Sporobolus striate mosaic virus 2
Basic Information
| Genus |
Mastrevirus
|
| NCBI Assembly |
GCF_000899215.1 |
| Isolate |
Australia |
| Release date |
2015/2/22 |
| Submitter |
Kraberger,S., Thomas,J.E., Geering,A.D., Dayaram,A., Stainton,D., Hadfield,J., Walters,M., Parmenter,K.S., van Brunschot,S., Collings,D.A., Martin,D.P., Varsani,A., Geering,A., Parmenter,K. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
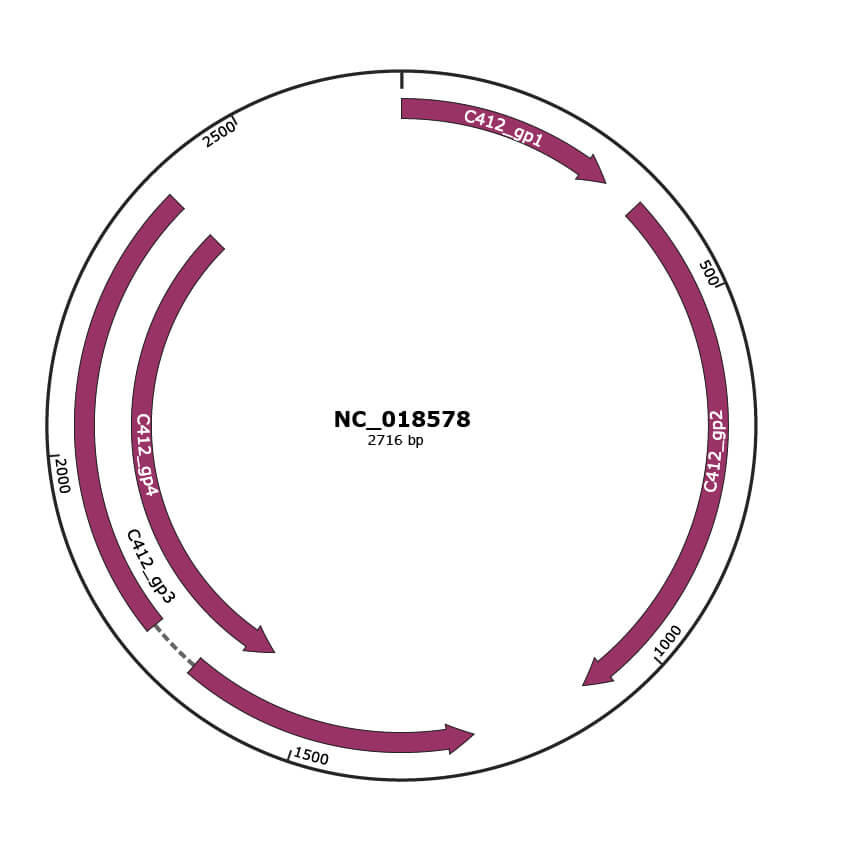
JBrowse
Genome
ATGTCTAATCCGGCAACCCCTTTGGGTGATTACACCTCAAGTCAGCATCAGGGTGGTACGCAGTCCGGATCCGTCGGAATCGGTAACGATTCCGCGTGGAGGGCGCTAGCTCTTGCTTTCACCGTAACTACGGTAACTCTTGTTTTGCTGTTCGGAGCTTGGAGGCTTTGTCTGAAAGACTGCCTTCTGACTCTGCGGGCTAAACGCAGCAAGACTACGACCGAACTAGGATTCGGTCAGACGCCGAGAAGGGATCCGGTAGGCGGAGGAGTCACCCAGTACCCCCCCGGAGTCCCTGGGTAACCAGGATCACCGCCGTAAAAGACGGCCGTGAAGCGGTCCAGAGAGGACGCTATGCCTCCTCCCGCTAAGAAGAAGAAGGGTTCGGACTCTGGAGCCGGAGGCTCCAGAAGCGTATACCAGCGAAGGTATTACGGACCGAGGAGCTCAAGCGGACGAGCAGTCAGACGTCCTCCGCTTCAGTTCATCCAGTACACCTGGACGAGCAACGGTTCTCCGATAACCGTTGGTCCGAATGGGTACGTAGCTCTCCTGACTAGCTTCCCAAGGGGAAGCGACGAAGATAAGCGTCATACAGGAGAGACTGTGACGTACAAGGTAGGCTTGGATCTGTTCTGCGTCAGAGACACAAACAGATACAAGGAGATAGGATCTGCTATCCACTGCTGCTGGTTGGTCTACGACGCTCAACCAACCGGTACGATTCCGGGGCTGGGAACTATCTTCGACCTCGTTGATAACTTCACGGAGTACCCGACGACATGGAAGGTAAACCGGGATATGGGGCACCGGTTTGTGATTAAACGTCGCTGGACCTTCACGCTCCAGTCGGATGGTCACCTGGGATCGAACGACTACAGCCGGGCTCCTGCAGCGCCCTGCAAGTACATGATTGCGTTCAACAAGTTCGTGAAGCGTCTAGGTGTTCGGACGGAATGGAGGAACACAACGACGGGTGACATCGGAGACGTGTCTAGGGGTGCGTTGTACATCGTAATGGCTAGAGGCAATGCCTGGAGTTACGAAGTTAGGGGGCGTATAAGAGTGTATTTCAAATCAGTCGGGAATCAGTGATGTAAGAACTCCTGGCTTGTAATGAATAAGACGTGTTTAATAAAATGCGTCAGTATGACGCTTGATTACATAACAGCACACTCGAACCGCCGCCGAGGCTTAAGACGAGTCGGTGCGGTTCCCTGCGATACATGACATTAAAAAAAGATTACATTTATGAAAATTACAAAGCTTCATTTCTAATGAAGCTTTCTCCTTCCGACATATAATATATCGACATATTCCCTTCAAAATACGAACGCTGGCCGTCGTTCATGGCTCTCATCCAGTCGTCGTCCTCGTTAACTAGGATGATACTTGGTATTCCTCCTTTGATGAGTTTTTTCTTGCCGTACTTTGGGTTGACTGTATATTCATGCTGAGAGCCAACCAAGGCCTTCCAATAAGGACAGAACTTGAACGGAATATCATCGATTACATTATACTGGGCTTCGTTATTATAGTTGGCGAAGTCCAGGTTCATCTGCCAGTAGTTATGTTTACCTAGACTCCTGGCCCAAGATGTCTTACCGGTACGATTTGGTCCGCAGATGTAGAGCCCAGATTTCCTAGTTCTTGGATGGTCTGCAGACTAGCATCCATCAACCAGTTTAGGTCCCCCGAAGCGTCAGCCTGCGGATGTAAAGAAGAGTATGCAGCAGGAGATACCTGGTAGAGTGTATTATCGAGCCAGTCTGTGATTCTCTCATTACACATGAGATTTTCTGTAGGGAAAGGGCTTGTGTATTCCGGAATCACGTCAGGGAAGAGCTTTGACGCGGAATATTCGAACTGCTGGAGTTTAGTAGCCCAGTCAAATGGGAAGGCTTTTCTGACCATTGAGAGATAACTGGCTCGGTCAGTTGAAGTGTTGATGATTGAGCGCATGACTGAGTCCTTTGCTTTGGACTCAGTGTTCTTTGGAGTCCTGCCTTTGAGAGGAATGAAGGTTCCTCTCTCGGCCTTTGAGACTGGATTTTTGAGACAATAGTCTCGGACGTTTGTAGGAGATTTTGCAGTTTGGATGTTAGGATGATAATCAAGGATATTAAAAGTACTGCTATCATTGGTACTGAATGCCTTATCAAGCTGAAATAGACAGTGAAGATGGTAATCACCGTCGCTGTGATGCTCACGAGTGACGAGGCAGTACTTCGGACCGTACTTGCGGAATTTAGAATAGAGATGTTCGACAACATCTCTAGGCTCCAGAGTGCACTTCGGATATGTAAGAAATGCGCTACGAGCTCTGAATCTGAAGTTTGCTGGGGATGCTTCGGTGGAGTTGCTCTGTGAAGACATGAGTGAAGTGAGTACTTAGTCGCGGAAGCTACTCAGCTCTCTCTTTTAGTCTACCGGGAACGCTTTCCTTTGCCCTTACGCGGGCCGGGCCGCGTTTATATAACACTCGAAAAGGCCGAGGAACCTTTAAATGACGGGACCGGCCGGCCGGCCCGGGGCGGCTCGCGGGGGCAAGGAAAGCGAAGCATAATATTACCCTTGCCCCCGCGGGCCGTCCCGAGGGCGACGTGTGCGCTCTACGTCGCCCGAGGGAAAGTGATAGAGAAAGAAAGGGAATCCTTTAATTAAAGAAGACTTGGATAGCACGTCTCTTTAAAAGGGGGTGCGCTCTGAGTCGGTT
Gene Information
|
NCBI Accession
|
YP_006666529.1
|
|
Location
|
1-303 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTCTAATCCGGCAACCCCTTTGGGTGATTACACCTCAAGTCAGCATCAGGGTGGTACGCAGTCCGGATCCGTCGGAATCGGTAACGATTCCGCGTGGAGGGCGCTAGCTCTTGCTTTCACCGTAACTACGGTAACTCTTGTTTTGCTGTTCGGAGCTTGGAGGCTTTGTCTGAAAGACTGCCTTCTGACTCTGCGGGCTAAACGCAGCAAGACTACGACCGAACTAGGATTCGGTCAGACGCCGAGAAGGGATCCGGTAGGCGGAGGAGTCACCCAGTACCCCCCCGGAGTCCCTGGGTAA |
|
Protein Sequence
|
MSNPATPLGDYTSSQHQGGTQSGSVGIGNDSAWRALALAFTVTTVTLVLLFGAWRLCLKDCLLTLRAKRSKTTTELGFGQTPRRDPVGGGVTQYPPGVPG |
|
NCBI Accession
|
YP_006666530.1
|
|
Location
|
355-1095 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCCTCCTCCCGCTAAGAAGAAGAAGGGTTCGGACTCTGGAGCCGGAGGCTCCAGAAGCGTATACCAGCGAAGGTATTACGGACCGAGGAGCTCAAGCGGACGAGCAGTCAGACGTCCTCCGCTTCAGTTCATCCAGTACACCTGGACGAGCAACGGTTCTCCGATAACCGTTGGTCCGAATGGGTACGTAGCTCTCCTGACTAGCTTCCCAAGGGGAAGCGACGAAGATAAGCGTCATACAGGAGAGACTGTGACGTACAAGGTAGGCTTGGATCTGTTCTGCGTCAGAGACACAAACAGATACAAGGAGATAGGATCTGCTATCCACTGCTGCTGGTTGGTCTACGACGCTCAACCAACCGGTACGATTCCGGGGCTGGGAACTATCTTCGACCTCGTTGATAACTTCACGGAGTACCCGACGACATGGAAGGTAAACCGGGATATGGGGCACCGGTTTGTGATTAAACGTCGCTGGACCTTCACGCTCCAGTCGGATGGTCACCTGGGATCGAACGACTACAGCCGGGCTCCTGCAGCGCCCTGCAAGTACATGATTGCGTTCAACAAGTTCGTGAAGCGTCTAGGTGTTCGGACGGAATGGAGGAACACAACGACGGGTGACATCGGAGACGTGTCTAGGGGTGCGTTGTACATCGTAATGGCTAGAGGCAATGCCTGGAGTTACGAAGTTAGGGGGCGTATAAGAGTGTATTTCAAATCAGTCGGGAATCAGTGA |
|
Protein Sequence
|
MPPPAKKKKGSDSGAGGSRSVYQRRYYGPRSSSGRAVRRPPLQFIQYTWTSNGSPITVGPNGYVALLTSFPRGSDEDKRHTGETVTYKVGLDLFCVRDTNRYKEIGSAIHCCWLVYDAQPTGTIPGLGTIFDLVDNFTEYPTTWKVNRDMGHRFVIKRRWTFTLQSDGHLGSNDYSRAPAAPCKYMIAFNKFVKRLGVRTEWRNTTTGDIGDVSRGALYIVMARGNAWSYEVRGRIRVYFKSVGNQ |
|
NCBI Accession
|
YP_006666531.1
|
|
Location
|
1259-1666,1744-2376 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGTCTTCACAGAGCAACTCCACCGAAGCATCCCCAGCAAACTTCAGATTCAGAGCTCGTAGCGCATTTCTTACATATCCGAAGTGCACTCTGGAGCCTAGAGATGTTGTCGAACATCTCTATTCTAAATTCCGCAAGTACGGTCCGAAGTACTGCCTCGTCACTCGTGAGCATCACAGCGACGGTGATTACCATCTTCACTGTCTATTTCAGCTTGATAAGGCATTCAGTACCAATGATAGCAGTACTTTTAATATCCTTGATTATCATCCTAACATCCAAACTGCAAAATCTCCTACAAACGTCCGAGACTATTGTCTCAAAAATCCAGTCTCAAAGGCCGAGAGAGGAACCTTCATTCCTCTCAAAGGCAGGACTCCAAAGAACACTGAGTCCAAAGCAAAGGACTCAGTCATGCGCTCAATCATCAACACTTCAACTGACCGAGCCAGTTATCTCTCAATGGTCAGAAAAGCCTTCCCATTTGACTGGGCTACTAAACTCCAGCAGTTCGAATATTCCGCGTCAAAGCTCTTCCCTGACGTGATTCCGGAATACACAAGCCCTTTCCCTACAGAAAATCTCATGTGTAATGAGAGAATCACAGACTGGCTCGATAATACACTCTACCAGTCTGCAGACCATCCAAGAACTAGGAAATCTGGGCTCTACATCTGCGGACCAAATCGTACCGGTAAGACATCTTGGGCCAGGAGTCTAGGTAAACATAACTACTGGCAGATGAACCTGGACTTCGCCAACTATAATAACGAAGCCCAGTATAATGTAATCGATGATATTCCGTTCAAGTTCTGTCCTTATTGGAAGGCCTTGGTTGGCTCTCAGCATGAATATACAGTCAACCCAAAGTACGGCAAGAAAAAACTCATCAAAGGAGGAATACCAAGTATCATCCTAGTTAACGAGGACGACGACTGGATGAGAGCCATGAACGACGGCCAGCGTTCGTATTTTGAAGGGAATATGTCGATATATTATATGTCGGAAGGAGAAAGCTTCATTAGAAATGAAGCTTTGTAA |
|
Protein Sequence
|
MSSQSNSTEASPANFRFRARSAFLTYPKCTLEPRDVVEHLYSKFRKYGPKYCLVTREHHSDGDYHLHCLFQLDKAFSTNDSSTFNILDYHPNIQTAKSPTNVRDYCLKNPVSKAERGTFIPLKGRTPKNTESKAKDSVMRSIINTSTDRASYLSMVRKAFPFDWATKLQQFEYSASKLFPDVIPEYTSPFPTENLMCNERITDWLDNTLYQSADHPRTRKSGLYICGPNRTGKTSWARSLGKHNYWQMNLDFANYNNEAQYNVIDDIPFKFCPYWKALVGSQHEYTVNPKYGKKKLIKGGIPSIILVNEDDDWMRAMNDGQRSYFEGNMSIYYMSEGESFIRNEAL |
|
NCBI Accession
|
YP_006666532.1
|
|
Location
|
1579-2376 |
|
Protein Name
|
RepA |
|
Coding Region
|
ATGTCTTCACAGAGCAACTCCACCGAAGCATCCCCAGCAAACTTCAGATTCAGAGCTCGTAGCGCATTTCTTACATATCCGAAGTGCACTCTGGAGCCTAGAGATGTTGTCGAACATCTCTATTCTAAATTCCGCAAGTACGGTCCGAAGTACTGCCTCGTCACTCGTGAGCATCACAGCGACGGTGATTACCATCTTCACTGTCTATTTCAGCTTGATAAGGCATTCAGTACCAATGATAGCAGTACTTTTAATATCCTTGATTATCATCCTAACATCCAAACTGCAAAATCTCCTACAAACGTCCGAGACTATTGTCTCAAAAATCCAGTCTCAAAGGCCGAGAGAGGAACCTTCATTCCTCTCAAAGGCAGGACTCCAAAGAACACTGAGTCCAAAGCAAAGGACTCAGTCATGCGCTCAATCATCAACACTTCAACTGACCGAGCCAGTTATCTCTCAATGGTCAGAAAAGCCTTCCCATTTGACTGGGCTACTAAACTCCAGCAGTTCGAATATTCCGCGTCAAAGCTCTTCCCTGACGTGATTCCGGAATACACAAGCCCTTTCCCTACAGAAAATCTCATGTGTAATGAGAGAATCACAGACTGGCTCGATAATACACTCTACCAGGTATCTCCTGCTGCATACTCTTCTTTACATCCGCAGGCTGACGCTTCGGGGGACCTAAACTGGTTGATGGATGCTAGTCTGCAGACCATCCAAGAACTAGGAAATCTGGGCTCTACATCTGCGGACCAAATCGTACCGGTAAGACATCTTGGGCCAGGAGTCTAG |
|
Protein Sequence
|
MSSQSNSTEASPANFRFRARSAFLTYPKCTLEPRDVVEHLYSKFRKYGPKYCLVTREHHSDGDYHLHCLFQLDKAFSTNDSSTFNILDYHPNIQTAKSPTNVRDYCLKNPVSKAERGTFIPLKGRTPKNTESKAKDSVMRSIINTSTDRASYLSMVRKAFPFDWATKLQQFEYSASKLFPDVIPEYTSPFPTENLMCNERITDWLDNTLYQVSPAAYSSLHPQADASGDLNWLMDASLQTIQELGNLGSTSADQIVPVRHLGPGV |