Chickpea yellow dwarf virus
Basic Information
| Genus | Mastrevirus |
|---|---|
| NCBI Assembly | GCF_000927635.1 |
| Isolate | Pakistan |
| Release date | 2015/2/22 |
| Submitter | Kraberger,S., Mumtaz,H.H., Briddon,R.W., Martin,D.P., Varsani,A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
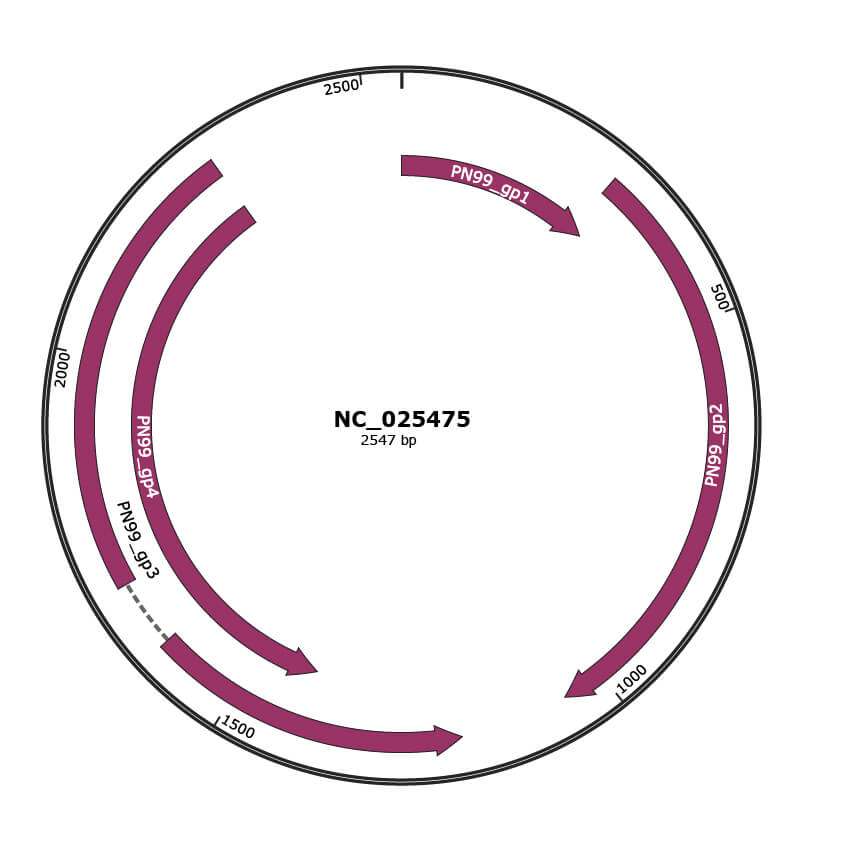
JBrowse
Genome
NC_025475
Gene Information
| NCBI Accession | YP_009104361.1 |
|---|---|
| Location | 1-306 |
| Protein Name | movement protein |
| Coding Region | ATGCTTCCCGCTAAATACCAAGTCTTTCCTGGAGAAAATTACTCTTATACCCCAACTTTCGCGGGAAGTTATCAGGAAGTGCCTACCTCACATAATTCTTCTGGTGAGACTTTTAACAAAGTCTTTGTTGCCCTTATAGTTATATTAATTTCCGTTGGTGTCTGTTATTTGGCTTACGTACTATTCGTTAAGGATCTTATTCTTCTATTGAAGGCTAAAAAACAAAGGACTACAACAGAGATAGGATTTGGTAACACTCCAGGTAGACCTAACAGTCGAAGACAAGAGGATGCCGGGACCGTTTAG |
| Protein Sequence | MLPAKYQVFPGENYSYTPTFAGSYQEVPTSHNSSGETFNKVFVALIVILISVGVCYLAYVLFVKDLILLLKAKKQRTTTEIGFGNTPGRPNSRRQEDAGTV |
| NCBI Accession | YP_009104362.1 |
|---|---|
| Location | 290-1054 |
| Protein Name | capsid protein |
| Coding Region | ATGCCGGGACCGTTTAGTGGTAAAACCTATTCAAGGAAGAAGGGTAAATATGCCAAGGCCTACAAAGCTCTTGGTGTGAAAAATCAAAAAGAACTGGAAGAGCTGGTAAATGCGCCTGCTTGTCCAGTTACTCCTAGACCTGCCTTACAGGTTGCTGAATATTTTTGGACTACGGACAAAAATGGAATGATATTCCGCTCTGGTGGTGGTACTGCTCATTTCACTATGTATCCTCAGGGTTCAAATGAGAATTGCAGACATTCCAACCAGACTAATACCTACAAGATGGCTATTAAGTGCTGGGTTGCATTGGATCCTACGTTCTACAAGAAGGTGGCATGTGTTCCTGTGCATTTCTGGTTGGTATACGACAAAGATCCGGGTAATACACTGCCTGGATGCTCTACCATTTTTGATACTCTGTATCAAGATTACCCGGGTACATGGACTGTATCCCGGAACGTTAGTCGTCGCTTTGTAGTTAAAAAACATTGGCACATTATCTTGGCCTCTAATGGAACGAATCCAACACAAGATCAAGACCCTGCTAAGTATGCTGGACCTGGACCTGTGTTTCAATGGAAACACATGAACAAGTTTTTTAAAAGACTTGGCGTAAGGACTGATTGGAAGAACTCAGCTACAGGTGAAGTAGCTGACATTAAGAGTGGAGCATTGTACTTAGTTTGTGCACCAAGTGGTGGTGCTGTTGTAAGGGTTGGGGGTAGATTCAGAATGTACTTCAAATCCGTTGGAAATCAATAA |
| Protein Sequence | MPGPFSGKTYSRKKGKYAKAYKALGVKNQKELEELVNAPACPVTPRPALQVAEYFWTTDKNGMIFRSGGGTAHFTMYPQGSNENCRHSNQTNTYKMAIKCWVALDPTFYKKVACVPVHFWLVYDKDPGNTLPGCSTIFDTLYQDYPGTWTVSRNVSRRFVVKKHWHIILASNGTNPTQDQDPAKYAGPGPVFQWKHMNKFFKRLGVRTDWKNSATGEVADIKSGALYLVCAPSGGAVVRVGGRFRMYFKSVGNQ |
| NCBI Accession | YP_009104363.1 |
|---|---|
| Location | 1196-1609,1699-2295 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCAAGACGTACAAACAACAACTCTTTCAGACTTCAAACAAAATATGTTTTCCTTACTTATCCTCATAGCTCCTCTACTGCAGAAAATCTCAGAGATTTTCTCTGGTCCAAACTCACATCTCTTGCTATTTTTTTCATTGCTATTGCTACTGAACTTCACCAAGATGGTTCTCCCCATCTTCACTGTCTTATACAGCTTGACAAAAGATGTGATATACGGGACCCTTCTTTTTTTGATTTTGAGGGAAACCATCCAAATATCCAACCTGCTAAGAACTCAAAGCAGGTTCTTGAATACATATCCAAGGACGGGAACATCATCACCAGAGGTGACTTCAGAAACCATCGAGTCAGCCCAACCAAATCTGATGAACGATGGAGAACTATCATACAGACTGCAACATCTAAAGAGGAGTATCTGGAAATGATTAAACAAGAATTCCCCCATGAATGGGCAACTAAGCTTCACTGGCTTGAATACAGTGCAAGCAAACTCTTTCCAGATATAGAACCACCCTATCAAAGCCCATTTCCAGATGAATTTCTTCACTGCCATGAAGAAATTACTGAGTGGCTTAACAGAGACCTCTATGTTGAACCCGAACAACTCCAACTCCGGCGAAGATCCCTCTACATCTGCGGACCAAGTCGTACCGGAAAGACCAGTTGGGCCAGAAGTCTGGGAAGACACAACTACTTCAACGGAGGGGTCGATTTCACTACATACGACGTCAACGCAACATACAACGTCATCGACGACATCCCCTTCAAGTTCTGCCCCAACTGGAAGCAGTTAGTAGGGTCACAGAAGGATTTCACAGTTAACCCTAAATACGGCAAAAAGAAGAGGGTTAAAGGAGGAATCCCATGTATTATAATAGTTAATAATGATGAGGACTGGCTTGAGAGTATGTCAGATTCTCAGAGAGAATATTTTTATTTAAATTGTAAAATCCATATAATGAGTGAAGGAGAGACTTTTATTGCTTCGGCAGCGTCGAGTCACTAA |
| Protein Sequence | MPRRTNNNSFRLQTKYVFLTYPHSSSTAENLRDFLWSKLTSLAIFFIAIATELHQDGSPHLHCLIQLDKRCDIRDPSFFDFEGNHPNIQPAKNSKQVLEYISKDGNIITRGDFRNHRVSPTKSDERWRTIIQTATSKEEYLEMIKQEFPHEWATKLHWLEYSASKLFPDIEPPYQSPFPDEFLHCHEEITEWLNRDLYVEPEQLQLRRRSLYICGPSRTGKTSWARSLGRHNYFNGGVDFTTYDVNATYNVIDDIPFKFCPNWKQLVGSQKDFTVNPKYGKKKRVKGGIPCIIIVNNDEDWLESMSDSQREYFYLNCKIHIMSEGETFIASAASSH |
| NCBI Accession | YP_009104364.1 |
|---|---|
| Location | 1408-2295 |
| Protein Name | RepA |
| Coding Region | ATGCCAAGACGTACAAACAACAACTCTTTCAGACTTCAAACAAAATATGTTTTCCTTACTTATCCTCATAGCTCCTCTACTGCAGAAAATCTCAGAGATTTTCTCTGGTCCAAACTCACATCTCTTGCTATTTTTTTCATTGCTATTGCTACTGAACTTCACCAAGATGGTTCTCCCCATCTTCACTGTCTTATACAGCTTGACAAAAGATGTGATATACGGGACCCTTCTTTTTTTGATTTTGAGGGAAACCATCCAAATATCCAACCTGCTAAGAACTCAAAGCAGGTTCTTGAATACATATCCAAGGACGGGAACATCATCACCAGAGGTGACTTCAGAAACCATCGAGTCAGCCCAACCAAATCTGATGAACGATGGAGAACTATCATACAGACTGCAACATCTAAAGAGGAGTATCTGGAAATGATTAAACAAGAATTCCCCCATGAATGGGCAACTAAGCTTCACTGGCTTGAATACAGTGCAAGCAAACTCTTTCCAGATATAGAACCACCCTATCAAAGCCCATTTCCAGATGAATTTCTTCACTGCCATGAAGAAATTACTGAGTGGCTTAACAGAGACCTCTATGTTGTAAGTGTAGATTCTTATCAACTACTCCATCCACATCTTTCTTTAGAAACTGCAACTGAAGACTTGATTTGGATGGACGATTATACCAGGAACCCGAACAACTCCAACTCCGGCGAAGATCCCTCTACATCTGCGGACCAAGTCGTACCGGAAAGACCAGTTGGGCCAGAAGTCTGGGAAGACACAACTACTTCAACGGAGGGGTCGATTTCACTACATACGACGTCAACGCAACATACAACGTCATCGACGACATCCCCTTCAAGTTCTGCCCCAACTGGAAGCAGTTAG |
| Protein Sequence | MPRRTNNNSFRLQTKYVFLTYPHSSSTAENLRDFLWSKLTSLAIFFIAIATELHQDGSPHLHCLIQLDKRCDIRDPSFFDFEGNHPNIQPAKNSKQVLEYISKDGNIITRGDFRNHRVSPTKSDERWRTIIQTATSKEEYLEMIKQEFPHEWATKLHWLEYSASKLFPDIEPPYQSPFPDEFLHCHEEITEWLNRDLYVVSVDSYQLLHPHLSLETATEDLIWMDDYTRNPNNSNSGEDPSTSADQVVPERPVGPEVWEDTTTSTEGSISLHTTSTQHTTSSTTSPSSSAPTGSS |
References More References in PubMed
| 1 |
Chickpea chlorotic dwarf virus: An Emerging Monopartite Dicot Infecting Mastrevirus. Kanakala S, et al. Viruses. 2018 Dec 21;11(1):5. doi: 10.3390/v11010005. PMID: 30577666 |
|---|---|
| 2 |
Identification of New Chickpea Virus and Control of Chickpea Virus Disease. Cun Z. Evid Based Complement Alternat Med. 2022 May 28;2022:6465505. doi: 10.1155/2022/6465505. eCollection 2022. PMID: 35668786 |
| 3 |
First Report of Chickpea Chlorotic Dwarf Virus Infecting Spring Chickpea in Syria. Kumari SG, et al. Plant Dis. 2004 Apr;88(4):424. doi: 10.1094/PDIS.2004.88.4.424C. PMID: 30812628 |
| 4 |
Chickpea chlorotic stunt virus: a threat to cool-season food legumes. Abraham A, et al. Arch Virol. 2022 Jan;167(1):21-30. doi: 10.1007/s00705-021-05288-4. Epub 2021 Nov 2. PMID: 34729666 |
| 5 |
Reddy MG, et al. 3 Biotech. 2021 Mar;11(3):112. doi: 10.1007/s13205-020-02613-7. Epub 2021 Feb 3. PMID: 33598378 |
| 6 |
Tomato Yellow Leaf Curl Virus Infection in a Monocotyledonous Weed (Eleusine indica). Kil EJ, et al. Plant Pathol J. 2021 Dec;37(6):641-651. doi: 10.5423/PPJ.FT.11.2021.0162. Epub 2021 Dec 1. PMID: 34897255 |
| 7 |
Tadesse N, et al. Plant Dis. 1999 Jun;83(6):589. doi: 10.1094/PDIS.1999.83.6.589B. PMID: 30849845 |
| 8 |
Makkouk KM, et al. Virus Res. 2009 May;141(2):209-18. doi: 10.1016/j.virusres.2008.12.007. Epub 2009 Jan 17. PMID: 19152820 |
| 9 |
First Report of Beet mosaic virus Infecting Chickpea (Cicer arietinum) in Tunisia. Kumari SG, et al. Plant Dis. 2010 Aug;94(8):1068. doi: 10.1094/PDIS-94-8-1068C. PMID: 30743474 |
| 10 |
First Report of Chickpea chlorotic stunt virus Infecting Legume Crops in Tunisia. Najar A, et al. Plant Dis. 2011 Oct;95(10):1321. doi: 10.1094/PDIS-10-10-0708. PMID: 30731675 |