Turnip curly top virus
Basic Information
| Genus | Turncurtovirus |
|---|---|
| NCBI Assembly | GCF_000887455.1 |
| Isolate | Iran |
| Release date | 2015/2/22 |
| Submitter | Briddon,R.W., Heydarnejad,J., Khosrowfar,F., Massumi,H., Martin,D.P., Varsani,A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
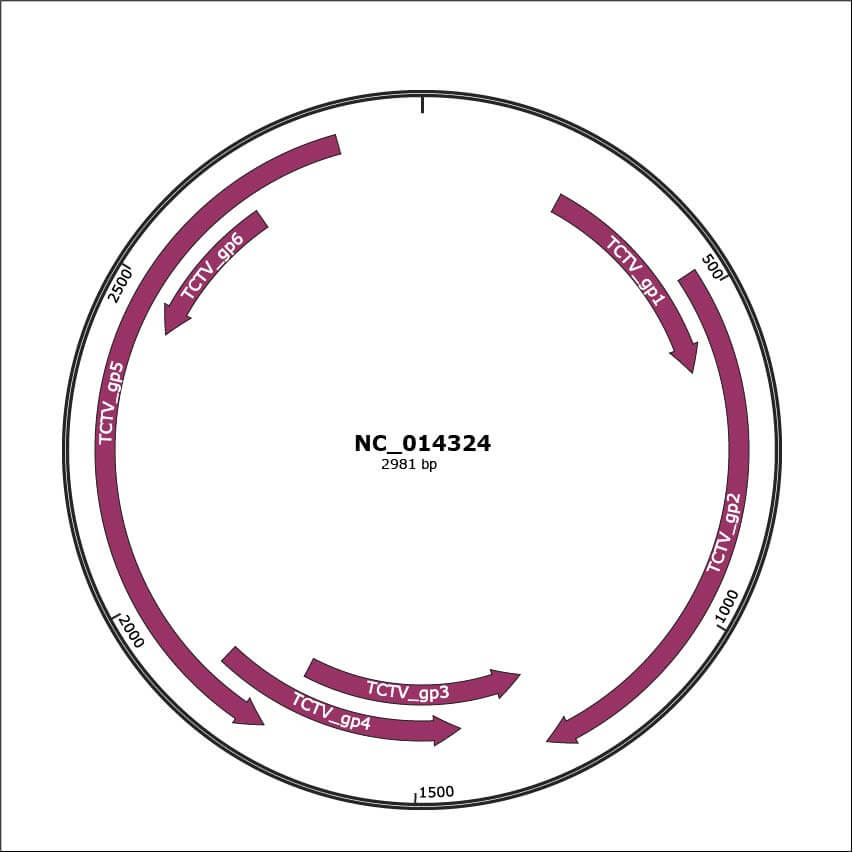
Genomic Organization
JBrowse
Genome
NC_014324
Gene Information
| NCBI Accession | YP_003778174.1 |
|---|---|
| Location | 237-614 |
| Protein Name | V2 |
| Coding Region | ATGATTTGGAGAATCGCAAAAGACGATAAACGGGTTAGGGCGTTTAGGTATAAAAAAAGAAGGTTTTACTCTTTATCGGAGTATTTATTGGCCCCTTTGGCTACACATTTACGACTCGCTCGTATTTTACCAGAGAAGTGTTGGTCCGTAGTTCCAGCTTATACCGACGAGGCGTATAGTTTTCTGTTTATGTTAAAAGAAGAAACGCGAACGCCGTTTCAAATATTGAAAGATGAGTGGAACGTGGAGTTTAAAGAGGCCGAGGTGGCACTCTCCAGGCTACGACTTAGCACCGAAGACACCGGTGAAGAGACCGGCGGTGAGGAGAGCCCTGTTCAACAATCAAGCCCAGTTCAGTCGAGTAGCTGCGAGACGTAG |
| Protein Sequence | MIWRIAKDDKRVRAFRYKKRRFYSLSEYLLAPLATHLRLARILPEKCWSVVPAYTDEAYSFLFMLKEETRTPFQILKDEWNVEFKEAEVALSRLRLSTEDTGEETGGEESPVQQSSPVQSSSCET |
| NCBI Accession | YP_003778175.1 |
|---|---|
| Location | 469-1299 |
| Protein Name | coat protein |
| Coding Region | ATGAGTGGAACGTGGAGTTTAAAGAGGCCGAGGTGGCACTCTCCAGGCTACGACTTAGCACCGAAGACACCGGTGAAGAGACCGGCGGTGAGGAGAGCCCTGTTCAACAATCAAGCCCAGTTCAGTCGAGTAGCTGCGAGACGTAGATGGTCGAAGTTTCCTGTTCGAGGTAATAAACCGTATAGGTATCGTAAGTTAAAAGCTAGTGATTATCAGATCTACAAGGATAAGATTGGTGGAGATAATGGGTGGACGGTGACATTTAGTGGGGACTGCACTATGTTGAATAATTACGTAAGAGGAATTGGTAGGGACCAGCGTGACTCGGTGATGACTAAGACCGCACATATGCATTTTAATGGGGTATTGATGGCCAATGATGCTTTCTGGGAAGCGCCTAATTATATGACGATGTATAGTTGGATTATTCTTGATAATGATCCTGGTGGTACATTTCCAAAGCCCTCTGACATATTTGATATGGAGTATAAAGAGTTTCCGTCCATGTATGAGGTCGCCGAGAGTGTTAAATCTCGGTTTATTGTTAAGAGAAAGACGGAGCATTATTTACGGTCTACCGGTGTTGCTTTTGGGGAGAAACAAAATTATAAGGCGCCTAATGTTGGTCCGGTTAAAAAGCCTATACGTATGAAGTTTCGTAATATATGGCAGCCTTCCGAGTGGAAGGATACGGCTGGAGGAAAATACGAGGATTTGAAGAAAGGGGCTTTGTTATACGTATGTATTTGTGATAACAAGGCTACTCAATTTTCGTTTAATTTGAAGGGACAGTGGACCATGTATTTCATAAATAGAGATTTAATGTATTAA |
| Protein Sequence | MSGTWSLKRPRWHSPGYDLAPKTPVKRPAVRRALFNNQAQFSRVAARRRWSKFPVRGNKPYRYRKLKASDYQIYKDKIGGDNGWTVTFSGDCTMLNNYVRGIGRDQRDSVMTKTAHMHFNGVLMANDAFWEAPNYMTMYSWIILDNDPGGTFPKPSDIFDMEYKEFPSMYEVAESVKSRFIVKRKTEHYLRSTGVAFGEKQNYKAPNVGPVKKPIRMKFRNIWQPSEWKDTAGGKYEDLKKGALLYVCICDNKATQFSFNLKGQWTMYFINRDLMY |
| NCBI Accession | YP_003778176.1 |
|---|---|
| Location | 1296-1718 |
| Protein Name | C3 |
| Coding Region | ATGAGTGTGGTGAGGGATTTACGCACAGGGGAACCCATAACTCATCGTCAATCAACGATTGGAACATACATACATCAAGTACCAAACCCGTTTCATCTCAAACTAATATCATGGGACCACCAGGAGAACGGGTTCTTCAACATCAGATTACAACTCCGATTCAACTACAACCTACGGAAACAACTGGGATTACACATGGCTTGGATCGAATTCACGGTATTGGGTCGTCACCGGAGTTTGACTGGACATCGATTTACGACGATTTTTTTGAAGAGATTACTCTTCTACCTTAATAATCTAGGGATTATATCCCTTAACCTTGTAATAAATGGTATTAGTCATGTTTTATTTAAGGATTTTAAGTTTGTCGAGTCTGTAATAAATCAAGAGTATCGTGTTGCAATGAAAGAAGAGTTTTATTAA |
| Protein Sequence | MSVVRDLRTGEPITHRQSTIGTYIHQVPNPFHLKLISWDHQENGFFNIRLQLRFNYNLRKQLGLHMAWIEFTVLGRHRSLTGHRFTTIFLKRLLFYLNNLGIISLNLVINGISHVLFKDFKFVESVINQEYRVAMKEEFY |
| NCBI Accession | YP_003778177.1 |
|---|---|
| Location | 1426-1851 |
| Protein Name | C2 |
| Coding Region | ATGAAGCCCTTAAGTCCTGGAGTTTACAAAATTCAGTCTTCACAACAATCGAGGAACCTCTCTTCAATATCACGAGTGATCAAGAAGTCGAAGACAGTACTCCTACCGTGTAAGTGCAAATTCACAATACATCATGAGTGTGGTGAGGGATTTACGCACAGGGGAACCCATAACTCATCGTCAATCAACGATTGGAACATACATACATCAAGTACCAAACCCGTTTCATCTCAAACTAATATCATGGGACCACCAGGAGAACGGGTTCTTCAACATCAGATTACAACTCCGATTCAACTACAACCTACGGAAACAACTGGGATTACACATGGCTTGGATCGAATTCACGGTATTGGGTCGTCACCGGAGTTTGACTGGACATCGATTTACGACGATTTTTTTGAAGAGATTACTCTTCTACCTTAA |
| Protein Sequence | MKPLSPGVYKIQSSQQSRNLSSISRVIKKSKTVLLPCKCKFTIHHECGEGFTHRGTHNSSSINDWNIHTSSTKPVSSQTNIMGPPGERVLQHQITTPIQLQPTETTGITHGLDRIHGIGSSPEFDWTSIYDDFFEEITLLP |
| NCBI Accession | YP_003778178.1 |
|---|---|
| Location | 1739-2854 |
| Protein Name | Rep |
| Coding Region | ATGCCAAGGACTCCGAGGCAATATCGCATTCATGCTAAAAACATTTTCCTAACATACCCTCACTGCCATCTAACTAAAGAAGACGCTCTTCTGCAACTACAAACTATACAGTGTCCTTCAACCAAGAAATTCATACGAATTTGTAGAGAAAGGCACGATAATGGGGAACCTCATCTCCATGTGCTTATCCAATTCGAAGGAAAAATCCAGCTCTATAACCCCCGTCATTTCGATTTACGAGATGGAGGTTCCGGTCGCATCTGCCACCCAAATATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATATCGAGAAGGACGGAGATTACATCGACTGGGGTGAATTTCAGATCGATGCACGATCTGCACGAGGAGGTCAACAGACGGCTAATGATGCATGTGCAGAGGCGTTAAACTCAGGTACCGCTGAAGCCGCTTTGGCTGTCATTAGGGAGAAACTCCCTAAAGATTACATCTTTCAATTCCATAACCTGAAACCAAACTTAGCGGCCATATTCAATCCTCCTCCTGTAGGATACGTCCCCAAATACAACCATACCCAATTCGTCTTAACAGATGATATTTTGGATTGGTTAGAGTCTAATTTTTTTCTGGAGGAGTCCAATTCCCCTGCGGGGCCGAGTAAATATAAGGTAATTCCATCTATCGACAGACCTAAATCAATAATCATCGAAGGTCCTTCAAGAACAGGTAAAACCCTGTGGGCAAGATCCCTTGGATCTCATAATTACATAACCGGTCATCTCGACTTCTCCACTAAAGTATACAACGACGACGTTTCTTACAACGTGATTGATGACGTGGACCCCCATTATCTAAAGATGAAGCACTGGAAGCATTTAATTGGTGCGCAAAAGGAGTGGCAGACAAACCTCAAATACGGGAAGCCACGTATTATAAAAGGGGGAATCCCTTCGATCATTTTATGCAACCCAGGAGACGGAGCCTCATATCAAAACTTCCTCGACAAACCAGAGAATGAAGCCCTTAAGTCCTGGAGTTTACAAAATTCAGTCTTCACAACAATCGAGGAACCTCTCTTCAATATCACGAGTGATCAAGAAGTCGAAGACAGTACTCCTACCGTGTAA |
| Protein Sequence | MPRTPRQYRIHAKNIFLTYPHCHLTKEDALLQLQTIQCPSTKKFIRICRERHDNGEPHLHVLIQFEGKIQLYNPRHFDLRDGGSGRICHPNIQGAKSSSDVKSYIEKDGDYIDWGEFQIDARSARGGQQTANDACAEALNSGTAEAALAVIREKLPKDYIFQFHNLKPNLAAIFNPPPVGYVPKYNHTQFVLTDDILDWLESNFFLEESNSPAGPSKYKVIPSIDRPKSIIIEGPSRTGKTLWARSLGSHNYITGHLDFSTKVYNDDVSYNVIDDVDPHYLKMKHWKHLIGAQKEWQTNLKYGKPRIIKGGIPSIILCNPGDGASYQNFLDKPENEALKSWSLQNSVFTTIEEPLFNITSDQEVEDSTPTV |
| NCBI Accession | YP_003778179.1 |
|---|---|
| Location | 2437-2694 |
| Protein Name | C4 |
| Coding Region | ATGGGGAACCTCATCTCCATGTGCTTATCCAATTCGAAGGAAAAATCCAGCTCTATAACCCCCGTCATTTCGATTTACGAGATGGAGGTTCCGGTCGCATCTGCCACCCAAATATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATATCGAGAAGGACGGAGATTACATCGACTGGGGTGAATTTCAGATCGATGCACGATCTGCACGAGGAGGTCAACAGACGGCTAATGATGCATGTGCAGAGGCGTTAA |
| Protein Sequence | MGNLISMCLSNSKEKSSSITPVISIYEMEVPVASATQIFRELNRAPTSSPISRRTEITSTGVNFRSMHDLHEEVNRRLMMHVQRR |
References More References in PubMed
| 1 |
Turnip curly top virus, a highly divergent geminivirus infecting turnip in Iran. Briddon RW, et al. Virus Res. 2010 Sep;152(1-2):169-75. doi: 10.1016/j.virusres.2010.05.016. Epub 2010 Jun 8. PMID: 20566344 |
|---|---|
| 2 |
Genetic diversity and host range studies of turnip curly top virus. Razavinejad S, et al. Virus Genes. 2013 Apr;46(2):345-53. doi: 10.1007/s11262-012-0858-y. Epub 2012 Dec 9. PMID: 23225113 |
| 3 |
Kamali M, et al. Genome Announc. 2017 Feb 23;5(8):e01674-16. doi: 10.1128/genomeA.01674-16. PMID: 28232449 |
| 4 |
Next-Generation Sequencing and Genome Editing in Plant Virology. Hadidi A, et al. Front Microbiol. 2016 Aug 26;7:1325. doi: 10.3389/fmicb.2016.01325. eCollection 2016. PMID: 27617007 |
| 5 |
Molecular diversity of turncurtoviruses in Iran. Kamali M, et al. Arch Virol. 2016 Mar;161(3):551-61. doi: 10.1007/s00705-015-2686-6. Epub 2015 Nov 26. PMID: 26611911 |
| 6 |
Varsani A, et al. Arch Virol. 2014 Aug;159(8):2193-203. doi: 10.1007/s00705-014-2050-2. Epub 2014 Mar 22. PMID: 24658781 |
| 7 |
Hasanvand V, et al. Virus Genes. 2018 Dec;54(6):840-845. doi: 10.1007/s11262-018-1604-x. Epub 2018 Oct 11. PMID: 30311179 |
| 8 |
Zarrabi S, et al. Sci Rep. 2026 Jan 20;16(1):5861. doi: 10.1038/s41598-026-36331-6. PMID: 41559270 |
| 9 |
Farzadfar S, et al. Plant Dis. 2006 Mar;90(3):252-258. doi: 10.1094/PD-90-0252. PMID: 30786545 |