Chickpea chlorotic dwarf virus
Basic Information
| Genus | Mastrevirus |
|---|---|
| NCBI Assembly | GCF_000880315.1 |
| Isolate | Pakistan:Layyah |
| Release date | 2015/2/22 |
| Submitter | Nahid,N., Amin,I., Mansoor,S., Rybicki,E.P., van der Walt,E., Briddon,R.W. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
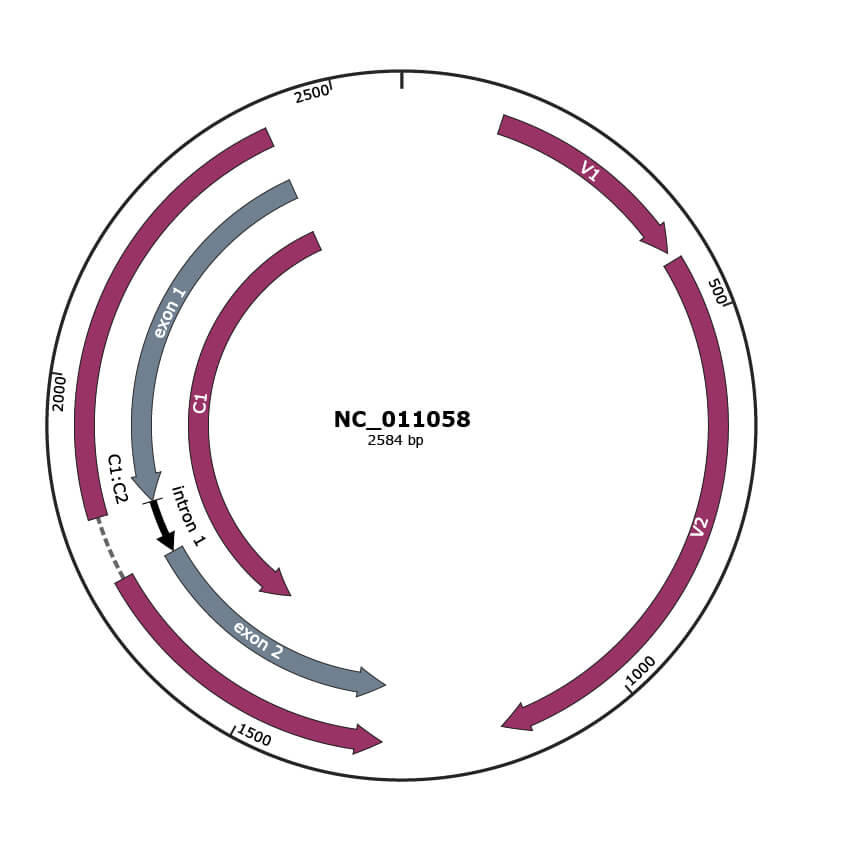
Genomic Organization
JBrowse
Genome
NC_011058
Gene Information
| NCBI Accession | YP_002014710.1 |
|---|---|
| Location | 132-410 |
| Gene Name | V1 |
| Protein Name | movement protein |
| Coding Region | ATGGAACGTATTCTGTATCAGGTATTTCCTACGGATACGAATTATTCGTACGATCCTCCTCCTGTGAATACGAATTCCCAGGGATCCTCTCAAACGGATTTCGGGAAGGTGGTTATCGCCTTGGTGGTTATTCTGGTTAGTGTTGGTGTGTTCTATCTGGCTTATAGTCTGTTCTTGAAGGATTGTATCCTTCTGTTCAAGGCGAAGAAGCAGAGGACCACCACTGAAATCGGGTTTGGTCAAACCCCGGCTAGAAACCAGGATCATCCTCAACCTTAG |
| Protein Sequence | MERILYQVFPTDTNYSYDPPPVNTNSQGSSQTDFGKVVIALVVILVSVGVFYLAYSLFLKDCILLFKAKKQRTTTEIGFGQTPARNQDHPQP |
| NCBI Accession | YP_002014711.1 |
|---|---|
| Location | 423-1160 |
| Gene Name | V2 |
| Protein Name | coat protein |
| Coding Region | ATGTCAACTGTGACGTGGGGAAACAAGAGGAAGCGCAGCGATAGGTCCTCGAAGGCGAAGAGTAAGTCCTCTGGGTCTTATGTTCCCAGATCTGTGTCTTCCAGGAGGGAATCGTTGCAGGTGGCTACCTTTTCCTGGACCAGTTCTGGTTCGGGTATCAAGTTCTCTACTGGTGGTGCTGCCTACCTTGTGAGTAATTTTCCACAGGGTGCCAACGATAACTGTCGTCACACCAACAAGACCGTGCTATACAAATTCATGGCCAAGAATACGGTGTACTTGGACCCTAGTCATTATCCTAAGGTCTTTAAGTGCCCGTTTACTTTTTGGCTGGTGTACGACAAGGCTCCTGGTGCAAGTGTCCCTAGTACTGGGGACATATTTGAAGGCCCCTCTCTATTCCCTGCTAATCCCTGGACGTGGACTGTGTCTAGGGCTGCTTGCCATCGATTTGTTGTTAAAAAAACGTGGTCAGTGGTGGTGGAGAGCAATGGTGTTGATCCAGGAAAGGCCCAATCCAGTTCCTATTATGGGCCTGGACCTTGTAATCAGATTAAGTCCTGCAATAAGTTCTTTAAGAGGCTGGGTGTGTCAACGGAGTGGAAAAATAGTTCCACGGGGGATGTTGGTGATATAAAGGAAGGAGCCCTTTACATTGTAGGTGCTCCTTCCCAGAAGTCTGATGTATATGTAAATGGTTATTTCCGAGTGTACTTCAAGTCCGTTGGCAATCAATAA |
| Protein Sequence | MSTVTWGNKRKRSDRSSKAKSKSSGSYVPRSVSSRRESLQVATFSWTSSGSGIKFSTGGAAYLVSNFPQGANDNCRHTNKTVLYKFMAKNTVYLDPSHYPKVFKCPFTFWLVYDKAPGASVPSTGDIFEGPSLFPANPWTWTVSRAACHRFVVKKTWSVVVESNGVDPGKAQSSSYYGPGPCNQIKSCNKFFKRLGVSTEWKNSSTGDVGDIKEGALYIVGAPSQKSDVYVNGYFRVYFKSVGNQ |
| NCBI Accession | YP_002014712.1 |
|---|---|
| Location | 1318-1731,1818-2408 |
| Gene Name | C1:C2 |
| Protein Name | Rep A protein |
| Coding Region | ATGCCTTCTGCAAACAAGAACTTCAGATTCCAATCAAAATATGTTTTCCTTACCTACCCTAAATGCTCATCTCCAAGAGATGATTTATTCGAGTTTCTCTGGGAGAAACTCACACCTTTTCTTATTTTCTTCCTTGGTGTTGCTACTGAGCTTCATCAAGATGGCACTACCCACTATCATGCTCTTGTCCAGCTTGATAAAAAACCTTGGATTAGGGATCCTTCTTTTTTCGATTTTGAAGGAAATCACCCTAATATCCAACCAGCTAGAAACTCTAAACAAGTCCTTGAATACATTTCCAAGGACGGAGATATTAAAACAAGAGGAGATTTCAGAGATCATAAAGTCTCTCCTCGCAAATCTGACGCACGATGGCGAACTATTATCCAGACTGCAACGTCTAAGGAGGAATATCTTGACATGATCAAGGAGGAGTTCCCCCATGAATGGACTACCAAGCTTCAATGGCTTGAATACTCCGCAAACAAGCTATTCCCTCCACAACCTGAAGCATATGTGTCGCCGTTCACTGAGTCAGATCTCCGCTGCCACGAGGATCTAGCACAATGGAGGGATACACACCTGTACCAAGAACCGAGAAGGACTGGAGCTAGAGTCCCCAGCCTCTACATCTGCGGACCAACTCGTACCGGAAAGACCACCTGGGCTAGAAGCCTCGGACGACACAACTACTGGAATGGGACCATCGACTTCACCACGTACGACGAACACGCGACCTACAATGTCATTGACGACATCCCCTTCAAGTTCGTCCCATTGTGGAAGCAATTAATAGGTTGCCAGTTCGACTTCACTGTCAACCCTAAGTATGGAAAAAAGAAGAAAATAAAAGGTGGTGTCCCTTCCATAATTTTAACAAATAGAGATGAGGACTGGATCCCTGCTATGTCTGAGCATCAGAAAGAATACTTTACAGACAATTGTGAGATCCATTATATGGATGACGGCGAAACTTTTTTTGCCCGGGAATCGTCGAGTCACTGA |
| Protein Sequence | MPSANKNFRFQSKYVFLTYPKCSSPRDDLFEFLWEKLTPFLIFFLGVATELHQDGTTHYHALVQLDKKPWIRDPSFFDFEGNHPNIQPARNSKQVLEYISKDGDIKTRGDFRDHKVSPRKSDARWRTIIQTATSKEEYLDMIKEEFPHEWTTKLQWLEYSANKLFPPQPEAYVSPFTESDLRCHEDLAQWRDTHLYQEPRRTGARVPSLYICGPTRTGKTTWARSLGRHNYWNGTIDFTTYDEHATYNVIDDIPFKFVPLWKQLIGCQFDFTVNPKYGKKKKIKGGVPSIILTNRDEDWIPAMSEHQKEYFTDNCEIHYMDDGETFFARESSSH |
| NCBI Accession | YP_002014713.1 |
|---|---|
| Location | 1530-2408 |
| Gene Name | C1 |
| Protein Name | Rep protein |
| Coding Region | ATGCCTTCTGCAAACAAGAACTTCAGATTCCAATCAAAATATGTTTTCCTTACCTACCCTAAATGCTCATCTCCAAGAGATGATTTATTCGAGTTTCTCTGGGAGAAACTCACACCTTTTCTTATTTTCTTCCTTGGTGTTGCTACTGAGCTTCATCAAGATGGCACTACCCACTATCATGCTCTTGTCCAGCTTGATAAAAAACCTTGGATTAGGGATCCTTCTTTTTTCGATTTTGAAGGAAATCACCCTAATATCCAACCAGCTAGAAACTCTAAACAAGTCCTTGAATACATTTCCAAGGACGGAGATATTAAAACAAGAGGAGATTTCAGAGATCATAAAGTCTCTCCTCGCAAATCTGACGCACGATGGCGAACTATTATCCAGACTGCAACGTCTAAGGAGGAATATCTTGACATGATCAAGGAGGAGTTCCCCCATGAATGGACTACCAAGCTTCAATGGCTTGAATACTCCGCAAACAAGCTATTCCCTCCACAACCTGAAGCATATGTGTCGCCGTTCACTGAGTCAGATCTCCGCTGCCACGAGGATCTAGCACAATGGAGGGATACACACCTGTACCAAGTAAGCATCGACGCCTACACTCTTGTCCATCCAGTTTCATATCAGCAAGCTCAATCTGACCTTGAATGGATGGCCGATCTAACCAGGAACCGAGAAGGACTGGAGCTAGAGTCCCCAGCCTCTACATCTGCGGACCAACTCGTACCGGAAAGACCACCTGGGCTAGAAGCCTCGGACGACACAACTACTGGAATGGGACCATCGACTTCACCACGTACGACGAACACGCGACCTACAATGTCATTGACGACATCCCCTTCAAGTTCGTCCCATTGTGGAAGCAATTAA |
| Protein Sequence | MPSANKNFRFQSKYVFLTYPKCSSPRDDLFEFLWEKLTPFLIFFLGVATELHQDGTTHYHALVQLDKKPWIRDPSFFDFEGNHPNIQPARNSKQVLEYISKDGDIKTRGDFRDHKVSPRKSDARWRTIIQTATSKEEYLDMIKEEFPHEWTTKLQWLEYSANKLFPPQPEAYVSPFTESDLRCHEDLAQWRDTHLYQVSIDAYTLVHPVSYQQAQSDLEWMADLTRNREGLELESPASTSADQLVPERPPGLEASDDTTTGMGPSTSPRTTNTRPTMSLTTSPSSSSHCGSN |
References More References in PubMed
| 1 |
Chickpea chlorotic dwarf virus: An Emerging Monopartite Dicot Infecting Mastrevirus. Kanakala S, et al. Viruses. 2018 Dec 21;11(1):5. doi: 10.3390/v11010005. PMID: 30577666 |
|---|---|
| 2 |
Pest categorisation of chickpea chlorotic dwarf virus. EFSA Panel on Plant Health (PLH), et al. EFSA J. 2022 Nov 15;20(11):e07625. doi: 10.2903/j.efsa.2022.7625. eCollection 2022 Nov. PMID: 36398295 |
| 3 |
Identification of New Chickpea Virus and Control of Chickpea Virus Disease. Cun Z. Evid Based Complement Alternat Med. 2022 May 28;2022:6465505. doi: 10.1155/2022/6465505. eCollection 2022. PMID: 35668786 |
| 4 |
Rashid K, et al. Cell Mol Biol (Noisy-le-grand). 2019 Sep 30;65(7):34-37. PMID: 31880515 |
| 5 |
First Report of Chickpea Chlorotic Dwarf Virus Infecting Spring Chickpea in Syria. Kumari SG, et al. Plant Dis. 2004 Apr;88(4):424. doi: 10.1094/PDIS.2004.88.4.424C. PMID: 30812628 |
| 6 |
Reddy MG, et al. 3 Biotech. 2021 Mar;11(3):112. doi: 10.1007/s13205-020-02613-7. Epub 2021 Feb 3. PMID: 33598378 |
| 7 |
Invasion of previously unreported dicot plant hosts by chickpea chlorotic dwarf virus in Pakistan. Hameed U, et al. Virusdisease. 2019 Mar;30(1):95-100. doi: 10.1007/s13337-018-0454-4. Epub 2018 May 25. PMID: 31143836 |
| 8 |
First Report of Chickpea chlorotic dwarf virus Infecting Hot Pepper in India. Byun HS, et al. Plant Dis. 2014 Nov;98(11):1590. doi: 10.1094/PDIS-05-14-0440-PDN. PMID: 30699800 |
| 9 |
Kraberger S, et al. Infect Genet Evol. 2015 Jan;29:203-15. doi: 10.1016/j.meegid.2014.11.024. Epub 2014 Nov 29. PMID: 25444941 |
| 10 |
Reddy MG, et al. 3 Biotech. 2022 Jan;12(1):23. doi: 10.1007/s13205-021-03094-y. Epub 2021 Dec 22. PMID: 35036271 |