Chilli leaf curl Gonda virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004787215.1 |
| Isolate |
India: Gonda |
| Release date |
2021/6/1 |
| Submitter |
Khan,Z.A., Khan,J.A. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
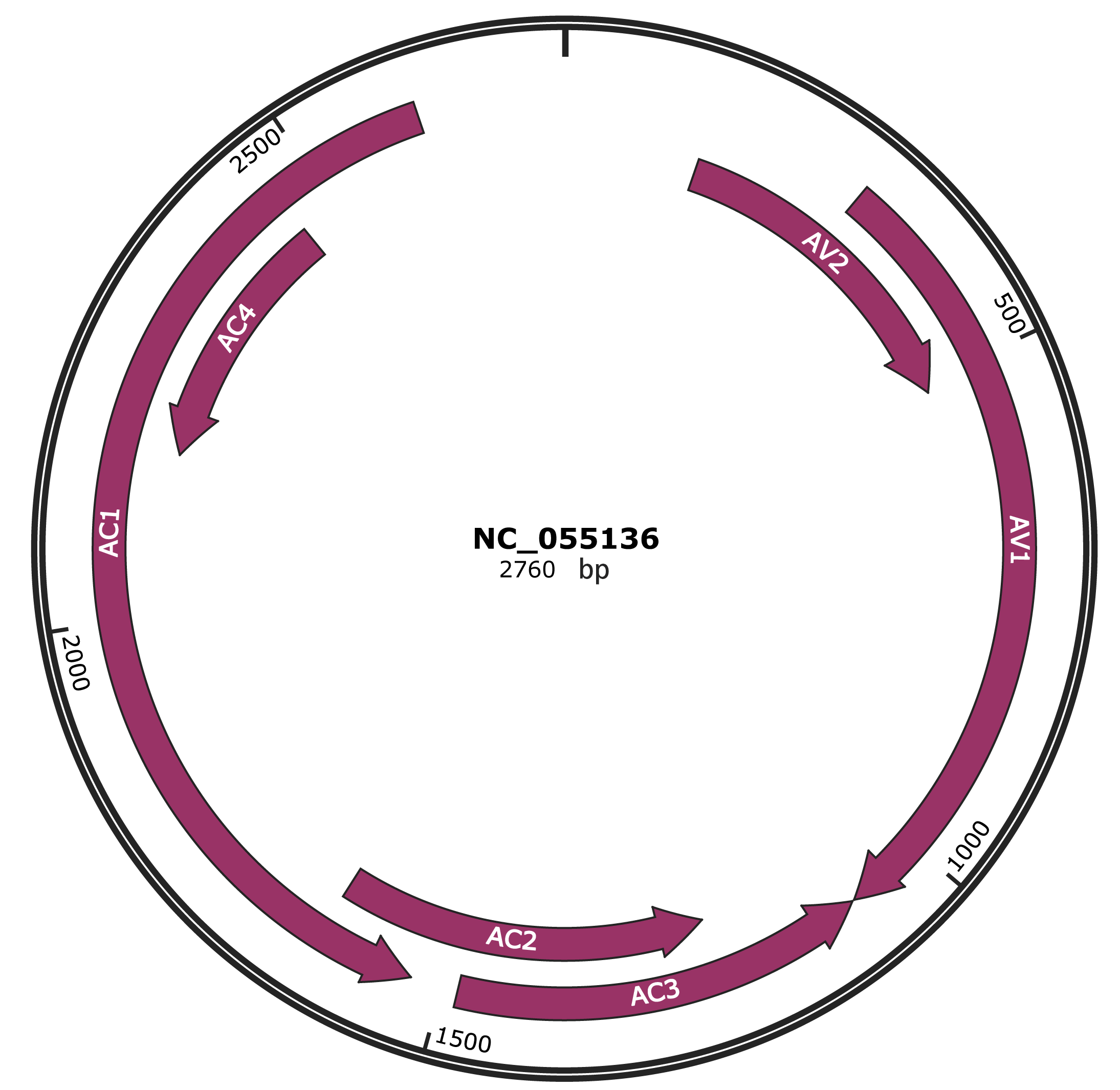
JBrowse
Genome
ACCGGATGGCCCCGATTTTTTTTCATGTGGGCCCCACCACGCACGTGTTGACAAGGACAATTGGACCAATTAGAAACGCCGCTCAAAGCTAAATTGTGTGGTGGTCCCCTATATAAACTCGGGCTCCAAGTACCGCACACATACCAATGCGGGATCCGTTACTTAACCACTTACCCGAAACCGTTCACGGTCTTACGTGTCTGCTACCCGTTTTATATCTTTATACCGTAGAAATTACGCTTTCTCCAGACACTCTAAAATACGATTTAATCCGGGATTTGATATCTGTCATTAGGGCTAGAAAATATGTGGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCCTCGAAGGTAAACCGCAGTTTCAACTTTGTCAGCCCATATACCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAAAGCATGGGCCAACAGGCCCATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGCCCAGATGTTCCGAGGGGCTGTGAAGGCCCGTGTAAGGTCCAGTCGTTTGAGTCCAGGCATGATATCCAGCACATTGGTAAAGTCATGTGTGTTAGTGATGTTACTCGTGGTACTGGTCTGACCCACAGAGTTGGTAAAAGGTTTTGTGTAAAATCTGTCTATGTTCTGGGCAAGATTTGGATGGATGAGAATATAAAGACTAAGAATCATACGAATAGTGTTATGTTTTTTCTTGTTAGGGATCGTAGGCCCGTTGATAAGCCCCAAGATTTTGGTGAGGTTTTTAACATGTTTGACAATGAGCCCAGTACGGCAACTGTCAAGAATGTGCATCGTGACAGGTACCAGGTTCTGAGGAAGTGGCAGGCAACCGTTACAGGTGGTCAATACGCATCGAAGGAGCAAGCTCTCGTGAAGAAGTTTATTAGAGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATAGTGAGAATGCATTGATGTTGTATATGGCGTGTGCCCATGCCTCGAACCCTGTGTATGCTACGTTGAATATACCTATCTATTATTCCGAATCTGGAACGACCTGAAATTAATAAAGATTTAATTTTATTATGCTTGAAGTTTGCACATGAATTGCAGGTGCTATTACATTCCATAAAACATGGTCGACAGCTGTAATTACAGCGTTGATACTAATTACAGCGAAGTAAGTTAAAAACAGCAACACATGTGTCCTAAATACCCTTAAGAAAAGACCAGTCGGAGGGTGTAAGGTCGTCCAGATTCGGAAGGTGAGAAAACATTTGTGTATCCCCAACGCTTTCCTCAGGTTGTGATTGAACCGTACTTGGACTGTTATGATGTCGTGGTTCCTCATGAATGGCCTGTTGTGGTGCTCGGTTATCTTGAAATACAGGGGATTTGTTATCTCCCAGATAAACACGGAATTCTCTGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATAGTCGTGGCAGCGTAATGCGATGAAATATGAACAGCCGCAGTCTAGGTCAACGCGACGACGCCAAGTCCCCCTCTTCGCCAGCCTGTGCTGCACTTTGATTGGAACCTGAGTAGAGTGGGCCTTCGAGGGTGATGAAGGTCGCATTCTTTAAAGCCCAATTTTTGAGTGCGTTATTTTTCTCTTCATCCAAGAACTCTTTATAGCTGGAGTTGGGTCCTGGATTGCAGAGGAAGATAGCGGGAATTCCACCTTTAATTTGAACTGGCTTTCCGTATTTTGTATTTGATTGCCAGTCCCTTTGGGCCCCCATGAATTCCTTAAAGTGCTTTAGGTAGTGGGGATCGACGTCATCAATGACGTTGTACCAGGCGTCATTGCTGTAGACCTTTGGGCTAAGGTCTAGATGTCCACATAAATAGTTATGTGGACCTAATGACCTGGCCCACATCGTCTTCCCCGTCCTACTCTCACCCTCTATGATAATACTAATGGGTCTTAAAGGCCGCGCAGCGGCACCGAGAACATTCTCGGCAGCCCATTCCTCAAGTTCTTCGGGAACTTGATCAAAAGAAGAAGAACAAAAAGGAGAAATATAAACCTCCAAGGGAGGTGTAAAAATCCTATCTAAGTTACATTTTAAATTATGAAATTGTAAAACATAATCTTTGGGTAGTTTTTCCCTAAATATTGCTAGGGCCGCTGAAGACGACCCTGAATTGATTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCTCTAGCTGATCTGCCATCGATCTGAAACTTACCAAAATCAATGAAGTCTCCGTCTTTCTCCACATAGGCTTTGACATCTGAACGCGACTTAGCTCCCTGAATGTTCGGATGGAAATGGGTGGCGTTATTAGGGTGAGTGACATCGAAATGTCTATGGTTTCGGAGCTGTGTTGCCCCTTTGAACTGAATGAGCGCTTGGATAAGCAAGCTCCCATCTTGAGGGTTTTCTTGAGAAACTCTAGTGGCAGGTTTATCAGAAAAAGAAGAATACTTTTTAAGTAGCTCGAGCATTCGCTCGAAGGCAGTACGGCATTTTCCATGCGTAAAGAAGATATTTTTGGCATTCACACAAAACGACTGCGTACGAGGCATATTGAATTGGGGACACTTCAAAACTCTATGGAAGGGGGGACACCGGGGACCCATTTGTAAGGTGTCCCCAAATGGCATTCACGTAATAACGTGGAAAATTCCAAAATTTTCCCGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010084446.1
|
|
Location
|
147-512 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGCGGGATCCGTTACTTAACCACTTACCCGAAACCGTTCACGGTCTTACGTGTCTGCTACCCGTTTTATATCTTTATACCGTAGAAATTACGCTTTCTCCAGACACTCTAAAATACGATTTAATCCGGGATTTGATATCTGTCATTAGGGCTAGAAAATATGTGGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCCTCGAAGGTAAACCGCAGTTTCAACTTTGTCAGCCCATATACCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAAAGCATGGGCCAACAGGCCCATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGCCCAGATGTTCCGAGGGGCTGTGA |
|
Protein Sequence
|
MRDPLLNHLPETVHGLTCLLPVLYLYTVEITLSPDTLKYDLIRDLISVIRARKYVEATSRYNHFHSRLEGKPQFQLCQPIYQPCCCPHCPRHQSKSMGQQAHEQEAQDVQDVQKPRCSEGL |
|
NCBI Accession
|
YP_010084447.1
|
|
Location
|
307-1077 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTGGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCCTCGAAGGTAAACCGCAGTTTCAACTTTGTCAGCCCATATACCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAAAGCATGGGCCAACAGGCCCATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGCCCAGATGTTCCGAGGGGCTGTGAAGGCCCGTGTAAGGTCCAGTCGTTTGAGTCCAGGCATGATATCCAGCACATTGGTAAAGTCATGTGTGTTAGTGATGTTACTCGTGGTACTGGTCTGACCCACAGAGTTGGTAAAAGGTTTTGTGTAAAATCTGTCTATGTTCTGGGCAAGATTTGGATGGATGAGAATATAAAGACTAAGAATCATACGAATAGTGTTATGTTTTTTCTTGTTAGGGATCGTAGGCCCGTTGATAAGCCCCAAGATTTTGGTGAGGTTTTTAACATGTTTGACAATGAGCCCAGTACGGCAACTGTCAAGAATGTGCATCGTGACAGGTACCAGGTTCTGAGGAAGTGGCAGGCAACCGTTACAGGTGGTCAATACGCATCGAAGGAGCAAGCTCTCGTGAAGAAGTTTATTAGAGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATAGTGAGAATGCATTGATGTTGTATATGGCGTGTGCCCATGCCTCGAACCCTGTGTATGCTACGTTGAATATACCTATCTATTATTCCGAATCTGGAACGACCTGA |
|
Protein Sequence
|
MWKRPADIIISTPASKVNRSFNFVSPYTSRAAAPIVRVTKAKAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWQATVTGGQYASKEQALVKKFIRVNNYVVYNQQEAGKYENHSENALMLYMACAHASNPVYATLNIPIYYSESGTT |
|
NCBI Accession
|
YP_010084448.1
|
|
Location
|
1080-1484 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGAGAATTCCGTGTTTATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACCGAGCACCACAACAGGCCATTCATGAGGAACCACGACATCATAACAGTCCAAGTACGGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTCACCTTCCGAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTTAGGACACATGTGTTGCTGTTTTTAACTTACTTCGCTGTAATTAGTATCAACGCTGTAATTACAGCTGTCGACCATGTTTTATGGAATGTAATAGCACCTGCAATTCATGTGCAAACTTCAAGCATAATAAAATTAAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAENSVFIWEITNPLYFKITEHHNRPFMRNHDIITVQVRFNHNLRKALGIHKCFLTFRIWTTLHPPTGLFLRVFRTHVLLFLTYFAVISINAVITAVDHVLWNVIAPAIHVQTSSIIKLNLY |
|
NCBI Accession
|
YP_010084449.1
|
|
Location
|
1225-1629 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACCTTCATCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTGGCGAAGAGGGGGACTTGGCGTCGTCGCGTTGACCTAGACTGCGGCTGTTCATATTTCATCGCATTACGCTGCCACGACTATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGAGAATTCCGTGTTTATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACCGAGCACCACAACAGGCCATTCATGAGGAACCACGACATCATAACAGTCCAAGTACGGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTCACCTTCCGAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRPSSPSKAHSTQVPIKVQHRLAKRGTWRRRVDLDCGCSYFIALRCHDYGFTHRGTHHCSSSREFRVYLGDNKSPVFQDNRAPQQAIHEEPRHHNSPSTVQSQPEESVGDTQMFSHLPNLDDLTPSDWSFLKGI |
|
NCBI Accession
|
YP_010084450.1
|
|
Location
|
1532-2617 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTCGTACGCAGTCGTTTTGTGTGAATGCCAAAAATATCTTCTTTACGCATGGAAAATGCCGTACTGCCTTCGAGCGAATGCTCGAGCTACTTAAAAAGTATTCTTCTTTTTCTGATAAACCTGCCACTAGAGTTTCTCAAGAAAACCCTCAAGATGGGAGCTTGCTTATCCAAGCGCTCATTCAGTTCAAAGGGGCAACACAGCTCCGAAACCATAGACATTTCGATGTCACTCACCCTAATAACGCCACCCATTTCCATCCGAACATTCAGGGAGCTAAGTCGCGTTCAGATGTCAAAGCCTATGTGGAGAAAGACGGAGACTTCATTGATTTTGGTAAGTTTCAGATCGATGGCAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCGTCTTCAGCGGCCCTAGCAATATTTAGGGAAAAACTACCCAAAGATTATGTTTTACAATTTCATAATTTAAAATGTAACTTAGATAGGATTTTTACACCTCCCTTGGAGGTTTATATTTCTCCTTTTTGTTCTTCTTCTTTTGATCAAGTTCCCGAAGAACTTGAGGAATGGGCTGCCGAGAATGTTCTCGGTGCCGCTGCGCGGCCTTTAAGACCCATTAGTATTATCATAGAGGGTGAGAGTAGGACGGGGAAGACGATGTGGGCCAGGTCATTAGGTCCACATAACTATTTATGTGGACATCTAGACCTTAGCCCAAAGGTCTACAGCAATGACGCCTGGTACAACGTCATTGATGACGTCGATCCCCACTACCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACAAAATACGGAAAGCCAGTTCAAATTAAAGGTGGAATTCCCGCTATCTTCCTCTGCAATCCAGGACCCAACTCCAGCTATAAAGAGTTCTTGGATGAAGAGAAAAATAACGCACTCAAAAATTGGGCTTTAAAGAATGCGACCTTCATCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTGGCGAAGAGGGGGACTTGGCGTCGTCGCGTTGA |
|
Protein Sequence
|
MPRTQSFCVNAKNIFFTHGKCRTAFERMLELLKKYSSFSDKPATRVSQENPQDGSLLIQALIQFKGATQLRNHRHFDVTHPNNATHFHPNIQGAKSRSDVKAYVEKDGDFIDFGKFQIDGRSARGGCQSANDAYAEAINSGSSSAALAIFREKLPKDYVLQFHNLKCNLDRIFTPPLEVYISPFCSSSFDQVPEELEEWAAENVLGAAARPLRPISIIIEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPAIFLCNPGPNSSYKEFLDEEKNNALKNWALKNATFITLEGPLYSGSNQSAAQAGEEGDLASSR |
|
NCBI Accession
|
YP_010084451.1
|
|
Location
|
2176-2460 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAGCTTGCTTATCCAAGCGCTCATTCAGTTCAAAGGGGCAACACAGCTCCGAAACCATAGACATTTCGATGTCACTCACCCTAATAACGCCACCCATTTCCATCCGAACATTCAGGGAGCTAAGTCGCGTTCAGATGTCAAAGCCTATGTGGAGAAAGACGGAGACTTCATTGATTTTGGTAAGTTTCAGATCGATGGCAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCGTCTTCAGCGGCCCTAG |
|
Protein Sequence
|
MGACLSKRSFSSKGQHSSETIDISMSLTLITPPISIRTFRELSRVQMSKPMWRKTETSLILVSFRSMADQLEEVANLPTTHMPRQSIQGRLQRP |