Corchorus golden mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000873405.1 |
| Isolate | Viet Nam: Hanoi |
| Release date | 2015/2/13 |
| Submitter | Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
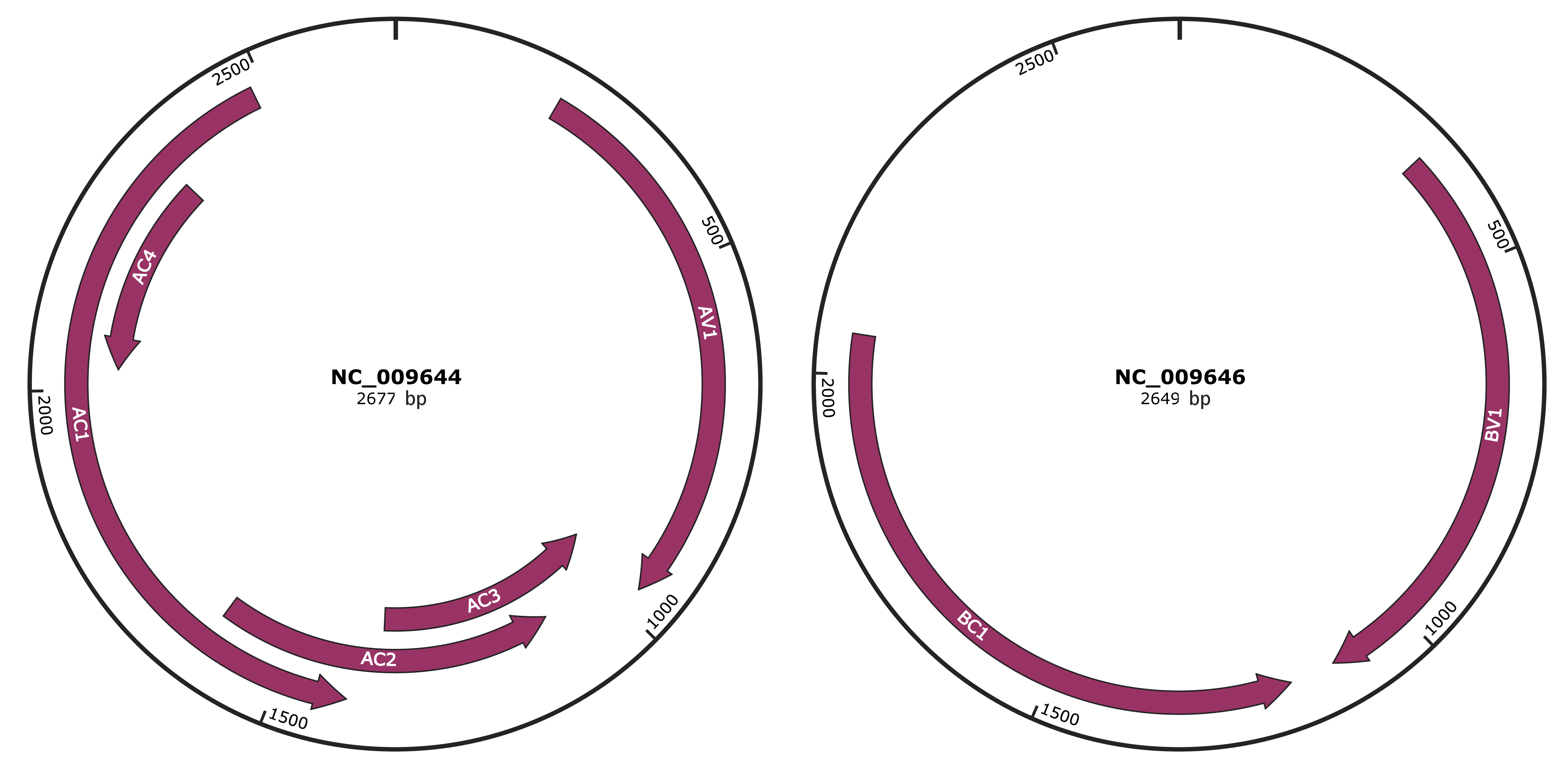
JBrowse
Genome
NC_009644
NC_009646
Gene Information
| NCBI Accession | YP_001333684.1 |
|---|---|
| Location | 225-968 |
| Gene Name | AV1 |
| Protein Name | CP protein |
| Coding Region | ATGAAACGTGAGGCCCCATGGCGTACGAATGCTGGGACCTCCAAGGTACGTCGCGCTTTAAATTTCTCCCCTCGTAGTGGATTGGGCCCAAAAGCGTCTGCTTGGGTTAATCGGCCCATGTATAGAAAGCCCAGGATTTATCGAACGTATAGATCACCTGATGTTCCAAAGGGCTGTGAAGGCCCTTGTAAGGTACAGTCATTTGAACAGCGTCACGACATTTCTCATGTCGGCAAGGTCATGTGTATATCCGATGTCACACGTGGTAATGGTATCACGCATCGTGTTGGTAAACGTTTTTGTATTAAGTCTGTTTATATCCTAGGTAAAGTATGGATGGACGATAATATTAAACTTAAGAACCACACTAACAGTGTTATGTTCTGGTTAGTTAGGGATAGGAGACCGTATGGTACTCCCATGGATTTTGGACAGGTTTTTAACATGTATGATAACGAGCCGAGTACCGCTACTATCAAGAACGATCTCCGTGATCGTTACCAGGTTTTGCATAGGTTTGCGTCGAAGGTTACTGGTGGACAGTATGCTAGCAACGAACAGTCTCTTGTGAGACGATTCTGGAAGGTGAACAACCATGTGGTGTACAACCATCAAGAAGCTGCTAAGTACGATAATCACACTGAGAATGCATTATTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACTTTAAAGATACGGATCTATTTCTATGATTCGATATCAAATTAA |
| Protein Sequence | MKREAPWRTNAGTSKVRRALNFSPRSGLGPKASAWVNRPMYRKPRIYRTYRSPDVPKGCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCIKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATIKNDLRDRYQVLHRFASKVTGGQYASNEQSLVRRFWKVNNHVVYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_001333685.1 |
|---|---|
| Location | 965-1357 |
| Gene Name | AC3 |
| Protein Name | REn protein |
| Coding Region | ATGGATTTACGCACAGGGGATCCCATCACTGCATATCAGGCAGAGAGTTCCGTTTTTACTTGGAGGGTTCCAAATCCCCTCTATTTCAAGATAATATCTGTCACAGATCTAGGTGCGAGACACCTACTATTGCTGCAGATAAGATTCAACCACAACCTGAGGAAAGCACTTCAGCTCCACAAGTGCTACCTGAATTTCAGGGTTCGGACGACCTCCAGATGGAGGATTTCGAGTTTCTTTCAAGTATTTTCTTCCCGAATTAGACGTTACTTAGATGATTTAGGTGCCATTGGCATAAACAATGTAATTAGAGCGATTGCACATGCTGCTGATACGCTCGTATATGTACATGTTGAAGAAGAAAATCATATAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDLRTGDPITAYQAESSVFTWRVPNPLYFKIISVTDLGARHLLLLQIRFNHNLRKALQLHKCYLNFRVRTTSRWRISSFFQVFSSRIRRYLDDLGAIGINNVIRAIAHAADTLVYVHVEEENHIIKFNIY |
| NCBI Accession | YP_001333686.1 |
|---|---|
| Location | 1095-1610 |
| Gene Name | AC2 |
| Protein Name | TrAP protein |
| Coding Region | ATGGAGGGATTCCAACAATCTTCCTCTGCAATCCTGGGCCTACTTCATCATATAAGGAGTTCTTCGAAGAGGAAAAGAACAAAGCAATCAATGACTGGGCCAAAAAAAACGTCATCTACGTCACCATCGAAGAGCCATTCTTTAATACCACAAATCAAGAATCGACATCGGCACTCGAAGAAAGTAATTCGTCGGAGACGAATTGACCTGGAATGCGGTTGCTCCATATATGTGAGCATCCACTGCAGAGACGATGGATTTACGCACAGGGGATCCCATCACTGCATATCAGGCAGAGAGTTCCGTTTTTACTTGGAGGGTTCCAAATCCCCTCTATTTCAAGATAATATCTGTCACAGATCTAGGTGCGAGACACCTACTATTGCTGCAGATAAGATTCAACCACAACCTGAGGAAAGCACTTCAGCTCCACAAGTGCTACCTGAATTTCAGGGTTCGGACGACCTCCAGATGGAGGATTTCGAGTTTCTTTCAAGTATTTTCTTCCCGAATTAG |
| Protein Sequence | MEGFQQSSSAILGLLHHIRSSSKRKRTKQSMTGPKKTSSTSPSKSHSLIPQIKNRHRHSKKVIRRRRIDLECGCSIYVSIHCRDDGFTHRGSHHCISGREFRFYLEGSKSPLFQDNICHRSRCETPTIAADKIQPQPEESTSAPQVLPEFQGSDDLQMEDFEFLSSIFFPN |
| NCBI Accession | YP_001333687.1 |
|---|---|
| Location | 1405-2484 |
| Gene Name | AC1 |
| Protein Name | rep protein |
| Coding Region | ATGAGCGGTCGTTTTAAGAAACAAGGCGTTTCTTTTTTCCTCACGTGGCCAAAATGCCCAGTTACTAAAGAGTCAGCCTTAGACCAAATACAAGCATTAACCCTTCCAACCAACATCGTTTATATTAGAGTCTGTGAGGAAAAACATCAAGATGGGTCGCCTCACCTGCATGCCTTGGTTCAATTCCAGAAAAAATTCATCTGCACAAATTGTCGATTATTCGACCTCTCCCATCCACAGAACTCACGTCAATTCCACTGTCACATTGAAACTGCGCGCTCCTCCTCCGACGCCAAATCATATATCGAAAAAGATGGAGTGTTCTGCGAATGGGGCACTTTCCAGGTGGACGGAAGATCGGCGAGAGGCGGTCAACAGACAGTTAATGAGGCTTATGCAAAGGCGCTTAACAGCGGAAGTAAGGACGAGGCTCTTAATATCATTAAGGAGTTAGTTCCAAAGGATTATGTATTACAATTTCATAATCTTAATCAAAATTTGGAGAGGATCTTTGCTCCTCCAGTTAATGTTTTTGAGCCACCGTTCCCACTATCATCGTTTAATAACGTTCCTGCTGTTATTAATCAGTGGGTTAACGATAATATAATGGATGCCGCTGCGCGGCCCTTTAGGCCGATATCTATTATCATTGAAGGTCCATCTAGGACAGGGAAAACATTATGGGCCAGAAGTTTGGGTCGTCACAATTATCTTTGTGGACATCTTGATCTAAGCCCAAAAGTGTATTCAAATGAGGCCTGGTACAACGTCATTGATGATGTCGACCCGCACTATCTAAAGCATATGAAGGAATTTATGGGGGCCCAGAGAGACTGGCAGTCCAACTGCAAGTACGGCAAACCAATTCAAATAAATGGAGGGATTCCAACAATCTTCCTCTGCAATCCTGGGCCTACTTCATCATATAAGGAGTTCTTCGAAGAGGAAAAGAACAAAGCAATCAATGACTGGGCCAAAAAAAACGTCATCTACGTCACCATCGAAGAGCCATTCTTTAATACCACAAATCAAGAATCGACATCGGCACTCGAAGAAAGTAATTCGTCGGAGACGAATTGA |
| Protein Sequence | MSGRFKKQGVSFFLTWPKCPVTKESALDQIQALTLPTNIVYIRVCEEKHQDGSPHLHALVQFQKKFICTNCRLFDLSHPQNSRQFHCHIETARSSSDAKSYIEKDGVFCEWGTFQVDGRSARGGQQTVNEAYAKALNSGSKDEALNIIKELVPKDYVLQFHNLNQNLERIFAPPVNVFEPPFPLSSFNNVPAVINQWVNDNIMDAAARPFRPISIIIEGPSRTGKTLWARSLGRHNYLCGHLDLSPKVYSNEAWYNVIDDVDPHYLKHMKEFMGAQRDWQSNCKYGKPIQINGGIPTIFLCNPGPTSSYKEFFEEEKNKAINDWAKKNVIYVTIEEPFFNTTNQESTSALEESNSSETN |
| NCBI Accession | YP_001333688.1 |
|---|---|
| Location | 2031-2333 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGTCGCCTCACCTGCATGCCTTGGTTCAATTCCAGAAAAAATTCATCTGCACAAATTGTCGATTATTCGACCTCTCCCATCCACAGAACTCACGTCAATTCCACTGTCACATTGAAACTGCGCGCTCCTCCTCCGACGCCAAATCATATATCGAAAAAGATGGAGTGTTCTGCGAATGGGGCACTTTCCAGGTGGACGGAAGATCGGCGAGAGGCGGTCAACAGACAGTTAATGAGGCTTATGCAAAGGCGCTTAACAGCGGAAGTAAGGACGAGGCTCTTAATATCATTAAGGAGTTAG |
| Protein Sequence | MGRLTCMPWFNSRKNSSAQIVDYSTSPIHRTHVNSTVTLKLRAPPPTPNHISKKMECSANGALSRWTEDRREAVNRQLMRLMQRRLTAEVRTRLLISLRS |
| NCBI Accession | YP_001333689.1 |
|---|---|
| Location | 345-1112 |
| Gene Name | BV1 |
| Protein Name | NSP protein |
| Coding Region | ATGTATATTGGTAAAGGTATACGTTATAGCAACAACACCATGAATCGTGCTAAGTACAACAGACCTGTTGGTCGTCGATCTTTTGTGTATAGGCGCGGTCCTAAAGTACGTGTTAATCAGTCTGTCCCAAAGTCACAGGGTGACAAGATGACCAGACAGCGTATCCATGAAAATCAGTATGGCGTACAGTATTCCCTATTAAACAATACGTCCAGTGTGTCTTTTATCACATATCCTAGATTAGGTGGGCCTGAGCCCAATAGAAGTCGGGCTTACATAAAATTGAATAGGCTTCGTTACAAGGGGACTGTTAATATTGAATGTTCAGATCCAGATGTTGGAATGGATCCCAATCGTGGTGGGCTTTCTGGTGTCTTCACTCTGGCTATTGTTGTTGATAGGAAACCTCATGTTGGACCTACTGGTTCATTGCCATCATTTGACGATCTGTTTGGTTGTAATCTGTACAGCAATGGGAGCCTTGATATCTCACCCCAGATGAAGCAGCGTTACTACATTCGGCACGTACACAAACGTGTCGTATCTTATGAGAAGGATTCTATCATGATGAACATATCGGGCAATATGGGATTATCTTCCCCTAAATATGTATGTTGGTCCTCATTCAAGGACCTTGATGTGGATAGTTGTACTGGGAGCTATTCTAATCTAGCTAAGAATGCTCTTTTAGTTTATTATTGTTGGGTTTCGAACATGCCTTCTAAGGCATCATCATTTGTATCTTTTGACCTGGATTATCTGGGTTAA |
| Protein Sequence | MYIGKGIRYSNNTMNRAKYNRPVGRRSFVYRRGPKVRVNQSVPKSQGDKMTRQRIHENQYGVQYSLLNNTSSVSFITYPRLGGPEPNRSRAYIKLNRLRYKGTVNIECSDPDVGMDPNRGGLSGVFTLAIVVDRKPHVGPTGSLPSFDDLFGCNLYSNGSLDISPQMKQRYYIRHVHKRVVSYEKDSIMMNISGNMGLSSPKYVCWSSFKDLDVDSCTGSYSNLAKNALLVYYCWVSNMPSKASSFVSFDLDYLG |
| NCBI Accession | YP_001333690.1 |
|---|---|
| Location | 1174-2052 |
| Gene Name | BC1 |
| Protein Name | MP protein |
| Coding Region | ATGAGTTCTCAATTAGCTAACGCTCCCAATTCTTTTAATTATATTGAGTCTAATAGAGACGAGTACAGACTCACCCATGATCTCACAGAGATTGTGCTGCAATTCCCATCAACTGCAGAACAATGGGGTGCAACTGTAAGGAGGAGGTGCATGAAGATAGATCATTGTGTCATCGAGTACAGACAACAGGTGCCAATTAACGCTTCTGGCTCAGTAATTGTCGAGATTCATGACACACGCATGAATGACAACGAGTCATTACAGACGACATACACCTTCCCAATTAGATGCAACATTGATCTCCACTACTTCTCTGCATCCTTCTTCTCACTCAAGGATCCTATTCCATGGAAGCTGTACTACAGGGTGTCAGACACTAATGTCAACCAGGGAACACATTTCGCCAAGTTCAAGGGCAAGCTGAAGATGTCCACAGCCAAGCACTCCGTTGATGTCGTTTTTCGCTCTCCCACCGTGAAGATACTATCTAAGCAGTTCACCGGGAAAGATATAGACTTCTCCCATGTGGAATATGGGAAGGTCGAGAGGAAGCTGATCAAATCAGCTTCATCATCAAGGTCAGCCCTCCATTCGGCAATCGAACTAAGGCCCGGTGAATCTTGGGCCACAAGGAGCTCAGTTGGAGTGGACATTAACGAGACAGAGTCCGACGTAGCCCATAACAGACACCCATACAGAGAGCTTCACAGGCTGAGCACAAGCATGCTAGACCCAGGTGACTCGGCATCACTGGTTGCAGCTGCGCGGTCCGAGTCCAACATCACACTTAGCAGGGCACAATTACAAGAACTTGTCAATAGCACTGTCGATTTATGCATTAATAGAAATTGTACGCCTCAACAGGCTAAACCATTATGA |
| Protein Sequence | MSSQLANAPNSFNYIESNRDEYRLTHDLTEIVLQFPSTAEQWGATVRRRCMKIDHCVIEYRQQVPINASGSVIVEIHDTRMNDNESLQTTYTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVNQGTHFAKFKGKLKMSTAKHSVDVVFRSPTVKILSKQFTGKDIDFSHVEYGKVERKLIKSASSSRSALHSAIELRPGESWATRSSVGVDINETESDVAHNRHPYRELHRLSTSMLDPGDSASLVAAARSESNITLSRAQLQELVNSTVDLCINRNCTPQQAKPL |
References More References in PubMed
| 1 |
Ghosh R, et al. Indian J Virol. 2012 Jun;23(1):70-4. doi: 10.1007/s13337-012-0062-7. Epub 2012 Mar 25. PMID: 23730007 |
|---|---|
| 2 |
Biswas C, et al. Lett Appl Microbiol. 2013 May;56(5):373-8. doi: 10.1111/lam.12058. Epub 2013 Mar 6. PMID: 23413927 |
| 3 |
[No authors listed] Lett Appl Microbiol. 2026 Jan 14;79(1):ovag005. doi: 10.1093/lambio/ovag005. PMID: 41609316 |
| 4 |
Collins A, et al. Virus Res. 2010 Jun;150(1-2):148-52. doi: 10.1016/j.virusres.2010.03.008. Epub 2010 Mar 25. PMID: 20347895 |
| 5 |
Characterization of sida golden mottle virus isolated from Sida santaremensis Monteiro in Florida. Al-Aqeel HA, et al. Arch Virol. 2018 Oct;163(10):2907-2911. doi: 10.1007/s00705-018-3903-x. Epub 2018 Jun 21. PMID: 29931396 |
| 6 |
Biswas C, et al. Plant Dis. 2014 Nov;98(11):1592. doi: 10.1094/PDIS-07-14-0668-PDN. PMID: 30699809 |
| 7 |
Two new begomoviruses infecting tomato and Hibiscus sp. in the Amazon region of Brazil. Quadros AFF, et al. Arch Virol. 2019 Jul;164(7):1897-1901. doi: 10.1007/s00705-019-04245-6. Epub 2019 Apr 10. PMID: 30972592 |
| 8 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |
| 9 |
Fiallo-Olivé E, et al. Arch Virol. 2012 Jan;157(1):141-6. doi: 10.1007/s00705-011-1123-8. Epub 2011 Oct 1. PMID: 21964921 |
| 10 |
Ha C, et al. J Gen Virol. 2008 Jan;89(Pt 1):312-326. doi: 10.1099/vir.0.83236-0. PMID: 18089756 |