Clerodendron yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000873145.1 |
| Isolate |
India |
| Release date |
2015/2/13 |
| Submitter |
Sivalingam,P.N., Satheesh,V., John,P., Chandramohan,S., Malathi,V.G. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
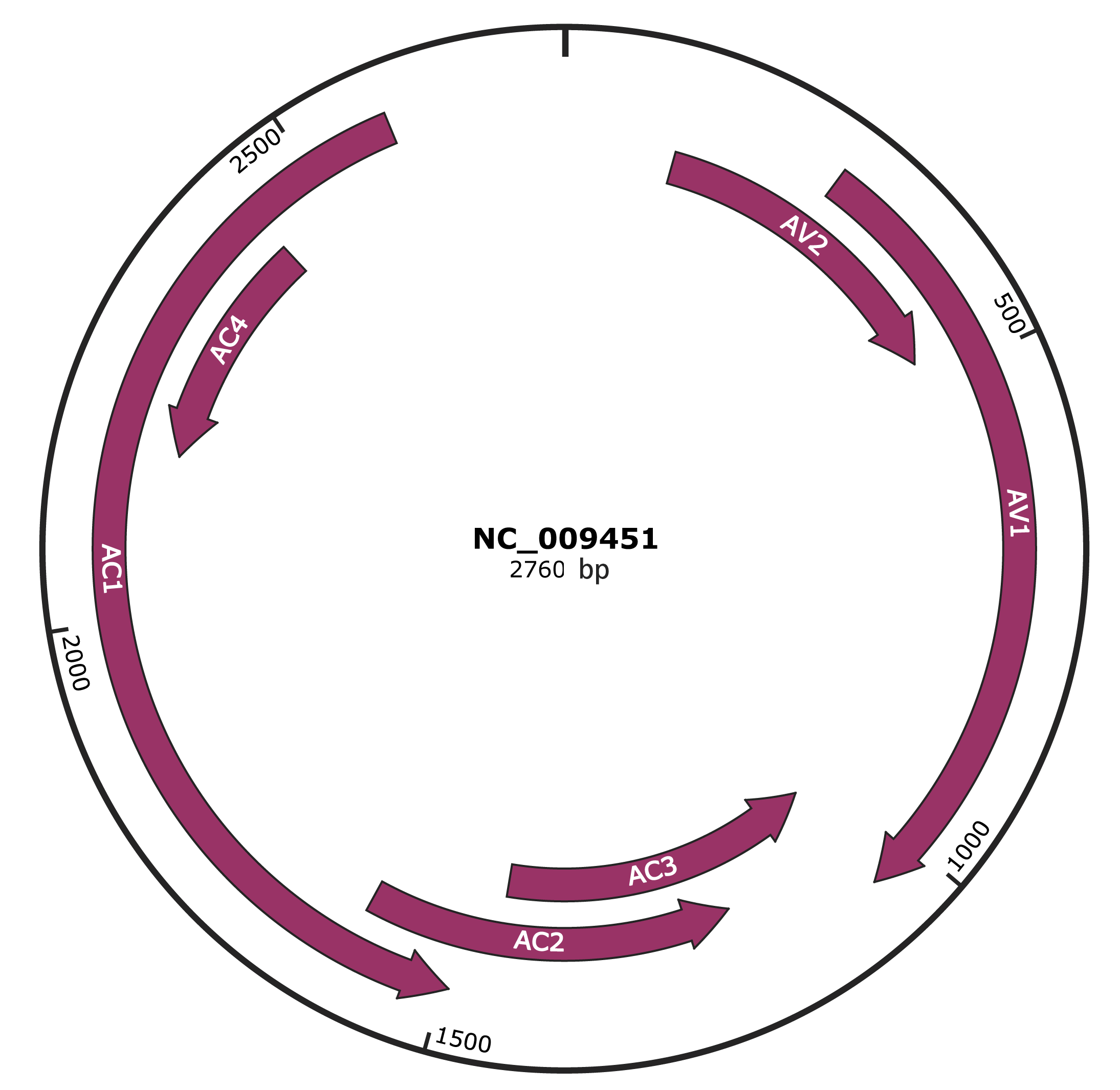
JBrowse
Genome
ACCGGATGGCAACGGCCCCGCGTGTGGGACCCACCACTAACCAATGAAAACGCTCCCTGAAAGCTACGTTATCTTGATTTTTCGTTATTTAACACGTGTCGTGTGAATATTGGTTGCATCATGTGGGATCCTATCGTGAACGATCTACCTGAAACCGTACATGGGTTTCGTTCTATGCTTGCAATCAAGTATCTACAGGCTGTAGAAAATACGTATTCTCCGGATACGCTGGGATACGATCTTGTACGTGATTTGATATCTGTTCTACGTGCAAGAAATTATGTCGAAGCGACCAGGAGATATCATAATTTCCACGCCCGCATCAAAGGTGCGACGACGTTTGAACTTCGAAAGCCCATTTGCCAACCGTGCCATTGCCCCCATTGTGGGCGTCACAAGAAGACAGGCCTGGGTCAACAGGCCCACGAACAGGAAGCCCAAATGGTATCGAATTTACAAAAGCCCAGATGTGCCTAGGGGCTGTGAAGGCCCATGCAAGGTCCAATCATTCGAGTCCAGACATGATATATCTCATATTGGCAAGGTGATGTGCGTAAGCGATGTCACACGTGGCATTGGTCTTACTCATCGAGTTGGCAAGAGATTTTGTGTAAAATCTGTGTATGTTTTGGGAAAGATCTGGATGGATGAAAACATAAAGACTAAGAACCACACTAATAGTGTGATGTTCTTTTTGGTTCGTGATCGGAGACCAATCGACAAGCCACAAGATTTTGGTGACGTTTTTAATATGTTTGATAATGAGCCCAGTACGGCAACTGTGAAGAACGTTAATCGCGATCGATATCAGGTTTTACGTAAGTGGTATCGGACGGTCACTGGTGGTCAGTACGCGTCTAAGGAGCAGGCATTAGTTAGGAGATTTATTAGGGTTAATAATTATGTTGTTTATAATCAACAAGAAGCTGGGAAATACGAGAATCATACTGAGAACGCTCTTATGTTGTATATGGCATGCACTCATGCCTCTAACCCCGTGTATGCTACTCTGAAGATACGGATATATTTCTATGATTCTGTATCAAATTAATACAAAAGAAATTTTATTTCATGAGAGATCTCAACATCAATCGTGTTGTTTATTACATTGTACAATACATGATCTACAGCCTTAAACACGTTATTAATACAGATAACACCTAAATTATCTAAATAACGCAAAACTTGGGTCCTAAAGACCCGTAAGAAACGCCCAGTCTGAGGAGTTAAACTCGTCCAGATCCGGAAGGTTAGCCAACATTTGTGAAGTCCCAGTGCTCTCCTCAGGTTGTGGTTGAACCGGATCTGGATTGTTATTATGTCGTGGTTCCGGAAGAATGGTCGGTCCAGGTGGCTTAGGATCCTGAAATAGAGGGGATTTGGAACCTCCCAGATATACACGCCATTCATTGCTTGAGCTGCAGTGATGGACTCCCCTGTGCGTGAATCCATGGTTGTGACAGTTGAGGCTGACGTAATACGAGCAGCCGCAGTTAAGGTCCACTCGTTTTCTGCGGAATGCTCTCCTCTTGGCTATTCTGTGTTGGACCTTGATTGGTACCTGAGAAGAGTGGCTCTTGGAGGGTGATGAATTTTGCATTCTTGATGGCCCACTGCTTGAGTGCAGAATTCTTTTCTTCGTCCAAGAATTCTTTATAGCTGGAATTGGGCCCTGGATTGCAGAGGAAGATTGTTGGGATTCCGCCTTTAATTTGAACTGGCTTTCCGTATTTCGTGTTTGATTGCCAATCCCTCTGGGCCCCCATGAATTCTTTAAAGTGTTTCAAATAATGCGGATCTACGTCATCAATGACGTTATACCAAGCATCGTTTGAATAAATTTTAGGGCTTAAATCCAAATGCCCACATAAATAATTATGTGGGCCTAATGATCTGGCCCATAAAGTCTTCCCTGTCCGACTATCGCCCTCGACGACAATACTATTAGGTCTATATGGCCGCGCAGCGGCACTCTTCACATTCTCAGACACCCACTCTTCTAACTCCTCAGGGACTCTATCAAACGAAGAAGACAAAAAAGGACTAACATAAACCTCTAATGGAGGTGCAAAAATCCTATCTAAATTTGATTTTAAATTATGATACTGGAAAATAAAATCTCTTGGGAGTTTCTCCCTAATAACATTTAAAGCAGCTTCAGCAGACCCAGAATTTAATGCCTCAGCTGCAGCATCGTTAGCTGTCTGTTGACCTCCTCTAGCAGATCTTCCATCGATCTGAAATCGACCCCATTCGACGTAATCTCCGTCCTTCTCGATGTATCTCTTGACATCAGAGCTGGATCTAGCTCCCTGGATGTGCGCATGGAATTGGGAGGAGGTGTTGGGATGAGTGACATCGAAATGTCTCTCATTTCGGAACTTGGCTTTACCCTTGAATTGTATGAGAGCATGGAGATGCAGAGACCCATCTCTGTGTTTCTCTTGTGCAACCCTAATGAACAGTTTCTCAGATGGACATGAAATGTTTTTAATGAGCTCGAGCATCTGTTCTTTTGGAATGGGGCATTTTGAATAAGTGAGGAAAATGTTTTTAGCGCTAACTGAAAACCTATTTATGCGAGGCATGTTTGACCGGAAGTGTCCCCAATTGACCACCCTCTCTAAAACTCAGGGAATTGGGGACACTGGGGACGCATTTATACTAGTGTCCCCAAATGGCATAATCGTAATTTTTGGATCTGAAATTCAAATCTGGCTCGCCACGTGGACCTCACCGTTGCCATCCGATTATAATATT
Gene Information
|
NCBI Accession
|
YP_001210299.1
|
|
Location
|
121-477 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGATCCTATCGTGAACGATCTACCTGAAACCGTACATGGGTTTCGTTCTATGCTTGCAATCAAGTATCTACAGGCTGTAGAAAATACGTATTCTCCGGATACGCTGGGATACGATCTTGTACGTGATTTGATATCTGTTCTACGTGCAAGAAATTATGTCGAAGCGACCAGGAGATATCATAATTTCCACGCCCGCATCAAAGGTGCGACGACGTTTGAACTTCGAAAGCCCATTTGCCAACCGTGCCATTGCCCCCATTGTGGGCGTCACAAGAAGACAGGCCTGGGTCAACAGGCCCACGAACAGGAAGCCCAAATGGTATCGAATTTACAAAAGCCCAGATGTGCCTAG |
|
Protein Sequence
|
MWDPIVNDLPETVHGFRSMLAIKYLQAVENTYSPDTLGYDLVRDLISVLRARNYVEATRRYHNFHARIKGATTFELRKPICQPCHCPHCGRHKKTGLGQQAHEQEAQMVSNLQKPRCA |
|
NCBI Accession
|
YP_001210300.1
|
|
Location
|
281-1051 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGGAGATATCATAATTTCCACGCCCGCATCAAAGGTGCGACGACGTTTGAACTTCGAAAGCCCATTTGCCAACCGTGCCATTGCCCCCATTGTGGGCGTCACAAGAAGACAGGCCTGGGTCAACAGGCCCACGAACAGGAAGCCCAAATGGTATCGAATTTACAAAAGCCCAGATGTGCCTAGGGGCTGTGAAGGCCCATGCAAGGTCCAATCATTCGAGTCCAGACATGATATATCTCATATTGGCAAGGTGATGTGCGTAAGCGATGTCACACGTGGCATTGGTCTTACTCATCGAGTTGGCAAGAGATTTTGTGTAAAATCTGTGTATGTTTTGGGAAAGATCTGGATGGATGAAAACATAAAGACTAAGAACCACACTAATAGTGTGATGTTCTTTTTGGTTCGTGATCGGAGACCAATCGACAAGCCACAAGATTTTGGTGACGTTTTTAATATGTTTGATAATGAGCCCAGTACGGCAACTGTGAAGAACGTTAATCGCGATCGATATCAGGTTTTACGTAAGTGGTATCGGACGGTCACTGGTGGTCAGTACGCGTCTAAGGAGCAGGCATTAGTTAGGAGATTTATTAGGGTTAATAATTATGTTGTTTATAATCAACAAGAAGCTGGGAAATACGAGAATCATACTGAGAACGCTCTTATGTTGTATATGGCATGCACTCATGCCTCTAACCCCGTGTATGCTACTCTGAAGATACGGATATATTTCTATGATTCTGTATCAAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPASKVRRRLNFESPFANRAIAPIVGVTRRQAWVNRPTNRKPKWYRIYKSPDVPRGCEGPCKVQSFESRHDISHIGKVMCVSDVTRGIGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPIDKPQDFGDVFNMFDNEPSTATVKNVNRDRYQVLRKWYRTVTGGQYASKEQALVRRFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_001210301.1
|
|
Location
|
1048-1452 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGTCCATCACTGCAGCTCAAGCAATGAATGGCGTGTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATCCTAAGCCACCTGGACCGACCATTCTTCCGGAACCACGACATAATAACAATCCAGATCCGGTTCAACCACAACCTGAGGAGAGCACTGGGACTTCACAAATGTTGGCTAACCTTCCGGATCTGGACGAGTTTAACTCCTCAGACTGGGCGTTTCTTACGGGTCTTTAGGACCCAAGTTTTGCGTTATTTAGATAATTTAGGTGTTATCTGTATTAATAACGTGTTTAAGGCTGTAGATCATGTATTGTACAATGTAATAAACAACACGATTGATGTTGAGATCTCTCATGAAATAAAATTTCTTTTGTATTAA |
|
Protein Sequence
|
MDSRTGESITAAQAMNGVYIWEVPNPLYFRILSHLDRPFFRNHDIITIQIRFNHNLRRALGLHKCWLTFRIWTSLTPQTGRFLRVFRTQVLRYLDNLGVICINNVFKAVDHVLYNVINNTIDVEISHEIKFLLY |
|
NCBI Accession
|
YP_001210302.1
|
|
Location
|
1193-1600 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAAAATTCATCACCCTCCAAGAGCCACTCTTCTCAGGTACCAATCAAGGTCCAACACAGAATAGCCAAGAGGAGAGCATTCCGCAGAAAACGAGTGGACCTTAACTGCGGCTGCTCGTATTACGTCAGCCTCAACTGTCACAACCATGGATTCACGCACAGGGGAGTCCATCACTGCAGCTCAAGCAATGAATGGCGTGTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATCCTAAGCCACCTGGACCGACCATTCTTCCGGAACCACGACATAATAACAATCCAGATCCGGTTCAACCACAACCTGAGGAGAGCACTGGGACTTCACAAATGTTGGCTAACCTTCCGGATCTGGACGAGTTTAACTCCTCAGACTGGGCGTTTCTTACGGGTCTTTAG |
|
Protein Sequence
|
MQNSSPSKSHSSQVPIKVQHRIAKRRAFRRKRVDLNCGCSYYVSLNCHNHGFTHRGVHHCSSSNEWRVYLGGSKSPLFQDPKPPGPTILPEPRHNNNPDPVQPQPEESTGTSQMLANLPDLDEFNSSDWAFLTGL |
|
NCBI Accession
|
YP_001210303.1
|
|
Location
|
1494-2588 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGCCTCGCATAAATAGGTTTTCAGTTAGCGCTAAAAACATTTTCCTCACTTATTCAAAATGCCCCATTCCAAAAGAACAGATGCTCGAGCTCATTAAAAACATTTCATGTCCATCTGAGAAACTGTTCATTAGGGTTGCACAAGAGAAACACAGAGATGGGTCTCTGCATCTCCATGCTCTCATACAATTCAAGGGTAAAGCCAAGTTCCGAAATGAGAGACATTTCGATGTCACTCATCCCAACACCTCCTCCCAATTCCATGCGCACATCCAGGGAGCTAGATCCAGCTCTGATGTCAAGAGATACATCGAGAAGGACGGAGATTACGTCGAATGGGGTCGATTTCAGATCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAACGATGCTGCAGCTGAGGCATTAAATTCTGGGTCTGCTGAAGCTGCTTTAAATGTTATTAGGGAGAAACTCCCAAGAGATTTTATTTTCCAGTATCATAATTTAAAATCAAATTTAGATAGGATTTTTGCACCTCCATTAGAGGTTTATGTTAGTCCTTTTTTGTCTTCTTCGTTTGATAGAGTCCCTGAGGAGTTAGAAGAGTGGGTGTCTGAGAATGTGAAGAGTGCCGCTGCGCGGCCATATAGACCTAATAGTATTGTCGTCGAGGGCGATAGTCGGACAGGGAAGACTTTATGGGCCAGATCATTAGGCCCACATAATTATTTATGTGGGCATTTGGATTTAAGCCCTAAAATTTATTCAAACGATGCTTGGTATAACGTCATTGATGACGTAGATCCGCATTATTTGAAACACTTTAAAGAATTCATGGGGGCCCAGAGGGATTGGCAATCAAACACGAAATACGGAAAGCCAGTTCAAATTAAAGGCGGAATCCCAACAATCTTCCTCTGCAATCCAGGGCCCAATTCCAGCTATAAAGAATTCTTGGACGAAGAAAAGAATTCTGCACTCAAGCAGTGGGCCATCAAGAATGCAAAATTCATCACCCTCCAAGAGCCACTCTTCTCAGGTACCAATCAAGGTCCAACACAGAATAGCCAAGAGGAGAGCATTCCGCAGAAAACGAGTGGACCTTAA |
|
Protein Sequence
|
MPRINRFSVSAKNIFLTYSKCPIPKEQMLELIKNISCPSEKLFIRVAQEKHRDGSLHLHALIQFKGKAKFRNERHFDVTHPNTSSQFHAHIQGARSSSDVKRYIEKDGDYVEWGRFQIDGRSARGGQQTANDAAAEALNSGSAEAALNVIREKLPRDFIFQYHNLKSNLDRIFAPPLEVYVSPFLSSSFDRVPEELEEWVSENVKSAAARPYRPNSIVVEGDSRTGKTLWARSLGPHNYLCGHLDLSPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALKQWAIKNAKFITLQEPLFSGTNQGPTQNSQEESIPQKTSGP |
|
NCBI Accession
|
YP_001210304.1
|
|
Location
|
2174-2431 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGTCTCTGCATCTCCATGCTCTCATACAATTCAAGGGTAAAGCCAAGTTCCGAAATGAGAGACATTTCGATGTCACTCATCCCAACACCTCCTCCCAATTCCATGCGCACATCCAGGGAGCTAGATCCAGCTCTGATGTCAAGAGATACATCGAGAAGGACGGAGATTACGTCGAATGGGGTCGATTTCAGATCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAACGATGCTGCAGCTGAGGCATTAA |
|
Protein Sequence
|
MGLCISMLSYNSRVKPSSEMRDISMSLIPTPPPNSMRTSRELDPALMSRDTSRRTEITSNGVDFRSMEDLLEEVNRQLTMLQLRH |