Corchorus yellow vein virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000845265.1 |
| Isolate | Viet Nam |
| Release date | 2015/2/12 |
| Submitter | Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
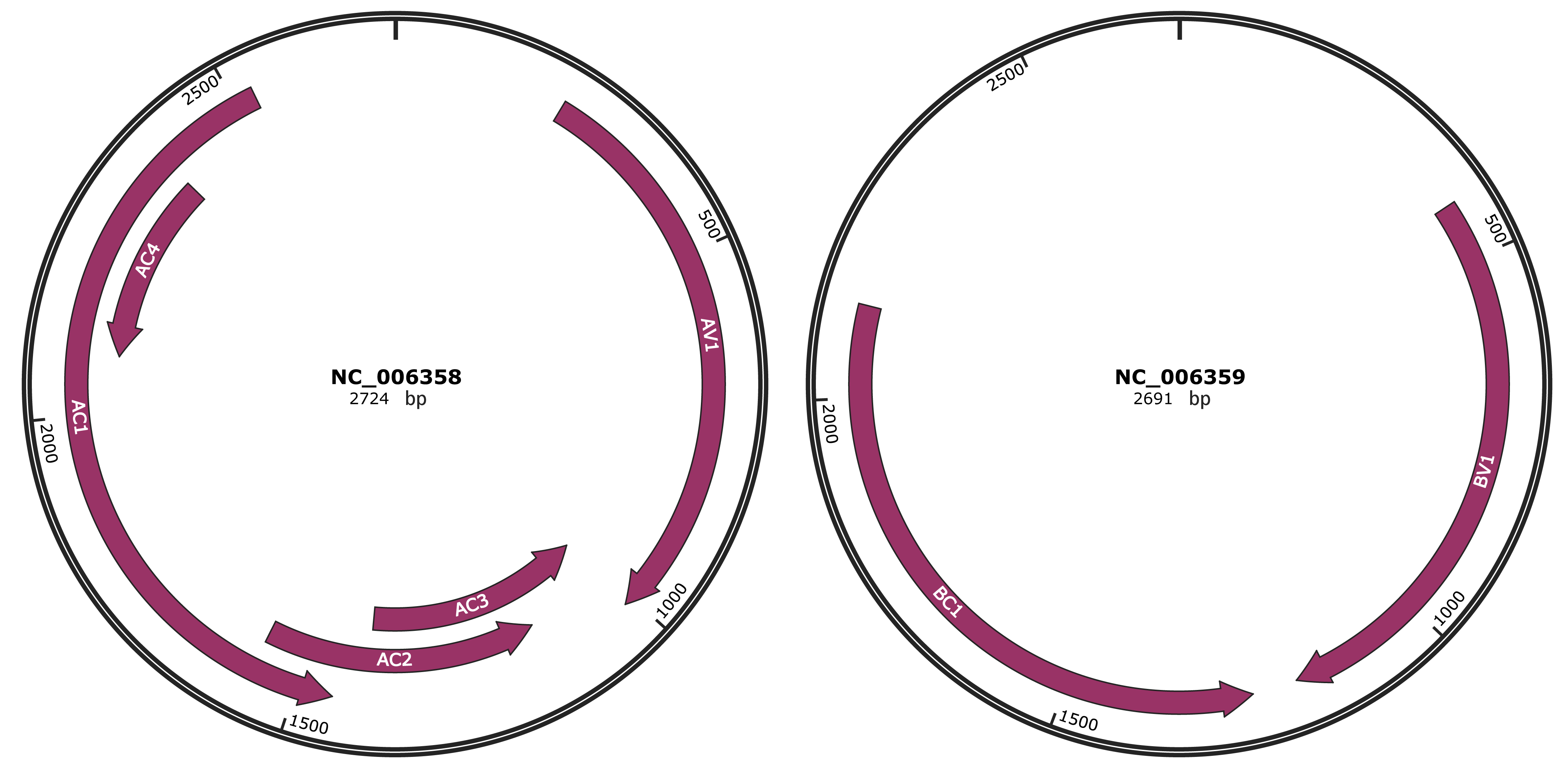
JBrowse
Genome
NC_006358
NC_006359
Gene Information
| NCBI Accession | YP_115508.1 |
|---|---|
| Location | 236-1012 |
| Gene Name | AV1 |
| Protein Name | CP protein |
| Coding Region | ATGCCTAAGCGCGATGCCCCATGGCGCTTGATGGCGGGAACCAGTAAGGTTAGCCGCTCATCTAATTATTCGCCTCGTGGAGGCGTTTCCGACTCAGGTTCTTATCTTCCACGTAGATTTAGCAGGGCCTCACTATGGGCAAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGGACCTATAGGTCCCCTGACGTTCCTAAAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCATTTGAACAGCGTCACGATATTGCTCATACAGGGAAGGTCATATGTTTATCAGATGTTACACGTGGTAATGGTATTACCCACCGTGTTGGTAAACGTTTCTGTGTTAAGTCTGTATATATTTTAGGTAAAATATGGATGGATGAGAATATTAAAGTTAAGAATCACACTAACAGTGTTATGTTCTGGTTAGTTAGGGATAGAAGGCCGTTTGGTTCACCGATGGATTTTGGACAGGTGTTCAACATGTATGATAATGAGCCAAGTACAGCGACAGTTAAGAACGATCTCCGTGATCGTTATCAGGTCATGCATCGGTTTTCTGCAAAGGTTACTGGTGGACAGTATGCTAGCAATGAGCAGGCTCTCGTGAGGCGTTTTTGGAAGGTCAATAACCATGTGGTTTATAACCATCAAGAAGCCGCTAAGTACGAGAATCACACGGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACTTTGAAGATACGGATCTACTTTTATGATTCGATATCTAATTAA |
| Protein Sequence | MPKRDAPWRLMAGTSKVSRSSNYSPRGGVSDSGSYLPRRFSRASLWANRPMYRKPRIYRTYRSPDVPKGCEGPCKVQSFEQRHDIAHTGKVICLSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKVKNHTNSVMFWLVRDRRPFGSPMDFGQVFNMYDNEPSTATVKNDLRDRYQVMHRFSAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_115509.1 |
|---|---|
| Location | 1009-1401 |
| Gene Name | AC3 |
| Protein Name | REn protein |
| Coding Region | ATGGATTTACGCACCGCGGAACCCATCACTGCGTCTCAGGCAGAGAATTCCGCTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATAATCGACGCCTGGGAATACAACCGGAGGAACATACTAATGTTCCAGATCCGGTTCAACCACAACTTGCGGAGGCGTCTTCATCTTCACAAGTGTTTCCTGAATTTCCGCATCTGGACGACATCCAGTTGGCTGATCAGGAGTTTTTTTCAAGTTTTTTGTTCAAGGATTAATCGTTATTTATATAATATAGGTGTTATAGGCATTAATAATGTAATTAGAGCGATTCAATATGCCGTGGATTCACTGCCTTATGTTGAATGTAATGAACAACAGCATATAATAAAATTCAATCTTTATTAA |
| Protein Sequence | MDLRTAEPITASQAENSAFIWEVPNPLYFRIIDAWEYNRRNILMFQIRFNHNLRRRLHLHKCFLNFRIWTTSSWLIRSFFQVFCSRINRYLYNIGVIGINNVIRAIQYAVDSLPYVECNEQQHIIKFNLY |
| NCBI Accession | YP_115510.1 |
|---|---|
| Location | 1139-1564 |
| Gene Name | AC2 |
| Protein Name | TrAP protein |
| Coding Region | ATGACTGGGCCAAGAAGAACTCCATCTACATCACCATCACGGAGCCTCTCTACAGCACCGTCGATCAAGCCTCGACATCGTCACGCCAAGAAAGTGGTTCGTCGGAGACGTATTGATCTGGAGTGTGGCTGCACCATCTACGTCAGCATAAGCTGCCGTGAAGATGGATTTACGCACCGCGGAACCCATCACTGCGTCTCAGGCAGAGAATTCCGCTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATAATCGACGCCTGGGAATACAACCGGAGGAACATACTAATGTTCCAGATCCGGTTCAACCACAACTTGCGGAGGCGTCTTCATCTTCACAAGTGTTTCCTGAATTTCCGCATCTGGACGACATCCAGTTGGCTGATCAGGAGTTTTTTTCAAGTTTTTTGTTCAAGGATTAA |
| Protein Sequence | MTGPRRTPSTSPSRSLSTAPSIKPRHRHAKKVVRRRRIDLECGCTIYVSISCREDGFTHRGTHHCVSGREFRFYLGGSKSPLFQDNRRLGIQPEEHTNVPDPVQPQLAEASSSSQVFPEFPHLDDIQLADQEFFSSFLFKD |
| NCBI Accession | YP_115511.1 |
|---|---|
| Location | 1449-2528 |
| Gene Name | AC1 |
| Protein Name | rep protein |
| Coding Region | ATGGGAAGTCGTTTTGTTAAAACAGCATCTTCTTTTTTTTTAACTTGGCCTAGATGCCCAATCAACAAAGAGTCAGCCTTAGAGCAAATTAAAACACTTTCCCTTCCAACTAATATCGTCTATATTAGGGTTTGCGAAGAAAAACATCAAGATGGCTCTCCGCATCTGCATGCCCTGGTTCAATTCCAGAAGAAGTACAGATGCACGAACTGCAGATTGTTCGATCTATCCAATCCAAATTCATCACAACAATACCATTGTAATATACAGACTGCACGCTCCTCCTCCGACGCCAAATCGTACATCGAAAAAGATGGAGTATTCTGCGAATGGGGTGAATTCAAGATCGACGGCCGATCATCCAGAGGAGGACAACAATCCGCAAACGATGCATACGCTAAAGCACTTAACAGCGGAGGTAAGGACGAAGCTCTCACAATAATTAAGGAATTACTTCCAAAAGATTATGTTTTACAGTATCATAATCTTAACGCTAATCTAGAGCGAATATTCGCTCCACCAACAACAGTATACATGCCGCCATTCCAAACGACGACGTTTAACAATGTACCGGAAGCATTAACAGATTGGGTCACAACAAATGTGGCCGATTCCGCTGCGCGGCCTTTCAGACCTATATCCATAATAATCGAAGGCCCATCCAGAACAGGTAAAACATTATGGGCCAGGAGTTTAGGCCCTCACAATTATCTGTGTGGGCATTTGGATCTTAGCCCAAAAGTATACTCTAATAATGCGTGGTATAACGTCATTGATGACGTAGATCCGCACTTCCTCAAACATATGAAGGAATTTATGGGGGCCCAGAGAGACTGGCAATCGAACTGCAAGTACGGGAAACCTATTCAAATTAAAGGAGGAATCCCAACAATCTTCCTCTGCAATCCTGGTCCACAATCTTCATATAAGGAGTTCTTCGAAGAGGAAAAGAACAAAGCAATCAATGACTGGGCCAAGAAGAACTCCATCTACATCACCATCACGGAGCCTCTCTACAGCACCGTCGATCAAGCCTCGACATCGTCACGCCAAGAAAGTGGTTCGTCGGAGACGTATTGA |
| Protein Sequence | MGSRFVKTASSFFLTWPRCPINKESALEQIKTLSLPTNIVYIRVCEEKHQDGSPHLHALVQFQKKYRCTNCRLFDLSNPNSSQQYHCNIQTARSSSDAKSYIEKDGVFCEWGEFKIDGRSSRGGQQSANDAYAKALNSGGKDEALTIIKELLPKDYVLQYHNLNANLERIFAPPTTVYMPPFQTTTFNNVPEALTDWVTTNVADSAARPFRPISIIIEGPSRTGKTLWARSLGPHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHFLKHMKEFMGAQRDWQSNCKYGKPIQIKGGIPTIFLCNPGPQSSYKEFFEEEKNKAINDWAKKNSIYITITEPLYSTVDQASTSSRQESGSSETY |
| NCBI Accession | YP_115512.1 |
|---|---|
| Location | 2087-2377 |
| Gene Name | AC4 |
| Protein Name | C4 protein |
| Coding Region | ATGGCTCTCCGCATCTGCATGCCCTGGTTCAATTCCAGAAGAAGTACAGATGCACGAACTGCAGATTGTTCGATCTATCCAATCCAAATTCATCACAACAATACCATTGTAATATACAGACTGCACGCTCCTCCTCCGACGCCAAATCGTACATCGAAAAAGATGGAGTATTCTGCGAATGGGGTGAATTCAAGATCGACGGCCGATCATCCAGAGGAGGACAACAATCCGCAAACGATGCATACGCTAAAGCACTTAACAGCGGAGGTAAGGACGAAGCTCTCACAATAA |
| Protein Sequence | MALRICMPWFNSRRSTDARTADCSIYPIQIHHNNTIVIYRLHAPPPTPNRTSKKMEYSANGVNSRSTADHPEEDNNPQTMHTLKHLTAEVRTKLSQ |
| NCBI Accession | YP_115513.1 |
|---|---|
| Location | 423-1184 |
| Gene Name | BV1 |
| Protein Name | NSP protein |
| Coding Region | ATGTATACTATGCGGTATAGACATGGAGCTCCTCTCTCTGTACGACGACCAATTTATAGACGGACTTATGTCCGTCGGTTCCCGGTTAGACGTCCTCCCGTCCGACGTCAGCTCTCGTTTTCCAACAAACCCGCTGATGATAAGATGACCAAACAGCGTCTCCATGAGAATCAATATGGCACACAGTATGCCATATCCAACAACACTTCTATCCCGTCTTTTGTGACATACCCACGCCTAGGTGGACCTTCTCCCAATAGGTCCAGGGATTACATGAAGCTGAACCGTCTGCGGTACAAGGGTACCGTTACCATAAACAACACCCAGCCCGATGTTACAATGTCTGGAGAAACCAAGATAGAGGGTGTATTCACAATGGCGATTGTGATGGACCGGAAACCACATGTTGGCCCATCTGGTTCGCTTCCCAAGTTTGAGGAGCTTTTTGGTGCAAATACCTTCAGTCATGGCAGTCTTGACATTGCGGCCCATTTGAAGGACCGGTACTATGTGCGTCACGTTTGTAAACGGGTTATATCTATGGAGAAGGACTCTACCATTTTGAACTTGACTGGGTCCATGAGTTTATCTTCATCACGATTCACGTGTTGGGCCTCGTTCAAGGATTTGAATGTTGATAGTTGTAATGGGGCGTACAGTAACGTCGCCAAGAACGCCATACTTGTATATTATTGTTGGATGTCGGACGAACCGTCACGTGCATCCACGTTTGTATCGTTTGATTTGGATTACTTGGGTTAA |
| Protein Sequence | MYTMRYRHGAPLSVRRPIYRRTYVRRFPVRRPPVRRQLSFSNKPADDKMTKQRLHENQYGTQYAISNNTSIPSFVTYPRLGGPSPNRSRDYMKLNRLRYKGTVTINNTQPDVTMSGETKIEGVFTMAIVMDRKPHVGPSGSLPKFEELFGANTFSHGSLDIAAHLKDRYYVRHVCKRVISMEKDSTILNLTGSMSLSSSRFTCWASFKDLNVDSCNGAYSNVAKNAILVYYCWMSDEPSRASTFVSFDLDYLG |
| NCBI Accession | YP_115514.1 |
|---|---|
| Location | 1246-2124 |
| Gene Name | BC1 |
| Protein Name | MP protein |
| Coding Region | ATGGAATCACAATTAGCTCAAGCTCCTAGTTCTTTTAATTACATAGAATCACATAGGGACGAATATCGTCTGACTCATGACCTAACAGAGATTGTTCTACAGTTTCCGTCTACGGCGGAACAGTGGGGTGCGACTGTCAGGCGTCGATGCATGAAGATCGACCACTGCGTCATAGAGTACCGACAACAGGTACCGATTAACGCCACAGGGTCCGTCATAGTGGAGATTCACGACAAGCGCATGACGGATAACGAGTCCTTACAGGCGTCGTACACCTTTCCCATAAGGTGCAACATAGATCTGCACTATTTCTCCGCCTCTTTCTTCTCTCTGAAAGATCCCATCCCATGGAAGCTGTACTACAGGGTATCTGATACCAATGTACATCAGGGGACCCATTTCGCAAAATTCAAGGGCAAACTGAAGATGTCGACAGCAAAGCACTCTGTTGATGTCATATTCCGTTCCCCGACGGTAAAGATACTCTCCAAGCAGTTCACCGGCAAAGATATCGACTTTTCCCATGTGGACTACGGCAAGGTCGAGAGGAAGCTGGTGAAGTGCGAGTCCTCCAGTCGACTGGGCCTGCACTCGGCAATAGAATTAAGGCCTGGTGAATCATGGGCCACGCGTAGCTGTATTGGGCCTGATACCATGGAGACAGAATCCGAGGTGCACAACAGGAACCACCCGTATCGTGAACTCAACAGACTCAGCACAAGTATGCTGGATCCAGGGGACTCCGCCTCAATGATCGGTGCTTCCCGGGCTGAGTCCAACATAACACTTACTAGAGCCCAGTTGCAGGAACTAGTCAGTAGCACGGTCGAACATTGTATTAATCGTAATTGTACGCCCCATCAGGCGAAACCATTATAA |
| Protein Sequence | MESQLAQAPSSFNYIESHRDEYRLTHDLTEIVLQFPSTAEQWGATVRRRCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASYTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQGTHFAKFKGKLKMSTAKHSVDVIFRSPTVKILSKQFTGKDIDFSHVDYGKVERKLVKCESSSRLGLHSAIELRPGESWATRSCIGPDTMETESEVHNRNHPYRELNRLSTSMLDPGDSASMIGASRAESNITLTRAQLQELVSSTVEHCINRNCTPHQAKPL |
References More References in PubMed
| 1 |
PLOS ONE Editors. PLoS One. 2023 Jun 14;18(6):e0286780. doi: 10.1371/journal.pone.0286780. eCollection 2023. PMID: 37315010 |
|---|---|
| 2 |
Arif M, et al. PLoS One. 2021 May 14;16(5):e0251232. doi: 10.1371/journal.pone.0251232. eCollection 2021. PMID: 33989327 |
| 3 |
Corchorus yellow vein virus, a New World geminivirus from the Old World. Ha C, et al. J Gen Virol. 2006 Apr;87(Pt 4):997-1003. doi: 10.1099/vir.0.81631-0. PMID: 16528050 |
| 4 |
Dokka N, et al. Virus Res. 2021 Oct 2;303:198521. doi: 10.1016/j.virusres.2021.198521. Epub 2021 Jul 24. PMID: 34314770 |
| 5 |
Arif M, et al. Methods. 2020 Nov 1;183:43-49. doi: 10.1016/j.ymeth.2019.11.010. Epub 2019 Nov 20. PMID: 31759050 |
| 6 |
Sohrab SS, et al. 3 Biotech. 2018 Feb;8(2):92. doi: 10.1007/s13205-018-1120-7. Epub 2018 Jan 24. PMID: 29430354 |
| 7 |
Fiallo-Olivé E, et al. Front Microbiol. 2020 Jul 23;11:1755. doi: 10.3389/fmicb.2020.01755. eCollection 2020. PMID: 32793176 |
| 8 |
Fiallo-Olivé E, et al. Arch Virol. 2012 Jan;157(1):141-6. doi: 10.1007/s00705-011-1123-8. Epub 2011 Oct 1. PMID: 21964921 |
| 9 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |
| 10 |
Hernández-Zepeda C, et al. Virus Genes. 2007 Oct;35(2):369-77. doi: 10.1007/s11262-007-0080-5. Epub 2007 Feb 15. PMID: 17638064 |