Abutilon mosaic Bolivia virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000890575.1 |
| Isolate |
Bolivia |
| Release date |
2015/2/22 |
| Submitter |
Wyant,P.S., Gotthardt,D., Schafer,B., Krenz,B., Jeske,H. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
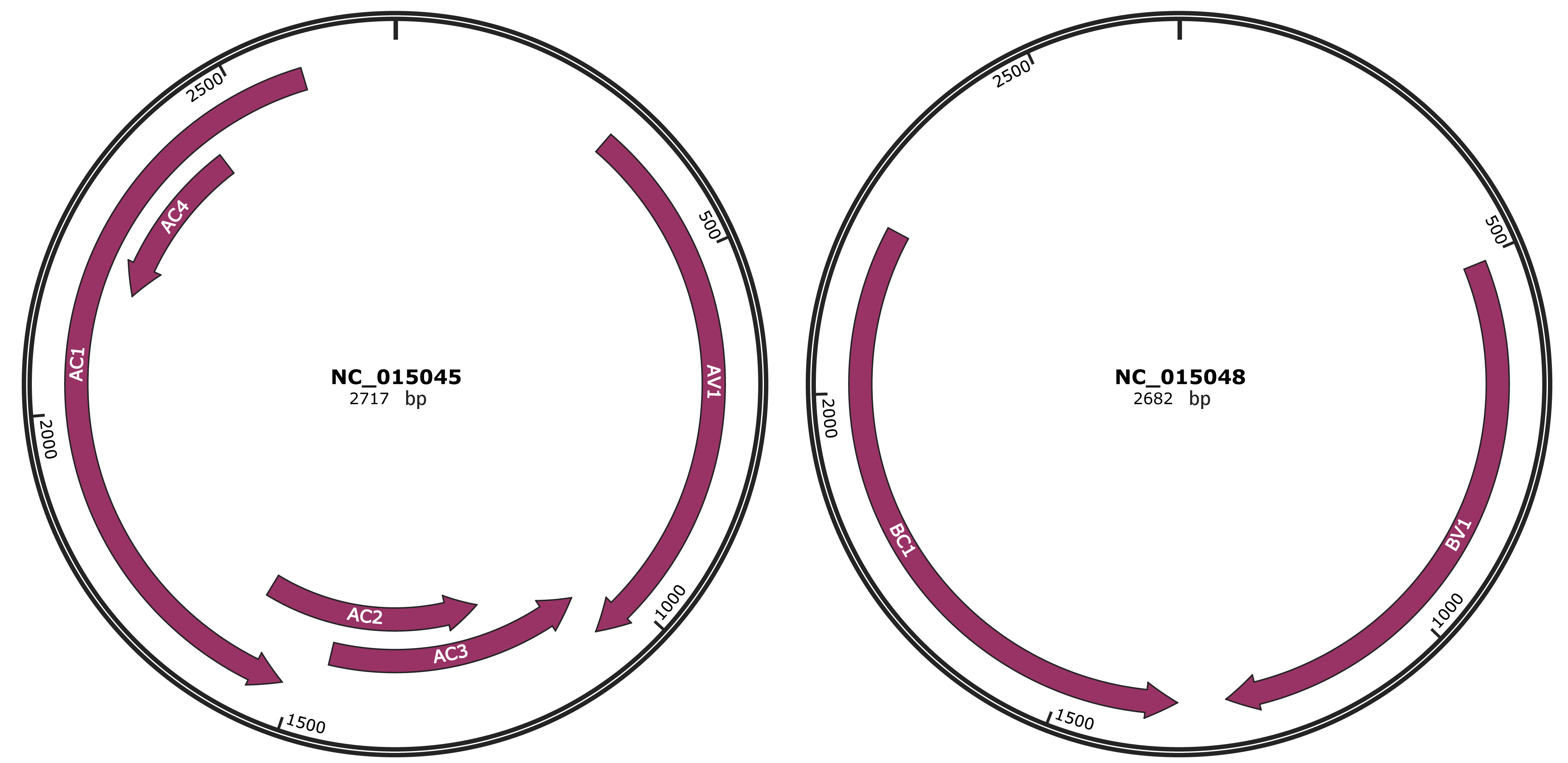
JBrowse
Genome
ACCGGATGGCCGCGCGCCCGCCCCCACGTGGAGCCCTGGTGACCGTTCGATCCCCCCCCTTTGGTGCGCTGGTGCCCGTACAATACCAATTGAGCGCATTTTTGGAGTCCGCGAATTTAGTTGAGCGTAATTTTGAGATCCGCCCCGCGGACCCGTTCGAACTTTAATTTGAATTAAAGTATTACCGTTGGGAAGCGTCCAATCACTTTTGTCCTGTCGCGCTTAGATATGCGTTAAAGTCCTTGGTGCACAAGTTTAGCCGTTATATAAAGTTTAACCTATGTTTAACCGTCTTGCTTTAATTCGAAATGCCTAAGCGCGATGCCCCGTGGCGCTCTATGGCGGGAACCTCAAAGGTTAGCCGCGCTAACAATTTTTCCCCTCGTGGAGGTATGGTGTCCAAGCCCAACAAGGCCGCTCTATGGGTTAATAGGCCCATGTACAGGAAGCCCAGAATATATCGTACTCTAAGATCGCCCGACGTTCCCAAAGGCTGTGAAGGGCCTTGTAAGGTCCAATCCTTCGAGCAGCGCCACGATATCTCCCATGTCGGCAAGGTAATATGCGTGTCCGACGTTACCCGTGGTAACGGTATTACCCACCGTGTTGGGAAACGTTTTTGCGTTAAGTCCGTGTACATTCTAGGGAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACGAACAGCGTCATGTTTTGGTTAGTTAGGGACCGTAGACCGTATGGAACGCCAATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACTGTCAAGAACGATATTCGCGATCGTTTTCAAGTTTTGCACAAGTTCTACGCCAAGGTTACAGGTGGACAATATGCAAGCAATGAACAGGCTCTCGTACGGCGTTTTTGGAGGATCAACAACTACGTGGTGTATAACCATCAAGATGCAGCGAAGTATGAGAATCACACCGAGAACGCCGTATTACTTTACATGGCATGTACGCATGCATCTAACCCCGTGTACGCAACGCTTAAGATACGAATCTATTTTTATGATTCGTTAATGAATTAATAAAGTTTAAATTTTATTGCATGATCTTCAAGTACATAGTTTACATAACGTCTGGCCGTTGCGTAACGCACAGCTCTAATTACATTGTTAATGGTAATAACTCCTAATTCGTCTAAGTACATGGTAACTATGGATTTAAACCTACTTAAATAAGTCGTCCCAGAAGGTTGAATCGATGTCGTCCAGACTTGGAAGTTCAGGAAGCATTTGTGGAGATCCAATGCTTTCCTCAGGTTGTGGTTGAACCGTATTTGTATGTGGTATACCCTGTTGTTGGTGTACAGCTGGTCCTCTACTCTGTACATCTTGAAATAAAGGGGATTGTCTACCTCCCAGATATAGACGCCATTCTCTGCCTGAGGCGCAGTGATGAGTTCCCCGGTGCGTGAATCCATGATTGCTGCAGTTAAGGTGGACGTATATGGAGCAGCCGCAGTTAAGATCAATTCGTCTACGGCGAGTTACCCGTCTCTTCGCCGCCCTGTGATGAGGCTTGATAGAGGGGGGAGTTGAGGAAGACGAATTTCGCATTATGTAGAGTCCAGGCTTTGAGAGCTGAGTTTTCAGCTTTGTCGAGGAAATCTTTATAACTAGATCCCTCGCCTGGATTGCAGAGCACGATTGATGGAAGCCCGCCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGATTGCCAGTCCTTTTGAGCCCCAATCAATTCTTTCCAGTGCTTTAGCTTTAGATAATGCGGGCTTACATCATCAATGACGTTGTACTCCACTAAGTTTGAATAAACCCTAGAATTGAAATCTAGGTGCCCGCTAAGATAATTATGTGGGCCTAACGCACGAGCCCACATTGTCTTCCCCGTCCGACTATCGCCCTCGATGATCAAACTTATGGGCCTAACAGGCCGCGCAGCGGCACCTCTCCCGAAATACTCGTCAGCCCATTCTTGCATCTCGTCAGGAACATTAGTGAAGGAGGAGAGGTGAAACGGAGAAGCCCAAGGCTCCGGAGCCTTAGAGAATATCCTGTCCAGGTTACTGGACAGATTGTGATACTGAAATAAGAACTTTTCCGGTAACTTCTCCTTTATTATTTGCATCGCTGCTTCTTTGGTCGATGCATTTAACGCCTCTGCTGCAGCGTCATTAGCTGTTTGCTTACCTCCTCTAGCAGATCTCCCGTCGATCTGGAATTCTCCCCATACAAGAATATCCCCGTCTTTGTCGACGTAGGACTTGACGTCGGAGCTGGACCTAGCTCCTTGATAGTTCCCATGGAACTGTGTTGAACTATGTGGGGAGACCAAGTCGAAGAATCTTTTATTTTGGCAGTTGTATTTGCCTTCGAACTGGAGCAACACATGTAAATGAGGCTGCCCATCTTCGTGGAGCTCTCGACAGATCTTGACGTATTTCTTATTTGTTGGGGTTTGAAGGTTTAGTAGTTGGGAAAGTACCTCCTCTTTGGATAGTGAGCATTTGGGATAAGTGAGGAAATAATTCTTGGCATTTATTTGAAAAGGCTTGACCCGTGGCATTATTGTAAATAAGAGGCTCACTACCGGTAGTAGCTCTTCTCAAAACTCTATATGAATCGGTAGTAAGGTAGTGTATTTATAGAAGTTCTCTCAAGGACACGTGGCGGCCATCCGACTATAATATT
ACCGGATGGCCGCGCGCCCGCCCCCCCACGTGGAGCCCTGGTGACCGTTCGATCCCCCCCCCTTGGTGCGCTGGTGCCCGTACAATACCAATTGAGCGCATTTTTGAAGTCCGCGAATTTAGTTGAGCGCAATTTTGAGATCCGCCCCGCGGACCCGTTCGACCTTTAATTTGAATTAAAGTATTTTCGTTAAAGTCGCGCGATATTTTGTCAGAACGCTTTGTGTTTGTACCGTTAGATATCTTTAAGGAATGATCGCCCGGCTGAAATTAAAATAGGAATTAAAGTGGATCGTTCTGACAATATGACCCATAGATACAATGATTTTTGTTTTTGTCATTGTACTTAATTTTGAACATCGACCAATTAAATAAGCTCTATATTGTTAAGATAAGTAATACATCTGAATGGGAATTTATATTTAAATTCAATTATGTTGAGCTTGCCACTGCGTCGATGTACATTGAATAGCTACGCTTGATATATTCTTAATAGGCAGTACTGAACATGTATCCTACTAAGTTTAGACGTGGTTGGTCGTCTACTAAACGAAGAAGCTATTCACGATTTCCCCAGTCCAGACGTTCTATTTCTGTCAAGCGTACTGATGGGAAACGTCGTCCTAGTAGTACCAAGAAAACTCCAGTTGAAGGTCAAATGGTGGAACAACGCATACATGAAAACCAGTTTGGGCCCGAATTTGTTATGGGCCAAAATTCAGCCCTTTCGACTTTTATCAACTACCCTGTACTCGGTAAAACCCTCCCTAATCGATCCCGTGCATATATCAAGTTAAAACGACTTCGTTTTAAAGGTACTGTCAAGATTGAACGTGTTCATGCTGACGTGAACATGGAGGGTGCACCCCCAAAGATCGAAGGGGTCTTTTCATTAGTCGTTGTGGTTGATCGTAAACCCCACTTGAGCCCGACAGGATGTCTTCATACATTTGATGAGTTATTCGGTGCAAGGATCAATAGCCATGGTAATTTAGACATTACTCCCTCTCTGAAAGACCGTTTCTACATACGTCACGTTCTGAAACGTGTTCTGTCCGTGGAGAAGGATACGATGATGGTTGACCTTGAAGGAACGACATCCCTATCTAACAGGCGTTTTAATTGTTGGGCTTCGTTTAATGACCTTGATCGGGAGTCATGTAATGGTGTTTATGCAAATATAAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCGGATATCCCGTCTAAGGCATCGACATTTGTATCTTTTGACCTTGATTATATCGGATAATAATAAGAATTGCTATTATGTTAAGTCAACTGCAAGTAATGATAAGATAAGAAAATAAACAGCGTTTATTTCAATGATTTTGGTGCTGACGGAGTACAATTATTGTTAATACACTCTTGGACCGTCGTCCTCACAAGTTCACTCAATTGTGCCACTGACATTGTTATATTTGACTGTGCCCTCTGGGCCCCGACAATTGAAGCGGAGTCTCCTGGGTCTAGGATGGTGGTACCGAGTCTGTTAAGTTCCCTATACGGATGTGTGGCGTCCCCCACATCAGAATCCGCATCGTTGTGTCCTATGGTACTACGAGAGGCCCATGATTCGCCTGGTCTTAATTCAAGTGGGCTTGGAAGCCCAAATCTTAATGTTGAGGCGGATCTGATAAGCTTCCTCTCCCACCTTCCATAGTCGACGTGCGAGAAATCGACATCTTTGTCGGTGAACTGTTTAGATAAGATCTTAACGGTCGGTGCCCGGAACGGGATATCTACGGAATGTTTTGCCGTCGACAGTTTCAGCTTCCCCTTGAATTTTGCGAAATGGGTCCTCTGATGAACGTTGGTGTCGGAAACTCTGTAATACAGTTTCCATGGAATTGGGTCTTTAAGTGAGAAGAAAGATGATGAGAAATAATGGAGATCTATGTTACATCTGATGGGAAATGTCCACGAAGCTTGTAAGGATTCATTGTCAGTCATCCTCTTGTCGTGGATCTCCATAATTACAGACCCCGTCGCGTTAATTGGAACTTGCTGTCTGTATTCGATGACGCAATGGTCGATTTTCATGCAGCTACGACTGAGTCTAGCTGTTAATTGAGATGCCGTCGACGGAAATTGCAAAATAATCTCCGTTAAGTCATGCGAAAGCTGATATTCGTCACGATGCGATTCTATATAATTAAAGGCGTTAGGAGGATTAACCAGCTGAGAAGATTCCATTGAAAATTATGGGAGCGCAGCGACAACGACGAGGTTAATGAAATGGGGAAAGAGAGTATATGAGGAAGAAAATTTACTAATTGGAATAAGAAAGTAATGCAAGATGAAGAGGAACTCTGTTTTAGAAGGAGAATAAATAATAGTAGTGAAGGGATGCTGAGAACTATCAATTGGGTGTTGTGCTTATATAGAAAGGAAAAGACTTGTTAAGTTAATTAGTTTAAGGAATAATTAAATTAAGTTAAGCTGTCATTATTTGGTAGATGAGTGTGTTTTGATGTTGATAAGCACAACTTACCTATAGTTAAGACAATGAAAAGGAAGTTCGGTGGCATTCTTGTAAATAAGAGCCTCACTACCGGTAGTAGCTCCTCTCAAAACTCTATATGAATCGGTAGTAAGGTAGTGTATTTATAGAAGTTCTCTCAAGGACACGTGGCGGCCATCCGACTATAATATT
Gene Information
|
NCBI Accession
|
YP_004207819.1
|
|
Location
|
309-1064 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCGTGGCGCTCTATGGCGGGAACCTCAAAGGTTAGCCGCGCTAACAATTTTTCCCCTCGTGGAGGTATGGTGTCCAAGCCCAACAAGGCCGCTCTATGGGTTAATAGGCCCATGTACAGGAAGCCCAGAATATATCGTACTCTAAGATCGCCCGACGTTCCCAAAGGCTGTGAAGGGCCTTGTAAGGTCCAATCCTTCGAGCAGCGCCACGATATCTCCCATGTCGGCAAGGTAATATGCGTGTCCGACGTTACCCGTGGTAACGGTATTACCCACCGTGTTGGGAAACGTTTTTGCGTTAAGTCCGTGTACATTCTAGGGAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACGAACAGCGTCATGTTTTGGTTAGTTAGGGACCGTAGACCGTATGGAACGCCAATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACTGTCAAGAACGATATTCGCGATCGTTTTCAAGTTTTGCACAAGTTCTACGCCAAGGTTACAGGTGGACAATATGCAAGCAATGAACAGGCTCTCGTACGGCGTTTTTGGAGGATCAACAACTACGTGGTGTATAACCATCAAGATGCAGCGAAGTATGAGAATCACACCGAGAACGCCGTATTACTTTACATGGCATGTACGCATGCATCTAACCCCGTGTACGCAACGCTTAAGATACGAATCTATTTTTATGATTCGTTAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRANNFSPRGGMVSKPNKAALWVNRPMYRKPRIYRTLRSPDVPKGCEGPCKVQSFEQRHDISHVGKVICVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDIRDRFQVLHKFYAKVTGGQYASNEQALVRRFWRINNYVVYNHQDAAKYENHTENAVLLYMACTHASNPVYATLKIRIYFYDSLMN |
|
NCBI Accession
|
YP_004207820.1
|
|
Location
|
1061-1459 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTCTATATCTGGGAGGTAGACAATCCCCTTTATTTCAAGATGTACAGAGTAGAGGACCAGCTGTACACCAACAACAGGGTATACCACATACAAATACGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAATGCTTCCTGAACTTCCAAGTCTGGACGACATCGATTCAACCTTCTGGGACGACTTATTTAAGTAGGTTTAAATCCATAGTTACCATGTACTTAGACGAATTAGGAGTTATTACCATTAACAATGTAATTAGAGCTGTGCGTTACGCAACGGCCAGACGTTATGTAAACTATGTACTTGAAGATCATGCAATAAAATTTAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGVYIWEVDNPLYFKMYRVEDQLYTNNRVYHIQIRFNHNLRKALDLHKCFLNFQVWTTSIQPSGTTYLSRFKSIVTMYLDELGVITINNVIRAVRYATARRYVNYVLEDHAIKFKLY |
|
NCBI Accession
|
YP_004207821.1
|
|
Location
|
1206-1595 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCGAAATTCGTCTTCCTCAACTCCCCCCTCTATCAAGCCTCATCACAGGGCGGCGAAGAGACGGGTAACTCGCCGTAGACGAATTGATCTTAACTGCGGCTGCTCCATATACGTCCACCTTAACTGCAGCAATCATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTCTATATCTGGGAGGTAGACAATCCCCTTTATTTCAAGATGTACAGAGTAGAGGACCAGCTGTACACCAACAACAGGGTATACCACATACAAATACGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAATGCTTCCTGAACTTCCAAGTCTGGACGACATCGATTCAACCTTCTGGGACGACTTATTTAAGTAG |
|
Protein Sequence
|
MRNSSSSTPPSIKPHHRAAKRRVTRRRRIDLNCGCSIYVHLNCSNHGFTHRGTHHCASGREWRLYLGGRQSPLFQDVQSRGPAVHQQQGIPHTNTVQPQPEESIGSPQMLPELPSLDDIDSTFWDDLFK |
|
NCBI Accession
|
YP_004207822.1
|
|
Location
|
1516-2592 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGGGTCAAGCCTTTTCAAATAAATGCCAAGAATTATTTCCTCACTTATCCCAAATGCTCACTATCCAAAGAGGAGGTACTTTCCCAACTACTAAACCTTCAAACCCCAACAAATAAGAAATACGTCAAGATCTGTCGAGAGCTCCACGAAGATGGGCAGCCTCATTTACATGTGTTGCTCCAGTTCGAAGGCAAATACAACTGCCAAAATAAAAGATTCTTCGACTTGGTCTCCCCACATAGTTCAACACAGTTCCATGGGAACTATCAAGGAGCTAGGTCCAGCTCCGACGTCAAGTCCTACGTCGACAAAGACGGGGATATTCTTGTATGGGGAGAATTCCAGATCGACGGGAGATCTGCTAGAGGAGGTAAGCAAACAGCTAATGACGCTGCAGCAGAGGCGTTAAATGCATCGACCAAAGAAGCAGCGATGCAAATAATAAAGGAGAAGTTACCGGAAAAGTTCTTATTTCAGTATCACAATCTGTCCAGTAACCTGGACAGGATATTCTCTAAGGCTCCGGAGCCTTGGGCTTCTCCGTTTCACCTCTCCTCCTTCACTAATGTTCCTGACGAGATGCAAGAATGGGCTGACGAGTATTTCGGGAGAGGTGCCGCTGCGCGGCCTGTTAGGCCCATAAGTTTGATCATCGAGGGCGATAGTCGGACGGGGAAGACAATGTGGGCTCGTGCGTTAGGCCCACATAATTATCTTAGCGGGCACCTAGATTTCAATTCTAGGGTTTATTCAAACTTAGTGGAGTACAACGTCATTGATGATGTAAGCCCGCATTATCTAAAGCTAAAGCACTGGAAAGAATTGATTGGGGCTCAAAAGGACTGGCAATCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGCGGGCTTCCATCAATCGTGCTCTGCAATCCAGGCGAGGGATCTAGTTATAAAGATTTCCTCGACAAAGCTGAAAACTCAGCTCTCAAAGCCTGGACTCTACATAATGCGAAATTCGTCTTCCTCAACTCCCCCCTCTATCAAGCCTCATCACAGGGCGGCGAAGAGACGGGTAACTCGCCGTAG |
|
Protein Sequence
|
MPRVKPFQINAKNYFLTYPKCSLSKEEVLSQLLNLQTPTNKKYVKICRELHEDGQPHLHVLLQFEGKYNCQNKRFFDLVSPHSSTQFHGNYQGARSSSDVKSYVDKDGDILVWGEFQIDGRSARGGKQTANDAAAEALNASTKEAAMQIIKEKLPEKFLFQYHNLSSNLDRIFSKAPEPWASPFHLSSFTNVPDEMQEWADEYFGRGAAARPVRPISLIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNLVEYNVIDDVSPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGLPSIVLCNPGEGSSYKDFLDKAENSALKAWTLHNAKFVFLNSPLYQASSQGGEETGNSP |
|
NCBI Accession
|
YP_004207823.1
|
|
Location
|
2178-2435 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAGCCTCATTTACATGTGTTGCTCCAGTTCGAAGGCAAATACAACTGCCAAAATAAAAGATTCTTCGACTTGGTCTCCCCACATAGTTCAACACAGTTCCATGGGAACTATCAAGGAGCTAGGTCCAGCTCCGACGTCAAGTCCTACGTCGACAAAGACGGGGATATTCTTGTATGGGGAGAATTCCAGATCGACGGGAGATCTGCTAGAGGAGGTAAGCAAACAGCTAATGACGCTGCAGCAGAGGCGTTAA |
|
Protein Sequence
|
MGSLIYMCCSSSKANTTAKIKDSSTWSPHIVQHSSMGTIKELGPAPTSSPTSTKTGIFLYGENSRSTGDLLEEVSKQLMTLQQRR |
|
NCBI Accession
|
YP_004207831.1
|
|
Location
|
508-1278 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCTACTAAGTTTAGACGTGGTTGGTCGTCTACTAAACGAAGAAGCTATTCACGATTTCCCCAGTCCAGACGTTCTATTTCTGTCAAGCGTACTGATGGGAAACGTCGTCCTAGTAGTACCAAGAAAACTCCAGTTGAAGGTCAAATGGTGGAACAACGCATACATGAAAACCAGTTTGGGCCCGAATTTGTTATGGGCCAAAATTCAGCCCTTTCGACTTTTATCAACTACCCTGTACTCGGTAAAACCCTCCCTAATCGATCCCGTGCATATATCAAGTTAAAACGACTTCGTTTTAAAGGTACTGTCAAGATTGAACGTGTTCATGCTGACGTGAACATGGAGGGTGCACCCCCAAAGATCGAAGGGGTCTTTTCATTAGTCGTTGTGGTTGATCGTAAACCCCACTTGAGCCCGACAGGATGTCTTCATACATTTGATGAGTTATTCGGTGCAAGGATCAATAGCCATGGTAATTTAGACATTACTCCCTCTCTGAAAGACCGTTTCTACATACGTCACGTTCTGAAACGTGTTCTGTCCGTGGAGAAGGATACGATGATGGTTGACCTTGAAGGAACGACATCCCTATCTAACAGGCGTTTTAATTGTTGGGCTTCGTTTAATGACCTTGATCGGGAGTCATGTAATGGTGTTTATGCAAATATAAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCGGATATCCCGTCTAAGGCATCGACATTTGTATCTTTTGACCTTGATTATATCGGATAA |
|
Protein Sequence
|
MYPTKFRRGWSSTKRRSYSRFPQSRRSISVKRTDGKRRPSSTKKTPVEGQMVEQRIHENQFGPEFVMGQNSALSTFINYPVLGKTLPNRSRAYIKLKRLRFKGTVKIERVHADVNMEGAPPKIEGVFSLVVVVDRKPHLSPTGCLHTFDELFGARINSHGNLDITPSLKDRFYIRHVLKRVLSVEKDTMMVDLEGTTSLSNRRFNCWASFNDLDRESCNGVYANISKNALLVYYCWMSDIPSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_004207832.1
|
|
Location
|
1344-2222 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTTCTCAGCTGGTTAATCCTCCTAACGCCTTTAATTATATAGAATCGCATCGTGACGAATATCAGCTTTCGCATGACTTAACGGAGATTATTTTGCAATTTCCGTCGACGGCATCTCAATTAACAGCTAGACTCAGTCGTAGCTGCATGAAAATCGACCATTGCGTCATCGAATACAGACAGCAAGTTCCAATTAACGCGACGGGGTCTGTAATTATGGAGATCCACGACAAGAGGATGACTGACAATGAATCCTTACAAGCTTCGTGGACATTTCCCATCAGATGTAACATAGATCTCCATTATTTCTCATCATCTTTCTTCTCACTTAAAGACCCAATTCCATGGAAACTGTATTACAGAGTTTCCGACACCAACGTTCATCAGAGGACCCATTTCGCAAAATTCAAGGGGAAGCTGAAACTGTCGACGGCAAAACATTCCGTAGATATCCCGTTCCGGGCACCGACCGTTAAGATCTTATCTAAACAGTTCACCGACAAAGATGTCGATTTCTCGCACGTCGACTATGGAAGGTGGGAGAGGAAGCTTATCAGATCCGCCTCAACATTAAGATTTGGGCTTCCAAGCCCACTTGAATTAAGACCAGGCGAATCATGGGCCTCTCGTAGTACCATAGGACACAACGATGCGGATTCTGATGTGGGGGACGCCACACATCCGTATAGGGAACTTAACAGACTCGGTACCACCATCCTAGACCCAGGAGACTCCGCTTCAATTGTCGGGGCCCAGAGGGCACAGTCAAATATAACAATGTCAGTGGCACAATTGAGTGAACTTGTGAGGACGACGGTCCAAGAGTGTATTAACAATAATTGTACTCCGTCAGCACCAAAATCATTGAAATAA |
|
Protein Sequence
|
MESSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIMEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKLIRSASTLRFGLPSPLELRPGESWASRSTIGHNDADSDVGDATHPYRELNRLGTTILDPGDSASIVGAQRAQSNITMSVAQLSELVRTTVQECINNNCTPSAPKSLK |