Sugarcane streak Reunion virus
Basic Information
| Genus | Mastrevirus |
|---|---|
| NCBI Assembly | GCF_000843205.1 |
| Release date | 2015/2/12 |
| Submitter | Bigarre,L., Salah,M., Granier,M., Frutos,R., Thouvenel,J., Peterschmitt,M., Thouvenel,J.C. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
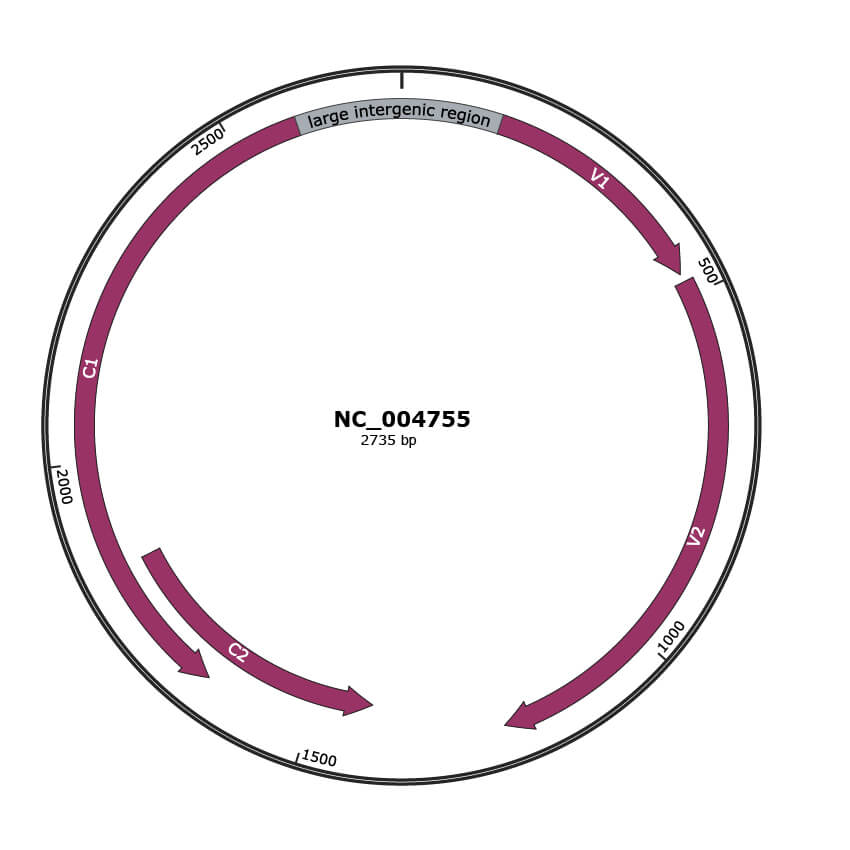
JBrowse
Genome
NC_004755
Gene Information
| NCBI Accession | NP_840050.1 |
|---|---|
| Location | 139-468 |
| Gene Name | V1 |
| Protein Name | putative movement protein V1 |
| Coding Region | ATGGATAGCCTTGAAGGAGCGTCCCCTGCTTTGCCCGCAGTAGCTTTGCCTCGTGTCCCCCGGGCAGCTCCGTCCGCTCCTGCGTTGCCGTGGAGCCGCGTTGGTGAAATAGCTATCTTTACCTTTGTTGCAGTGCTAGCGCTTTACTTACTTTGGGTTTGGGTGCTGAGAGATCTTGTCTTCGTTTTGAAGGCTCGACGAGGCGGATCTACGGAGGAGCTGCATTTTGGGCCCAGGGAGCGGGAGTCTGTCGCTTCTGCCGACAGTTCTCGTCCAGTCGCTGCTCCGTCGGCCCCTCCTGTAAGTGACGCTAGGCCTTTCTCGGTCTAG |
| Protein Sequence | MDSLEGASPALPAVALPRVPRAAPSAPALPWSRVGEIAIFTFVAVLALYLLWVWVLRDLVFVLKARRGGSTEELHFGPRERESVASADSSRPVAAPSAPPVSDARPFSV |
| NCBI Accession | NP_840051.1 |
|---|---|
| Location | 480-1223 |
| Gene Name | V2 |
| Protein Name | coat protein |
| Coding Region | ATGCCTACTACCGCCGGGAAACGGAAGAGGACAGATGATGCCGCTTGGAGTAAGAGAGCTCGACCGAAGGCCGGGCGTACATCTGCCGCCCGGCCTGGTACTGCCGTTCGTCGGGTCCGTCCAGCTCTGCAGATCCAGACGCTCCAGGCGGCTGGCACGTCAATGATCACCGTTCCGTCGGGTGGTGTTTGTGATATCCTCGGGTCCTATTCACGAGGCTCTGACGAGTGCAATCGCCACACCAACGAGACTGTCACCTACAAGGTAGCTCTGGACTACCATTTCGTTGCTAGTGCAGCAGCCTGCAAGTATTCCAGTATTGGCACTGGCGTGGTGTGGTTGGTGTACGACGCACAGCCTCAGGGAAATTGTCCTACGGTGAAAGACATCTTCCCGCATCCTGACACTTTGAGCGCCTTCCCGTATACCTGGAAGGTCGGCCGAGAGGTGTGCCATCGGTTCGTGGTGAAGCGGCGGTGGACTTTCACGATGGAAGTCAATGGACGGATTGGATCTGATATGCCTCCTGCGACTGCCGTGTGGCCCCCGTGCCGGAAGAACATATACTTCCACAAGTTTGTCACCGGACTCGGCGTAAAAACGGAGTGGAAGAATACAACCGGCGGTGAAGTCGGAGACATTAAGAAGGGTGCCCTCTATATTGTAATTGCCCCAGGCAATGGACTCGATTTTACGGTGCATGGAAATGCCCGTTTGTACTTTAAGAGCGTTGGTAATCAGTGA |
| Protein Sequence | MPTTAGKRKRTDDAAWSKRARPKAGRTSAARPGTAVRRVRPALQIQTLQAAGTSMITVPSGGVCDILGSYSRGSDECNRHTNETVTYKVALDYHFVASAAACKYSSIGTGVVWLVYDAQPQGNCPTVKDIFPHPDTLSAFPYTWKVGREVCHRFVVKRRWTFTMEVNGRIGSDMPPATAVWPPCRKNIYFHKFVTGLGVKTEWKNTTGGEVGDIKKGALYIVIAPGNGLDFTVHGNARLYFKSVGNQ |
| NCBI Accession | NP_840052.1 |
|---|---|
| Location | 1413->1847 |
| Gene Name | C2 |
| Protein Name | RepB |
| Coding Region | AACAATACAGGTACAAGAAAGCTTAGCCTCTACATCCTCGGCCCAACAAGAACTGGAAAATCTACTTGGGCCCGTAGCCTGGGAAGACATAATTACTGGCAAAACAACGTCGACTGGTCCTGCTACGACGAGGACGCAGTCTACAACGTCATTGACGACATCCCCTTCAAGTTCTGTCCTTGCTGGAAGCAACTGATTGGTTGCCAAGAGAACTACGTCGTTAATCCCAAGTATGGGAAGAAACGGAGAGTAGCCAAGAAAAGCATCTCCACAATTGTTCTTGCCAACGAGGATGAAGACTGGATGAAGGTAATGAGTCCAGGGCAGCTGGACTACTTTCATCAGAACTGCGTCGTCTACATAATGGAAGAAGGCGAGCGCTTCTTCGGCGGGCCCGCGGTGTCAGCTACAGCCCATCCCCCTATCGGGGTCTGA |
| Protein Sequence | NNTGTRKLSLYILGPTRTGKSTWARSLGRHNYWQNNVDWSCYDEDAVYNVIDDIPFKFCPCWKQLIGCQENYVVNPKYGKKRRVAKKSISTIVLANEDEDWMKVMSPGQLDYFHQNCVVYIMEEGERFFGGPAVSATAHPPIGV |
| NCBI Accession | NP_840053.1 |
|---|---|
| Location | 1652-2590 |
| Gene Name | C1 |
| Protein Name | RepA |
| Coding Region | ATGCCTTCACAGGAGGACTCCACCGTAGCCTCCAGGCCATTCAAGCATAGGAATGCCAACACCTTCCTCACTTACTCTCGCTGCAGACTGGACCCAGAGGCAGTGGGTCTGATACTATGGCAGCTCATTAGTCACTGGAGTCCGGCGTACATTCTAGTGAGCAGGGAAGCACACGCAGATGGAGAATGGCACCTCCATGCCTTAGTCCAGAGCGTCAGGCCTGTACAAACGACGAACCAAGGGTTCTTCGACATTGAGAGTTTCCACCCTAACATTCAGAGTGCAAAGAGTGCCAACAAAGTCAGGGAATACATACTGAAAAATCCAATCGCTAAATGGGAGAAAGGTACATTTATTCCACGCAAACAATGCTTTGTATCCTCTTCCTCTGAGAGCAAGAATTCCAAACCCTCCAAGGATGATATCGTTAGAGATATCATCGAGCACTCCACCTCTAAGGAAGAGTACCTTTCCATGCTTCAGAAGGCATTACCATACGACTGGGCTACGAAACTGCAATACTTTGAATACTCAGCTTCTAAGCTATTCCCAGATACTGTGGAAGAGTACACCAGTCCTCATCCTACTACCACGCCACTTCTGAGGGACCCAACCACCATTGACAACTGGGTGCAACCCAACCTGTTTCAGGTTAGTCCTGAAGCATACATGCTCTGTAACCCACATTGCTTAAGCCTGGAAGAGGCATCCTCTGACCTAGAATGGATGTCTTCTACATCCAGAACAATACAGGTACAAGAAAGCTTAGCCTCTACATCCTCGGCCCAACAAGAACTGGAAAATCTACTTGGGCCCGTAGCCTGGGAAGACATAATTACTGGCAAAACAACGTCGACTGGTCCTGCTACGACGAGGACGCAGTCTACAACGTCATTGACGACATCCCCTTCAAGTTCTGTCCTTGCTGGAAGCAACTGA |
| Protein Sequence | MPSQEDSTVASRPFKHRNANTFLTYSRCRLDPEAVGLILWQLISHWSPAYILVSREAHADGEWHLHALVQSVRPVQTTNQGFFDIESFHPNIQSAKSANKVREYILKNPIAKWEKGTFIPRKQCFVSSSSESKNSKPSKDDIVRDIIEHSTSKEEYLSMLQKALPYDWATKLQYFEYSASKLFPDTVEEYTSPHPTTTPLLRDPTTIDNWVQPNLFQVSPEAYMLCNPHCLSLEEASSDLEWMSSTSRTIQVQESLASTSSAQQELENLLGPVAWEDIITGKTTSTGPATTRTQSTTSLTTSPSSSVLAGSN |
References More References in PubMed
| 1 |
Shepherd DN, et al. Arch Virol. 2008;153(3):605-9. doi: 10.1007/s00705-007-0016-3. Epub 2008 Jan 4. PMID: 18175043 |
|---|---|
| 2 |
First Report of Maize streak virus Field Infection of Sugarcane in South Africa. van Antwerpen T, et al. Plant Dis. 2008 Jun;92(6):982. doi: 10.1094/PDIS-92-6-0982A. PMID: 30769738 |
| 3 |
Boukari W, et al. Virol J. 2017 Jul 28;14(1):146. doi: 10.1186/s12985-017-0810-9. PMID: 28754134 |
| 4 |
Nucleotide sequence evidence for three distinct sugarcane streak mastreviruses. Bigarré L, et al. Arch Virol. 1999;144(12):2331-44. doi: 10.1007/s007050050647. PMID: 10664387 |
| 5 |
Oluwafemi S, et al. Arch Virol. 2014 Oct;159(10):2765-70. doi: 10.1007/s00705-014-2090-7. Epub 2014 May 6. PMID: 24796552 |
| 6 |
Kraberger S, et al. Virus Res. 2017 Jun 15;238:171-178. doi: 10.1016/j.virusres.2017.07.001. Epub 2017 Jul 4. PMID: 28687345 |
| 7 |
Experimental evidence indicating that mastreviruses probably did not co-diverge with their hosts. Harkins GW, et al. Virol J. 2009 Jul 16;6:104. doi: 10.1186/1743-422X-6-104. PMID: 19607673 |