Abutilon mosaic Brazil virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000895175.1 |
| Isolate | Brazil |
| Release date | 2015/2/22 |
| Submitter | Wyant,P.S., Strohmeier,S., Schafer,B., Krenz,B., Assuncao,I.P., Lima,G.S., Jeske,H., Schaefer,B., Lima,G.S.A. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
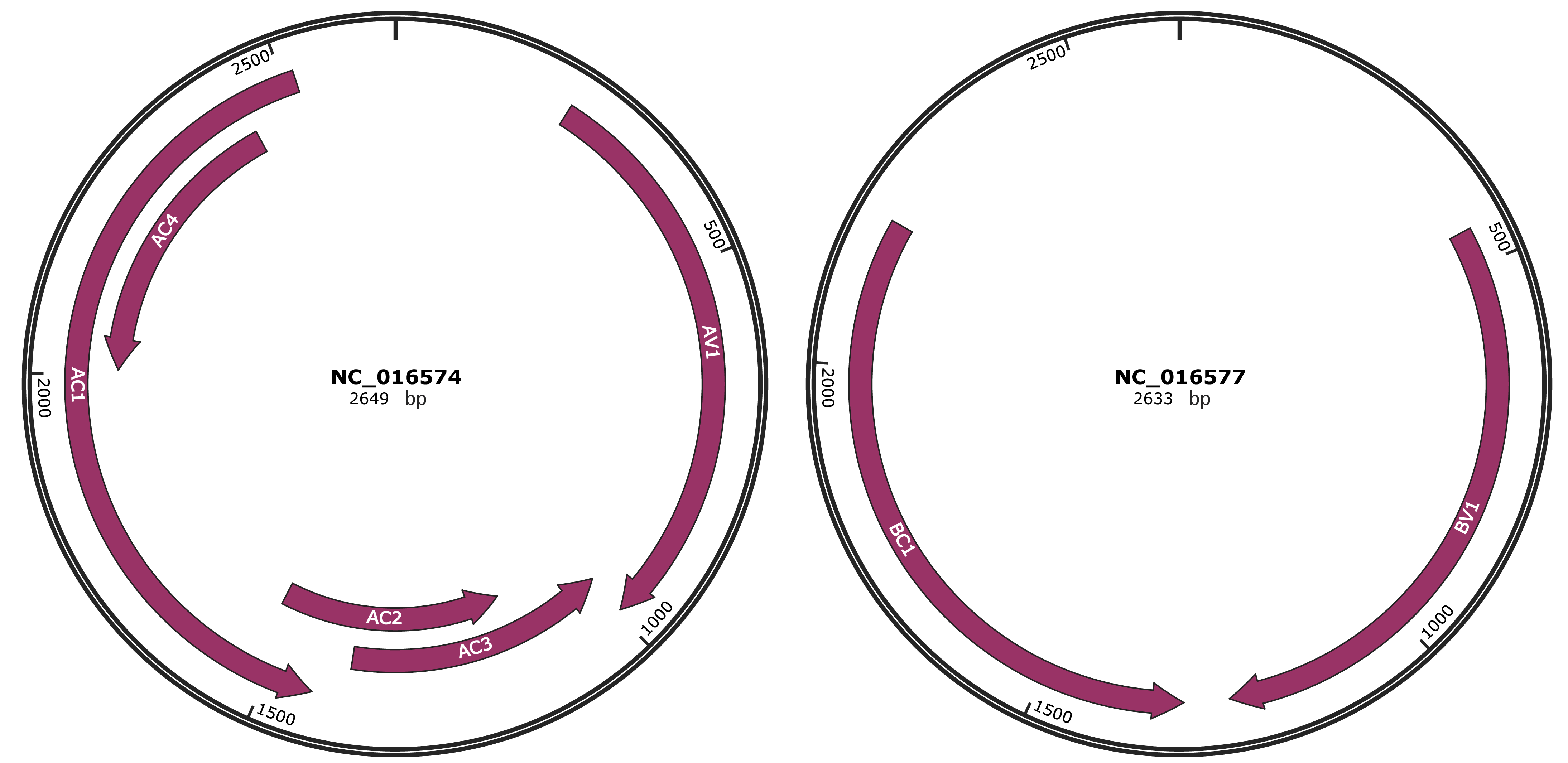
JBrowse
Genome
NC_016574
NC_016577
Gene Information
| NCBI Accession | YP_004958224.1 |
|---|---|
| Location | 239-994 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGCCTGATGGCGGGAACTTCCAAGGTTGGCCGTTTATCCAACACCGCTCCTCGTGGAGGTTCTGGGCCTAGGTCCAACAAGGCCAATGAGTGGGTCAACAGACCCATGTACAGGAAGCCCAGGATATACCGGGCCTTCAGAACTCCAGATGTCCCTCGAGGGTGTGAAGGGCCATGCAAGGTCCAGTCCTATGAACAGCGACATGATATCTCTCATGTCGGTAAGGTTATGTGTATATCTGATGTCACCCGAGGTAATGGTATTACTCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACACCAATGGACTTTGGCCAGGTCTTCAACATGTTTGACAACGAGCCCAGCACTGCTACGGTTAAGAACGATCTACGCGATCGTTATCAGGTCATGCACAAGTTCTATGCCAAGGTCACTGGCGGTCAGTATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTATAATCACCAGGAGGCTGGGAAGTACGAGAATCACACGGAGAACGCACTCCTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTACTTTTACGATTCGATCATGAATTAA |
| Protein Sequence | MPKRDAPWRLMAGTSKVGRLSNTAPRGGSGPRSNKANEWVNRPMYRKPRIYRAFRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_004958225.1 |
|---|---|
| Location | 991-1389 |
| Gene Name | AC3 |
| Protein Name | replication enhancer |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAATCAGGGTAGAGGATCCACCGTACACTCGGACAAGAGTGTACCACATCCAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGTCAACTTATTTGACTAGGTTTAGACACTTAGTCATGCTTTACTTAGACCGATTAGGAGTAATTACGCTTAACAATGTAATCAGAGCTGTGCGTTTCGCAACAGACAAATCTTATGTCAGCTATGTACTTGAAAACCACGTAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGELITARQAENGVYIWEITNPLYFKIIRVEDPPYTRTRVYHIQIRFNHNLRRALGLHKAFLNFQVWTTSLTASGSTYLTRFRHLVMLYLDRLGVITLNNVIRAVRFATDKSYVSYVLENHVIKFKFY |
| NCBI Accession | YP_004958226.1 |
|---|---|
| Location | 1136-1525 |
| Gene Name | AC2 |
| Protein Name | transcriptional regulator |
| Coding Region | ATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGGATTGCGAAGAAGAGAGCAATCAGGCGACGACGAATTGATCTGGACTGCGGCTGCTCCATTTACCAGCATCTCAACTGCACGGGCCATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAATCAGGGTAGAGGATCCACCGTACACTCGGACAAGAGTGTACCACATCCAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGTCAACTTATTTGACTAG |
| Protein Sequence | MLNSSSSTPPSIKPRHRIAKKRAIRRRRIDLDCGCSIYQHLNCTGHGFTHRGTHHCTSGREWRLYLGDNKSPVFQDNQGRGSTVHSDKSVPHPDKVQPQPQESIGSPQGIPELPSLDDFSDSFWVNLFD |
| NCBI Accession | YP_004958227.1 |
|---|---|
| Location | 1437-2516 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCCCGACTTTCCCATTCTTTTAGATTACAAGCCAGAAACATATTCCTCACATATCCCCGTTGCGACATACCCAAAGATGAAGCTCTTCAAATGCTTCAAGCCCTTTCATGGACAGTCGTCCAACCTACCTATATCAGAGTCGCACGTGAGGAACACTCCGATGGACACCCCCATCTACACTGTCTCATACAATTATCAGGAAAGTCCAACATCAGGGATGCAAGATTTTTCGACCTTACTCACCCCAGACGGTCAGCCAGTTTTCACCCGAACGTGCAAGCTGCCAAAGACACCGTTGCCGTCAGGAACTACATCACCAAAGATGGTGACTATTGTGAATCCGGACAATACAAGGTGTCTGGGGGTACCAAGGCCAACAAGGACGATGTCTTCCACAACGCCGTCAATGCAGGAGGTGTTTCAGAGGCTCTTGAAATTATCAGAGCCGGAGATCCAAAGACCTTCATCGTCCAACACCATAACATCCGCTCCAACCTGGAATTGATCTTTAAGAGGGCTCCGGAACCATGGGCTCCTCCGTTTCCCCTCTCATCGTTCACTAACGTTCCTGAAGAGATGCAAGAGTGGGCGGATGATTATTTTGGAAGAAGTTCCGCTGCGCGGCCTGTTAGGCCCATAAGTATAATAGTTGAAGGTGATTCTCGAACTGGTAAGACGATGTGGGCTAGAGCATTAGGCCCACATAATTACTTGAGTGGCCATTTAGATTTCAATTCCCGGGTCTACTCAAATCAAGTTGAGTATAACGTCATCGATGATGTCAGCCCGCAATACCTAAAGCTAAAGCACTGGAAGGAATTGATTGGTGCTCAAAAAGATTGGCAGTCCAATTGCAAGTACGGCAAGCCTGTTCAAATTAAAGGGGGTATCCCATCAATCGTGCTATGCAATCCTGGAGAGGGGGCCAGCTATAAAGATTTCCTGGAGAAGCAGGAAAACTCATCACTTAAAGCCTGGACAATCAACAATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGGATTGCGAAGAAGAGAGCAATCAGGCGACGACGAATTGA |
| Protein Sequence | MPRLSHSFRLQARNIFLTYPRCDIPKDEALQMLQALSWTVVQPTYIRVAREEHSDGHPHLHCLIQLSGKSNIRDARFFDLTHPRRSASFHPNVQAAKDTVAVRNYITKDGDYCESGQYKVSGGTKANKDDVFHNAVNAGGVSEALEIIRAGDPKTFIVQHHNIRSNLELIFKRAPEPWAPPFPLSSFTNVPEEMQEWADDYFGRSSAARPVRPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNQVEYNVIDDVSPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLEKQENSSLKAWTINNAKFIFLNSPLYQTTTQDCEEESNQATTN |
| NCBI Accession | YP_004958228.1 |
|---|---|
| Location | 2009-2437 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAGCTCTTCAAATGCTTCAAGCCCTTTCATGGACAGTCGTCCAACCTACCTATATCAGAGTCGCACGTGAGGAACACTCCGATGGACACCCCCATCTACACTGTCTCATACAATTATCAGGAAAGTCCAACATCAGGGATGCAAGATTTTTCGACCTTACTCACCCCAGACGGTCAGCCAGTTTTCACCCGAACGTGCAAGCTGCCAAAGACACCGTTGCCGTCAGGAACTACATCACCAAAGATGGTGACTATTGTGAATCCGGACAATACAAGGTGTCTGGGGGTACCAAGGCCAACAAGGACGATGTCTTCCACAACGCCGTCAATGCAGGAGGTGTTTCAGAGGCTCTTGAAATTATCAGAGCCGGAGATCCAAAGACCTTCATCGTCCAACACCATAACATCCGCTCCAACCTGGAATTGA |
| Protein Sequence | MKLFKCFKPFHGQSSNLPISESHVRNTPMDTPIYTVSYNYQESPTSGMQDFSTLLTPDGQPVFTRTCKLPKTPLPSGTTSPKMVTIVNPDNTRCLGVPRPTRTMSSTTPSMQEVFQRLLKLSEPEIQRPSSSNTITSAPTWN |
| NCBI Accession | YP_004958237.1 |
|---|---|
| Location | 453-1250 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTCCCATGTGTGTATGCCTAGTTTGAACATGTATTCTACAAAGAGTAGACGGGGATCGTCTGCATATCGGGGAACTTATTCTCGTAAACCTTTTATTAGACGTTCCTATGGTTCATCACGCACACATGCTAGACGTCGTGTTAGTAATCCTAACAGGTCAAGTGACGATAGCAAGATGTCACATTTTAGGATTCATGAAAATCAATATGGCCCAGAGTTTGTAATGCTTCATAACACGGCGATATCTACGTTTATTACGTATCCCACCCTTGGTAAGACTGAGCCTTGTCGTACTAGGTCATACATTAAACTGAGACGTTTGCGATATAAGGGAACTGTTAAGATTGAACGTGTTCACACGGATGTGAACATGAACGGGTTAATCCCCAAGATTGAAGGTGTGTTTTCCTTGGTGGTTGTTGTTGATCGCAAACCTCATCTTAGCCCATCTGGGAGCCTGTATACATTTGATGAGCTATTTGGTGCAAGGATCCATAGCCATGGTAACTTGGCCATTACTTCAGCTCTGAGAGATCGGTTTTACATACGTCATGTCCTGAAACGTGTATTATCTGTTGAGAAGGATACGACCATGATTGATCTCGAAGCAACCACATTATTGTCCACCAGGCGTTACAACTGTTGGGCTACTTTTAATGACCTTGATCGAGAATCATGTAATGGTGTTTATGCAAACATTAGCAAGAACGCCTTATTGGTTTATTATTGTTGGATGTCTGATACTGTGTCTAAGGCATCTACTTTTGTATCATTTGATCTGGATTACGTTGGATAA |
| Protein Sequence | MSHVCMPSLNMYSTKSRRGSSAYRGTYSRKPFIRRSYGSSRTHARRRVSNPNRSSDDSKMSHFRIHENQYGPEFVMLHNTAISTFITYPTLGKTEPCRTRSYIKLRRLRYKGTVKIERVHTDVNMNGLIPKIEGVFSLVVVVDRKPHLSPSGSLYTFDELFGARIHSHGNLAITSALRDRFYIRHVLKRVLSVEKDTTMIDLEATTLLSTRRYNCWATFNDLDRESCNGVYANISKNALLVYYCWMSDTVSKASTFVSFDLDYVG |
| NCBI Accession | YP_004958238.1 |
|---|---|
| Location | 1311-2192 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGAGTTCTCAGTTGGTTGCTCCTCCAAGCGCTTTTAATTATGTTGAATCTCAGCGTGATGAATACCAGCTATCGCATGACCTAACAGAAATTGTTCTGCAATTTCCTTCAACGGCGTCGCAAATTAGTGCTAAACTGAGTCGGAGCTGTATGAAGATAGATCATTGCGTCATCGAATACAGGCAGCAAGTGCCAATTAACGCCACAGGCTCAGTCATAATGGAGATTCACGACAAGAGGATGACGGACAATGAATCTCTACAGGCATCTTGGACCTTCCCAATCAGATGCAACATAGACCTACACTACTTCTCGTCGTCGTTCTTCTCCCTAAAAGATCCAATTCCATGGAAGTTATACTACAGAGTGATGGACACGAACGTTCATCAAAGGACGCATTTCGCCAAGTTCAAAGGAAAGCTGAAACTGTCAACAGCTAAACACTCTGTAGATATTCCGTTTAGGGCACCAACTGTGAAGATACTGTCGAAGCAGTTCACAGAAAAGGATATAGATTTCTCACACGTTGGATACGGAGCTTGGGAGCGGAAGCTCATAAGAACAGCTTCGACGTCAAGATTTGGGCTGCAAGTCCCAATAGAAATAAAGCCTGGAGAATCATGGGCTTCTAGAAGCACTATTGGGCTCACGAACTCATCAGGGGACTCGCAGCTACAAAACGAGATCCACCCATATAGACATTTACACAGACTAGGTTCAACAGTATTAGATCCAGGGGAGTCAGCATCGGTTACAGGAGCAGAGAGAACACGCTCCAACATTTCAATTTCGTTAGCGGAATTGAACGAGATTGTTAGGTCTACCGTACATGAATGTATTAACACAAATTGTACACCATCAGAACCAAAGTCATTGAAATAA |
| Protein Sequence | MSSQLVAPPSAFNYVESQRDEYQLSHDLTEIVLQFPSTASQISAKLSRSCMKIDHCVIEYRQQVPINATGSVIMEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVMDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTEKDIDFSHVGYGAWERKLIRTASTSRFGLQVPIEIKPGESWASRSTIGLTNSSGDSQLQNEIHPYRHLHRLGSTVLDPGESASVTGAERTRSNISISLAELNEIVRSTVHECINTNCTPSEPKSLK |
References More References in PubMed
| 1 |
Jovel J, et al. Arch Virol. 2004 Apr;149(4):829-41. doi: 10.1007/s00705-003-0235-1. Epub 2003 Dec 8. PMID: 15045569 |
|---|---|
| 2 |
Maliano MR, et al. PLoS One. 2021 Apr 28;16(4):e0250066. doi: 10.1371/journal.pone.0250066. eCollection 2021. PMID: 33909644 |
| 3 |
The complete nucleotide sequence of a new bipartite begomovirus from Brazil infecting Abutilon. Paprotka T, et al. Arch Virol. 2010 May;155(5):813-6. doi: 10.1007/s00705-010-0647-7. Epub 2010 Mar 28. PMID: 20349251 |
| 4 |
Two new begomoviruses infecting tomato and Hibiscus sp. in the Amazon region of Brazil. Quadros AFF, et al. Arch Virol. 2019 Jul;164(7):1897-1901. doi: 10.1007/s00705-019-04245-6. Epub 2019 Apr 10. PMID: 30972592 |
| 5 |
Variability in Geminivirus Isolates Associated with Phaseolus spp. in Brazil. Faria JC, et al. Phytopathology. 1999 Mar;89(3):262-8. doi: 10.1094/PHYTO.1999.89.3.262. PMID: 18944768 |
| 6 |
Molecular and biological characterization of corchorus mottle virus, a new begomovirus from Brazil. Blawid R, et al. Arch Virol. 2013 Dec;158(12):2603-9. doi: 10.1007/s00705-013-1764-x. Epub 2013 Jun 29. PMID: 23812656 |
| 7 |
Novel begomoviruses recovered from Pavonia sp. in Brazil. Pinto VB, et al. Arch Virol. 2016 Mar;161(3):735-9. doi: 10.1007/s00705-015-2708-4. Epub 2015 Dec 12. PMID: 26660167 |