Paper mulberry leaf curl virus 1
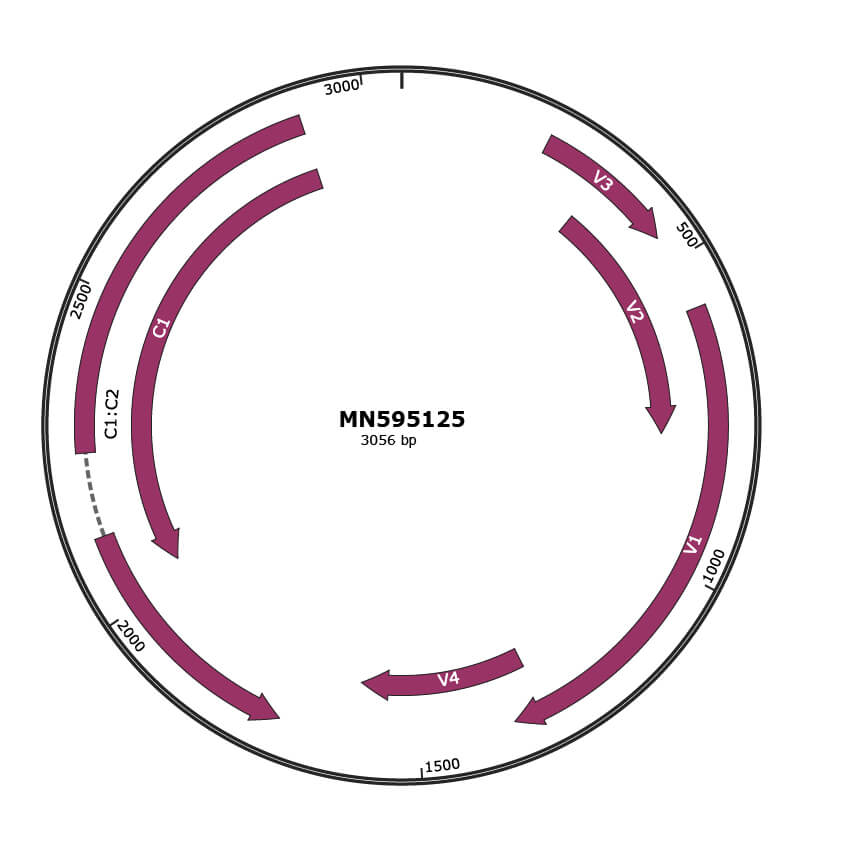
Basic Information
Genomic Organization
JBrowse
Genome
ACCCCCCGCGTCAGGAGTGGGCCCCACTTGGGGCCCACGATGAGTGACAGCTCAAAAGGCGGAGACGAGCTGACCCTAATGTGGCCGACAAAAGAAAAAGCGGGAAAAGCAAAAGATAAAAACTCGTGACCGCTTTTTCTTTTGACCGGCGTGTCGAGGAAGTTCCTTCCTCGCGAAGGTGTCGGTGACCGACACTATAAATGGAACGTCGTCGTTTCAATATTGTTGTGAGATGTCAGATATATCAGAGGTAGAGTATTGTTTGTCTAGTTCCAGTCTCACAGGTTTTTTTATTTGTATATCGATATTTTTATTATTATTATTCTGCCAGTATGGATACGTGGCAGTGCAGATTAGGCGACTTGCCAGAAACATTGACCGGCTGCCTGCACATGCTGGCATGCAAGTTCCTCCAGAACATGGAGGAGAGGGCAGAAATGCATATGGCCCTCATTAATCCCGAGTACGGGATGCCTGAGGCCAAGAGTTACTATGAACACATGATTGCTAAACAGGAGATCCGTGATTTGCTTAGGTTAATTAGGAGATTAGGGAGAGTGAAGGACAAGAGTAGTGTTAATGGCGATTACAAGGTCTATGCAGAGGAGCTCAGGAATAGGACTGCTTCCAGGTTGGGGAAGAAGACAGAGGAGACGGGGCCCACCAAGGAAGAGCCGGTACCAGCGAAGTGTACCTGGTCTGAGTGGGCCAAGTCGTTGGGGCCGACGGTCAAAAAGGACAAGGAGGACCAGATACCGCAAGGTCCCGATTGGGTGTAAGGGCCCCTGTAAAACTTTAACTTATGATAATAAAGGTGTTATTGACCACACCGGTGGTTATATTGTTCATATATCGCGTATTGACCGTGGTGAAGAGTTTGTGGACCGTACTGGGAAACGTGTTAAAATTAAAGCGATTAGAATGATGGGTAAAATATATCTGGATGGTCAGTATAAGGCCAATCCTGGGGTGACAACTGTACGTTTGTATATTATTAGAGATGCTCGTCCTGGCAGTCAACAGCTTGCTTTTGATGCATTTATGGACATGAAAGATAAAGAACCCACAACGGCAATGATAAAAACAGATTACAGAGACCGTTTGAAAATATTAAAATATATAGATTTGGAAGTGGCAGGTGGCAAGGATTTTAGGGTGGATGAGCAGACTTTTGAATTATTTATGGATGGATTAAATCATGAAATTGTTTATAATCACAATGATCAAGGCACACTGGACAATATACTGAGTGGATCTCTTCATATTTATCAGACTTGTAGTAATCCTGATATGAAAGTTAATGTTAATGCGACTGTTCGTTTGTATATGTTTGATTCTCTACAGAATTGACGGTCAAGGAGACTGGGTAAAGGTATTCAAGGTGGACCCACATATTCACCCCCACACAGTCCCCCCCCTCCTGATAAGAAATCCGATACCAGTGGCCCAAGTGGTCCCCAGTCAGAACCGTACACACCAGAACAGAAGAAAAAGGTTAAAGGAGATGACCGAGAAGATAGATCAAGTCAACAATCATATACATCAGACTATTCGACATCTGGATCAACTAATAGAAGATCACCGTTTGAAGACCCAGAGTTAATAAAAATAAGAAATGAAATAATGGGGGATGCAGGATTTACTGTAAAGAATGTAGAATATTGGACACCGGATGTAAAAAAGAAGACAAAAAAGACCGTGTTGTAAAATATGACTTGTATTAATAAAATTTTTCATTTTCATATAAATAATATTCGATTACATTTGAATGCCACCAATCTTTCAGTTGGGGTGACATGTAGTGGTTCCAGTCCATATCTGGGTTAACTAAGATAATACATGGTAAACCACCTTTAACAATCCTATCTTTACCGTACTTAACATTAACAATAAAATCAGACTGCCCTCCCACAAGTGATTTTAGAGTTTCAGTCTTAATAGTCTTATAACTAATATCGTCTATAACATTATATAAAGCGAACTGATCATAAAAACTAAAACTTAATTTATTCATAAAATAATTATGCCGTCCTAGGCTTCTGGCCCATTGGGTCTTCCCTGTTCTGGACGGGCCACAGATGTAGAGGGACTGTCTCCTCCTGCCCTGCTGGTCTGGTTCCTGAAAGAATTTGATTCTAAGTCAGAAGGGACCCTATCTAGAAAAAACGACCCTCTGATGAGCGAGTCGTCGTCGTACACTTGTGGTGCACAGTCATTACACAGTACGTAGTTGGTCGTCCATCTGCTTACCAGTAGTACATTATCTGCGGCCCACTGTCTAACGGTGTCTGGAAGCCCAGGGAAATCGTGCCATCTGGGTGTGTACAGATCAGGTTGGGCTTGGAAATGGGCCTCGGCAAAGGCAGAGACTGCTGGCCATCTGAGGACGAAGTCCTGAGGTCTGTCAGCCCTGACTCTGGAGAGGAAGGTGTCCTTGTCGTTGGACTCAGCAAGAATTCTGGCCCAAATAGTGTTTGCCTTAACTGTTGTATCAGGGGATGATCGTTTGTCATTAAATTCCCCTGACTCGACAAAATTGCCGTCCTTTCTGATGTAGTCGTAGGAGGCCTTGGGGCTGATGAGTTTCTGAATATTTGGGTGATACGTCTTCCGTACCCCCTCCTGCACAGAGAAATCAAAAAAATTATGCCGTTTAATTGAGACCCTTTTGTTACACTGAAACATGGCATGCAGATGAGGCGAACCATCTGCATGTTTTTCAGATGCTACCAGAATATAATTAGGTGAAAAAGTGTTCAGGATATTGAGAAGATGGGTTAGAATTAGGTCCGGGGTGACCGGACATTTTGGGTAAGTGAGAAAGCCATTTTTGGCTTGGAAACGGAATTGGGCCGACCTTGAAGATTCGGCCCGGTCAGATGTGTTTGGTACACGTGGCATTTTTGGCTCCTGTCCGTACTTTGCAAAACTGGCTGATTCTTATGGAGTCAAGAGCCCTGAAGAGTCACGAAGAGAAAGGGAGTGTTTGTGAAGGAGTAGAGGGCTGATGGGGCTTCGCGTTGAGGAGCCAGAGCTGACGCGGGGGTATTAATATT
Gene Information
|
NCBI Accession
|
QJX74412.1
|
|
Location
|
233-457 |
|
Protein Name
|
V3 |
|
Coding Region
|
ATGTCAGATATATCAGAGGTAGAGTATTGTTTGTCTAGTTCCAGTCTCACAGGTTTTTTTATTTGTATATCGATATTTTTATTATTATTATTCTGCCAGTATGGATACGTGGCAGTGCAGATTAGGCGACTTGCCAGAAACATTGACCGGCTGCCTGCACATGCTGGCATGCAAGTTCCTCCAGAACATGGAGGAGAGGGCAGAAATGCATATGGCCCTCATTAA |
|
Protein Sequence
|
MSDISEVEYCLSSSSLTGFFICISIFLLLLFCQYGYVAVQIRRLARNIDRLPAHAGMQVPPEHGGEGRNAYGPH |
|
NCBI Accession
|
QJX74411.1
|
|
Location
|
333-779 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGGATACGTGGCAGTGCAGATTAGGCGACTTGCCAGAAACATTGACCGGCTGCCTGCACATGCTGGCATGCAAGTTCCTCCAGAACATGGAGGAGAGGGCAGAAATGCATATGGCCCTCATTAATCCCGAGTACGGGATGCCTGAGGCCAAGAGTTACTATGAACACATGATTGCTAAACAGGAGATCCGTGATTTGCTTAGGTTAATTAGGAGATTAGGGAGAGTGAAGGACAAGAGTAGTGTTAATGGCGATTACAAGGTCTATGCAGAGGAGCTCAGGAATAGGACTGCTTCCAGGTTGGGGAAGAAGACAGAGGAGACGGGGCCCACCAAGGAAGAGCCGGTACCAGCGAAGTGTACCTGGTCTGAGTGGGCCAAGTCGTTGGGGCCGACGGTCAAAAAGGACAAGGAGGACCAGATACCGCAAGGTCCCGATTGGGTGTAA |
|
Protein Sequence
|
MDTWQCRLGDLPETLTGCLHMLACKFLQNMEERAEMHMALINPEYGMPEAKSYYEHMIAKQEIRDLLRLIRRLGRVKDKSSVNGDYKVYAEELRNRTASRLGKKTEETGPTKEEPVPAKCTWSEWAKSLGPTVKKDKEDQIPQGPDWV |
|
NCBI Accession
|
QJX74410.1
|
|
Location
|
580-1350 |
|
Protein Name
|
V1 |
|
Coding Region
|
ATGGCGATTACAAGGTCTATGCAGAGGAGCTCAGGAATAGGACTGCTTCCAGGTTGGGGAAGAAGACAGAGGAGACGGGGCCCACCAAGGAAGAGCCGGTACCAGCGAAGTGTACCTGGTCTGAGTGGGCCAAGTCGTTGGGGCCGACGGTCAAAAAGGACAAGGAGGACCAGATACCGCAAGGTCCCGATTGGGTGTAAGGGCCCCTGTAAAACTTTAACTTATGATAATAAAGGTGTTATTGACCACACCGGTGGTTATATTGTTCATATATCGCGTATTGACCGTGGTGAAGAGTTTGTGGACCGTACTGGGAAACGTGTTAAAATTAAAGCGATTAGAATGATGGGTAAAATATATCTGGATGGTCAGTATAAGGCCAATCCTGGGGTGACAACTGTACGTTTGTATATTATTAGAGATGCTCGTCCTGGCAGTCAACAGCTTGCTTTTGATGCATTTATGGACATGAAAGATAAAGAACCCACAACGGCAATGATAAAAACAGATTACAGAGACCGTTTGAAAATATTAAAATATATAGATTTGGAAGTGGCAGGTGGCAAGGATTTTAGGGTGGATGAGCAGACTTTTGAATTATTTATGGATGGATTAAATCATGAAATTGTTTATAATCACAATGATCAAGGCACACTGGACAATATACTGAGTGGATCTCTTCATATTTATCAGACTTGTAGTAATCCTGATATGAAAGTTAATGTTAATGCGACTGTTCGTTTGTATATGTTTGATTCTCTACAGAATTGA |
|
Protein Sequence
|
MAITRSMQRSSGIGLLPGWGRRQRRRGPPRKSRYQRSVPGLSGPSRWGRRSKRTRRTRYRKVPIGCKGPCKTLTYDNKGVIDHTGGYIVHISRIDRGEEFVDRTGKRVKIKAIRMMGKIYLDGQYKANPGVTTVRLYIIRDARPGSQQLAFDAFMDMKDKEPTTAMIKTDYRDRLKILKYIDLEVAGGKDFRVDEQTFELFMDGLNHEIVYNHNDQGTLDNILSGSLHIYQTCSNPDMKVNVNATVRLYMFDSLQN |
|
NCBI Accession
|
QJX74413.1
|
|
Location
|
1301-1603 |
|
Protein Name
|
V4 |
|
Coding Region
|
ATGTTAATGCGACTGTTCGTTTGTATATGTTTGATTCTCTACAGAATTGACGGTCAAGGAGACTGGGTAAAGGTATTCAAGGTGGACCCACATATTCACCCCCACACAGTCCCCCCCCTCCTGATAAGAAATCCGATACCAGTGGCCCAAGTGGTCCCCAGTCAGAACCGTACACACCAGAACAGAAGAAAAAGGTTAAAGGAGATGACCGAGAAGATAGATCAAGTCAACAATCATATACATCAGACTATTCGACATCTGGATCAACTAATAGAAGATCACCGTTTGAAGACCCAGAGTTAA |
|
Protein Sequence
|
MLMRLFVCICLILYRIDGQGDWVKVFKVDPHIHPHTVPPLLIRNPIPVAQVVPSQNRTHQNRRKRLKEMTEKIDQVNNHIHQTIRHLDQLIEDHRLKTQS |
|
NCBI Accession
|
QJX74415.1
|
|
Location
|
NA |
|
Protein Name
|
C1:C2 |
|
Coding Region
|
ATGCCACGTGTACCAAACACATCTGACCGGGCCGAATCTTCAAGGTCGGCCCAATTCCGTTTCCAAGCCAAAAATGGCTTTCTCACTTACCCAAAATGTCCGGTCACCCCGGACCTAATTCTAACCCATCTTCTCAATATCCTGAACACTTTTTCACCTAATTATATTCTGGTAGCATCTGAAAAACATGCAGATGGTTCGCCTCATCTGCATGCCATGTTTCAGTGTAACAAAAGGGTCTCAATTAAACGGCATAATTTTTTTGATTTCTCTGTGCAGGAGGGGGTACGGAAGACGTATCACCCAAATATTCAGAAACTCATCAGCCCCAAGGCCTCCTACGACTACATCAGAAAGGACGGCAATTTTGTCGAGTCAGGGGAATTTAATGACAAACGATCATCCCCTGATACAACAGTTAAGGCAAACACTATTTGGGCCAGAATTCTTGCTGAGTCCAACGACAAGGACACCTTCCTCTCCAGAGTCAGGGCTGACAGACCTCAGGACTTCGTCCTCAGATGGCCAGCAGTCTCTGCCTTTGCCGAGGCCCATTTCCAAGCCCAACCTGATCTGTACACACCCAGATGGCACGATTTCCCTGGGCTTCCAGACACCGTTAGACAGTGGGCCGCAGATAATGTACTACTGGAACCAGACCAGCAGGGCAGGAGGAGACAGTCCCTCTACATCTGTGGCCCGTCCAGAACAGGGAAGACCCAATGGGCCAGAAGCCTAGGACGGCATAATTATTTTATGAATAAATTAAGTTTTAGTTTTTATGATCAGTTCGCTTTATATAATGTTATAGACGATATTAGTTATAAGACTATTAAGACTGAAACTCTAAAATCACTTGTGGGAGGGCAGTCTGATTTTATTGTTAATGTTAAGTACGGTAAAGATAGGATTGTTAAAGGTGGTTTACCATGTATTATCTTAGTTAACCCAGATATGGACTGGAACCACTACATGTCACCCCAACTGAAAGATTGGTGGCATTCAAATGTAATCGAATATTATTTATATGAAAATGAAAAATTTTATTAA |
|
Protein Sequence
|
MPRVPNTSDRAESSRSAQFRFQAKNGFLTYPKCPVTPDLILTHLLNILNTFSPNYILVASEKHADGSPHLHAMFQCNKRVSIKRHNFFDFSVQEGVRKTYHPNIQKLISPKASYDYIRKDGNFVESGEFNDKRSSPDTTVKANTIWARILAESNDKDTFLSRVRADRPQDFVLRWPAVSAFAEAHFQAQPDLYTPRWHDFPGLPDTVRQWAADNVLLEPDQQGRRRQSLYICGPSRTGKTQWARSLGRHNYFMNKLSFSFYDQFALYNVIDDISYKTIKTETLKSLVGGQSDFIVNVKYGKDRIVKGGLPCIILVNPDMDWNHYMSPQLKDWWHSNVIEYYLYENEKFY |
|
NCBI Accession
|
QJX74414.1
|
|
Location
|
2032-2901 |
|
Protein Name
|
C1 |
|
Coding Region
|
ATGCCACGTGTACCAAACACATCTGACCGGGCCGAATCTTCAAGGTCGGCCCAATTCCGTTTCCAAGCCAAAAATGGCTTTCTCACTTACCCAAAATGTCCGGTCACCCCGGACCTAATTCTAACCCATCTTCTCAATATCCTGAACACTTTTTCACCTAATTATATTCTGGTAGCATCTGAAAAACATGCAGATGGTTCGCCTCATCTGCATGCCATGTTTCAGTGTAACAAAAGGGTCTCAATTAAACGGCATAATTTTTTTGATTTCTCTGTGCAGGAGGGGGTACGGAAGACGTATCACCCAAATATTCAGAAACTCATCAGCCCCAAGGCCTCCTACGACTACATCAGAAAGGACGGCAATTTTGTCGAGTCAGGGGAATTTAATGACAAACGATCATCCCCTGATACAACAGTTAAGGCAAACACTATTTGGGCCAGAATTCTTGCTGAGTCCAACGACAAGGACACCTTCCTCTCCAGAGTCAGGGCTGACAGACCTCAGGACTTCGTCCTCAGATGGCCAGCAGTCTCTGCCTTTGCCGAGGCCCATTTCCAAGCCCAACCTGATCTGTACACACCCAGATGGCACGATTTCCCTGGGCTTCCAGACACCGTTAGACAGTGGGCCGCAGATAATGTACTACTGGTAAGCAGATGGACGACCAACTACGTACTGTGTAATGACTGTGCACCACAAGTGTACGACGACGACTCGCTCATCAGAGGGTCGTTTTTTCTAGATAGGGTCCCTTCTGACTTAGAATCAAATTCTTTCAGGAACCAGACCAGCAGGGCAGGAGGAGACAGTCCCTCTACATCTGTGGCCCGTCCAGAACAGGGAAGACCCAATGGGCCAGAAGCCTAG |
|
Protein Sequence
|
MPRVPNTSDRAESSRSAQFRFQAKNGFLTYPKCPVTPDLILTHLLNILNTFSPNYILVASEKHADGSPHLHAMFQCNKRVSIKRHNFFDFSVQEGVRKTYHPNIQKLISPKASYDYIRKDGNFVESGEFNDKRSSPDTTVKANTIWARILAESNDKDTFLSRVRADRPQDFVLRWPAVSAFAEAHFQAQPDLYTPRWHDFPGLPDTVRQWAADNVLLVSRWTTNYVLCNDCAPQVYDDDSLIRGSFFLDRVPSDLESNSFRNQTSRAGGDSPSTSVARPEQGRPNGPEA |