Chickpea chlorosis virus
Basic Information
| Genus | Mastrevirus |
|---|---|
| NCBI Assembly | GCF_000887795.1 |
| Isolate | Australia |
| Release date | 2015/2/22 |
| Submitter | Thomas,J.E., Parry,J.N., Schwinghamer,M.W., Dann,E.K. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
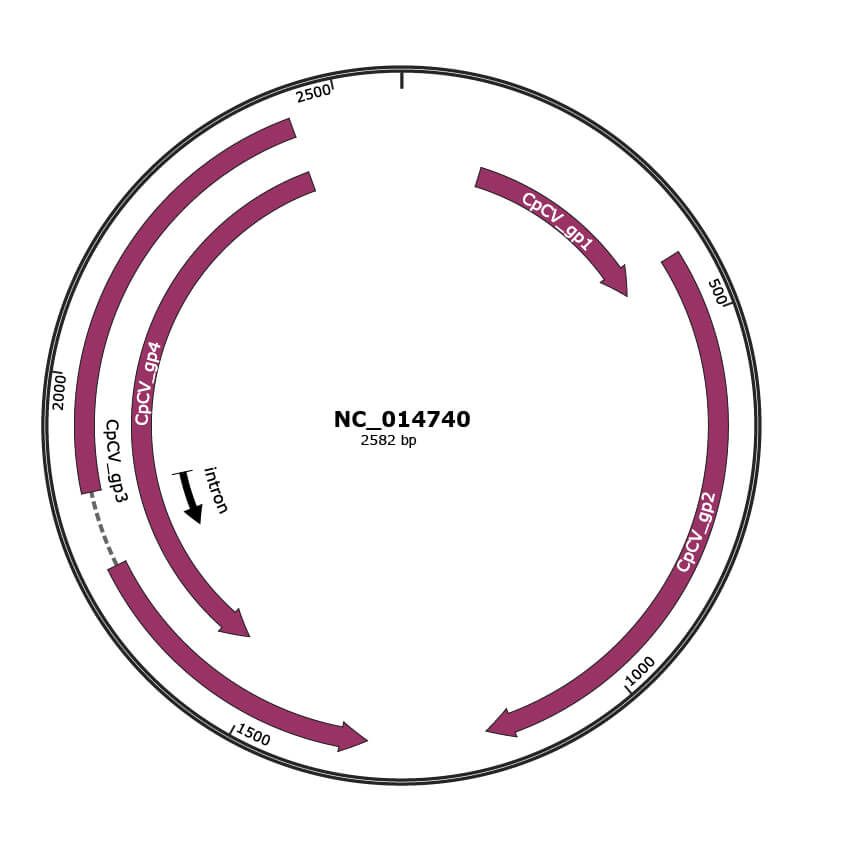
JBrowse
Genome
NC_014740
Gene Information
| NCBI Accession | YP_004046665.1 |
|---|---|
| Location | 124-432 |
| Protein Name | V2 |
| Coding Region | ATGTTAGGCGCCTACTATCAAATATTCCCTTCTGAGGAAAATTACTCTTATACCCCTGTTCAGACGCAGGAGTCTTTTTCTGGCGCGAAAGCAGGTGATTCATCCGAGCACGTATTTTCGAAAGTCGTCGTTGCTTTAATTATTATTCTTTTTTCAGTGGGAATCATTTATCTTGCCTATTCTTTATTTTTAAAAGATTTGATATTATTATTAAAGGCGAAAAAGCAGAGGACGACGACTGAGATAGGGTTTGGTAATACCCCTGGTAGACCCGGTTCTCAACCTCAGCAAAATGTCGGGCCGATTTAA |
| Protein Sequence | MLGAYYQIFPSEENYSYTPVQTQESFSGAKAGDSSEHVFSKVVVALIIILFSVGIIYLAYSLFLKDLILLLKAKKQRTTTEIGFGNTPGRPGSQPQQNVGPI |
| NCBI Accession | YP_004046666.1 |
|---|---|
| Location | 416-1180 |
| Protein Name | V1 |
| Coding Region | ATGTCGGGCCGATTTAAGGGACAAGTGTACAGCAGGAAAAGGGGTCGTAATGCAAAGGCGTATCAGGCTCTGGGAGTTAAATCTCAACGGGAGTTGGAGCAGTTAGTTAACCAACCAGGACGTCCTATTGGTAATAGGCGTCCGTCACTGCAGGTCGCAGAGTATCTGTGGACGACCAACAAGGCTGGTGTGACGTTCTCGCCTGGTGGGGGAACTTATTTGTTCACTAATTACCCTCAAGGGGCGAACGAGAACTGCAGGCACACTAACCGGACCATAACGTACAAGATGGCTATCAAGTGTTGGGTTGCCTTGGATGGGTCTATGGTGGCTAGGGTTGCAAAGTTTCCAGTCCACTTCTGGTTAGTGTACGACAAGAACCCTGGTGATACGAATCCTTCTCCATCGGCTATTTTTGATAGTCTCTATCAAGATCAGCCTGGGACTTGGACTGTAACGAGGAATGTGTGTCATAGGTTTGTCGTTAAAAAGTCTTGGTCCGTGATGCTGGAGTCTAATGGGATTGATCCCAGTAAGTCTCAGTCCACATCATATTATGGGCCTGGGCCTTGTTATAATTGGAGGCACATGACCAAATTTTTTAAACGTTTAGGAGTTAGTACTGAGTGGAAGAATTCTTCCACTGGTGATGTTGCTGATATTAAGGAAGGAGCACTATACCTTGTATGTGCTCCTGGTGGTGGTGTTACTGTAAGAGTTGGCGGTAGATTCCGCATGTATTTCAAATCCGTTGGCAATCAATAA |
| Protein Sequence | MSGRFKGQVYSRKRGRNAKAYQALGVKSQRELEQLVNQPGRPIGNRRPSLQVAEYLWTTNKAGVTFSPGGGTYLFTNYPQGANENCRHTNRTITYKMAIKCWVALDGSMVARVAKFPVHFWLVYDKNPGDTNPSPSAIFDSLYQDQPGTWTVTRNVCHRFVVKKSWSVMLESNGIDPSKSQSTSYYGPGPCYNWRHMTKFFKRLGVSTEWKNSSTGDVADIKEGALYLVCAPGGGVTVRVGGRFRMYFKSVGNQ |
| NCBI Accession | YP_004046667.1 |
|---|---|
| Location | 1336-1749,1851-2438 |
| Protein Name | C1:C2 |
| Coding Region | ATGCCTTCTTCTTCAAAACGACAAAACAACTTCCGTCTACAAACCAAATATGTTTTTCTTACTTATCCCCATTGCAGCTCTACTGCAACAAGCCTCAGAGACTTTCTCTGGGAAAAACTCTCACGTTTTGCTATTTTCTTTATTGCTGTTGCTACTGAGCTCCATCAAGATGGTACTCCCCATCTTCACTGTCTTCTTCAGCTTGATAAAAGAGGGGATATACGTGACCCTTCTTTTTTTGATTTTGAAGGAAACCATCCAAATATCCAACCAGCTAAAAATTCTGAACAAGTCCTTGATTACATATCAAAGGATGGAAACGTCATCACGAGAGGAGACTTTCGAAAACACAAGGTCTCCCCAACTAAACATGATGAACGATGGCGAACTATTATCCAGACTGCAACAACTAAGGAGGAGTATTTGAGAATGATTAGGGATCAGTTCCCTCATGAATGGGCGACCAAACTACAATGGCTTGAATATAGCGCCAATAAACTGTTCCCAGATATAGAGCCTCCATATGAAAACCCCTTCTCCCCCATTGATCTTCAGTGCCACGAAGAAATACAGGAGTGGCTGAACAGAGAACCCGAACAACTCCAACACCGAAGGAACTCCCTCTACATCTGCGGACCAACTCGTACCGGAAAGACCAGCTGGGCCCGCAGTCTCGGCAGACACAACTACTTCAACGGAGGAGTGGACTTCACCACGTACGACATTAACGCCACCTACAATATCGTCGACGACATCCCCTTCAAGTTCTGCCCAAACTGGAAGCAACTAGTGGGTTCCCAGAAGGACTTCACCGTAAATCCAAAATACGGCAAAAAGAAGAGGATCAAAGGGGGAATACCATGTATTATATTAGTTAATAATGACGACGACTGGTTATTAGATATGTCTTCCTCTCAGAAGGAATACTTTGAATCCAACTGCAAGATCCATTATATGTATAGCGGCGAGACATTTATTGCTCCTGAATCGTCGAGTCACTGA |
| Protein Sequence | MPSSSKRQNNFRLQTKYVFLTYPHCSSTATSLRDFLWEKLSRFAIFFIAVATELHQDGTPHLHCLLQLDKRGDIRDPSFFDFEGNHPNIQPAKNSEQVLDYISKDGNVITRGDFRKHKVSPTKHDERWRTIIQTATTKEEYLRMIRDQFPHEWATKLQWLEYSANKLFPDIEPPYENPFSPIDLQCHEEIQEWLNREPEQLQHRRNSLYICGPTRTGKTSWARSLGRHNYFNGGVDFTTYDINATYNIVDDIPFKFCPNWKQLVGSQKDFTVNPKYGKKKRIKGGIPCIILVNNDDDWLLDMSSSQKEYFESNCKIHYMYSGETFIAPESSSH |
| NCBI Accession | YP_004046668.1 |
|---|---|
| Location | 1548-2438 |
| Protein Name | C1 |
| Coding Region | ATGCCTTCTTCTTCAAAACGACAAAACAACTTCCGTCTACAAACCAAATATGTTTTTCTTACTTATCCCCATTGCAGCTCTACTGCAACAAGCCTCAGAGACTTTCTCTGGGAAAAACTCTCACGTTTTGCTATTTTCTTTATTGCTGTTGCTACTGAGCTCCATCAAGATGGTACTCCCCATCTTCACTGTCTTCTTCAGCTTGATAAAAGAGGGGATATACGTGACCCTTCTTTTTTTGATTTTGAAGGAAACCATCCAAATATCCAACCAGCTAAAAATTCTGAACAAGTCCTTGATTACATATCAAAGGATGGAAACGTCATCACGAGAGGAGACTTTCGAAAACACAAGGTCTCCCCAACTAAACATGATGAACGATGGCGAACTATTATCCAGACTGCAACAACTAAGGAGGAGTATTTGAGAATGATTAGGGATCAGTTCCCTCATGAATGGGCGACCAAACTACAATGGCTTGAATATAGCGCCAATAAACTGTTCCCAGATATAGAGCCTCCATATGAAAACCCCTTCTCCCCCATTGATCTTCAGTGCCACGAAGAAATACAGGAGTGGCTGAACAGAGACCTGTACGTGGTAAGCGTCGATGCTTACACTTTAATTCATCCAAATATCAATTACCAAACAGCAACTGAAGATTTGATATGGATGGATCATTTTACCAGGAACCCGAACAACTCCAACACCGAAGGAACTCCCTCTACATCTGCGGACCAACTCGTACCGGAAAGACCAGCTGGGCCCGCAGTCTCGGCAGACACAACTACTTCAACGGAGGAGTGGACTTCACCACGTACGACATTAACGCCACCTACAATATCGTCGACGACATCCCCTTCAAGTTCTGCCCAAACTGGAAGCAACTAG |
| Protein Sequence | MPSSSKRQNNFRLQTKYVFLTYPHCSSTATSLRDFLWEKLSRFAIFFIAVATELHQDGTPHLHCLLQLDKRGDIRDPSFFDFEGNHPNIQPAKNSEQVLDYISKDGNVITRGDFRKHKVSPTKHDERWRTIIQTATTKEEYLRMIRDQFPHEWATKLQWLEYSANKLFPDIEPPYENPFSPIDLQCHEEIQEWLNRDLYVVSVDAYTLIHPNINYQTATEDLIWMDHFTRNPNNSNTEGTPSTSADQLVPERPAGPAVSADTTTSTEEWTSPRTTLTPPTISSTTSPSSSAQTGSN |
References More References in PubMed
| 1 |
Identification of New Chickpea Virus and Control of Chickpea Virus Disease. Cun Z. Evid Based Complement Alternat Med. 2022 May 28;2022:6465505. doi: 10.1155/2022/6465505. eCollection 2022. PMID: 35668786 |
|---|---|
| 2 |
Zhou CJ, et al. Arch Virol. 2012 Jul;157(7):1393-6. doi: 10.1007/s00705-012-1301-3. Epub 2012 Apr 3. PMID: 22476900 |
| 3 |
Two novel mastreviruses from chickpea (Cicer arietinum) in Australia. Thomas JE, et al. Arch Virol. 2010 Nov;155(11):1777-88. doi: 10.1007/s00705-010-0763-4. Epub 2010 Aug 24. PMID: 20734091 |
| 4 |
Fahmy IF, et al. Virusdisease. 2015 Jun;26(1-2):33-41. doi: 10.1007/s13337-014-0246-4. Epub 2015 Feb 14. PMID: 26436119 |
| 5 |
Viromes of Ten Alfalfa Plants in Australia Reveal Diverse Known Viruses and a Novel RNA Virus. Samarfard S, et al. Pathogens. 2020 Mar 13;9(3):214. doi: 10.3390/pathogens9030214. PMID: 32183134 |
| 6 |
First Report of Red Clover Vein Mosaic Carlavirus Naturally Infecting Lentil. Larsen RC, et al. Plant Dis. 1998 Sep;82(9):1064. doi: 10.1094/PDIS.1998.82.9.1064A. PMID: 30856843 |
| 7 |
First Report of Bean Leafroll Luteovirus Infecting Pea in Italy. Larsen RC, et al. Plant Dis. 1999 Apr;83(4):399. doi: 10.1094/PDIS.1999.83.4.399B. PMID: 30845604 |