Coccinia mosaic Tamil Nadu virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000922555.1 |
| Isolate | India: Tindivanam, Tamil Nadu |
| Release date | 2015/2/22 |
| Submitter | Nagendran,K., Mohankumar,S., Sathya,V.K., Malathi,V.G., Naidu,R.A., Karthikeyan,G. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
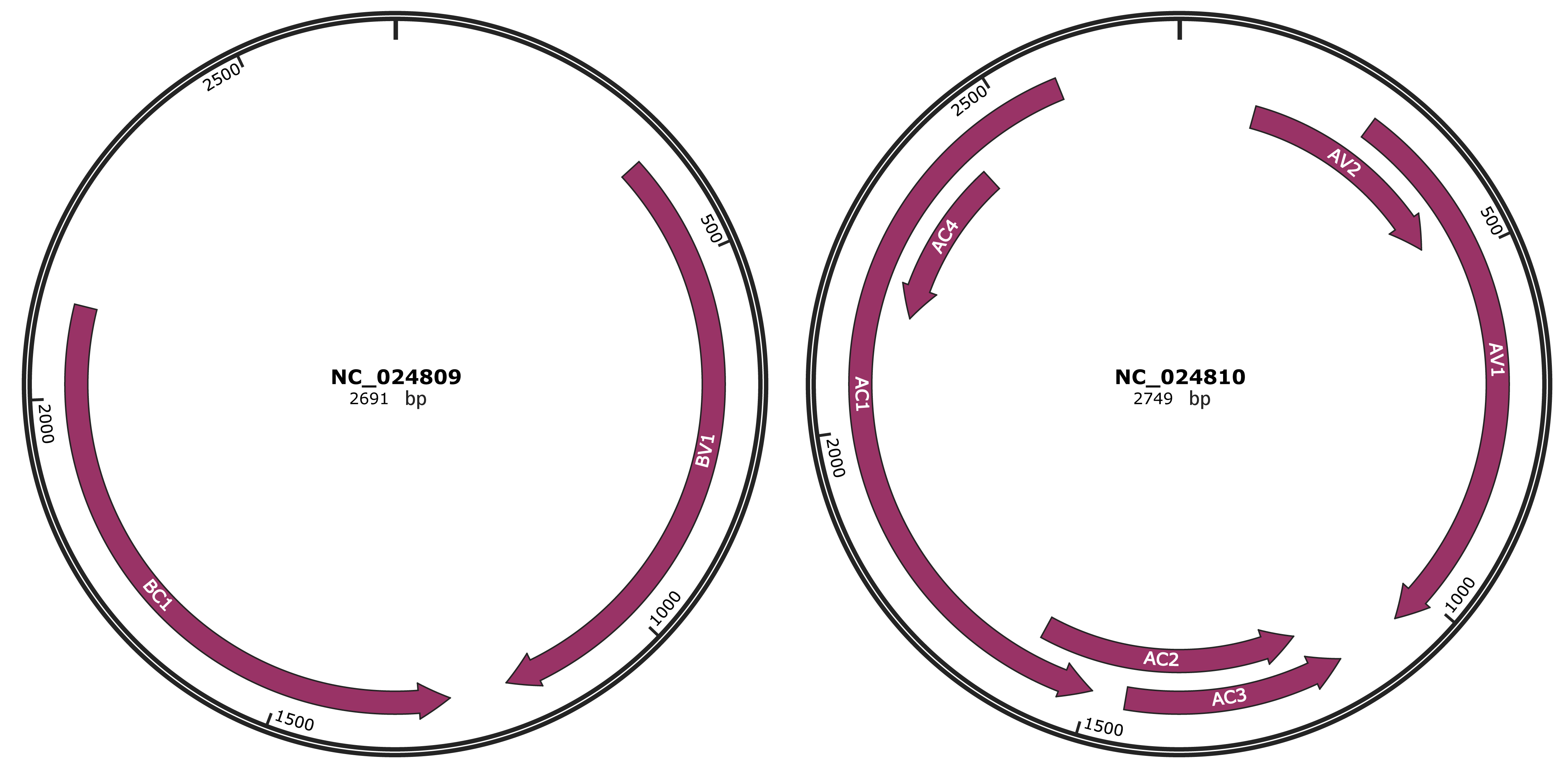
JBrowse
Genome
NC_024809
NC_024810
Gene Information
| NCBI Accession | YP_009056852.1 |
|---|---|
| Location | 357-1193 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGGACCTAGCGTGTTCTTGTGATAAGATGAAAACCCCCGGAATTTCTCCATCATCCGGCAAGTTCAGAGGGTACCGCAATTCTGTTTTGTACGGGAGATCTGGTAATTGGAGGACTTCTAAAAATGGGCGCCGGTCGGATACTAGGTTCCGACGCTGGGTTCCGCGCCATGTTAAGACATCCGTCGATTTATTCGGAGACGAAGGAAGCAGGCAGTTTCGCCGCAAGGAACTGACCGAGTCTCAGTACGGAACGGACTATGTGGTTGGTCAGAATAGGGTTGTAACTACGTATGTCACGTATCCTAGCAAGACTCGAATCGGTGCAAATAACAGAACTAGGTCATATATTCGACTGGTAGGTTTGAGGATGAACGGAACATTTTCCGTTCGATTTGCAGGAATGGAGACGGATGTCGACCGCTCGCACATGGTTTTCGGTGTTTTGTCGGTCGTCGTGGTCCGAGATAAAAAGCCTAAGATCTACTCGAGTGCATCCCCTCTGATTCCATTCGTGGAGTTGTTTGGATCCGTCGAGGCATCCAAGGGTACTCTTAGAGTCTCTGAACATCACCGGGATCGTTTCGTTCTACTGAAACAGACTTCTATACTGGTAAACAGTCCACATGGAATCACGATGAAGAAGTTTTATATGACTAACTGTATTCCTACATCCTATACAACCTGGGCTACGTTCAAGGATGAGGAGGAAGATCATTGTACTGGACAGTATTCTAATACTTCGAGCAACGCGTTGCTCGTTTATTATGTTTGGGTTAGCGACGTCCCGTCGCATGCGGATGTCTATAACAACATAATTCTTAATTATATCGGCTGA |
| Protein Sequence | MDLACSCDKMKTPGISPSSGKFRGYRNSVLYGRSGNWRTSKNGRRSDTRFRRWVPRHVKTSVDLFGDEGSRQFRRKELTESQYGTDYVVGQNRVVTTYVTYPSKTRIGANNRTRSYIRLVGLRMNGTFSVRFAGMETDVDRSHMVFGVLSVVVVRDKKPKIYSSASPLIPFVELFGSVEASKGTLRVSEHHRDRFVLLKQTSILVNSPHGITMKKFYMTNCIPTSYTTWATFKDEEEDHCTGQYSNTSSNALLVYYVWVSDVPSHADVYNNIILNYIG |
| NCBI Accession | YP_009056853.1 |
|---|---|
| Location | 1272-2123 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGTCAACAAGTAATAGGTATGAGGGTTCAAGTGTTCTTCCGGGGGGATACATCAACTCCGAGAGAGTTGAATATGCTCTCACAAACGACGCAACGGACGTCGTATTGTCATTTCCCTCCATGTTTGAACAAAAGCTTAGCCAAATAAGGAATAGATGCATGAAGATTGATCACGTCGTGCTCGAATACCGGAATCAGGTACCGGTGAATGCTGTCGGTCACGTAGTTGTAGAGATCCACGACATGAGATTGACGGAGGGAGACACCAAGCAGGCAGAGTTCACGATTCCTATCAAATGCAACTGCAACCTACACTACTATTCGTCCTCATACTCTCCGTCAAAGATTAAAAATCCCTGGAGAGTAGAGTACAGGGTCGAGGACACAAATGTCGTGAACGGGGTTCACTTTTGCAAGATGATGGGGAAACTCCGGTTGTCGTCCGCCAAACATTCCACAGATGTAGAGTTCAAGTCTCCGAAGATAGAGATTCTCAGCAAGGAATTCTCCTTGAACGACATAGACTTCTGGGCCGTAGGTGCTAGGACCCAGACTAGAAGACTAGTTGAAGGCCCAAGACTGTTGGGCCTCAGATCAACATCGTTCCGTGCGCCCAATTACGCAATTGGGCCGAACGAATCATGGGCCAGCAGGTCCGAGTGTGGAACGACATCCAACACGAGCAGACCATACAAGGGACTTAGCGGCCTCGACGAAAGCGCAATAGACCCAGGCCCGTCCGCCTCTCAAGTCGGAAGCATGACAAAGGACGACATCACAGAAATCATCACAAAAACAGTAGAACAATGTATCAAATCAAATATTAACGCCCCAATTAAGAAAGATATATAG |
| Protein Sequence | MSTSNRYEGSSVLPGGYINSERVEYALTNDATDVVLSFPSMFEQKLSQIRNRCMKIDHVVLEYRNQVPVNAVGHVVVEIHDMRLTEGDTKQAEFTIPIKCNCNLHYYSSSYSPSKIKNPWRVEYRVEDTNVVNGVHFCKMMGKLRLSSAKHSTDVEFKSPKIEILSKEFSLNDIDFWAVGARTQTRRLVEGPRLLGLRSTSFRAPNYAIGPNESWASRSECGTTSNTSRPYKGLSGLDESAIDPGPSASQVGSMTKDDITEIITKTVEQCIKSNINAPIKKDI |
| NCBI Accession | YP_009056854.1 |
|---|---|
| Location | 119-466 |
| Gene Name | AV2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCACTATTGCACGAATTTCCAGATACTGTCCACGGATTGAGGTGCATGCTAGCTGTAAAATATCTGCAGGAGGTCGAGCGCACTTATTCACCCGATACTATTGGGTTTGACCTTATTCGAGACCTCATCACCGTCGTTCGATCTAAGAGCTATGTCGAAGCGACCGGCAGATATCATCATTTCAACTCCCGCCTCGAAAGTACGCCGTCGACTGAACTTCGACAGCCCGTATGCTGTCCGTGCAGCTGTCCCTATTGTCCGAGGCACAAAGGCAAGGGCTTGGGCCAACAGGCCCATGAACAGAAAGCCCAGAATGTACAGAATGTATCGAAGTCCTGA |
| Protein Sequence | MWDPLLHEFPDTVHGLRCMLAVKYLQEVERTYSPDTIGFDLIRDLITVVRSKSYVEATGRYHHFNSRLESTPSTELRQPVCCPCSCPYCPRHKGKGLGQQAHEQKAQNVQNVSKS |
| NCBI Accession | YP_009056855.1 |
|---|---|
| Location | 279-1049 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCGGCAGATATCATCATTTCAACTCCCGCCTCGAAAGTACGCCGTCGACTGAACTTCGACAGCCCGTATGCTGTCCGTGCAGCTGTCCCTATTGTCCGAGGCACAAAGGCAAGGGCTTGGGCCAACAGGCCCATGAACAGAAAGCCCAGAATGTACAGAATGTATCGAAGTCCTGATGTACCTAGGGGCTGTGAAGGCCCGTGTAAGGTGCAATCCTTCGAATCCAGACATGACGTATCTCACATTGGTAAAGTGTTGTGCGTGAGCGATGTTACGCGGGGCACGGGTCTCACACATCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTTTATGTTTTAGGTAAGATCTGGATGGACGAGAACATCAAGACGAAGAACCACACCAACAGCGTTATTTTCTTTTTAGTTCGTGACCGGCGTCCAACTGGATCGCCTCAAGATTTTGGGGAGGTGTTCAATATGTTCGACAGCGAGCCCAGTACAGCTACTGTGAAGAACGTGCACCGTGATCGCTATCAAGTTCTGCGGAAGTGGTATTCGACTGTGACTGGTGGGACCTATGCGTCTAAGGAACAGGCATTAGTTAAGAAGTTTGTTAGGGTTAATAATTATGTAGTCTATAATCAACAAGAACCGGGCAAGTATGAGAATCATACAGAAAATGCCCTTATGCTGTATATGGCGTGCACTCACGCCTCAAATCCTGTATATGCAACTCTGAAGATCCGGATCTATTTTTATGATTCGGTCTCAAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPYAVRAAVPIVRGTKARAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVSHIGKVLCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVIFFLVRDRRPTGSPQDFGEVFNMFDSEPSTATVKNVHRDRYQVLRKWYSTVTGGTYASKEQALVKKFVRVNNYVVYNQQEPGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
| NCBI Accession | YP_009056856.1 |
|---|---|
| Location | 1143-1448 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAGTACATTACTGCGGATCAAGCAGAGAGTGGCGCGTTTATCTGGACGGTGCCAAATCCCCTCTATTTCAGAATAACAGACCACGCAGTCCGGCCCTTTCTGACGCACCACGACGTCATCAAACTGGAGATACGATTCAACCACAACATCAGGAGGGAACTTCAGATTCACAAGTGTTTTCTAACCTACCAGATCTGGACGGTTTTACAACCGCCGACTGGGCTTTTCTTGAAAGTCTTTAAGACACAAGTGTTAAAGTATCTTAATAACCTAGCGTTATCAGTATAA |
| Protein Sequence | MDSRTGEYITADQAESGAFIWTVPNPLYFRITDHAVRPFLTHHDVIKLEIRFNHNIRRELQIHKCFLTYQIWTVLQPPTGLFLKVFKTQVLKYLNNLALSV |
| NCBI Accession | YP_009056857.1 |
|---|---|
| Location | 1189-1593 |
| Gene Name | AC2 |
| Protein Name | transcription activator protein |
| Coding Region | ATGCCATCTTCTACACCCTCGAAGGACCTCTCTACTCCGGCAGGCAACAAAACACTGAACAAGAGAACGAAGAGGTCAATTCGCAGGAGACGAATTGATCTGAAGTGCGGCTGCACATACTACTACACTATTGCCTGCCACGACCATGGATTCACGCACAGGGGAGTACATTACTGCGGATCAAGCAGAGAGTGGCGCGTTTATCTGGACGGTGCCAAATCCCCTCTATTTCAGAATAACAGACCACGCAGTCCGGCCCTTTCTGACGCACCACGACGTCATCAAACTGGAGATACGATTCAACCACAACATCAGGAGGGAACTTCAGATTCACAAGTGTTTTCTAACCTACCAGATCTGGACGGTTTTACAACCGCCGACTGGGCTTTTCTTGAAAGTCTTTAA |
| Protein Sequence | MPSSTPSKDLSTPAGNKTLNKRTKRSIRRRRIDLKCGCTYYYTIACHDHGFTHRGVHYCGSSREWRVYLDGAKSPLFQNNRPRSPALSDAPRRHQTGDTIQPQHQEGTSDSQVFSNLPDLDGFTTADWAFLESL |
| NCBI Accession | YP_009056858.1 |
|---|---|
| Location | 1496-2581 |
| Gene Name | AC1 |
| Protein Name | replication initiator protein |
| Coding Region | ATGCCTCGTCAGCGTAGTTTTCAAATTAAAGCCAAAAATATATTTCTCACATACCCAAAATGCCCTATTCCAAAAGAACAAATGCTCGACATCCTCAAAAACATAGAATGCCCTTCAGACAAATTGTTCATTAGGGTTGCGCAAGAGAGACACCAAGATGGGTCTCTGCACATCCACGCCCTTATCCAGTTCAAAGGTAAAGCCCAGTTCAGAAACCCCAGACACTTCGATGTTGTTCACCCTCATAGCTCCACCCAGTTCCACCCGAACGTCCAGGGAGCAAAGTCCTGCTCCGACGTCAAATCATATATCGAGAAGGACGGTGATTACGTCGACTGGGGTGAGTTTCAGATCGATGGACGATCTGCTAGAGGAGGTCAGCAGACAATTAATGATGCGGCAGCGGAGGCGCTGAATTCTGGGTCGACGGAGGCAGCAATGAATATCCTTCGGGAAAAGCTCCCGAAGGATTACATCTTCCAGTACCACAATTACAAGACGAATCTAGACCGGATATTTGCAGCTCCGGTCGATACATATGTTTGTCCATTTTCAAAGGAATCCTTCGACCTCGTCCCAAGAGAACTCGTCGATTGGGCATCAGAAAATATTGTGTGTTCCGCTGCGCGGCCAGTGAGGCCCATAGGTATTGTTTTAGAGGGTGATAGTAGGACGGGGAAGACGATGTGGGCACGTTCTTTAGGACCGCACAATTACTTGTGCGGCCATCTGGACCTGAGCCCCAAGATCTACAGTAACGATGCTTGGTACAACGTCATTGACGACGTCGACCCGCACTACTTGAAACACTTTAAAGAATTCATGGGGGCCCAGCGTGACTGGCAAAGCAACACAAAATACGGAAAGCCAGTCATGATTAAAGGAGGTATACCCACTATCTTCCTCTGCAATCCTGGTCCTTCGAGCAGCTATAAAGAATTCTTGGATGAGGACAAGAATTCCGCACTAAAATCCTGGGCTCTCAAGAATGCCATCTTCTACACCCTCGAAGGACCTCTCTACTCCGGCAGGCAACAAAACACTGAACAAGAGAACGAAGAGGTCAATTCGCAGGAGACGAATTGA |
| Protein Sequence | MPRQRSFQIKAKNIFLTYPKCPIPKEQMLDILKNIECPSDKLFIRVAQERHQDGSLHIHALIQFKGKAQFRNPRHFDVVHPHSSTQFHPNVQGAKSCSDVKSYIEKDGDYVDWGEFQIDGRSARGGQQTINDAAAEALNSGSTEAAMNILREKLPKDYIFQYHNYKTNLDRIFAAPVDTYVCPFSKESFDLVPRELVDWASENIVCSAARPVRPIGIVLEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVMIKGGIPTIFLCNPGPSSSYKEFLDEDKNSALKSWALKNAIFYTLEGPLYSGRQQNTEQENEEVNSQETN |
| NCBI Accession | YP_009056859.1 |
|---|---|
| Location | 2167-2424 |
| Gene Name | AC4 |
| Protein Name | PTGS |
| Coding Region | ATGGGTCTCTGCACATCCACGCCCTTATCCAGTTCAAAGGTAAAGCCCAGTTCAGAAACCCCAGACACTTCGATGTTGTTCACCCTCATAGCTCCACCCAGTTCCACCCGAACGTCCAGGGAGCAAAGTCCTGCTCCGACGTCAAATCATATATCGAGAAGGACGGTGATTACGTCGACTGGGGTGAGTTTCAGATCGATGGACGATCTGCTAGAGGAGGTCAGCAGACAATTAATGATGCGGCAGCGGAGGCGCTGA |
| Protein Sequence | MGLCTSTPLSSSKVKPSSETPDTSMLFTLIAPPSSTRTSREQSPAPTSNHISRRTVITSTGVSFRSMDDLLEEVSRQLMMRQRRR |
References More References in PubMed
| 1 |
Nagendran K, et al. Virus Genes. 2016 Feb;52(1):146-51. doi: 10.1007/s11262-015-1278-6. Epub 2016 Jan 6. PMID: 26739457 |
|---|---|
| 2 |
Sivagnanapazham K, et al. 3 Biotech. 2025 Sep;15(9):307. doi: 10.1007/s13205-025-04484-2. Epub 2025 Aug 22. PMID: 40860583 |
| 3 |
Muthupandi K, et al. 3 Biotech. 2019 Jun;9(6):247. doi: 10.1007/s13205-019-1775-8. Epub 2019 Jun 3. PMID: 31168440 |
| 4 |
A new seed-transmissible begomovirus in bitter gourd (Momordica charantia L.). Manivannan K, et al. Microb Pathog. 2019 Mar;128:82-89. doi: 10.1016/j.micpath.2018.12.036. Epub 2018 Dec 21. PMID: 30583019 |
| 5 |
Sivagnanapazham K, et al. 3 Biotech. 2026 Aug;16(8):345. doi: 10.1007/s13205-026-04962-1. Epub 2026 Jul 20. PMID: 42482923 |