Common bean mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_003029365.2 |
| Isolate | Cuba |
| Release date | 2018/12/27 |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
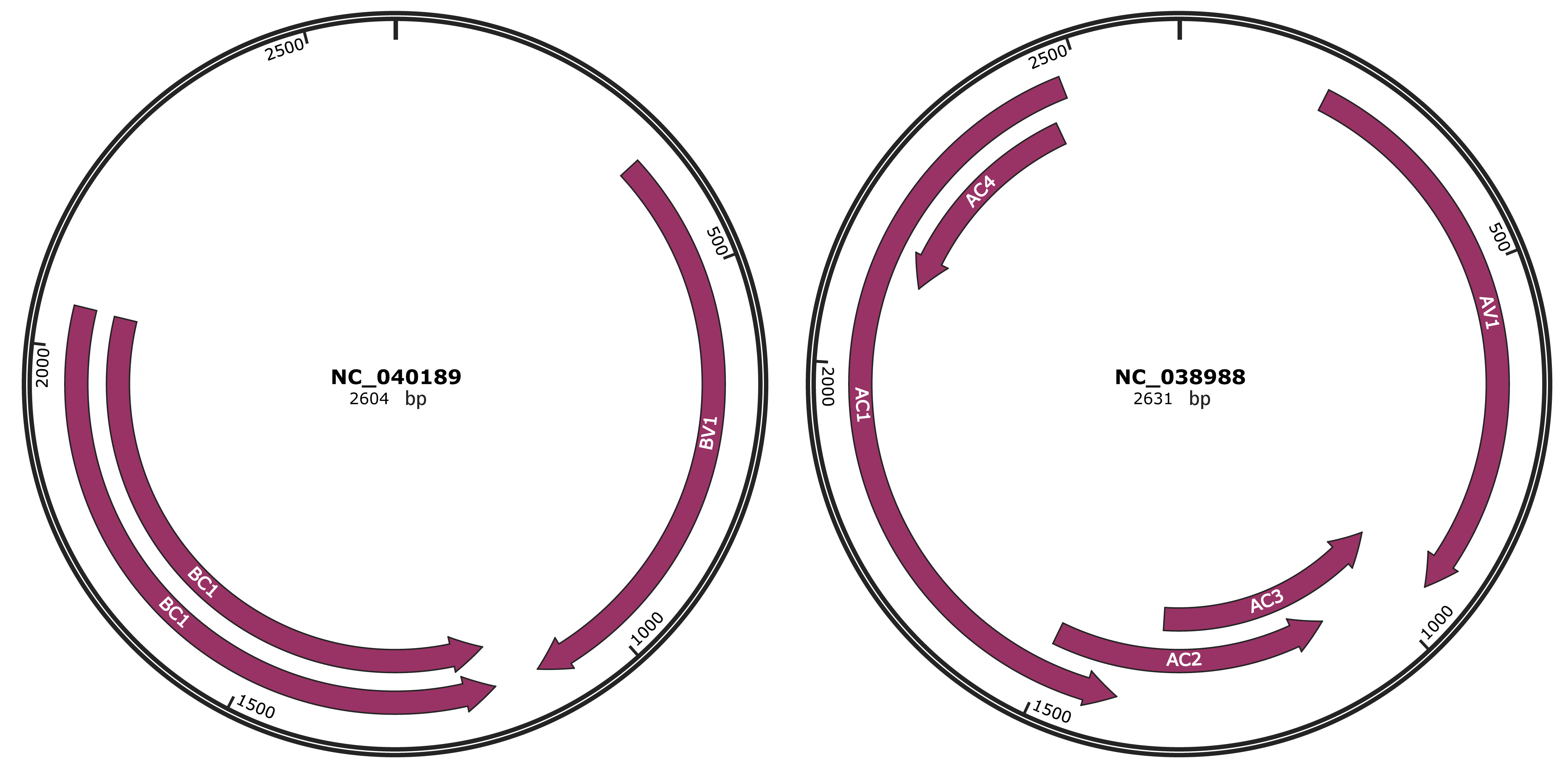
JBrowse
Genome
NC_040189
NC_038988
Gene Information
| NCBI Accession | YP_009547938.1 |
|---|---|
| Location | 343-1110 |
| Gene Name | BV1 |
| Protein Name | NSP |
| Coding Region | ATGTATTCTTCTAAATATAAACGTGGTGTGTCTAATTATCAACGACGTGGTTATATTCGTAATCAAGTCTTGCGAAAAGCATCTTTTAAACGTTATGATGGCAAACGTCGACAAATTCATGGTGGTAAGGTTTATGATGATTCTAAAATGTTGGATCAACGGTTACATGAAAATCAATTTGGACCTGAATTTGTTATGGGTCAGAATGGTGCTATATCGACGTTTATTAGTTTCCCTCAATTGGGTAAGAATAAACCCAATCGAACTAGGTCATATATTAAATTAAAACGTTTGCGATTAAAAGGTACTGTTAAAATAGAGCGTGTTCGTAATGATATGAATATGGATGGTATTTCCTCAAAAATCGAAGGTGTATTCTCTATGGTTGTTGTGGTGGATCGTAAACCACATCTTGGTCCGTCTGGGAATCTACCAACATTTGAAGATTTATTCGGTGCAAGGATTAATAGTCATGGTAACTTAGCAATAATTCCGTCAATGGAGGACCGTTTTTATATACGACATGTTACGAAGCGAGTATTATCCGTGGATAATGACACAATGATGATCGATGTTGAAGGTTATACAAAATTGTCTAATAGGCGATATAATATGTGGTCTACGTTTAAGGATATAGACCATGAATCAAGTAATGGGGCCTATGATAATATTAGTAAAAATGCGATTTTAGTGTATTACTGTTGGATGTCGGATAATATGTCAAAGGCATCTACATTTGTATCATTTGATCTTGATTATGTGGGTTGA |
| Protein Sequence | MYSSKYKRGVSNYQRRGYIRNQVLRKASFKRYDGKRRQIHGGKVYDDSKMLDQRLHENQFGPEFVMGQNGAISTFISFPQLGKNKPNRTRSYIKLKRLRLKGTVKIERVRNDMNMDGISSKIEGVFSMVVVVDRKPHLGPSGNLPTFEDLFGARINSHGNLAIIPSMEDRFYIRHVTKRVLSVDNDTMMIDVEGYTKLSNRRYNMWSTFKDIDHESSNGAYDNISKNAILVYYCWMSDNMSKASTFVSFDLDYVG |
| NCBI Accession | YP_009547939.1 |
|---|---|
| Location | 1170-2051 |
| Gene Name | BC1 |
| Protein Name | MP |
| Coding Region | ATGGATTCTCAGTTAGCAAATGCTCCAAATGCGTTTAATTACATAGAATCCCATAGGGATGAATATCAACTGTCTCATGATCTAACTGAGATAATTCTTCAATTTCCTTCAACAGCAGCACAATTAACAGCAAGGCTCAGTCGTAGCTGTATGAAAATTGACCATTGCGTCATTGAATATAGGCAGCAAGTACCAATAAACGCTACTGGCACAGTCATTGTAGAGATCCATGACAAAAGAATGACTGACGATGAATCATTACAAGCATCATGGACATTTCCACTACGATGCAACATAGATCTCCATTACTTTTCCTCTTCCTTCTTCTCGCTAAAAGACCCAATACCATGGAAACTGTATTATAGAGTTAGCGACACAAACGTACATCAAAGAACACATTTTGCCAAGTTTAAGGGTAAATTAAAATTATCCACGGCTAAACATTCAGTGGATATACCCTTCCGAGCACCAACAGTGAAAATTCACTCCAAACAATTTTCACATAAAGATGTTGATTTTTCGCATGTGGACTACGGTCGATGGGAACGAAAAACATTAAGGTCCACATCCATATCCAGAGTTGCTCTACCAGGCCCAATTGAATTGAGACCAGGAGAGTCATGGGCCGCCAAAAGCACAATTGGGCTTACTCATACAGATACGGATTCTGAAATAGAAAACGCAATACATCCATACAGACAACTGAATCGTTTAGGATCAAGCGCAATAGACCCAGGTGATTCAGCATCACAAGCAGGGTTGCAAAGAACCCAATCAAACATTACAATGTCAGTGGCCCAATTAAGCGATCTTGTTAGGACAACGGTTCAAGAATGTATAAACAATAATTGTATTCCAAATCAGCCCAAAGCATTGAAATAA |
| Protein Sequence | MDSQLANAPNAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDDESLQASWTFPLRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIHSKQFSHKDVDFSHVDYGRWERKTLRSTSISRVALPGPIELRPGESWAAKSTIGLTHTDTDSEIENAIHPYRQLNRLGSSAIDPGDSASQAGLQRTQSNITMSVAQLSDLVRTTVQECINNNCIPNQPKALK |
| NCBI Accession | YP_009508412.1 |
|---|---|
| Location | 198-947 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGTTCTAATGCGGGGACCTCTAAGGTTAGCCGTAATTTGAATTACTCTCCTCGTGGAGGCCCAAAATCCAATAAGGCCAACGATTGGGTTAATAGGCCCATGTATAGAAAGCCCAGGTTTTATCGGATGTACAGGACTCCCGATGTACCTAGAGGATGTGAAGGGCCATGTAAGATCCAGTCGTTTGAACAACGCCATGATGTGTCTCACCTTGGTAAGGTTATGTGTATATCTGACGTGACACGTGGTAACGGTATTACCCATCGCGTTGGAAAACGTTTCTGTATCAAGTCTGTGTATATTTTAGGCAAGGTATGGATGGATGACAATATCAAGTTAAAGAATCACACCAACAGTGTTATGTTTTGGTTGGTTAGGGATAGGAGACCATATGGCACTCCCATGGATTTTGGTCAAGTTTTTAATATGTTTGATAATGAACCAAGTACTGCTACGGTTAAGAACGATCTTCGTGATCGTTTCCAGGTCTTGCACAAGTTTTATTCTAAGGTTACAGGTGGACAATATGCGAGTAATGAACAATCACTCGTTAAGCGATTTTGGAAGGTTAACAACCATGTGGTGTATAACCATCAGGAAGCGGCTAAGTACGAGAATCACACTGAAAATGCTCTATTATTGTATATGGCATGTACTCATGCGTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTACGATTCGATAATGAATTAA |
| Protein Sequence | MPKRDAPWRSNAGTSKVSRNLNYSPRGGPKSNKANDWVNRPMYRKPRFYRMYRTPDVPRGCEGPCKIQSFEQRHDVSHLGKVMCISDVTRGNGITHRVGKRFCIKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVLHKFYSKVTGGQYASNEQSLVKRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_009508413.1 |
|---|---|
| Location | 944-1342 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAACGAATGGCGTTTTTATTTGGGAGGTTCCAAATCCCCTATATTTCAAGATCGTATGGGTGGAACATCCAATATACACACGCAGCAAGGTGTTCCAAATACAAATCCGAGCCAACCACAACCTCAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTCTGGACGACTTTGACGACAGCTTCTGGGAAGAATTATTTAAGTAGATTCAAATTTATTGTCATGTATTACTTAGACAATTTAGGTGTTATTTCAGTTAACAATATTATTAGAGCTGTCTCATATGCAACAGACAAACATTATGTAAATGATGTACTTGAAGATCATGATATAAAATATAAACTTTATTAA |
| Protein Sequence | MDSRTGEPITAAQATNGVFIWEVPNPLYFKIVWVEHPIYTRSKVFQIQIRANHNLRKALALHKAYFNFQVWTTLTTASGKNYLSRFKFIVMYYLDNLGVISVNNIIRAVSYATDKHYVNDVLEDHDIKYKLY |
| NCBI Accession | YP_009508414.1 |
|---|---|
| Location | 1089-1505 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGACTGGGCACAAAAAAACGCCATCTACGTCTCAATTGAGAGACCACTGTTCTCCTCCGTCAATCAAACCTCGCCATCGATACGCGAAGAGACAAACGAGGCGTAAAAGAATTGATCTGCAGTGCGGCTGTTCAATTTACGTTCACATCAACTGCAACAATCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAACGAATGGCGTTTTTATTTGGGAGGTTCCAAATCCCCTATATTTCAAGATCGTATGGGTGGAACATCCAATATACACACGCAGCAAGGTGTTCCAAATACAAATCCGAGCCAACCACAACCTCAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTCTGGACGACTTTGACGACAGCTTCTGGGAAGAATTATTTAAGTAG |
| Protein Sequence | MTGHKKTPSTSQLRDHCSPPSIKPRHRYAKRQTRRKRIDLQCGCSIYVHINCNNHGFTHRGTHHCSSGNEWRFYLGGSKSPIFQDRMGGTSNIHTQQGVPNTNPSQPQPQESVGSPQSLLQFPSLDDFDDSFWEELFK |
| NCBI Accession | YP_009508415.1 |
|---|---|
| Location | 1399-2475 |
| Gene Name | AC1 |
| Protein Name | Rep |
| Coding Region | ATGCCACTCCAGAAACGCTTTCGTTTAAATGCAAAGAACTACTTCCTCACATATCCAAAATGTTCTCTTTCTAAAGAAGAGGCATTATCACAATTACAACAATTATCCACACCTGTCAACAAAAAATACATCAAGATCTGCAGCGAATTGCATGAAGATGGGCAACCACATCTGCATGTTCTCATCCAATTCGAAGGTAAATACCAATGCGCGAATAATAGATTCTTCGACCTGGTATCCACAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCTAGCTCAGACGTCAAATCCTACATCGACAAAGACGGGGATACACTCGAATGGGGAGAGTTTCAAATAGACGGCAGATCAGCTAGAGGAGGTAAGCAATCTGCTAATGATTCATATGCAAAGGCCTTAAATGCAGAATCCATAGACGAAGCATTAAAGATCATTAAAGAGGAACAACCCAAAGATTATCTCCTTCAACATCATAACATACATAATAATCTCCAACGAATCTTCGCAAAGGCCCCGGAACAATGGGTTCCTCCATATCAATCATCAACGTTTGATAATGTTCCTCAAGTCATGAAAGACTGGGTTAGTCATAATGTTGTCGATGCCGCTGCGCGGCCATTGAGACCTATTTCAATTATTATTGAAGGATCATCAAGAACAGGCAAAACATTATGGGCCCGAAGTCTGGGCCCTCATAATTATTTATGTGGTCATATCGATCTCAATCCACGCATATACTCCAATGATGCTTGGTATAACGTCATCGACGACGTAGATCCGCATTATCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGAAATTGGCAATCAAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGAGGAATTCCCACTATCTTCCTTTGCAATCCTGGCCCCCATTCATCATATAAAGAGTATCTCGGCGAGGACAAGAACAGATCACTCAATGACTGGGCACAAAAAAACGCCATCTACGTCTCAATTGAGAGACCACTGTTCTCCTCCGTCAATCAAACCTCGCCATCGATACGCGAAGAGACAAACGAGGCGTAA |
| Protein Sequence | MPLQKRFRLNAKNYFLTYPKCSLSKEEALSQLQQLSTPVNKKYIKICSELHEDGQPHLHVLIQFEGKYQCANNRFFDLVSTTRSTHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGKQSANDSYAKALNAESIDEALKIIKEEQPKDYLLQHHNIHNNLQRIFAKAPEQWVPPYQSSTFDNVPQVMKDWVSHNVVDAAARPLRPISIIIEGSSRTGKTLWARSLGPHNYLCGHIDLNPRIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRNWQSNCKYGKPIQIKGGIPTIFLCNPGPHSSYKEYLGEDKNRSLNDWAQKNAIYVSIERPLFSSVNQTSPSIREETNEA |
| NCBI Accession | YP_009508416.1 |
|---|---|
| Location | 2121-2447 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGCAAAGAACTACTTCCTCACATATCCAAAATGTTCTCTTTCTAAAGAAGAGGCATTATCACAATTACAACAATTATCCACACCTGTCAACAAAAAATACATCAAGATCTGCAGCGAATTGCATGAAGATGGGCAACCACATCTGCATGTTCTCATCCAATTCGAAGGTAAATACCAATGCGCGAATAATAGATTCTTCGACCTGGTATCCACAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCTAGCTCAGACGTCAAATCCTACATCGACAAAGACGGGGATACACTCGAATGGGGAGAGTTTCAAATAG |
| Protein Sequence | MQRTTSSHIQNVLFLKKRHYHNYNNYPHLSTKNTSRSAANCMKMGNHICMFSSNSKVNTNARIIDSSTWYPQPGQHISIRTFRELNLAQTSNPTSTKTGIHSNGESFK |
References More References in PubMed
| 1 |
Mulenga RM, et al. Plant Dis. 2022 Sep;106(9):2380-2391. doi: 10.1094/PDIS-11-21-2533-RE. Epub 2022 Aug 12. PMID: 35188414 |
|---|---|
| 2 |
Molecular Characteristics of Bean Common Mosaic Virus Occurring in Inner Mongolia, China. Li J, et al. Genes (Basel). 2024 Jan 21;15(1):133. doi: 10.3390/genes15010133. PMID: 38275614 |
| 3 |
Interactions between Common Bean Viruses and Their Whitefly Vector. Ferreira AL, et al. Viruses. 2024 Oct 2;16(10):1567. doi: 10.3390/v16101567. PMID: 39459901 |
| 4 |
Seed Transmission of Cowpea Mild Mottle Virus in Common Beans in Brazil. Pinheiro-Lima B, et al. Viruses. 2026 Jul 7;18(7):752. doi: 10.3390/v18070752. PMID: 42515604 |
| 5 |
First Report of Bean common mosaic virus Infecting Lablab purpureus in India. Udayashankar AC, et al. Plant Dis. 2011 Jul;95(7):881. doi: 10.1094/PDIS-01-11-0009. PMID: 30731707 |
| 6 |
Yang QQ, et al. Sci Rep. 2022 Jan 13;12(1):681. doi: 10.1038/s41598-021-03562-8. PMID: 35027575 |
| 7 |
Sword Bean (Canavalia gladiata): a new host of Bean common mosaic virus. Verma R, et al. Mol Biol Rep. 2023 Oct;50(10):8777-8781. doi: 10.1007/s11033-023-08769-8. Epub 2023 Aug 31. PMID: 37651019 |
| 8 |
Kareem KT, et al. Virusdisease. 2023 Jun;34(2):204-212. doi: 10.1007/s13337-023-00812-3. Epub 2023 Apr 7. PMID: 37408549 |
| 9 |
Virus-induced gene silencing in soybean and common bean. Zhang C, et al. Methods Mol Biol. 2013;975:149-56. doi: 10.1007/978-1-62703-278-0_11. PMID: 23386301 |
| 10 |
Meziadi C, et al. Theor Appl Genet. 2023 Dec 13;137(1):8. doi: 10.1007/s00122-023-04513-9. PMID: 38092992 |