Common bean severe mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002366145.2 |
| Isolate | Cuba |
| Release date | 2018/12/27 |
| Submitter | Chang-Sidorchuk,L., Gonzalez-Alvarez,H., Navas-Castillo,J., Fiallo-Olive,E., Martinez-Zubiaur,Y. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
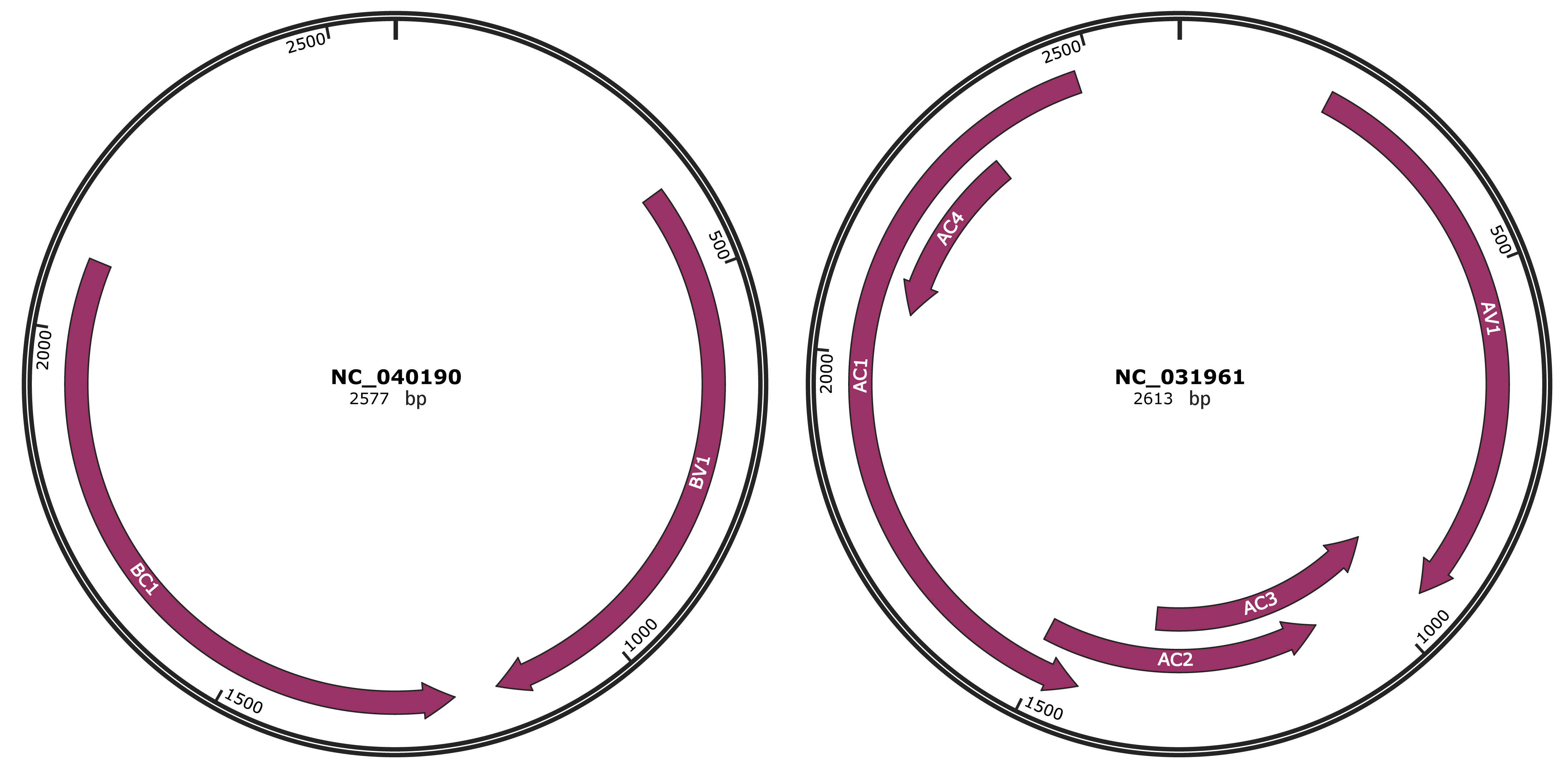
JBrowse
Genome
NC_040190
NC_031961
Gene Information
| NCBI Accession | YP_009547940.1 |
|---|---|
| Location | 386-1156 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATCCAAGAAAATATAGGCGCGGTTCATTTTATTCACATCGACGCTCAAATAATGTGTTTAAGCGATCCACCTATGTTAAAGGAAAGGATGTTAAAGATGGTAAGCGTCGATTAAATTATGGCAGCAATGTTCATGATGATTCCAAAATGTCATCTAAACGTATACATGAGAATCAGTATGGGCCTGATTTTGTGTTAGCCCATAATGCTGCCATCTCTACGTTCATTAGTTATCCTCATTTGGGTAAGACGGAACCCAATCGATCCAGGTCATATATTAAGTTGAAACGTTTACGTTTCAAAGGCACGGTGAAATTTGAACGTGTTCATGCTGATGTGAATATGGATGGTTTATGTCCCAAAATAGACGGAGTATTTTCTCTTGTTATTGTTATGGACCGCAAACCTCATCTCAGTGCGTCTGGGGTTTTGCATACCTTTGATGAACTATTCGGTGCAAGAATACATAGTCATGGTAACCTGTGCATAACCCCAGCTTTGAAAGACCGCTTCTATATTCGTCATGTATTAAAGCGAGTTGTATCTGTGGAGAAGGACACTGCAATGATTGACCTTGATGGATCGATTGGGTTATCTACTCGTCGTTTTAATTGTTGGGCTACATTTAAAGACCTTGATCATGATTCATCTAATGGGGTGTATGATAATATAAGTAAAAACGCTATCTTAGTTTATTATTGTTGGATGTCGGATGCCATGTCTAAAGCATCCACATTTGTATCGTTCGATCTTGATTATGTTGGCTGA |
| Protein Sequence | MYPRKYRRGSFYSHRRSNNVFKRSTYVKGKDVKDGKRRLNYGSNVHDDSKMSSKRIHENQYGPDFVLAHNAAISTFISYPHLGKTEPNRSRSYIKLKRLRFKGTVKFERVHADVNMDGLCPKIDGVFSLVIVMDRKPHLSASGVLHTFDELFGARIHSHGNLCITPALKDRFYIRHVLKRVVSVEKDTAMIDLDGSIGLSTRRFNCWATFKDLDHDSSNGVYDNISKNAILVYYCWMSDAMSKASTFVSFDLDYVG |
| NCBI Accession | YP_009547941.1 |
|---|---|
| Location | 1212-2093 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGATTCTCAGTTAGCAAATCCACCTAACGCGTTCAACTATATAGAATCTCATAGAGATGAATATCAACTGTCTCATGATCTAACTGAGATAGTTCTGCAATTTCCTTCCACGGCGTCGCAATTAACGGCAAGACTTAGTCGGAGTTGTATGAAAATTGACCATTGCGTCATAGAATATAGACAACAAGTACCAATTAACGCGACGGGATCAGTAATAGTGGAGATTCATGACAAACGAATGACAGACAACGAGTCATTACAAGCATCATGGACATTTCCCATCAGATGCAACATAGATCTCCACTATTTTTCGTCATCATTCTTTTCCTTAAAAGACCCCATTCCATGGAAACTATACTACAGGGTTTCTGATACCAATGTTCATCAAAGGACTCATTTTGCCAAGTTCAAAGGAAAACTGAAATTGTCCACAGCGAAACATTCAGTAGATATCCCATTCCGGGCACCAACGGTGAAAATTCTGTCAAAACAGTTCTCACATAAAGATGTCGACTTTTCGCATGTGGACTATGGTAAATGGGAGAGACGACCAATTAGGTCCACATCAATGTCCAGATTTGGACTACCAGGCCCAATTGAATTGAAACCCGGAGAGTCATGGGCCTCCAGAAGCACAATTGGATTGACACATACAGACTCAGAGTCAGACATGGAAAATGCAACACATCCATATAAAGAACTCCATCGCTTAGGAACAAGCGTTTTCGACCCGGGTGAATCGGCTTCAATAATAGGTGCGCAGAGGGCCCAATCAAACATTACAATGTCAGTTGCCCAATTAAGCGAGTTAGTCAGAACTACCGTTCAAGAATGTATTAACAATAATTGTACTCCTTCTCAACCAAAAACATTGAAATAA |
| Protein Sequence | MDSQLANPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSHKDVDFSHVDYGKWERRPIRSTSMSRFGLPGPIELKPGESWASRSTIGLTHTDSESDMENATHPYKELHRLGTSVFDPGESASIIGAQRAQSNITMSVAQLSELVRTTVQECINNNCTPSQPKTLK |
| NCBI Accession | YP_009325421.1 |
|---|---|
| Location | 202-951 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGTTATACTGCGGGGACCTCAAAGGTTAGTCGCAATGCTAATTATTCACCTGGTGGAGGCCCAAAATCCAACAGGACCAATGCTTGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATATATCGTATGTATAGATCCCCCGATGTTCCGAAAGGCTGTGAAGGGCCCTGTAAAATCCAGTCTTTTGAACAGAGACATGATGTTTCTCATGTTGGTAAGGTTATGTGTATATCCGACGTGACTCGTGGTAATGGTATTACCCATCGTGTTGGTAAACGATTCTGTGTTAAGTCTGTTTACATTTTAGGGAAAGTATGGATGGACGACAACATCAAGTTGAAGAACCACACCAACAGTGTCATGTTTTGGTTAGTCAGGGATAGACGACCATATGGCACCCCTATGGATTTTGGCCAAGTTTTTAATATGTTCGATAATGAGCCTAGTACAGCTACTGTTAAGAACGACCTCCGTGATCGTTTCCAAGTCATGCACAAATTTTATGCCAAGGTTACAGGTGGACAATATGCCAGCAACGAGCAATCTTTGGTCAAGCGTTTTTGGAAGGTGAATAATTATGTCGTCTACAACCATCAGGAAGCTGCTAAATATGAGAACCATACTGAGAATGCTCTATTATTGTATATGGCATGTACTCATGCTTCTAATCCTGTGTATGCTACTCTAAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAA |
| Protein Sequence | MPKRDAPWRYTAGTSKVSRNANYSPGGGPKSNRTNAWVNRPMYRKPRIYRMYRSPDVPKGCEGPCKIQSFEQRHDVSHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQSLVKRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_009325422.1 |
|---|---|
| Location | 948-1346 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCGACGAGTGGCGTTTATATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAACCAGAGTAGAGAAACCACTCTTCACACACACGACGGTGTTCCACATACAAGTCCGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAATAGATTCAAGTTTCTTGTAATGTATTACTTAGACAATTTAGGTGTTATTTCAGTTAACAATGTAATTAAAGCTGTCTCTTTTGCAACGAACAGAAGTTATGTCAACGATGTACTTGAATATCATGAAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGEPITAAQATSGVYIWEVPNPLYFKITRVEKPLFTHTTVFHIQVRANHNLRKALALHKAYFNFQVWTTLTTASGQIYLNRFKFLVMYYLDNLGVISVNNVIKAVSFATNRSYVNDVLEYHEIKFKFY |
| NCBI Accession | YP_009325423.1 |
|---|---|
| Location | 1093-1509 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGACTGGGCACAGAAGAACGCCATCTTCGTCTCCATTGAAGAACCTCTCTTCACCACCGAAAATTAAACCTCGCCATAGATACGCGAAAAAACAAATAAGACGAAGAAGGATTGATCTGCAGTGCGGCTGTTCTATTTACATTCACATTAACTGCAGAAACAATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCGACGAGTGGCGTTTATATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAACCAGAGTAGAGAAACCACTCTTCACACACACGACGGTGTTCCACATACAAGTCCGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAATAG |
| Protein Sequence | MTGHRRTPSSSPLKNLSSPPKIKPRHRYAKKQIRRRRIDLQCGCSIYIHINCRNNGFTHRGTHHCSSGDEWRLYLGGSKSPLFQDNQSRETTLHTHDGVPHTSPSQPQPEESVGSPQSLLQFPSLDDIDDSFWADLFK |
| NCBI Accession | YP_009325424.1 |
|---|---|
| Location | 1442-2479 |
| Gene Name | AC1 |
| Protein Name | Rep |
| Coding Region | ATGCCACTGCAGAAACGCTTTCGCTTAAATGCCAAGAACTTCTTCATCACTTATCCAAAGTGCTCTCTCACGAAAGAAGAAGCTCTTGACCAGTTACGTTCGATAACCACTCCAGTAAACAAGAAGTTCATCAAGATATGCAGGGAACTCCATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAATTCGAAGGAAAATACCAATGCACGAATAACAGATTCTTCGACCTGGTTTCCACATCCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCCTACATCGATAAAGACGGAGATACACTTGAATGGGGAGAGTTTCAAATCGACGGCAGATCTGCTAGAGGAGGTCAACAATCGGCTAACGATTCATATGCAAGGGCGTTAAATGCAGAATCTGCAGACGAAGCTCTACAGATAATCAAAGAGCATCAACCACAACATTTTGTCTTACAATATCATAATTTAGTCACAAACATATCCAAAATATTTCAAAAACCCCCGGAACCATGGGTTCCTCCATTCCAGTTGTCCACATTCAATAATGTTCCAGATATAATGTCAGAATGGGTTAGTCAGAATATTGCCGATTCCGCTGCGCGGCCAATTAGACCTATATCAATTATTATTGAAGGATCATCAAGAACAGGCAAAACATTATGGGCCCGTAGTCTCGGGCCTCACAACTACTTATGTGGTCATATCGATCTAAATTCAAAAATTTACTCCAATAATGCATGGTATAACGTCATTGATGATGTTGATCCCCATTATTTAAAACACTTTAAAGAGTTCATGGGGGCCCAGAGGGATTGGCAATCAAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTTTGCAATCCAGGCCCCCATTCATCATATAAGGAGTTTCTCAGTGAGGACAAAAACACATCACTCAATGACTGGGCACAGAAGAACGCCATCTTCGTCTCCATTGAAGAACCTCTCTTCACCACCGAAAATTAA |
| Protein Sequence | MPLQKRFRLNAKNFFITYPKCSLTKEEALDQLRSITTPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSTSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSANDSYARALNAESADEALQIIKEHQPQHFVLQYHNLVTNISKIFQKPPEPWVPPFQLSTFNNVPDIMSEWVSQNIADSAARPIRPISIIIEGSSRTGKTLWARSLGPHNYLCGHIDLNSKIYSNNAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNCKYGKPIQIKGGIPTIFLCNPGPHSSYKEFLSEDKNTSLNDWAQKNAIFVSIEEPLFTTEN |
| NCBI Accession | YP_009325425.1 |
|---|---|
| Location | 2065-2328 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAATTCGAAGGAAAATACCAATGCACGAATAACAGATTCTTCGACCTGGTTTCCACATCCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCCTACATCGATAAAGACGGAGATACACTTGAATGGGGAGAGTTTCAAATCGACGGCAGATCTGCTAGAGGAGGTCAACAATCGGCTAACGATTCATATGCAAGGGCGTTAA |
| Protein Sequence | MKMGNLIFTCSSNSKENTNARITDSSTWFPHPGQHISIQTFRELSRAPTSSPTSIKTEIHLNGESFKSTADLLEEVNNRLTIHMQGR |
References More References in PubMed
| 1 |
Sword Bean (Canavalia gladiata): a new host of Bean common mosaic virus. Verma R, et al. Mol Biol Rep. 2023 Oct;50(10):8777-8781. doi: 10.1007/s11033-023-08769-8. Epub 2023 Aug 31. PMID: 37651019 |
|---|---|
| 2 |
Worrall EA, et al. Adv Virus Res. 2015;93:1-46. doi: 10.1016/bs.aivir.2015.04.002. Epub 2015 Jun 10. PMID: 26111585 |
| 3 |
Feng X, et al. Plant Dis. 2019 Jun;103(6):1220-1227. doi: 10.1094/PDIS-08-18-1307-RE. Epub 2019 Apr 15. PMID: 30983522 |
| 4 |
Bean dwarf mosaic virus: a model system for the study of viral movement. Levy A, et al. Mol Plant Pathol. 2010 Jul;11(4):451-61. doi: 10.1111/j.1364-3703.2010.00619.x. PMID: 20618704 |
| 5 |
Kumar S, et al. Microb Pathog. 2020 Jan;138:103812. doi: 10.1016/j.micpath.2019.103812. Epub 2019 Oct 25. PMID: 31669830 |
| 6 |
Wani F, et al. Appl Biochem Biotechnol. 2025 May;197(5):3431-3446. doi: 10.1007/s12010-025-05187-3. Epub 2025 Feb 14. PMID: 39951170 |
| 7 |
Zaim M, et al. Virus Genes. 2011 Aug;43(1):138-46. doi: 10.1007/s11262-011-0610-z. Epub 2011 May 10. PMID: 21556742 |
| 8 |
Identification of Three Strains of Bean common mosaic necrosis virus in Common Bean from Iran. Naderpour M, et al. Plant Dis. 2010 Jan;94(1):127. doi: 10.1094/PDIS-94-1-0127A. PMID: 30754409 |
| 9 |
Pest categorisation of cowpea mosaic virus. EFSA Panel on Plant Health (PLH), et al. EFSA J. 2023 Feb 24;21(2):e07847. doi: 10.2903/j.efsa.2023.7847. eCollection 2023 Feb. PMID: 36846393 |
| 10 |
Al-Jaberi MS, et al. 3 Biotech. 2021 Sep;11(9):407. doi: 10.1007/s13205-021-02957-8. Epub 2021 Aug 13. PMID: 34471590 |