Chickpea redleaf virus
Basic Information
| Genus | Mastrevirus |
|---|---|
| NCBI Assembly | GCF_000890315.1 |
| Isolate | Australia |
| Release date | 2015/2/22 |
| Submitter | Thomas,J.E., Parry,J.N., Schwinghamer,M.W., Dann,E.K. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
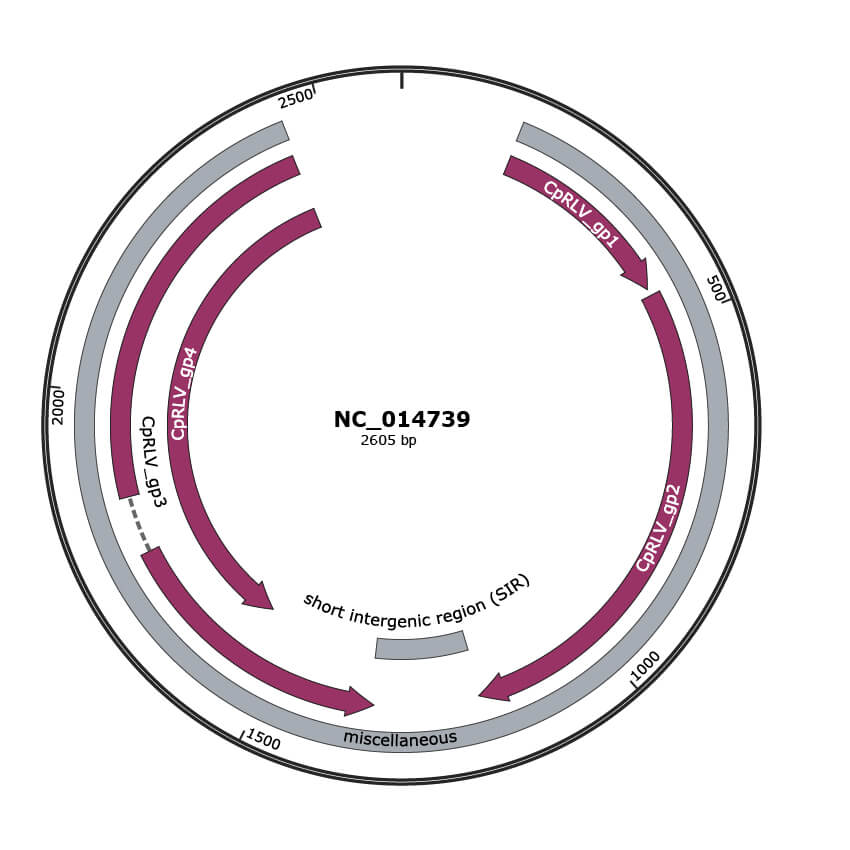
Genomic Organization
JBrowse
Genome
NC_014739
Gene Information
| NCBI Accession | YP_004046661.1 |
|---|---|
| Location | 161-442 |
| Protein Name | V2 |
| Coding Region | ATGAGAGAGAAAAAGTATCAGATATTTCCTCCGAACCCTAATTACTCTGAATTTTCCCCTCCTGTGGAAATTTCTCACGGTGAAAACTCTCAGGTTAATTTCCAGCGAGTAGTAACTGCTTTAATTGTAGTACTCGTGGCTGTAGGAGTATTGTATTTGGCGTATACCCTCTTTATTAAAGACTGTATTTTACTGTTTAAAGCGAAAAAGCAGCGAACAACGACGGAAATTGGGTTTGGACAAACCCCTGGTAGAAGCAGCGATCGTCCTCCTCAGCCTTAG |
| Protein Sequence | MREKKYQIFPPNPNYSEFSPPVEISHGENSQVNFQRVVTALIVVLVAVGVLYLAYTLFIKDCILLFKAKKQRTTTEIGFGQTPGRSSDRPPQP |
| NCBI Accession | YP_004046662.1 |
|---|---|
| Location | 453-1187 |
| Protein Name | V1 |
| Coding Region | ATGCCAGGGACGTGGGGTGGTAAGAAGAAGCGGAGTGAACGGAAGGTTGTTCCGAACTCCAAGTATGCTTCTGGTCGTATTCCCCGTAATCCCTCTGCTAAGAGGGACGCACTTCAGGTGGCTACCTTTTCCTGGACCAGTTCAGGTTCGGGAGTTAAGTTTAGTGCTGGTGGGGGTGTTTTTCTCATGACCAATTATCCTCAGGGTGCGAACGATAACTGTCGTCACACCAACTCCACTATCACCTACAAGTTGATGACCAAGAATACCGTGTTCTTGGATAGTTCAGTTTGGCCGTTGGTATGTAGGGTTCCGGTGGTGTTCTGGTTGGTGTACGACAAGTTTCCAGGTGCTTCATTACCCAGTACTGGGGATATATTTGATGGTCCTGTCCCATTCAAAAACAATCCTTGGGTCTGGACTGTTTCAAGGGCTGTGTGTCACAGGTTCGTGGTGAAGAAGACCTGGACTGTGATTCTTGAGTCTAATGGAGTTGACCCAACAAAGAAGCAGTCATCCAGTTACTATGGCCCAGGCCCATGTAACCAGTGGCGTGTATCTAATAAATTTTTTAAACGTTTAGGTGTTAGTACTGAGTGGAAGAACTCTTCCACCGGAGACGTAGGTGACATAAAAGAAGGGGCGTTGTACATAGTAGTAGCCCCTTCCCAGAGTTGTGATGTTTATGTTAATGGTTATTTCCGAGTGTATTTTAAGTCCGTTGGAAATCAATAA |
| Protein Sequence | MPGTWGGKKKRSERKVVPNSKYASGRIPRNPSAKRDALQVATFSWTSSGSGVKFSAGGGVFLMTNYPQGANDNCRHTNSTITYKLMTKNTVFLDSSVWPLVCRVPVVFWLVYDKFPGASLPSTGDIFDGPVPFKNNPWVWTVSRAVCHRFVVKKTWTVILESNGVDPTKKQSSSYYGPGPCNQWRVSNKFFKRLGVSTEWKNSSTGDVGDIKEGALYIVVAPSQSCDVYVNGYFRVYFKSVGNQ |
| NCBI Accession | YP_004046663.1 |
|---|---|
| Location | 1344-1762,1849-2446 |
| Protein Name | C1:C2 |
| Coding Region | ATGCCTCGTCTTAACAAAAAAACCTCAAACTTCCGTTTTCAATCTAAATATGTCTTCCTTACTTATCCTCATTGCAACTCAAACCCAGAGGCTCTACGAGATTACCTCTGGGAAAAACTTACACGTTTTATTATTTTTTTTATTGCTGTTGCTTCTGAAGTTCATCAAGATGGTTCTCCCCATCTTCACTGTCTTATCCAGCTTACTAATAAACCTAACATATCTGATGCTTCTTTTTTTGATTTTGAGGGAAACCACCCTAATATACAACCAGCTAGAAATTCTGAACAAGTCCTTGACTATATATCTAAGGACGGAAACATCATCACCAAGGGGGAGTTCAAAAAACACAGAGTCTCCCCCACAAAACATGATGAGCGATGGAGAACTATCATCAACACTGCAACGTCTAAGGAACACTATCTGGGAATGATAAGAGACCAATTCCCACATGAATGGGCCTCAAAGCTTCAATGGTTTGAATACAGCGCCAATAAGCTATTCCCTGATGTAGAGCCTCCATACCAGAGTCCATTCCCAGAGGCCTCCCTTCAATGCCACGAAGAAATACAAGACTGGCTAAACAGAGACCTGTACCACCAGGAACCCGAACAACTCAGACATAGAAGGAAGTCCCTCTACATATGTGGACCAACCAGAACAGGAAAGACATCCTGGGCAAGGTCTCTCGGGAGGCACAACTACTTCAACGGAGGAGTGGACTTCACAACCTACGACGAACAGGCAGCATACAACATCATCGACGACATCCCATTCAAGTTCTGCCCGAACTGGAAACAATTAGTGGGTTCACAGTTGGATTTCACTGTGAACCCTAAGTACGGCAAAAAAAGAAGAATAAAGGGAGGGGTTCCATGTATAATCTTAGTTAATAATGATGATGATTGGATGAAAGATATGTCTTCACATCAGAAAGAATACTTTCAACACAACTGTATGATCCATTACATGGACGAAGGAGAGACGTTTATTGCTCCTGTGTCGTCGAGTCACTGA |
| Protein Sequence | MPRLNKKTSNFRFQSKYVFLTYPHCNSNPEALRDYLWEKLTRFIIFFIAVASEVHQDGSPHLHCLIQLTNKPNISDASFFDFEGNHPNIQPARNSEQVLDYISKDGNIITKGEFKKHRVSPTKHDERWRTIINTATSKEHYLGMIRDQFPHEWASKLQWFEYSANKLFPDVEPPYQSPFPEASLQCHEEIQDWLNRDLYHQEPEQLRHRRKSLYICGPTRTGKTSWARSLGRHNYFNGGVDFTTYDEQAAYNIIDDIPFKFCPNWKQLVGSQLDFTVNPKYGKKRRIKGGVPCIILVNNDDDWMKDMSSHQKEYFQHNCMIHYMDEGETFIAPVSSSH |
| NCBI Accession | YP_004046664.1 |
|---|---|
| Location | 1556-2446 |
| Protein Name | C1 |
| Coding Region | ATGCCTCGTCTTAACAAAAAAACCTCAAACTTCCGTTTTCAATCTAAATATGTCTTCCTTACTTATCCTCATTGCAACTCAAACCCAGAGGCTCTACGAGATTACCTCTGGGAAAAACTTACACGTTTTATTATTTTTTTTATTGCTGTTGCTTCTGAAGTTCATCAAGATGGTTCTCCCCATCTTCACTGTCTTATCCAGCTTACTAATAAACCTAACATATCTGATGCTTCTTTTTTTGATTTTGAGGGAAACCACCCTAATATACAACCAGCTAGAAATTCTGAACAAGTCCTTGACTATATATCTAAGGACGGAAACATCATCACCAAGGGGGAGTTCAAAAAACACAGAGTCTCCCCCACAAAACATGATGAGCGATGGAGAACTATCATCAACACTGCAACGTCTAAGGAACACTATCTGGGAATGATAAGAGACCAATTCCCACATGAATGGGCCTCAAAGCTTCAATGGTTTGAATACAGCGCCAATAAGCTATTCCCTGATGTAGAGCCTCCATACCAGAGTCCATTCCCAGAGGCCTCCCTTCAATGCCACGAAGAAATACAAGACTGGCTAAACAGAGACCTGTACCTGGTAAGCGTCGAAGCTTACACTCTTATACATCCAAATTTAAACACTCAAACTGCAACTGAAGACCTTATTTGGATGGACCATTACACCAGGAACCCGAACAACTCAGACATAGAAGGAAGTCCCTCTACATATGTGGACCAACCAGAACAGGAAAGACATCCTGGGCAAGGTCTCTCGGGAGGCACAACTACTTCAACGGAGGAGTGGACTTCACAACCTACGACGAACAGGCAGCATACAACATCATCGACGACATCCCATTCAAGTTCTGCCCGAACTGGAAACAATTAG |
| Protein Sequence | MPRLNKKTSNFRFQSKYVFLTYPHCNSNPEALRDYLWEKLTRFIIFFIAVASEVHQDGSPHLHCLIQLTNKPNISDASFFDFEGNHPNIQPARNSEQVLDYISKDGNIITKGEFKKHRVSPTKHDERWRTIINTATSKEHYLGMIRDQFPHEWASKLQWFEYSANKLFPDVEPPYQSPFPEASLQCHEEIQDWLNRDLYLVSVEAYTLIHPNLNTQTATEDLIWMDHYTRNPNNSDIEGSPSTYVDQPEQERHPGQGLSGGTTTSTEEWTSQPTTNRQHTTSSTTSHSSSARTGNN |
References More References in PubMed
| 1 |
Identification of New Chickpea Virus and Control of Chickpea Virus Disease. Cun Z. Evid Based Complement Alternat Med. 2022 May 28;2022:6465505. doi: 10.1155/2022/6465505. eCollection 2022. PMID: 35668786 |
|---|---|
| 2 |
Complete Genome Sequence of a New Mastrevirus, Chickpea Redleaf Virus 2, from Australia. Filardo FF, et al. Microbiol Resour Announc. 2019 Sep 5;8(36):e00602-19. doi: 10.1128/MRA.00602-19. PMID: 31488527 |
| 3 |
Two novel mastreviruses from chickpea (Cicer arietinum) in Australia. Thomas JE, et al. Arch Virol. 2010 Nov;155(11):1777-88. doi: 10.1007/s00705-010-0763-4. Epub 2010 Aug 24. PMID: 20734091 |