Cleome golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000893495.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Fonseca,M.E.N., Boiteux,L.S., Fernandes,N.A.N., Costa,A.F. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
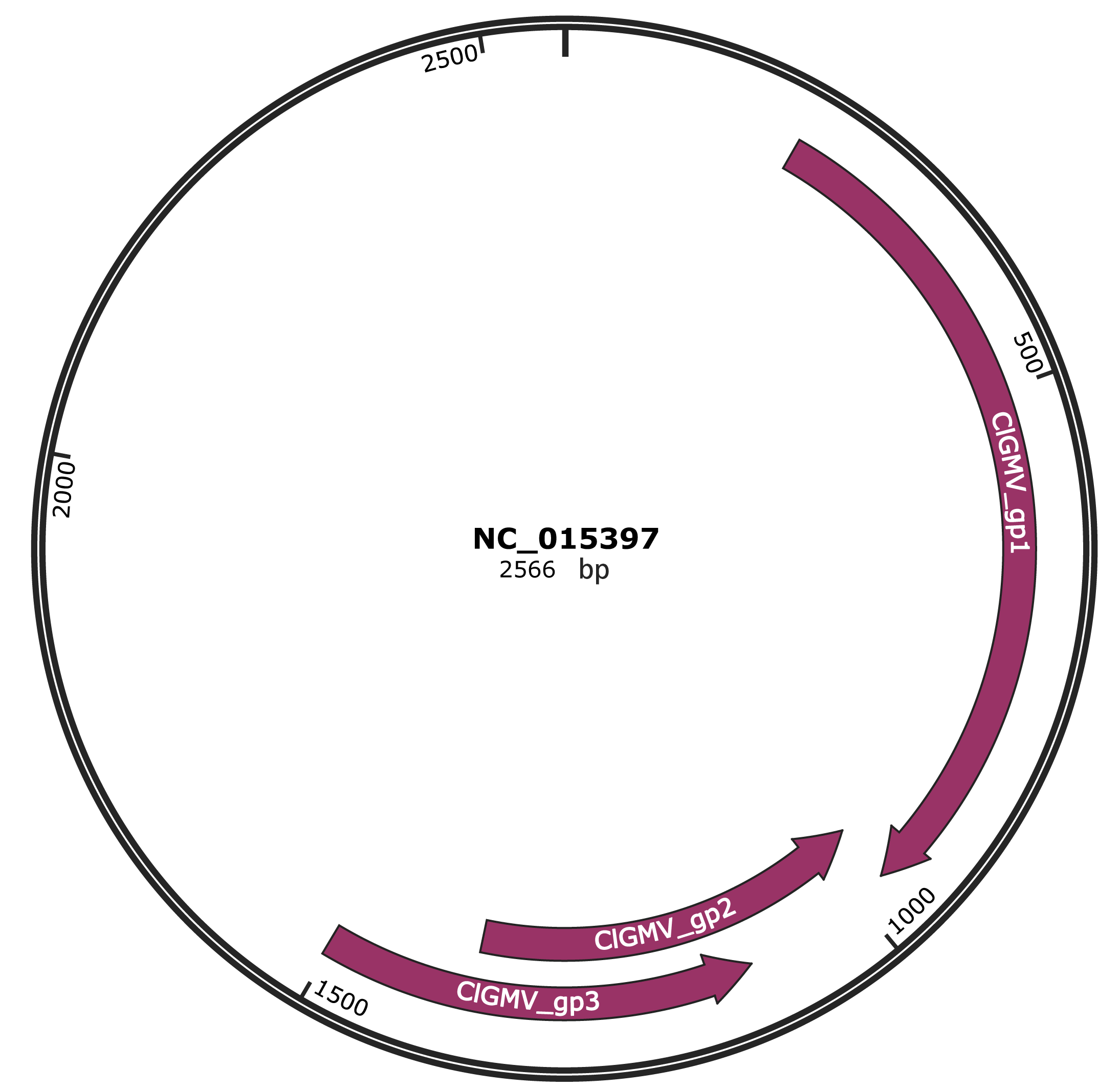
JBrowse
Genome
ACCGGATGGCCGCGCGATCAAAAAGTGGCCCCCCTCTCCGTAAATCGCGGCGCGTTGTCGGGTTCGTGGTCCCCCACGAGTATCTTGGACTTTGTATGGCCCAATAACAATTGGGCTTGAAAGCCAATATATGAAAATATACTTGGCCGCTAAGTTGATAAAGTTGTATATAAGGGGACCACATTCAATGTTCCCCGCATTCTGTTGTACAGAATGCCTAAGCGGGATGCCCCATGGCGCTTGTCGGCGGGTACCACCAAGGTTAGCCGCAATGCTAACTACTCCCCTGGTGGAGCTACGGGCCCTCGACCAAGCAGGGCCTCTGCTTGGGTTAACAGGCCCATGTATAGGAAGCCGCGTATTTACCGGATGTACCGATCACCCGATGTGCCCAAAGGGTGCGAAGGCCCATGCAAGGTCCAGTCATACGAGCAGCGTCACGATATATCCCACACCGGGAAGGTGCTATGCATATCGGACGTTACCCGAGGTAACGGTATAACTCACCGCGTCGGTAAGCGGTTTTGCGTTAAGTCTGTGTACATACTAGGCAAGATTTGGATGGACGAGAACATAAAGCTCAAGAACCACACGAATAGTGTGATGTTCTGGCTAGTTAGGGATAGGAGACCGTATGGGACGCCTATGGATTTTGGACAGGTTTTCAACCTGTTTGACAACGAGCCTAGCACTGCTACGGTGAAGAACGATCTTCGCGATCGTTTTCAGGTGATGCACAGGTTCTACGCCAAGGTGACCGGAGGGCAATATGCGAGCAACGAACAGGCGCTAGTGCGGCGTTTCTGGAGGGTCAATAACTATGTGGTGTACAACCACCAAGAGGCGGCGAAGTACGAGAACCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCGACGCTTAAGATTCGAATCTATTTCTACGATTCGATATCAAATTAATAAAATTTGAATTTTATTGAATGGTTCTCATGTACATGGGATACATACGATCGATCAGTTGCGAAACTGACGGCCCTGATTACATTGTTAAGGCTAATAACGCCTAGCTGATCAAGATACATGAGAACTAGATGTTTAAACCTATTTAAATAGGTCTGCCCAGAAGCTGTCACCGAGACTGTCCAGACTTGGAAGTTGAGAAAGGCCATGTGGAGAGCCAATGCTCTCCTCACGCTGTGGTTGAACCGTATCTGGACGTGGTATATCCTCGTCTCTGCTGTGCAGGACGTCCTCCACGTCGTGTATCCTGAAATACAGGGGATTTGATATCTCCCATGTATACACGCCATTCTCCGCCTGAGGCACAGCTGATGACGTTCCCCTGTGCGTGAATTCATTGCTATGGCAGTTAAGGTGGATGTATATGGTACATCCACAGGTGAGGTCGATACGTCTACGGCGAATGGCTCTCCGCTTCGCGGCCTTGTGTTGAGCTTTGATACAGGGGGGATTCGAGGAAGACGAACCTCGCATTGTGAAGGGTCCAGGCTCTGAGTGCAGAATTCTCCTCTTTCTCGAGGAAGTCTTTATAGCTGGACCCTTCACCAGGATTGCAAAGCACGATTGATGGGATACCGCCTTTAATTTGAACAGGCTTTCCATATTTGCAGTTGCTTTGCCAGTCTCGTTGGGCCCCAACGAGCTCTTTCCAGTGCTTTAGCTTTAGGTATTGCGGTGGCAACGTCATCAATGACGTTGTATGCGACCTCGTGTTGAGTAGACCCTCGGATTGAAATCGAGGTGTCCACTGAGATAATTGTGTGGACCTTTAGTTCGCGCCCACGTTGTTTACCACGGCCTCGAATCCCCTTCCACGATTAACGACAATGGACGATAACTATTATTATGTTCAGGCCGCGCAGCGGCACACGAGCCGAAGTACTCTTCGGCCCAGAGACGCATCTCGTCAGGGACGTTAATAAACGAGGAGATAGGGAACGGAGGGACCCACGGATCATGAGCCTTGGAGAAAATCCTGTCCAGATTACTGGACAGATTGTGATATTGGAAGAGAAACTTCTCCGGCAGTTTCTCTCTGACGATTTGCATTGCTTCTTCTTTCGAAGAAGCATTTAACGCCTCTGCTGCAGCGTCGTTAGCCGTCTGCTGACCTCCTCTAGCAGATCGTCCGTCGATCTGGAATTGACCCCATTCGAGGATATCACCGTCCTTGTCGAGGTAGTGACTTGACGTCGGAGCTAGATTTAGCTCCCTGAACATTCGGATGGAAATGTGTTGACCTGGTAGGGGACGGTATATCGAAGAATCGGTTATTTGTACAGTTGTATTTCCCTTCAAACTGGATAAGCACGTGGAGATGAGGCTCCCCATTCTCGTGGAGCTCTCTTGCGACCTTGATGAATTTCTTGTTTGTTGGGGGGAAAAAGAGCCCTTCCGTGGCATTTTGGTAAATAAGAGTGTTCCCCCGATTGAGCTCGCTCTCAAAGTCTCTATGAATCGGGGGAACTGGGGGAACATTTATAGTAGAAGGTCCTTAGGCTCTAAAGGCCACGTGTCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_004376206.1
|
|
Location
|
214-969 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCATGGCGCTTGTCGGCGGGTACCACCAAGGTTAGCCGCAATGCTAACTACTCCCCTGGTGGAGCTACGGGCCCTCGACCAAGCAGGGCCTCTGCTTGGGTTAACAGGCCCATGTATAGGAAGCCGCGTATTTACCGGATGTACCGATCACCCGATGTGCCCAAAGGGTGCGAAGGCCCATGCAAGGTCCAGTCATACGAGCAGCGTCACGATATATCCCACACCGGGAAGGTGCTATGCATATCGGACGTTACCCGAGGTAACGGTATAACTCACCGCGTCGGTAAGCGGTTTTGCGTTAAGTCTGTGTACATACTAGGCAAGATTTGGATGGACGAGAACATAAAGCTCAAGAACCACACGAATAGTGTGATGTTCTGGCTAGTTAGGGATAGGAGACCGTATGGGACGCCTATGGATTTTGGACAGGTTTTCAACCTGTTTGACAACGAGCCTAGCACTGCTACGGTGAAGAACGATCTTCGCGATCGTTTTCAGGTGATGCACAGGTTCTACGCCAAGGTGACCGGAGGGCAATATGCGAGCAACGAACAGGCGCTAGTGCGGCGTTTCTGGAGGGTCAATAACTATGTGGTGTACAACCACCAAGAGGCGGCGAAGTACGAGAACCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCGACGCTTAAGATTCGAATCTATTTCTACGATTCGATATCAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLSAGTTKVSRNANYSPGGATGPRPSRASAWVNRPMYRKPRIYRMYRSPDVPKGCEGPCKVQSYEQRHDISHTGKVLCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNLFDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_004376207.1
|
|
Location
|
966-1367 |
|
Protein Name
|
Ren |
|
Coding Region
|
ATGAATTCACGCACAGGGGAACGTCATCAGCTGTGCCTCAGGCGGAGAATGGCGTGTATACATGGGAGATATCAAATCCCCTGTATTTCAGGATACACGACGTGGAGGACGTCCTGCACAGCAGAGACGAGGATATACCACGTCCAGATACGGTTCAACCACAGCGTGAGGAGAGCATTGGCTCTCCACATGGCCTTTCTCAACTTCCAAGTCTGGACAGTCTCGGTGACAGCTTCTGGGCAGACCTATTTAAATAGGTTTAAACATCTAGTTCTCATGTATCTTGATCAGCTAGGCGTTATTAGCCTTAACAATGTAATCAGGGCCGTCAGTTTCGCAACTGATCGATCGTATGTATCCCATGTACATGAGAACCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MNSRTGERHQLCLRRRMACIHGRYQIPCISGYTTWRTSCTAETRIYHVQIRFNHSVRRALALHMAFLNFQVWTVSVTASGQTYLNRFKHLVLMYLDQLGVISLNNVIRAVSFATDRSYVSHVHENHSIKFKFY |
|
NCBI Accession
|
YP_004376208.1
|
|
Location
|
1111-1503 |
|
Protein Name
|
Trap |
|
Coding Region
|
ATGCGAGGTTCGTCTTCCTCGAATCCCCCCTGTATCAAAGCTCAACACAAGGCCGCGAAGCGGAGAGCCATTCGCCGTAGACGTATCGACCTCACCTGTGGATGTACCATATACATCCACCTTAACTGCCATAGCAATGAATTCACGCACAGGGGAACGTCATCAGCTGTGCCTCAGGCGGAGAATGGCGTGTATACATGGGAGATATCAAATCCCCTGTATTTCAGGATACACGACGTGGAGGACGTCCTGCACAGCAGAGACGAGGATATACCACGTCCAGATACGGTTCAACCACAGCGTGAGGAGAGCATTGGCTCTCCACATGGCCTTTCTCAACTTCCAAGTCTGGACAGTCTCGGTGACAGCTTCTGGGCAGACCTATTTAAATAG |
|
Protein Sequence
|
MRGSSSSNPPCIKAQHKAAKRRAIRRRRIDLTCGCTIYIHLNCHSNEFTHRGTSSAVPQAENGVYTWEISNPLYFRIHDVEDVLHSRDEDIPRPDTVQPQREESIGSPHGLSQLPSLDSLGDSFWADLFK |