Turnip leaf roll virus
Basic Information
| Genus | Turncurtovirus |
|---|---|
| NCBI Assembly | GCF_001550845.1 |
| Isolate | Iran |
| Release date | 2016/2/7 |
| Submitter | Kamali,M., Heydarnejad,J., Massumi,H., Kvarnheden,A., Kraberger,S., Varsani,A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
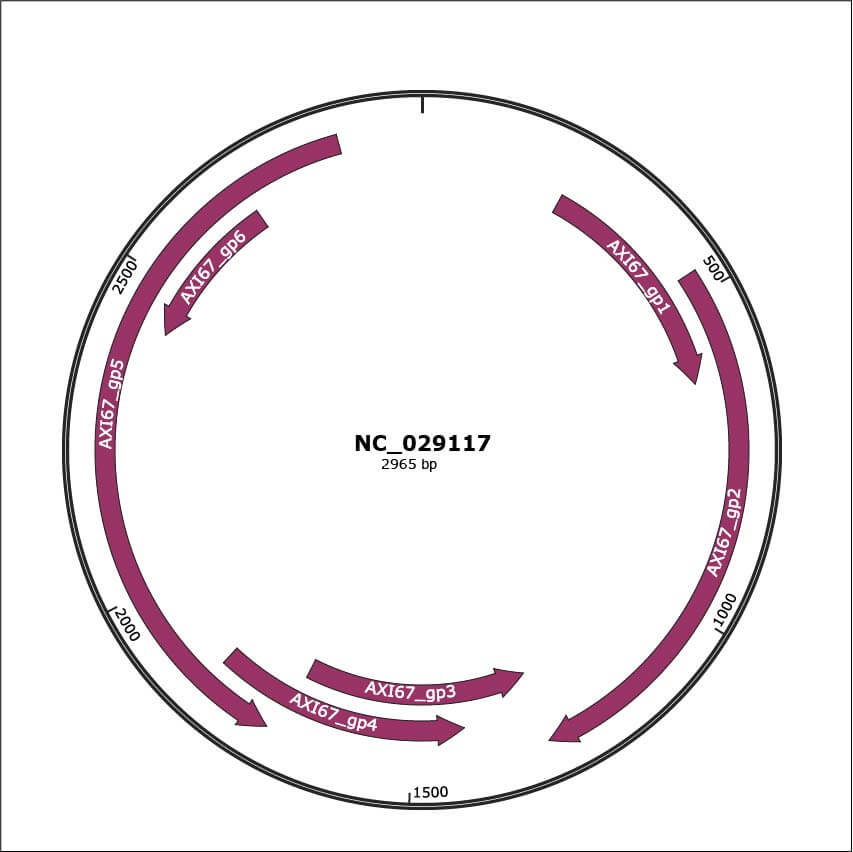
JBrowse
Genome
NC_029117
Gene Information
| NCBI Accession | YP_009226623.1 |
|---|---|
| Location | 238-630 |
| Protein Name | V2 |
| Coding Region | ATGATTTGGAGAGTAAATAAAGATGACAAACGGGTTAGGGCGTTTAGGTATAAAAAAAGAAGGTTTTACTCTTTAGCGGAGTATTTATTAGCCCCTTTGGCTACTCATCTTTGTAAGGGTCGTATATTTCCAGACGATAAGTATCTTGTCCCAGCGTATACCGACGAGGCGTATAGTTTCCTGGTGTTTCTTAAGGAAGAAACTCGTACACCGTTTCAGATATTGAAGGATGAGTGGAACGTGGAGTTTAAAGAGATCGAGGTGGAACTCTCCCGGTTACGATCTGGCCCCAAAGACGCCGGCGAAGAGGCCGGCGATAAGGAGGGCTCTCTTTCAATCCCCATCTCAGTATGTGGCGAGACGTCCTTGGAGGAGGACGTTTACGAGGACTAA |
| Protein Sequence | MIWRVNKDDKRVRAFRYKKRRFYSLAEYLLAPLATHLCKGRIFPDDKYLVPAYTDEAYSFLVFLKEETRTPFQILKDEWNVEFKEIEVELSRLRSGPKDAGEEAGDKEGSLSIPISVCGETSLEEDVYED |
| NCBI Accession | YP_009226624.1 |
|---|---|
| Location | 467-1288 |
| Protein Name | coat protein |
| Coding Region | ATGAGTGGAACGTGGAGTTTAAAGAGATCGAGGTGGAACTCTCCCGGTTACGATCTGGCCCCAAAGACGCCGGCGAAGAGGCCGGCGATAAGGAGGGCTCTCTTTCAATCCCCATCTCAGTATGTGGCGAGACGTCCTTGGAGGAGGACGTTTACGAGGACTAATAAAGGTGTGTCAAAGAAGAAATTAAAGGCTAGTGATTATCAGATCTATGAAGATCGAGTGGGTGGAGATAATGGATGGACAGTGACATCCACTGGTGATTGTACTATGCTCAATAATTACGTTAGAGGTATTGGTAGGGACCAGCGTGACTCGACATTGACTAAGACCGTTCATATGCATTTTAGCGGAGTATTAATGGCTAATGATGCATTTTGGGAGGCGCCTAATTATATGACTATGTATAGTTGGATCATTTTAGATAATGATCCTGGTGGTTCGTTTCCTAAACCTGCTGACATATTTGATATGACGGATAAGGATTTTCCGTCTATGTATGAAGTTGCAGAGAGTGTGAAGCCCAGGTTTATTGTTAAGAGGAAGACTCGACATTATCTTAGATCGTGTGGTGTTGCTTTTGGCGAGAAGCAGAATTACAAAGCTCCTACACTTGGACCGATTAAGAAACCCATTAGTATGGTGTTTCGTAATATGTGGCAGATGACTGAATGGAAGGACACTGCTGGTGGGAAGTATGAAGACCTAAAGAAGGGAGCTTTGTTGTTTGTTTGTATGTCTGATAATAAGGCTTCTCAATTTTCGTTTTCATTAAGGGGAAAGTGGAAGATGTATTTTATTAATAGAGATCGTTTTCAATAA |
| Protein Sequence | MSGTWSLKRSRWNSPGYDLAPKTPAKRPAIRRALFQSPSQYVARRPWRRTFTRTNKGVSKKKLKASDYQIYEDRVGGDNGWTVTSTGDCTMLNNYVRGIGRDQRDSTLTKTVHMHFSGVLMANDAFWEAPNYMTMYSWIILDNDPGGSFPKPADIFDMTDKDFPSMYEVAESVKPRFIVKRKTRHYLRSCGVAFGEKQNYKAPTLGPIKKPISMVFRNMWQMTEWKDTAGGKYEDLKKGALLFVCMSDNKASQFSFSLRGKWKMYFINRDRFQ |
| NCBI Accession | YP_009226625.1 |
|---|---|
| Location | 1282-1704 |
| Protein Name | C3 |
| Coding Region | ATGGCTGTGGTGAGGGATTTACGCACAGGGGAACCTATAACGCATCGTCAATCAACGATTGGGATCTACACGCATCAAACCAAGAATCCATTTTACCTCAAACTCATATCATGGGACCACCGCGAGAGCGGGTGGTTCAACATCAGAATACAACTCCGCTTCAACTACAACCTACGGAAACAACTGGGGATACACCTATGCTGGATCGAGTTTACGGCGTTGGGACGTCACCGGAGTTTGACTGGACAGCGTTTTACAACGATTTTCTTGAAGAGACTCAACCACTACCTTGATAACCTTGGGGTTATTTCTCTTAATCTAGTTATAAATGGCATTAGCCATGTATTGTTTGAAGATTTCAATTTCGTGGAAAATGTAATCCATCAAGAATATCGTGTAGCAATGAAAGAGGAGTTTTATTGA |
| Protein Sequence | MAVVRDLRTGEPITHRQSTIGIYTHQTKNPFYLKLISWDHRESGWFNIRIQLRFNYNLRKQLGIHLCWIEFTALGRHRSLTGQRFTTIFLKRLNHYLDNLGVISLNLVINGISHVLFEDFNFVENVIHQEYRVAMKEEFY |
| NCBI Accession | YP_009226626.1 |
|---|---|
| Location | 1412-1837 |
| Protein Name | C2 |
| Coding Region | ATGAAGCCCTTAAATCCTGGACGATACAAAATTCAGCCTTCACCACTATCACGGAGCCTCTCTACGATAACGAGAATATCGAAGAAGCCGAAGACGATCCACCTACCGTGTAAGTGCAAATTCACAATACATCATGGCTGTGGTGAGGGATTTACGCACAGGGGAACCTATAACGCATCGTCAATCAACGATTGGGATCTACACGCATCAAACCAAGAATCCATTTTACCTCAAACTCATATCATGGGACCACCGCGAGAGCGGGTGGTTCAACATCAGAATACAACTCCGCTTCAACTACAACCTACGGAAACAACTGGGGATACACCTATGCTGGATCGAGTTTACGGCGTTGGGACGTCACCGGAGTTTGACTGGACAGCGTTTTACAACGATTTTCTTGAAGAGACTCAACCACTACCTTGA |
| Protein Sequence | MKPLNPGRYKIQPSPLSRSLSTITRISKKPKTIHLPCKCKFTIHHGCGEGFTHRGTYNASSINDWDLHASNQESILPQTHIMGPPRERVVQHQNTTPLQLQPTETTGDTPMLDRVYGVGTSPEFDWTAFYNDFLEETQPLP |
| NCBI Accession | YP_009226627.1 |
|---|---|
| Location | 1725-2840 |
| Protein Name | Rep |
| Coding Region | ATGGGGAGGACTAACAAGCAATATCGCATCCAAGCTAAAAACATCTTTCTTACTTTTCCACACTGTACTCTCTCCAAGGACGAAGCCTTAGAGCAGCTGCAGAACCTCGCCTGTCCATCTAACAAGAAATTCATCCGTATCTCAAGAGAACTACACGAGAATGGGGAACCTCATCTCCATGTGCTTATCCAATTCGAAGGAAAAGTACAAATCTGTAACCCCCGTCACTTCGATTTACGGCATCCAAGTGCCAGTAGAAGCTTCCACCCAAATATCCAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTATATCGAAAAAGACGGAGATTACCTCGACTGGGGTCAATTTCAAATCGATGGTCGATCTGCAAGAGGAGGTCAACAGACGGTTAATGATGCATCTGCAGAAGCACTAAACGCAGCATCGGCGGAAGCGGCGTTGGCAATTATTCGTGAGAAACTGCCTCACGATTTTCTATTCAAATACCATAACCTCAAACCAAACCTCGCCGCTATATTCGCACCGCCACCTGCAGTTTACACACCACCATTTACGCACACCCAATTCAACATTCCAGAAGAAATACGGCAATGGGTGAACAACAATTTCATTTTAGAAGAAGCCTCTTCCCCTGCGGGGCCGACAAAACATAAGCGAATTCCTTCGATAGAGCGTCCTCAATCAATAATCATCGAAGGTCCATCAAGAACTGGCAAAACCCTTTGGGCTAGATCGCTAGGAACACATAACTACATCACCGGACACCTAGACTTCTCTGCGCGTGTATATCACGACGATGTGGAATACAACGTAATCGATGACGTCGATCCGCACTATCTAAAGATGAAACACTGGAAGCATCTCATTGGTGCACAAAAGGAGTGGCAGACAAACCTCAAATACGGTAAACCACGTATTATAAAAGGGGGGGTTCCCTCTATTATTTTATGCAACCCAGGAGACGGAGCTTCTTATAAAGACTTCCTAGATAAGTCAGAGAATGAAGCCCTTAAATCCTGGACGATACAAAATTCAGCCTTCACCACTATCACGGAGCCTCTCTACGATAACGAGAATATCGAAGAAGCCGAAGACGATCCACCTACCGTGTAA |
| Protein Sequence | MGRTNKQYRIQAKNIFLTFPHCTLSKDEALEQLQNLACPSNKKFIRISRELHENGEPHLHVLIQFEGKVQICNPRHFDLRHPSASRSFHPNIQGAKSSSDVKSYIEKDGDYLDWGQFQIDGRSARGGQQTVNDASAEALNAASAEAALAIIREKLPHDFLFKYHNLKPNLAAIFAPPPAVYTPPFTHTQFNIPEEIRQWVNNNFILEEASSPAGPTKHKRIPSIERPQSIIIEGPSRTGKTLWARSLGTHNYITGHLDFSARVYHDDVEYNVIDDVDPHYLKMKHWKHLIGAQKEWQTNLKYGKPRIIKGGVPSIILCNPGDGASYKDFLDKSENEALKSWTIQNSAFTTITEPLYDNENIEEAEDDPPTV |
| NCBI Accession | YP_009226628.1 |
|---|---|
| Location | 2423-2680 |
| Protein Name | C4 |
| Coding Region | ATGGGGAACCTCATCTCCATGTGCTTATCCAATTCGAAGGAAAAGTACAAATCTGTAACCCCCGTCACTTCGATTTACGGCATCCAAGTGCCAGTAGAAGCTTCCACCCAAATATCCAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTATATCGAAAAAGACGGAGATTACCTCGACTGGGGTCAATTTCAAATCGATGGTCGATCTGCAAGAGGAGGTCAACAGACGGTTAATGATGCATCTGCAGAAGCACTAA |
| Protein Sequence | MGNLISMCLSNSKEKYKSVTPVTSIYGIQVPVEASTQISRELNLAPTSSPISKKTEITSTGVNFKSMVDLQEEVNRRLMMHLQKH |
References More References in PubMed
| 1 |
Molecular diversity of turncurtoviruses in Iran. Kamali M, et al. Arch Virol. 2016 Mar;161(3):551-61. doi: 10.1007/s00705-015-2686-6. Epub 2015 Nov 26. PMID: 26611911 |
|---|---|
| 2 |
Blouin AG, et al. Mol Ecol Resour. 2016 Sep;16(5):1255-63. doi: 10.1111/1755-0998.12525. Epub 2016 Apr 4. PMID: 26990372 |
| 3 |
MACKINNON JP. Can J Microbiol. 1960 Dec;6:679-80. doi: 10.1139/m60-081. PMID: 13764931 |
| 4 |
Hasanvand V, et al. Virus Genes. 2018 Dec;54(6):840-845. doi: 10.1007/s11262-018-1604-x. Epub 2018 Oct 11. PMID: 30311179 |
| 5 |
The second face of a known player: Arabidopsis silencing suppressor AtXRN4 acts organ-specifically. Vogel F, et al. New Phytol. 2011 Jan;189(2):484-93. doi: 10.1111/j.1469-8137.2010.03482.x. Epub 2010 Oct 6. PMID: 21039560 |
| 6 |
First Report of Soybean dwarf virus (Genus Luteovirus) Infecting Faba Bean and Clover in Germany. Abraham AD, et al. Plant Dis. 2007 Aug;91(8):1059. doi: 10.1094/PDIS-91-8-1059B. PMID: 30780466 |
| 7 |
Isolation and analysis of small RNAs from virus-infected plants. Curtin SJ, et al. Methods Mol Biol. 2012;894:173-89. doi: 10.1007/978-1-61779-882-5_12. PMID: 22678580 |
| 8 |
Guo J, et al. Chin J Biotechnol. 1990;6(3):215-22. PMID: 2104212 |