Chilli leaf curl Sri Lanka virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_004786955.1 |
| Isolate | Sri Lanka: Nochchiyagama |
| Release date | 2021/6/1 |
| Submitter | Senanayake,D.M., Mandal,B., Jayasinghe,J.E., Wasala,S.K. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
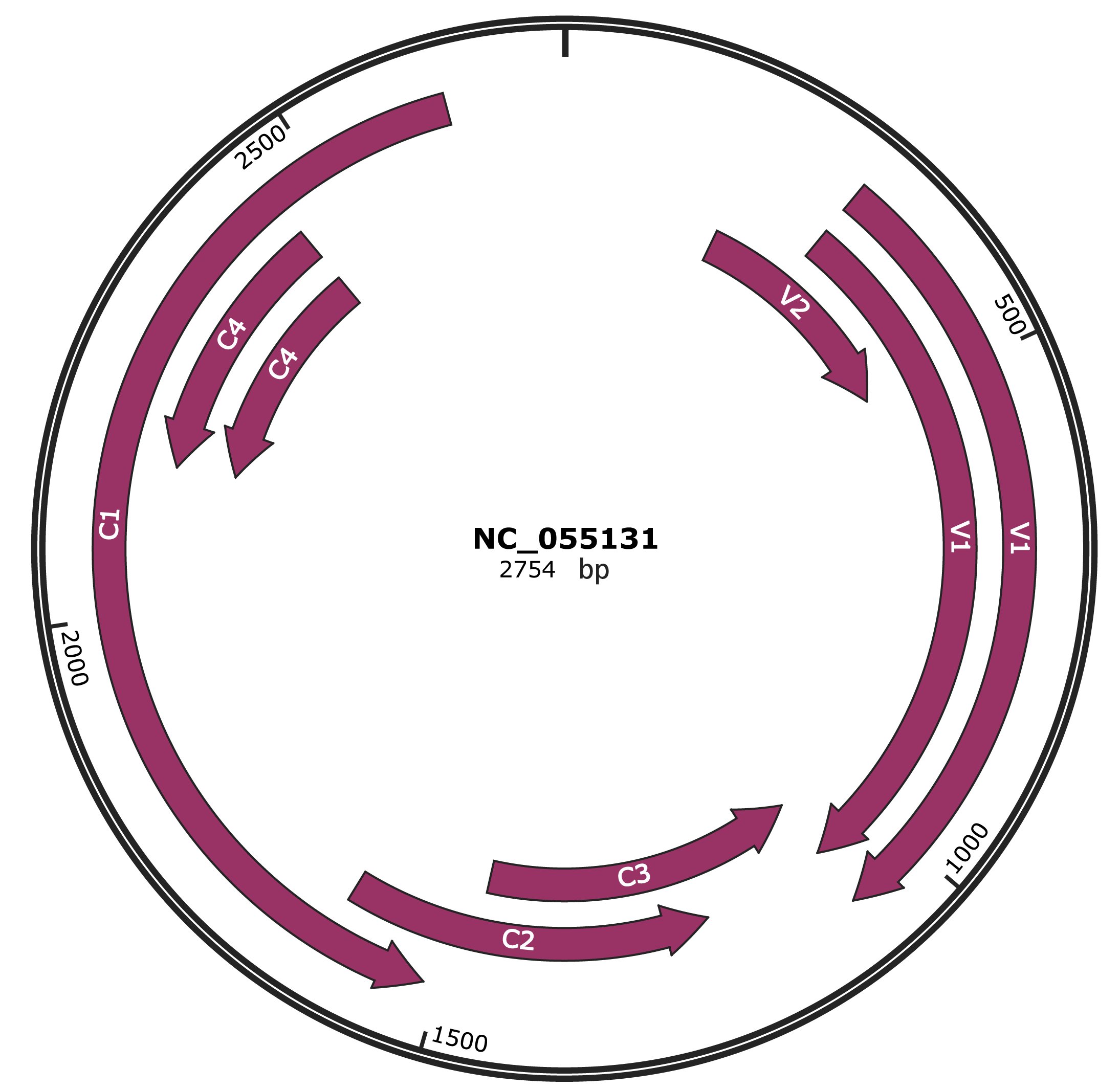
JBrowse
Genome
NC_055131
Gene Information
| NCBI Accession | YP_010084340.1 |
|---|---|
| Location | 197-490 |
| Gene Name | V2 |
| Protein Name | V2 protein |
| Coding Region | ATGCTTGCAATTAAATACTTGCAACTTGTAGAAAATACGTATTCCCCTGATTCTCTGGGATACGACTTGATACGAGAATTAATATCCGTAGTTCGTGCCAAAAATTATGTCCAAGCGTCCGGCAGATATGATCATTTCAGGACCCGCCTCGAAGTATCGTCGACTGCTGACCTCAACCAGCCCATACAGCCGACGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MLAIKYLQLVENTYSPDSLGYDLIRELISVVRAKNYVQASGRYDHFRTRLEVSSTADLNQPIQPTCCCPHCPRHKGKGMGQQAHESEAHVLQNVQKP |
| NCBI Accession | YP_010084341.1 |
|---|---|
| Location | 303-1073 |
| Gene Name | V1 |
| Protein Name | V1 protein |
| Coding Region | ATGTCCAAGCGTCCGGCAGATATGATCATTTCAGGACCCGCCTCGAAGTATCGTCGACTGCTGACCTCAACCAGCCCATACAGCCGACGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGATGTTCCCAAGGGATGTGAAGGCCCATGTAAGGTCCAGTCTTTCGAGTCTAGGCATGACGTAGTTCATATTGGTAAGGTTATGTGTATTAGTGATGTTACTAGGGGTACGGGTCTGACCCATAGGGTAGGTAAGCGTTTCTGCGTTAAGTCTGTCTATGTTCTGGGCAAGATATGGATGGATGAGAACATCAAAACCAAGAACCACACTAACAGTGTTATGTTCTTCCTTGTTCGTGATCGTCGTCCAGTTGATAAACCTCAAGATTTTGGTGATGTGTTTAACATGTTCGACAACGAGCCGAGCACTGCAACGGTCAAGAATATGCACAGGGATCGTTACCAGGTTCTCAGGAAGTGGCATGCAACCGTGACTGGTGGTCAATATGCGTCTAAGGAGCAGGCTCTCGTGAAGAAATTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCACAGTGAGAATGCGTTGATGTTGTATATGGCATGTACGCATGCCTCAAACCCCGTGTATGCTACTCTGAAAATACGAATCTATTTCTACGATTCGGTTACAAATTAA |
| Protein Sequence | MSKRPADMIISGPASKYRRLLTSTSPYSRRAAVRIVRATKGKEWANRPMNRKPMFYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGDVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_010084342.1 |
|---|---|
| Location | 1070-1474 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTACGCACAGGGGAACGCATCACTGCAGCTCAGGCAACGAATGGCGTCAGTATCTTGCAGGTCCCAAATCCCCTATATTTCAAGATCCTCAGCCACGACAGCAGGCCATTCAACTCCAACACGGACCTGATAACTATCAGGGTCCAGTTCAACCACAACCTTCGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTGTTTAGGACCCAAGTGTTAAAATGTATCAATAATTTTGCTGTAATTAGCCTCAACAATGTAATTAGGGCAGTCGATCATGTATTGTGGAATGTATTAACGCAAACAGTCTATGTACAGAGTTCAAACATAATAAAATTCAATGTTTATTAA |
| Protein Sequence | MDLRTGERITAAQATNGVSILQVPNPLYFKILSHDSRPFNSNTDLITIRVQFNHNLRKALGIHKCFLTFRIWTTLQPQTGHFLRVFRTQVLKCINNFAVISLNNVIRAVDHVLWNVLTQTVYVQSSNIIKFNVY |
| NCBI Accession | YP_010084343.1 |
|---|---|
| Location | 1215-1619 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCAATCTTCGTCACCCTCACAGGCCCACTATACTCAGGTACCAATCAAGGTTCTCCACAGGCAAGCCAAGAGGTCCATCAGGAGGAAGAGGGTGGACCTTGACTGTGGTTGTTCCTACTACATCCATATCAACTGCAGGAACCATGGATTTACGCACAGGGGAACGCATCACTGCAGCTCAGGCAACGAATGGCGTCAGTATCTTGCAGGTCCCAAATCCCCTATATTTCAAGATCCTCAGCCACGACAGCAGGCCATTCAACTCCAACACGGACCTGATAACTATCAGGGTCCAGTTCAACCACAACCTTCGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTGTTTAG |
| Protein Sequence | MQSSSPSQAHYTQVPIKVLHRQAKRSIRRKRVDLDCGCSYYIHINCRNHGFTHRGTHHCSSGNEWRQYLAGPKSPIFQDPQPRQQAIQLQHGPDNYQGPVQPQPSESVGDTQMFSNLPNLDDLTASDWSFLKGV |
| NCBI Accession | YP_010084344.1 |
|---|---|
| Location | 1516-2640 |
| Gene Name | C1 |
| Protein Name | Rep protein |
| Coding Region | ATGGAGTTTGGAGAGCCAATTGTCCAATTCAAAATGCCTAAAACACGGTCGTTTCAAGTTCAGGCTAAAAATATTTTTTTAACATACCCCAAATGCCCAATACCCAAAGAACAAATGTTAGAACTTATTAAGGGCATTAACTGTCCATCTGATAAACTATTTATACGGGTTGCTCAGGAAAAACACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAAGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAACACCTCATCCCAATTCCATCCAAACTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGATTTTCAGCTCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTCAATTCAGGATCCGCTGATGCCGCTTTGGCAATAATAAGGGAGAAACTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAGTCTAATTTAGATAGGATTTTTGCACCTCCAAGAGAGGTTTATATTTCTCCTTTTTCTATTTCTTCTTTTGATCAAGTTCCTGATGAACTTGAAGAATGGGCTGCAGTTAATGTTGTCACTGCCGCTGCGCGGCCTATTAGGCCCATAGGAATTGTTATTGAGGGTGATAGTCGGACCGGCAAAACAATGTGGGCTAGGTCCCTCGGCCCTCACAATTATTTGTGTGGCCACTTGGACTTAAGCCCAAGAGTGTATTCAAATGACGCATGGTATAACGTCATTGATGATGTGGATCCGCATTATTTAAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAGTCCAACACCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGCATTCCCACTATCTTCCTCTGCAATCCAGGGCCCAACTCCAGCTATAAAGAGTTCCTGGACGAAGAAAAGCATTCCGCACTAAAACATTGGGCACTCAAGAATGCAATCTTCGTCACCCTCACAGGCCCACTATACTCAGGTACCAATCAAGGTTCTCCACAGGCAAGCCAAGAGGTCCATCAGGAGGAAGAGGGTGGACCTTGA |
| Protein Sequence | MEFGEPIVQFKMPKTRSFQVQAKNIFLTYPKCPIPKEQMLELIKGINCPSDKLFIRVAQEKHQDGSLHIHALIQFKGKAQFRNPRHFDVTHPNTSSQFHPNFQGAKSSSDVKSYIEKDGDYIDWGDFQLDGRSARGGQQTANDAAAEALNSGSADAALAIIREKLPKDFIFQYHNLKSNLDRIFAPPREVYISPFSISSFDQVPDELEEWAAVNVVTAAARPIRPIGIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKHSALKHWALKNAIFVTLTGPLYSGTNQGSPQASQEVHQEEEGGP |
| NCBI Accession | YP_010084345.1 |
|---|---|
| Location | 2160-2450 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAAGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAACACCTCATCCCAATTCCATCCAAACTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGATTTTCAGCTCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTCAATTCAGGATCCGCTGATGCCGCTTTGGCAATAA |
| Protein Sequence | MGLCISMPSSSSRVKPSSETPDISMSLTLTPHPNSIQTSRELSPHPMSSPTSRRTVITSTGVIFSSMEDLLEEVNRQLMMLQQRPSIQDPLMPLWQ |
References More References in PubMed
| 1 |
A new begomovirus-betasatellite complex is associated with chilli leaf curl disease in Sri Lanka. Senanayake DM, et al. Virus Genes. 2013 Feb;46(1):128-39. doi: 10.1007/s11262-012-0836-4. Epub 2012 Oct 23. PMID: 23090833 |
|---|---|
| 2 |
Shingote PR, et al. Front Microbiol. 2022 Jun 29;13:899512. doi: 10.3389/fmicb.2022.899512. eCollection 2022. PMID: 35847087 |
| 3 |
Venkataravanappa V, et al. Microb Pathog. 2023 Jul;180:106127. doi: 10.1016/j.micpath.2023.106127. Epub 2023 Apr 28. PMID: 37119939 |
| 4 |
Padelkar P, et al. Mol Biol Rep. 2025 Sep 20;52(1):933. doi: 10.1007/s11033-025-11038-5. PMID: 40974375 |
| 5 |
Jayanthi P, et al. Int Microbiol. 2025 Apr;28(4):863-876. doi: 10.1007/s10123-024-00580-0. Epub 2024 Sep 4. PMID: 39230779 |