Grapevine geminivirus A
Basic Information
| Genus | Maldovirus |
|---|---|
| NCBI Assembly | GCF_001766605.1 |
| Isolate | Israel |
| Release date | 2016/10/15 |
| Submitter | Al Rwahnih,M., Alabi,O.J., Westrick,N.M., Golino,D., Rowhani,A., Alabi,O., Westrick,N. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
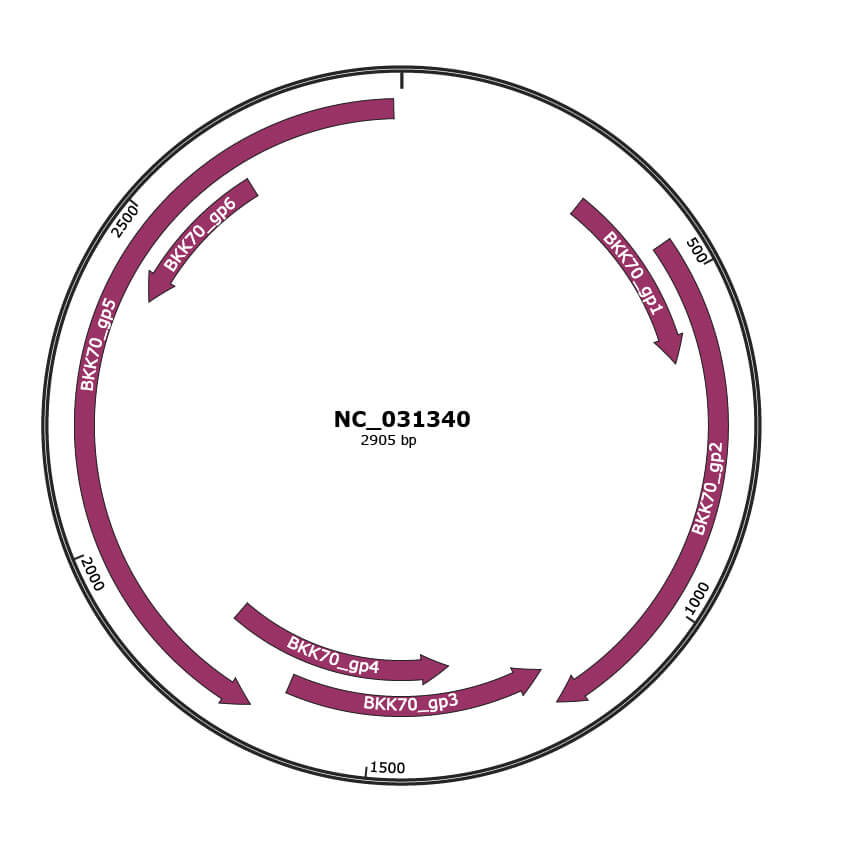
Genomic Organization
JBrowse
Genome
NC_031340
Gene Information
| NCBI Accession | YP_009305424.1 |
|---|---|
| Location | 313-624 |
| Protein Name | Pre-CP/V2 |
| Coding Region | ATGTGGTTGGTGTTTATGGATCGCCTCTATTCATCGTTCCAAGATAAGAGGCTTCATCCTGCTGAAATATTGCCTCACGTGACCCAGTGGATCTGTGAGAAGGGAACGGCCCAACAACTCATAGATTGGATCCATGGACTTCAATCCGAGAAAGAGGAAATCTTTCGCACCCTTGACGCCTGCTCAGTTGGCCCGTCAGAGGAGATGGAGGGCTTTGGTGGCCCAAGGGGCCAAGAGAAGGTTGACCTATCCCTCACTTTATCGTCCCCAACTGATGAACGTCCGCAGGTCAAGTCAGTCAGTATATCCTGA |
| Protein Sequence | MWLVFMDRLYSSFQDKRLHPAEILPHVTQWICEKGTAQQLIDWIHGLQSEKEEIFRTLDACSVGPSEEMEGFGGPRGQEKVDLSLTLSSPTDERPQVKSVSIS |
| NCBI Accession | YP_009305425.1 |
|---|---|
| Location | 446-1216 |
| Protein Name | CP/V1 |
| Coding Region | ATGGACTTCAATCCGAGAAAGAGGAAATCTTTCGCACCCTTGACGCCTGCTCAGTTGGCCCGTCAGAGGAGATGGAGGGCTTTGGTGGCCCAAGGGGCCAAGAGAAGGTTGACCTATCCCTCACTTTATCGTCCCCAACTGATGAACGTCCGCAGGTCAAGTCAGTCAGTATATCCTGACAAGGGATACCATGATGACGAGGACCATTGGGAAGGGTTCACCATGTCTGAGGGTAAGGCTACCTATGTATCTATGCCTCATTTGGGCCAGGGTGCTAGTCAACGTCATACCAGTAAGATCAAGTTGTGGTCCATATCTGTTCGTGGGTCACTACATGTTTTAAATTGTACTAATCCGGAGACGATCTCGGCCCAAGTCATTTTGGTTTGGGCCCATAGGCCCGAAGGTGGATCTGTTCCAGGCTTTTATGATCTGTTTACTGGTGGAGGGAGTATGAATGATCAGCATAACCCCACATGTGCGAAGCTCAAGCATTCGATGACCAAGTCCTACCACGTGCTGAGTCGTCGCACGTTCCAATTGACTCCGTATACGACATATTCATCTGGTCGTAATCGAGTCAATTTTCAGATATACAAGGTATTCCGAGGTCGGAATACAAAATATGTAACCTTTGGTGAAGACAGTACTGGAGGCTCCTACTCTGATATTAAGTATGGAGGCCTGTTTTATTTTATTAGGTTTATTAGTTCGGATGCAGGTGCAAAATTAGAAGGAGATTGGAATTGTAGAATAATATATTATCATTAA |
| Protein Sequence | MDFNPRKRKSFAPLTPAQLARQRRWRALVAQGAKRRLTYPSLYRPQLMNVRRSSQSVYPDKGYHDDEDHWEGFTMSEGKATYVSMPHLGQGASQRHTSKIKLWSISVRGSLHVLNCTNPETISAQVILVWAHRPEGGSVPGFYDLFTGGGSMNDQHNPTCAKLKHSMTKSYHVLSRRTFQLTPYTTYSSGRNRVNFQIYKVFRGRNTKYVTFGEDSTGGSYSDIKYGGLFYFIRFISSDAGAKLEGDWNCRIIYYH |
| NCBI Accession | YP_009305426.1 |
|---|---|
| Location | 1213-1641 |
| Protein Name | Ren/C3 |
| Coding Region | ATGCCTGTCGGCCATGTCAGGGTGTTGGATTCACGCACCGGGGAGTCACTTACATCGCAGCAAACCCAGACAGGAGTATACTCATGGACTTTGAAGAATCCTCTGTATGTAACGATCATACAGAGTTGGGACATATTCCTTCCCAAAGGGAAGGGATTCAAGATACAGTTCAGAGCAAATCACAACATGAGGAAAGCTTTGGGGCTACACAAATGCTGGATAACATACAGGGTCTGGACGACCTTGAAAACATTTGGGCTGATCTCTTTACAAATTAGAATTAGGGATAGAATTTTAAGTTACTTCGATTCTGTTGGTGTAATTTCATGTAAAACATTAGCATTAGGTATTAATGAATTTATGTTAAAATCCAGTTGGATTTCAAGTTTCGAATTGTACTCAACAGATGTAAAATTCAATTTATATTAA |
| Protein Sequence | MPVGHVRVLDSRTGESLTSQQTQTGVYSWTLKNPLYVTIIQSWDIFLPKGKGFKIQFRANHNMRKALGLHKCWITYRVWTTLKTFGLISLQIRIRDRILSYFDSVGVISCKTLALGINEFMLKSSWISSFELYSTDVKFNLY |
| NCBI Accession | YP_009305427.1 |
|---|---|
| Location | 1364-1783 |
| Protein Name | TrAP/C2 |
| Coding Region | ATGCAATTTTCGTCTCCCTGCAGGAGCCCCTCTTCAAACCACAATCACCTCGTGCCTCAGAAGATACTGCACAAACAAGCCAAGACAGACAGTCCAGCTAGAAGAAGAAGAAGGATCAATTGCCAGTGCAATTGTATCATCTATGCCTGTCGGCCATGTCAGGGTGTTGGATTCACGCACCGGGGAGTCACTTACATCGCAGCAAACCCAGACAGGAGTATACTCATGGACTTTGAAGAATCCTCTGTATGTAACGATCATACAGAGTTGGGACATATTCCTTCCCAAAGGGAAGGGATTCAAGATACAGTTCAGAGCAAATCACAACATGAGGAAAGCTTTGGGGCTACACAAATGCTGGATAACATACAGGGTCTGGACGACCTTGAAAACATTTGGGCTGATCTCTTTACAAATTAG |
| Protein Sequence | MQFSSPCRSPSSNHNHLVPQKILHKQAKTDSPARRRRRINCQCNCIIYACRPCQGVGFTHRGVTYIAANPDRSILMDFEESSVCNDHTELGHIPSQREGIQDTVQSKSQHEESFGATQMLDNIQGLDDLENIWADLFTN |
| NCBI Accession | YP_009305428.1 |
|---|---|
| Location | 1683-2894 |
| Protein Name | Rep/C1 |
| Coding Region | ATGGCCGCTACTAGCTCTGGGAGAGGTATATATTTCACCCCATTCACCCCCTTAGATGGACTTATAGAGCTCACCCCGATAGCCAATATGCCACGTAAGCCATCTTCGTTCAGGCTTAATGCCAAGAACATTTTCCTAACATATCCCCAGTGCCATATATCCAAAGAGTCTGCATTAGAGCAACTCAAAGCCTTTCATTACCCAATTCCTCCAGTTTTCATTAAAGTCTCAGCAGAATCCCATCAAGATGGGCAACCGCATCTGCATGCACTGCTTCAATTCAAGGGGAAATTCCAGACGACAAATCAACGATTCTTCGACCTGGTATCCCCAAGCCGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCTCGTCCGACGTCAAGTCCTATATCGAGAAGGACGGAGATGTCATCTCCTGGGGAGAATTTCAGATCGACGGCCGATCATCTAGAGGAGGTGTGCAATCGGCTAACGACGCTTATGCTGAGGCGTTAAATTCAGGAGGTAAGGACCAGGCATTGCAAATTTTAAAGGAAAAAGCCCCAAAAGATTATATTTTGCATTATCATCATTTAGTTGGGAACTTAGGTCGCATTTTTAAAACACCCCCTAAGGAATACACACCTCCATTTTCATTAGATAGTTTTAATAATGTCCCAGATGAATTATGGGATTGGGTATGGGAGAGTGGGTTAGGGTCCACTGCGTTCCCTAGTGAGTTGAGAGAGAATGCCCCTGCGGGGCCATTAAGACCTAAATCATTAGTATTAGAGGGAGATTCAAGGACGGGAAAAACATTATGGGCTAGGGCACTAGGAAAACATAATTATTTAAGTGGCCATTTAGATTTAAACGATAAGGTATTTAGTTTAGATGCAGATTATAATATAATAGATGATGTAGACCCACATTATTTAAAACATTTTAAAGAATTCATGGGGGCCCAGGTGGGCTGGCAATCCAACACAAAATACGGAAAGCCGATCCACGTGGAAAAGACAATGCCCTCAATCTTCCTTTGCAATCCTGGTCCTAATTCCTCCTATAAAGAATTCCTGGATGAGGAGAAGAATGCGGCACTAAAAAATTGGGCACTGAAAAATGCAATTTTCGTCTCCCTGCAGGAGCCCCTCTTCAAACCACAATCACCTCGTGCCTCAGAAGATACTGCACAAACAAGCCAAGACAGACAGTCCAGCTAG |
| Protein Sequence | MAATSSGRGIYFTPFTPLDGLIELTPIANMPRKPSSFRLNAKNIFLTYPQCHISKESALEQLKAFHYPIPPVFIKVSAESHQDGQPHLHALLQFKGKFQTTNQRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIEKDGDVISWGEFQIDGRSSRGGVQSANDAYAEALNSGGKDQALQILKEKAPKDYILHYHHLVGNLGRIFKTPPKEYTPPFSLDSFNNVPDELWDWVWESGLGSTAFPSELRENAPAGPLRPKSLVLEGDSRTGKTLWARALGKHNYLSGHLDLNDKVFSLDADYNIIDDVDPHYLKHFKEFMGAQVGWQSNTKYGKPIHVEKTMPSIFLCNPGPNSSYKEFLDEEKNAALKNWALKNAIFVSLQEPLFKPQSPRASEDTAQTSQDRQSS |
| NCBI Accession | YP_009305429.1 |
|---|---|
| Location | 2390-2647 |
| Protein Name | HAP/C4 |
| Coding Region | ATGGGCAACCGCATCTGCATGCACTGCTTCAATTCAAGGGGAAATTCCAGACGACAAATCAACGATTCTTCGACCTGGTATCCCCAAGCCGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCTCGTCCGACGTCAAGTCCTATATCGAGAAGGACGGAGATGTCATCTCCTGGGGAGAATTTCAGATCGACGGCCGATCATCTAGAGGAGGTGTGCAATCGGCTAACGACGCTTATGCTGAGGCGTTAA |
| Protein Sequence | MGNRICMHCFNSRGNSRRQINDSSTWYPQADQHISIQTFRELNPRPTSSPISRRTEMSSPGENFRSTADHLEEVCNRLTTLMLRR |
References More References in PubMed
| 1 |
Molecular Characterization and Genomic Function of Grapevine Geminivirus A. Sun S, et al. Front Microbiol. 2020 Sep 2;11:555194. doi: 10.3389/fmicb.2020.555194. eCollection 2020. PMID: 32983075 |
|---|---|
| 2 |
Kuo YW, et al. Phytopathology. 2022 Aug;112(8):1603-1609. doi: 10.1094/PHYTO-01-22-0015-R. Epub 2022 Jun 17. PMID: 35713600 |
| 3 |
Kishan G, et al. Front Plant Sci. 2023 Mar 9;14:1151471. doi: 10.3389/fpls.2023.1151471. eCollection 2023. PMID: 36968414 |
| 4 |
Liu C, et al. Arch Virol. 2025 May 15;170(6):125. doi: 10.1007/s00705-025-06318-1. PMID: 40372509 |
| 5 |
Grapevine red blotch disease: A comprehensive Q&A guide. Krenz B, et al. PLoS Pathog. 2023 Oct 12;19(10):e1011671. doi: 10.1371/journal.ppat.1011671. eCollection 2023 Oct. PMID: 37824437 |
| 6 |
Liu C, et al. Plants (Basel). 2024 Jun 8;13(12):1601. doi: 10.3390/plants13121601. PMID: 38931032 |
| 7 |
Marwal A, et al. Virusdisease. 2019 Mar;30(1):106-111. doi: 10.1007/s13337-018-0477-x. Epub 2018 Jul 17. PMID: 31143838 |
| 8 |
Description of a Novel Monopartite Geminivirus and Its Defective Subviral Genome in Grapevine. Al Rwahnih M, et al. Phytopathology. 2017 Feb;107(2):240-251. doi: 10.1094/PHYTO-07-16-0282-R. Epub 2016 Nov 16. PMID: 27670772 |
| 9 |
Nita M, et al. Viruses. 2023 Oct 17;15(10):2102. doi: 10.3390/v15102102. PMID: 37896878 |
| 10 |
Grapevine Red Blotch Disease: A Threat to the Grape and Wine Industries. Cieniewicz E, et al. Annu Rev Virol. 2025 Sep;12(1):335-353. doi: 10.1146/annurev-virology-092623-101702. Epub 2025 Apr 15. PMID: 40233140 |