Sesame curly top virus
Basic Information
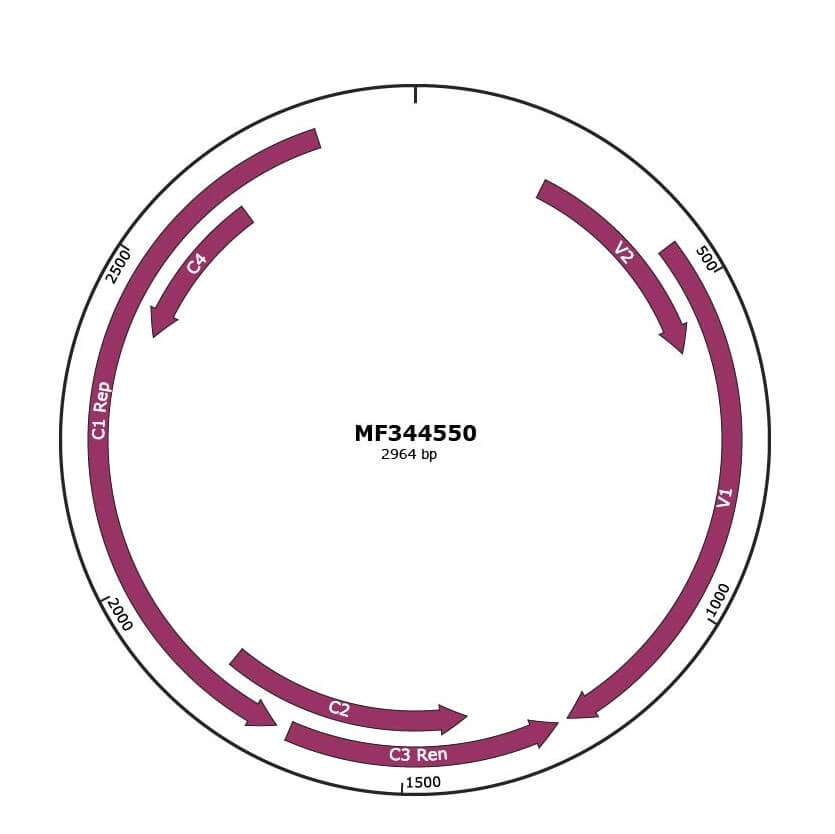
Genomic Organization
JBrowse
Genome
ACCGCTCGGCCCGAAAAAATCGCCGTACGATGTGACGTTTTTGAGCGGGATAAAATCCCGCGCTACAGTATGTTTTGTTAGCTTACTGAGGAAGGAGTTGTTTGAAATAATGAGTGCGATTCCACGTGTACATGTTTGATTGGGTTTTTAAAAATTGGTTTGGTTATAGGTTCGGCTTTAAATAATGTGGTTCGGAGTATATATATTGTATAACATACGATGGCGTATTCCGCACCACGTATTGTTGTGCCAATACGTGCGTTTTCTTACAAAAAACGTAGATTTTATTCACTCAAAGAATTCCTCTTTGCACCCCTTGAGGCTTTGCTCAAATCTGGTGATTTCCCTGTTGGAGATTACCGTGAGTTCGATCTAGATAATTTGATCGAATTTTATAGATCTGAAAACAGATCTATTAAGGAACTGTTTGAGGATGAGTACGTGGTCCGGCGTGAAGAGGGAAAGGACGCCGTATACCCCAGGGTACGCCCTGAGGAACCCCTCCCCGTACAAGAGGTCAGGCGTAAGGAGATCCCTATTTCAGACTCCGAATGCCCCTGTTGCTCGAAGGAGAAGGGTGTGGATGAAGTCTAGGAGGACTTCATCCAAGAATAAGCTCATGCCCTCTGAGATACAGGTGTATAAGGATGGTATAGGATCTGGTGTTAATGGTGCTACCATTACTAGTAATGGTTTAATTACTATGTTGAATAATTATTCTAGGGGTATAGGTCGTGACATGCGTAATTCTGTTGTCACGAAGACTGTTCATATGCATTTTGATGCCGTTTTAATGGCAAATGATAGGTTTTGGGAGGCCCCTAATTGTATGACCATGTATTCGTGGGTTATTTACGATAGGGAGCCTGGTGGTACTTTCCCCACCATCACTGACATATTTGATATGACTCACAAGGGATTTCCTATGCTGTATAAGGTCCAGGCTAATGTTAGGGATCGTTTCATTGTGAAACGAAAATTCACTTCTGTTTTGAGATCTACTGGACAGGCGTATGGTGAGAAATCCAGTTACAAAGCCCCTGTTATGCCTCCTGTGAAGAAGCCAATTAACATCAAGATGCGTAATTGCTGGATTAAATCTGATTGGAAGGATACTGCTGGTGGCAAGTATGAAGACTTGAAGAGTGGAGCCATCTTGTTTGTTTGTATTAATGATGATACTAATAGTGGCTTTGATTTTAGTCTTTTGGGAGACTGGACAATGTATTTTGTAAACCCACGTTGATGAAATACATATTCATTAATACTGCTTCATTGATATTGAGTACCACTGGTCTGAGATAGAGCTTACAAAGTTGAATTCATCAAACAGTACATGCCCAATACCCTTAACTACTAACTGAATTGAAATTACACCCACATTATCTAAATATTTATACAATCTCCTCAAAAAAGTCGTCGAAAAACGCTGTCCAGTCAAGTTCCGGTGGCTTCCCGTCATTGTGAACTCCATCCAGCATTTGTGGATGTTTAGATGCCTCCTGAGGTTGTTGTTGAATCGGATTTGCCACCGTGCTTGGAAGACTTCTCCGAACCTGTGGAAGTATATCTGCTTGAGGTAGAGTGGATTGGGCACCTCCCATGTGTAGGTTCCAATCATCGTTTCCATAGCAGTGATAGGTTCCCCTGTGCGAAAATCCGTGGGCACATTCATTATGAATTGTTACAGAGCACTTACAGGGTAGCTTGATCCTCTTCGGCTTCGATATCACTTTGCTGATTGTAGAGAGGGCCTTCGAGCCTTGTGAAGGTTGAATTTTGTAGAGTCCAGGACTTAAGTGCTTCATTTTCAGGCTTGTCTAAGAAGCTTTGATATGAAGATTCAGGTCCTGGGTTGCATATTATTATGCTAGGAATTCCGCCTTTTATAACACGAGGCTTTCCATATTTGAGGTTTGTCTGCCACTCTTTTTGTGCTCCAATTAAATGCTTCCAGTGTTTCATCTTTAGATATTGCGGTTCTATGTCATCAATGACGTTATATGAAACATCATCAGAGTAGGTTTCAAGTGAGAAGTTTAGATGGCCTGTTATGTAATTATGTTTGGGTGAAAGGGAACGTGCCCAATGAGTTTTGCCAGTTCTAGAATCACCCTCTACAATTAATGATTTTGGCCTATCTACCCCCTCTTTTAGCTTATATAAACCAGGCCCCGCAGGGGAATTAAGGTCCGGAATGAAAACAAAAAACTCTTCTAACCAATCTAAAATGTCATCATTTAAGACAAATTGATTATGGGTGTATTTGGGTGTGTATATAGTTTTTGGGGGGGTAAAAATGCATTTGAGGTTTGCAACGAGGTTGTGGTGTTGAAAAATGAATTCCTTAGGGAGTTTCTCCCTAAGGAGAGCCAAAGCGGCTTCAGCGTTACCTGTGTTTAATGCCTCCGCACATGCATCATTAGCCGTCTGTTGACCTCCTCTTGCAGATCTTCCATCGACCTGAAATTCACCCCAGTCGATGAAATCTCCGTCCTTCTCGATATAGGACTTGACATCGGTGCTGGATTTAGCTCCCTGGATATTTGGATGGAAGTCTCTGCTGGAACTAGGATTCCGTAAGTCGAAATGACGGGGGTTATAGAGCTGGACCTTGCCTTCGAATTGGATAAGCACGTGGAGATGAGGTTCCCCATTTTCATGTAGTTCTCTAGAAATTCGAATGAATTTCTTATTTGAAGGACATTCAATATTTTGGATCTGGTGGAGTGCTTCTTCTTTGGAAAGAGAACAGTGGGGATATGTGAGAAATATGTTTTTGGCTTGAATGCGATATTGCTTAGGAGCCCTCGGCATTTATAATAATTGCACTTTGGTATTGGAGTCCCCAAAACTTGCTCTTTCAATTGGAGTTTGGAGTTGTATATATACTACTTAGCGAGGCTCCTCGCCTTTTGTATGGGGTCCCACCGATGGGTCCCAAAAGGGCCGAGCGTTAATATT
Gene Information
|
NCBI Accession
|
AWV91697.1
|
|
Location
|
220-594 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGGCGTATTCCGCACCACGTATTGTTGTGCCAATACGTGCGTTTTCTTACAAAAAACGTAGATTTTATTCACTCAAAGAATTCCTCTTTGCACCCCTTGAGGCTTTGCTCAAATCTGGTGATTTCCCTGTTGGAGATTACCGTGAGTTCGATCTAGATAATTTGATCGAATTTTATAGATCTGAAAACAGATCTATTAAGGAACTGTTTGAGGATGAGTACGTGGTCCGGCGTGAAGAGGGAAAGGACGCCGTATACCCCAGGGTACGCCCTGAGGAACCCCTCCCCGTACAAGAGGTCAGGCGTAAGGAGATCCCTATTTCAGACTCCGAATGCCCCTGTTGCTCGAAGGAGAAGGGTGTGGATGAAGTCTAG |
|
Protein Sequence
|
MAYSAPRIVVPIRAFSYKKRRFYSLKEFLFAPLEALLKSGDFPVGDYREFDLDNLIEFYRSENRSIKELFEDEYVVRREEGKDAVYPRVRPEEPLPVQEVRRKEIPISDSECPCCSKEKGVDEV |
|
NCBI Accession
|
AWV91698.1
|
|
Location
|
434-1246 |
|
Protein Name
|
V1 |
|
Coding Region
|
ATGAGTACGTGGTCCGGCGTGAAGAGGGAAAGGACGCCGTATACCCCAGGGTACGCCCTGAGGAACCCCTCCCCGTACAAGAGGTCAGGCGTAAGGAGATCCCTATTTCAGACTCCGAATGCCCCTGTTGCTCGAAGGAGAAGGGTGTGGATGAAGTCTAGGAGGACTTCATCCAAGAATAAGCTCATGCCCTCTGAGATACAGGTGTATAAGGATGGTATAGGATCTGGTGTTAATGGTGCTACCATTACTAGTAATGGTTTAATTACTATGTTGAATAATTATTCTAGGGGTATAGGTCGTGACATGCGTAATTCTGTTGTCACGAAGACTGTTCATATGCATTTTGATGCCGTTTTAATGGCAAATGATAGGTTTTGGGAGGCCCCTAATTGTATGACCATGTATTCGTGGGTTATTTACGATAGGGAGCCTGGTGGTACTTTCCCCACCATCACTGACATATTTGATATGACTCACAAGGGATTTCCTATGCTGTATAAGGTCCAGGCTAATGTTAGGGATCGTTTCATTGTGAAACGAAAATTCACTTCTGTTTTGAGATCTACTGGACAGGCGTATGGTGAGAAATCCAGTTACAAAGCCCCTGTTATGCCTCCTGTGAAGAAGCCAATTAACATCAAGATGCGTAATTGCTGGATTAAATCTGATTGGAAGGATACTGCTGGTGGCAAGTATGAAGACTTGAAGAGTGGAGCCATCTTGTTTGTTTGTATTAATGATGATACTAATAGTGGCTTTGATTTTAGTCTTTTGGGAGACTGGACAATGTATTTTGTAAACCCACGTTGA |
|
Protein Sequence
|
MSTWSGVKRERTPYTPGYALRNPSPYKRSGVRRSLFQTPNAPVARRRRVWMKSRRTSSKNKLMPSEIQVYKDGIGSGVNGATITSNGLITMLNNYSRGIGRDMRNSVVTKTVHMHFDAVLMANDRFWEAPNCMTMYSWVIYDREPGGTFPTITDIFDMTHKGFPMLYKVQANVRDRFIVKRKFTSVLRSTGQAYGEKSSYKAPVMPPVKKPINIKMRNCWIKSDWKDTAGGKYEDLKSGAILFVCINDDTNSGFDFSLLGDWTMYFVNPR |
|
NCBI Accession
|
AWV91699.1
|
|
Location
|
1262-1675 |
|
Protein Name
|
C3 Ren |
|
Coding Region
|
ATGAATGTGCCCACGGATTTTCGCACAGGGGAACCTATCACTGCTATGGAAACGATGATTGGAACCTACACATGGGAGGTGCCCAATCCACTCTACCTCAAGCAGATATACTTCCACAGGTTCGGAGAAGTCTTCCAAGCACGGTGGCAAATCCGATTCAACAACAACCTCAGGAGGCATCTAAACATCCACAAATGCTGGATGGAGTTCACAATGACGGGAAGCCACCGGAACTTGACTGGACAGCGTTTTTCGACGACTTTTTTGAGGAGATTGTATAAATATTTAGATAATGTGGGTGTAATTTCAATTCAGTTAGTAGTTAAGGGTATTGGGCATGTACTGTTTGATGAATTCAACTTTGTAAGCTCTATCTCAGACCAGTGGTACTCAATATCAATGAAGCAGTATTAA |
|
Protein Sequence
|
MNVPTDFRTGEPITAMETMIGTYTWEVPNPLYLKQIYFHRFGEVFQARWQIRFNNNLRRHLNIHKCWMEFTMTGSHRNLTGQRFSTTFLRRLYKYLDNVGVISIQLVVKGIGHVLFDEFNFVSSISDQWYSISMKQY |
|
NCBI Accession
|
AWV91700.1
|
|
Location
|
1395-1808 |
|
Protein Name
|
C2 |
|
Coding Region
|
ATGAAGCACTTAAGTCCTGGACTCTACAAAATTCAACCTTCACAAGGCTCGAAGGCCCTCTCTACAATCAGCAAAGTGATATCGAAGCCGAAGAGGATCAAGCTACCCTGTAAGTGCTCTGTAACAATTCATAATGAATGTGCCCACGGATTTTCGCACAGGGGAACCTATCACTGCTATGGAAACGATGATTGGAACCTACACATGGGAGGTGCCCAATCCACTCTACCTCAAGCAGATATACTTCCACAGGTTCGGAGAAGTCTTCCAAGCACGGTGGCAAATCCGATTCAACAACAACCTCAGGAGGCATCTAAACATCCACAAATGCTGGATGGAGTTCACAATGACGGGAAGCCACCGGAACTTGACTGGACAGCGTTTTTCGACGACTTTTTTGAGGAGATTGTATAA |
|
Protein Sequence
|
MKHLSPGLYKIQPSQGSKALSTISKVISKPKRIKLPCKCSVTIHNECAHGFSHRGTYHCYGNDDWNLHMGGAQSTLPQADILPQVRRSLPSTVANPIQQQPQEASKHPQMLDGVHNDGKPPELDWTAFFDDFFEEIV |
|
NCBI Accession
|
AWV91701.1
|
|
Location
|
1696-2817 |
|
Protein Name
|
C1 Rep |
|
Coding Region
|
ATGCCGAGGGCTCCTAAGCAATATCGCATTCAAGCCAAAAACATATTTCTCACATATCCCCACTGTTCTCTTTCCAAAGAAGAAGCACTCCACCAGATCCAAAATATTGAATGTCCTTCAAATAAGAAATTCATTCGAATTTCTAGAGAACTACATGAAAATGGGGAACCTCATCTCCACGTGCTTATCCAATTCGAAGGCAAGGTCCAGCTCTATAACCCCCGTCATTTCGACTTACGGAATCCTAGTTCCAGCAGAGACTTCCATCCAAATATCCAGGGAGCTAAATCCAGCACCGATGTCAAGTCCTATATCGAGAAGGACGGAGATTTCATCGACTGGGGTGAATTTCAGGTCGATGGAAGATCTGCAAGAGGAGGTCAACAGACGGCTAATGATGCATGTGCGGAGGCATTAAACACAGGTAACGCTGAAGCCGCTTTGGCTCTCCTTAGGGAGAAACTCCCTAAGGAATTCATTTTTCAACACCACAACCTCGTTGCAAACCTCAAATGCATTTTTACCCCCCCAAAAACTATATACACACCCAAATACACCCATAATCAATTTGTCTTAAATGATGACATTTTAGATTGGTTAGAAGAGTTTTTTGTTTTCATTCCGGACCTTAATTCCCCTGCGGGGCCTGGTTTATATAAGCTAAAAGAGGGGGTAGATAGGCCAAAATCATTAATTGTAGAGGGTGATTCTAGAACTGGCAAAACTCATTGGGCACGTTCCCTTTCACCCAAACATAATTACATAACAGGCCATCTAAACTTCTCACTTGAAACCTACTCTGATGATGTTTCATATAACGTCATTGATGACATAGAACCGCAATATCTAAAGATGAAACACTGGAAGCATTTAATTGGAGCACAAAAAGAGTGGCAGACAAACCTCAAATATGGAAAGCCTCGTGTTATAAAAGGCGGAATTCCTAGCATAATAATATGCAACCCAGGACCTGAATCTTCATATCAAAGCTTCTTAGACAAGCCTGAAAATGAAGCACTTAAGTCCTGGACTCTACAAAATTCAACCTTCACAAGGCTCGAAGGCCCTCTCTACAATCAGCAAAGTGATATCGAAGCCGAAGAGGATCAAGCTACCCTGTAA |
|
Protein Sequence
|
MPRAPKQYRIQAKNIFLTYPHCSLSKEEALHQIQNIECPSNKKFIRISRELHENGEPHLHVLIQFEGKVQLYNPRHFDLRNPSSSRDFHPNIQGAKSSTDVKSYIEKDGDFIDWGEFQVDGRSARGGQQTANDACAEALNTGNAEAALALLREKLPKEFIFQHHNLVANLKCIFTPPKTIYTPKYTHNQFVLNDDILDWLEEFFVFIPDLNSPAGPGLYKLKEGVDRPKSLIVEGDSRTGKTHWARSLSPKHNYITGHLNFSLETYSDDVSYNVIDDIEPQYLKMKHWKHLIGAQKEWQTNLKYGKPRVIKGGIPSIIICNPGPESSYQSFLDKPENEALKSWTLQNSTFTRLEGPLYNQQSDIEAEEDQATL |
|
NCBI Accession
|
AWV91702.1
|
|
Location
|
2400-2663 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGAAAATGGGGAACCTCATCTCCACGTGCTTATCCAATTCGAAGGCAAGGTCCAGCTCTATAACCCCCGTCATTTCGACTTACGGAATCCTAGTTCCAGCAGAGACTTCCATCCAAATATCCAGGGAGCTAAATCCAGCACCGATGTCAAGTCCTATATCGAGAAGGACGGAGATTTCATCGACTGGGGTGAATTTCAGGTCGATGGAAGATCTGCAAGAGGAGGTCAACAGACGGCTAATGATGCATGTGCGGAGGCATTAA |
|
Protein Sequence
|
MKMGNLISTCLSNSKARSSSITPVISTYGILVPAETSIQISRELNPAPMSSPISRRTEISSTGVNFRSMEDLQEEVNRRLMMHVRRH |