTTCTATTCCTACTACAGAAGGCGTTTTTTCTTTAGTAATCGTTGTTGATCGCAAACCTCACTTGAATTCATCCGGAAGTCTGCATACATTTGATGAGTTGTTTGGTGCAAGGATAAACAGTCATGGTAAATTGGATATTGTTCAATCTTTGAAAGACCGGTTTTATATAAGACATGTTCTTAAACGTGTTTTATCTGCTAATAAAGATACTATGATGATAGATCTTGAAGGAACGATGACTCTCTCTAATAAGCGTAATAATTGTTGGGCGACTTTTAAAGATTTAGATAACGAATCATGTAATGGTGTTTATGCGAATATAAGCAAGAACGCCCTGTTAGTCTATTATTGTTGGATGTCAGATGTTGTGTCTAAAGCATCTACATTTGTATCTTATGATCTTGATTATGTTGGATAAATAAAAACTTTATATTACATCAATTGAGGGATTTCGGCTGCGAAGGGATACAGTTAGTGTTAATACACTCTTGTACTGCAGTCCTAACTATATTGTCTAATTGGGCTTGCGATAATGTGATGTTTGATTGTGTCCGTTGGGCCGCAACTATTGAAGCAGATTCTCCTGGGTCTAGAACTGTTGAACCCAATCTGTTTAGATCTCTGTATGGATATGACGCTTGACCTGTTTCAGACCCCACATCTGATTGGGTTAATCCTATGGTGCTCCTGACAGCCCATGTATCTCCTGGTCTAAGCTCCAATGGGCTCTGGAATCTCGATGCTGATGATGACATTGAACGGATTGTCTTTCTCTCCCATGTCCCGTAGCCAACGTGGTAAAAATCGATGTCTTTTTCTGTGAATTGTTTTGACAATATCTTCACAGTTGGCGCTCGAAATGGGATATCAACGGAATGTTTTGCCGTAGACAACTTCAGTTTACCCTTAAACTTCGCAAAATGGGTCATTTGATGAACATTCGTATCGCAAACCTTATAAAACAACTTCCATGGAATAGGGTCTTTGAGGGAGAAAAATGAAGAAGAGAAAAAGTGTAGATCTATGTTACATCTGATCGGGAAAGTCCATGACGCTTGTAATGATTCATTGTCCGTCATCCTTCTGTCATGAATCTCCACTATTACTGATCCTGTAGCGTTAATAGGGACTTGTTGCCTGTATTCAATGACGCAATGATCGATTTTCATACAGCTTCGACTTATTCTAGCTGTTAATTGCGATGCTGTAGATGGAAATTGCAAGAAAATCTCAGTTAAGTCATGAGAAAGCTGATATTCATCGCGATGTGATTCTATATAATTAAAGGCATTTGGGGGATTAACTAAATGAGAATCCATTAAAAAACACAGGGTCGCGCAGCGAGAGCGTTCAAGTGAAAATGGAGTAGAAAGCGTTCAATTGAAAATGGAACAGAGAGCGTTCAAGTGAAAGTGATTTTGAATATGAAAATAAAAGAAACCCACAACTTCTGAAGATGAAAATGATTTTGAATATAGAAAAGAAAGAAATCAGCAATTAAAGAAGATAAAAGTGATTTTGAATATAGGGATATTGGTTTAACAGATAAGAAGAAAGAATTGTGTAATAATTTAAGTAATGTCAGCCTTTAATTTATAGCAAATGATATAGTTTAGTGGCATTTTTGTAAATATGTAGAGGACTCCATCTTGGGACTCCGTCCGTACCAGGACTCTCTCAACTTCTGTGATATTTTGCGGAGTCCTGGAGTCCCATTTATACTAGAACTCCCAGACCCGCGGCCATCAACTATAATATT
Gene Information
|
NCBI Accession
|
YP_009507985.1
|
|
Location
|
256-1011 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGAAGCCCCATGGCGATTGATGGCGGGTACCTCAAAGATTAGCCGCTCTACCAATTTAAATTCGCGTAGAGGAAATGGGTCAACATTCAATAAGGCCGATGCTTGGGTTAATAGGCCGATGTACAGGAAGCCCAAGATATATCGAATAATGAGAACGCCCGACGTTCCACGAGGATGTGAAGGCCCATGTAAGGTCCAGTCGTATGAGCAGCGTCACGATATCTCTCACGCTGGAAAGGTGATTTGTGTATCTGATGTGACACGTGGTAATGGTATTACTCACCGTGTCGGAAAACGTTTCTGTGTTAAGTCTGTATATATTTTAGGGAAGATTTGGATGGATGAGAACATTAAACTGAAGAATCACACGAACAGCGTTATGTTCTGGTTAGTTAGGGACAGGAGACCAAACGGAACACCCATGGATTTTGGGCATTTATTTAATATGTTTGACAACGAGCCCAGTACTGCCACGATTAAGAACGATCTACGTGATCGTTTCCAGGTTATGCATAGATTCTATGCCAAGGTGACAGGTGGACAATATGCTAGCAACGAACAGGCTTTGGTCAAGAGGTTCTGGAAGGTCAACAACCACGTGGTGTATAATAATCAAGAAGCCGCTCGCTACGAGAATCATACTGAGAACGCATTGTTATTGTATATGGCATGTACACATGCTTCGAACCCCGTGTATGCAACTTTGAAAATTCGAATCTATTTTTATGATTCGATATCAAATTAA |
|
Protein Sequence
|
MPKREAPWRLMAGTSKISRSTNLNSRRGNGSTFNKADAWVNRPMYRKPKIYRIMRTPDVPRGCEGPCKVQSYEQRHDISHAGKVICVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPNGTPMDFGHLFNMFDNEPSTATIKNDLRDRFQVMHRFYAKVTGGQYASNEQALVKRFWKVNNHVVYNNQEAARYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009507986.1
|
|
Location
|
1008-1406 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTCATCACGCCACTTCAAGCGGAGAATGGCGTGTTTATCTGGGAAGTGCAAAATCCCCTTTATTTCAAGATAACCAGGGTGGAAGACCCACCGTTCACCAACACCAGAATTTATCACGTCAGCATCCGGTTCAATCACAACCTGAGGAAAGTATTGGATCTCCACAAGGCGTTCCTGAACTTCCAAGTCTGGACGAAATCAATGACAGCTTCTGGGACGACATATTTAGCTAGGTTTAAATTCTTAGTTAATATGTATCTAGATCAATTAGGTGTCATTTGTCTTAATAATGTAATAAGAGCTGTTCGCTTTGCAACAGACAAATCATATGTGAGTCATGTACTTGAAAATCATTCAATAAAATTTAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITPLQAENGVFIWEVQNPLYFKITRVEDPPFTNTRIYHVSIRFNHNLRKVLDLHKAFLNFQVWTKSMTASGTTYLARFKFLVNMYLDQLGVICLNNVIRAVRFATDKSYVSHVLENHSIKFKLY |
|
NCBI Accession
|
YP_009507987.1
|
|
Location
|
1153-1542 |
|
Gene Name
|
AC2 |
|
Protein Name
|
Trap |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAGATCAGACACAGGCAAGCCAAGAGGAGGGCCATTCGCCGTAAGCGTGTAGATTTAGCCTGTGGTTGTTCCTTCTTCATACACCTCAACTGCGAGGGACATGGATTCACGCACAGGGGAATTCATCACGCCACTTCAAGCGGAGAATGGCGTGTTTATCTGGGAAGTGCAAAATCCCCTTTATTTCAAGATAACCAGGGTGGAAGACCCACCGTTCACCAACACCAGAATTTATCACGTCAGCATCCGGTTCAATCACAACCTGAGGAAAGTATTGGATCTCCACAAGGCGTTCCTGAACTTCCAAGTCTGGACGAAATCAATGACAGCTTCTGGGACGACATATTTAGCTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKIRHRQAKRRAIRRKRVDLACGCSFFIHLNCEGHGFTHRGIHHATSSGEWRVYLGSAKSPLFQDNQGGRPTVHQHQNLSRQHPVQSQPEESIGSPQGVPELPSLDEINDSFWDDIFS |
|
NCBI Accession
|
YP_009507988.1
|
|
Location
|
1463-2533 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACGACAACCAAAAGAATTACGCGTGCAGTCAAAAAATATTTTTGTCACATATCCACAGTGTGACATACCAAAAGATGAAGTTCTTCAAATGCTTCAAAATCTACAGTGGAGAGTCGTCAAACCGACATACATCAGGGTGGCCAGAGAGGAACACAGTGACGGAAACCCACATCTCCACTGTCTTGTCCAATTATCAGGAAAGCCAAACATCAAGGATGTTAGGTTTTTCGACATTACTCACCCCAGAAGGTCTGCCAGTTTTCACCCAAACGTACAACCGGCCAAAAACTCCGATGCCGTCAAAAATTACATCACCAAAGGAGGTGATTTTTGTGAATCCGGACAATACAAACCATATGGGGGTACCAAGGCCAATAAAGATGACGTCTACCGAAACGCTGTCAATTCGGGAACTGCGACGGAGGCTCTTGACATTATAAAGGATGGTGATCCAAAAACGTTCATAGTTCAATATCATAACATCCGATCAAACCTGGATCGGATCTTTAAAAAAGCCCCGGAACCATGGATTCCTCCATATCAACTTTCCTCCTTTGTCAACGTTCCAGACGATATGCAAGAATGGGCAGATAGTTTTTTTGGAGTTGATCACGCTGCGCGGCCGGAACGTCCTATTAGTATAATCATCGAGGGTGATAGTCGAACGGGGAAGACAATGTGGGCTCGTGCTTTAGGCCCACATAATTATTTGAGTGGACACTTGGACTTCAATTCAAGGGTTTACTCAAACAATGCGGAGTATAACGTCATCGATGACATCAACCCGCAATATCTGAAGATGAAGCATTGGAAGGAGTTGATTGGTGCACAAAAAGACTGGCAATCAAATTGCAAGTACGGAAAGCCTGTTCAAATTAAAGGAGGGATTCCCTCAATCGTGCTTTGCAATCCTGGTGAAGGGTCCAGCTATAAAGATTTCCTCGATAAAGAGGAAAATGTTGCTCTCAAGAATTGGACACTTCACAATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAGATCAGACACAGGCAAGCCAAGAGGAGGGCCATTCGCCGTAA |
|
Protein Sequence
|
MPRQPKELRVQSKNIFVTYPQCDIPKDEVLQMLQNLQWRVVKPTYIRVAREEHSDGNPHLHCLVQLSGKPNIKDVRFFDITHPRRSASFHPNVQPAKNSDAVKNYITKGGDFCESGQYKPYGGTKANKDDVYRNAVNSGTATEALDIIKDGDPKTFIVQYHNIRSNLDRIFKKAPEPWIPPYQLSSFVNVPDDMQEWADSFFGVDHAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNNAEYNVIDDINPQYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKDFLDKEENVALKNWTLHNAKFIFLNSPLYQDQTQASQEEGHSP |
|
NCBI Accession
|
YP_009507989.1
|
|
Location
|
2089-2454 |
|
Gene Name
|
AC1 |
|
Protein Name
|
putative AC4 |
|
Coding Region
|
ATGAAGTTCTTCAAATGCTTCAAAATCTACAGTGGAGAGTCGTCAAACCGACATACATCAGGGTGGCCAGAGAGGAACACAGTGACGGAAACCCACATCTCCACTGTCTTGTCCAATTATCAGGAAAGCCAAACATCAAGGATGTTAGGTTTTTCGACATTACTCACCCCAGAAGGTCTGCCAGTTTTCACCCAAACGTACAACCGGCCAAAAACTCCGATGCCGTCAAAAATTACATCACCAAAGGAGGTGATTTTTGTGAATCCGGACAATACAAACCATATGGGGGTACCAAGGCCAATAAAGATGACGTCTACCGAAACGCTGTCAATTCGGGAACTGCGACGGAGGCTCTTGACATTATAA |
|
Protein Sequence
|
MKFFKCFKIYSGESSNRHTSGWPERNTVTETHISTVLSNYQESQTSRMLGFSTLLTPEGLPVFTQTYNRPKTPMPSKITSPKEVIFVNPDNTNHMGVPRPIKMTSTETLSIRELRRRLLTL |
|
NCBI Accession
|
YP_009507990.1
|
|
Location
|
539-1309 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATCCATCTAAATATAGAACAGGAATGTCAACTACTTATCGGCGAAGTTCTACACGGAATCCTGTGTACAAGCGTGCATATGTTGTTAAAAGAGGCAAATGGAAACGTGGTGTTAACAACACAAGGAATTCACATGATGGTGTAAAAATGAAAGAACAGCGAATGCATGAGAATCAGTTTGGGCCTGAGTTTGTAATGGGCCATAACACGGCAATTGCAACGTATATCAATTTTCCTAATCTCGTGAAGACGGAGCCCAATCGTTCCCGGTCGTATATTAAGATTAAACGATTGAGTTTTAAGGGAACAGTTAAGATTGACCGTGTTCCTGTTGATATGAGCATTGAAGGTTCTATTCCTACTACAGAAGGCGTTTTTTCTTTAGTAATCGTTGTTGATCGCAAACCTCACTTGAATTCATCCGGAAGTCTGCATACATTTGATGAGTTGTTTGGTGCAAGGATAAACAGTCATGGTAAATTGGATATTGTTCAATCTTTGAAAGACCGGTTTTATATAAGACATGTTCTTAAACGTGTTTTATCTGCTAATAAAGATACTATGATGATAGATCTTGAAGGAACGATGACTCTCTCTAATAAGCGTAATAATTGTTGGGCGACTTTTAAAGATTTAGATAACGAATCATGTAATGGTGTTTATGCGAATATAAGCAAGAACGCCCTGTTAGTCTATTATTGTTGGATGTCAGATGTTGTGTCTAAAGCATCTACATTTGTATCTTATGATCTTGATTATGTTGGATAA |
|
Protein Sequence
|
MYPSKYRTGMSTTYRRSSTRNPVYKRAYVVKRGKWKRGVNNTRNSHDGVKMKEQRMHENQFGPEFVMGHNTAIATYINFPNLVKTEPNRSRSYIKIKRLSFKGTVKIDRVPVDMSIEGSIPTTEGVFSLVIVVDRKPHLNSSGSLHTFDELFGARINSHGKLDIVQSLKDRFYIRHVLKRVLSANKDTMMIDLEGTMTLSNKRNNCWATFKDLDNESCNGVYANISKNALLVYYCWMSDVVSKASTFVSYDLDYVG |
|
NCBI Accession
|
YP_009507991.1
|
|
Location
|
1329-2210 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCTCATTTAGTTAATCCCCCAAATGCCTTTAATTATATAGAATCACATCGCGATGAATATCAGCTTTCTCATGACTTAACTGAGATTTTCTTGCAATTTCCATCTACAGCATCGCAATTAACAGCTAGAATAAGTCGAAGCTGTATGAAAATCGATCATTGCGTCATTGAATACAGGCAACAAGTCCCTATTAACGCTACAGGATCAGTAATAGTGGAGATTCATGACAGAAGGATGACGGACAATGAATCATTACAAGCGTCATGGACTTTCCCGATCAGATGTAACATAGATCTACACTTTTTCTCTTCTTCATTTTTCTCCCTCAAAGACCCTATTCCATGGAAGTTGTTTTATAAGGTTTGCGATACGAATGTTCATCAAATGACCCATTTTGCGAAGTTTAAGGGTAAACTGAAGTTGTCTACGGCAAAACATTCCGTTGATATCCCATTTCGAGCGCCAACTGTGAAGATATTGTCAAAACAATTCACAGAAAAAGACATCGATTTTTACCACGTTGGCTACGGGACATGGGAGAGAAAGACAATCCGTTCAATGTCATCATCAGCATCGAGATTCCAGAGCCCATTGGAGCTTAGACCAGGAGATACATGGGCTGTCAGGAGCACCATAGGATTAACCCAATCAGATGTGGGGTCTGAAACAGGTCAAGCGTCATATCCATACAGAGATCTAAACAGATTGGGTTCAACAGTTCTAGACCCAGGAGAATCTGCTTCAATAGTTGCGGCCCAACGGACACAATCAAACATCACATTATCGCAAGCCCAATTAGACAATATAGTTAGGACTGCAGTACAAGAGTGTATTAACACTAACTGTATCCCTTCGCAGCCGAAATCCCTCAATTGA |
|
Protein Sequence
|
MDSHLVNPPNAFNYIESHRDEYQLSHDLTEIFLQFPSTASQLTARISRSCMKIDHCVIEYRQQVPINATGSVIVEIHDRRMTDNESLQASWTFPIRCNIDLHFFSSSFFSLKDPIPWKLFYKVCDTNVHQMTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTEKDIDFYHVGYGTWERKTIRSMSSSASRFQSPLELRPGDTWAVRSTIGLTQSDVGSETGQASYPYRDLNRLGSTVLDPGESASIVAAQRTQSNITLSQAQLDNIVRTAVQECINTNCIPSQPKSLN |