Chayote yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000859865.1 |
| Isolate | Nigeria: Ibadan |
| Release date | 2015/2/13 |
| Submitter | Thottappilly,G., Winter,S., Maxwell,D., Kamal,S. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
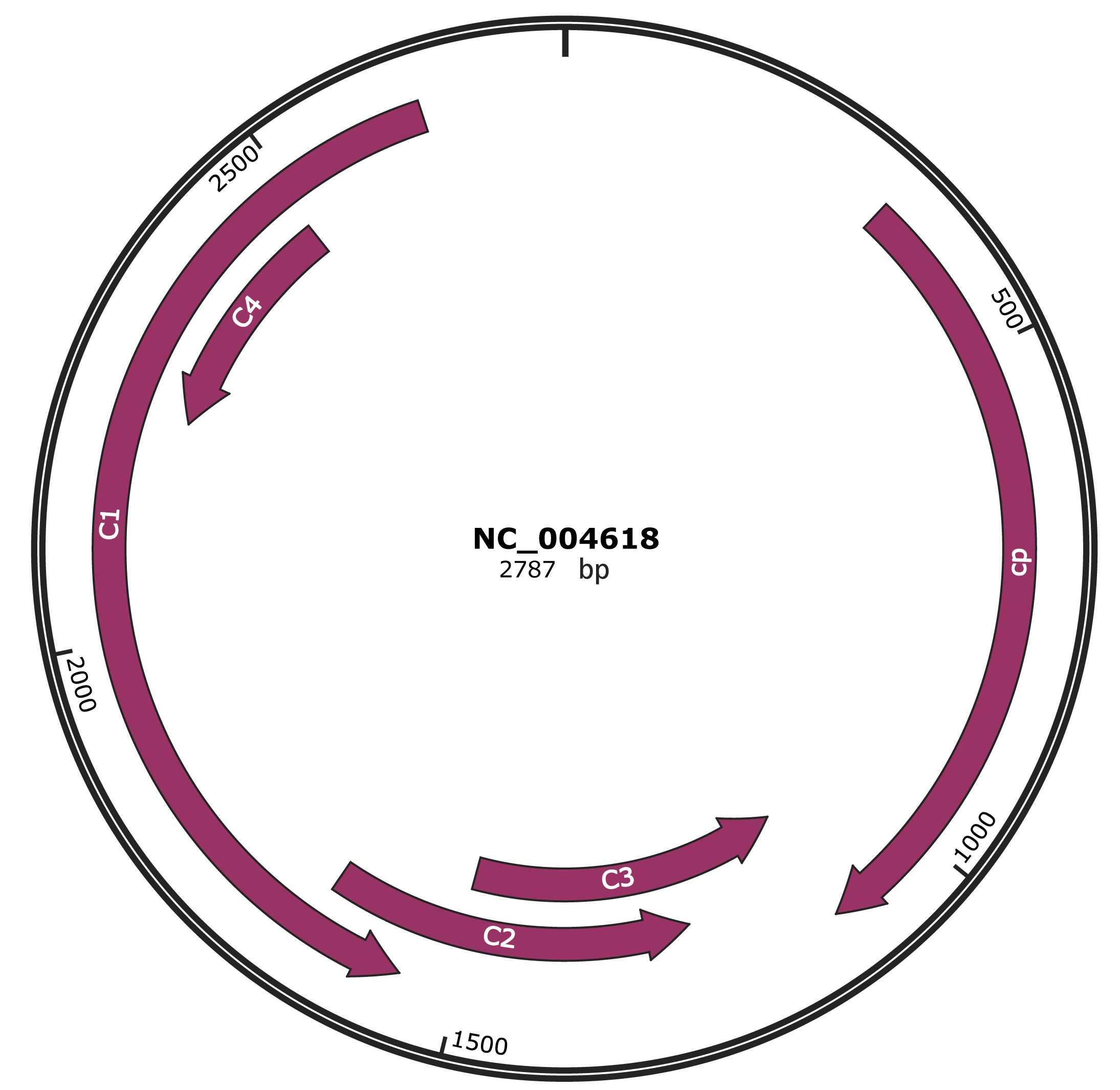
JBrowse
Genome
NC_004618
Gene Information
| NCBI Accession | NP_803405.1 |
|---|---|
| Location | 334-1110 |
| Gene Name | cp |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCCGCAGATATCATCATTTCCACGCCCGTTTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCATATACCAACCGTGTTGCTGTCCCCATTGTCCAAGGCACAAACAAACGACGGTCATGGACCTACCGGCCCAGTTACCGAAAGCCCAGAATGTACAGGATGTACAGAAGTCCTGATGTTCCTCGAGGTTGTGAGGGTCCATGTAAGATCCAGTCGTTTGATCAGCGCGATTCCGTTGTACATACCGGTAACGTTAGGTGTCTTAGCGATGTCACTAGGGGTGGGGGTCTTACCCACCGTACCGGCAAACGTTTCTGTATTAAGTCCGTGTATGTACTAGGTAAGGTTTGGATGGATGAGAATGTTAAGAAGTCCAACCATACTAACACGTGTCTGTTCTGGTTAGTTAGAGATAGACGTCCTTACGGAAGTAGTCCTCAGGACTTTGGTCAGGTATTTAACATGTTCGACAATGAACCCAGTACTGCAACGGTGATGAACGACAAGCGTGATCGCTACCAGGTCCTGAGACGGTTTCAGGTAACGGTTACAGGAGGACCTTCCGGATGTAAGGAGGCCGCTATTGTTAAGCGGTTTTTCCGCCTCAACCACCACGTGACTTACAACCATCAGGAAGCGGCTAAGTACGAGAATCACACCGAGAATGCATTATTACTATACATGGCATGCACGCATGCTTCCAACCCTGTCTATGCTAGTTTGAAAATACGTATGTATTTCTACGATTCGGTCATTAATTAA |
| Protein Sequence | MSKRPADIIISTPVSKVRRRLNFDSPYTNRVAVPIVQGTNKRRSWTYRPSYRKPRMYRMYRSPDVPRGCEGPCKIQSFDQRDSVVHTGNVRCLSDVTRGGGLTHRTGKRFCIKSVYVLGKVWMDENVKKSNHTNTCLFWLVRDRRPYGSSPQDFGQVFNMFDNEPSTATVMNDKRDRYQVLRRFQVTVTGGPSGCKEAAIVKRFFRLNHHVTYNHQEAAKYENHTENALLLYMACTHASNPVYASLKIRMYFYDSVIN |
| NCBI Accession | NP_803406.1 |
|---|---|
| Location | 1107-1511 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTGCGCACAGGGGAACTCATCACTGCGCATCAAGCGCAGAATTCCGTCTTTATCTGGGAGCTGACAAATCCCCTCTATTTCAAGATAGTCGACCACATAGAGAGGCCGTTCAACTCGAACCACGACATATTATCAATTCAAATCCGGTTCAACCACAACCTCCGGAAAGCATTGGGGATTCACAAGTGTTTCCTGAACTTCCAAGTCTGGACGACCTTACGTCCTCAGACTGGTCGTTTCTTGAGAGTCTTTAGGACACAAGTGCTTAAGTATCTAGATAGCGTTCATGTAATTTCAATTAATTTTGTCGTCAGAGCCGTTGCTCATGTACTGAACGACGTCCTTACGGGGACGATAGATGTAATTGAGAATCACGAAATAAAGTTCAATCTTTATTAA |
| Protein Sequence | MDLRTGELITAHQAQNSVFIWELTNPLYFKIVDHIERPFNSNHDILSIQIRFNHNLRKALGIHKCFLNFQVWTTLRPQTGRFLRVFRTQVLKYLDSVHVISINFVVRAVAHVLNDVLTGTIDVIENHEIKFNLY |
| NCBI Accession | NP_803407.1 |
|---|---|
| Location | 1252-1659 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCCGCCTTCTGCACGCTCACCCAGCCGCTCTACTCAAGTGCCGATCAAAGTTCAACACCGAATCGGGAAGAAGAAAGCCATTCGGCGCAAAAGGATTGACCTCGAGTGCGGCTGCTCATTCTACCTGCACATCGACTGCGCATTGAATGGATTTGCGCACAGGGGAACTCATCACTGCGCATCAAGCGCAGAATTCCGTCTTTATCTGGGAGCTGACAAATCCCCTCTATTTCAAGATAGTCGACCACATAGAGAGGCCGTTCAACTCGAACCACGACATATTATCAATTCAAATCCGGTTCAACCACAACCTCCGGAAAGCATTGGGGATTCACAAGTGTTTCCTGAACTTCCAAGTCTGGACGACCTTACGTCCTCAGACTGGTCGTTTCTTGAGAGTCTTTAG |
| Protein Sequence | MPPSARSPSRSTQVPIKVQHRIGKKKAIRRKRIDLECGCSFYLHIDCALNGFAHRGTHHCASSAEFRLYLGADKSPLFQDSRPHREAVQLEPRHIINSNPVQPQPPESIGDSQVFPELPSLDDLTSSDWSFLESL |
| NCBI Accession | NP_803408.1 |
|---|---|
| Location | 1559-2647 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGGCACCTCCCAAGCGATTTCAAATAAATGCGAAGAATTACTTCCTCACTTATCCACAGTGCTCTCTCACGAAGGAGGAAGCACTTTCCCAATTACGAAGCTTACGCACGCCCACGAACCAGAAATACATCAAAGTTTGTCGTGAGTTACACGAGGATGGGCAACCTCATCTGCATGCCCTCATTCAGTTCGAGGGCAAATACAAGTGCCAAAATCAGCGATTCTTCGATCTGGTCTCCCCAACTCGATCAACACATTTCCATCCAAACGTTCAGGGAGCTAAGTCGTGTTCCGACGTCAAGTCCTACATCGAGAAGGACGGTGATAGCATCGAGTGGGGAGAGTTCCAGGTCGACGGACGTAGTGCTAGAGGCGGCTGCCATAAGGCTAATGACGCAGCCGCCGAGGCGTTAAACGCAGGTTCCGCTGAAGCTGCGTTGGCTATTATTAAGGAGAAACTCCCCAAAGATTATATATTTCAATATCATAATATCAAGGCTAATTTGGATAAGATCTTCCAAGCTCCTCCGGAGGTTTATGTTTCTCCCTTCTGTGCTTCCTCCTTCACTCAGGTTCCTGATGAACTTCAACGATGGGCATCGGCGAACGTGATGGATGCCGCTGCGCGGCCGTGGAGGCCGAGTAGTATAATAGTCGAGGGTGATAGTCGGACGGGCAAGACAATGTGGGCCCGTTCATTGGGACCACACAATTATTTGTGTGGACATCTCGACCTCAGTCCAAAAGTGTACAGCAATTCGGCTTGGTACAACGTCATTGATGACGTCGATCCGCATTATCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAGCGTGACTGGCAAAGCAACACGAAGTACGGGAAGCCGATTCAAATTAAAGGCGGCATTCCGACAATCTTCCTGTGCAATCCAGGGCCGACGTCTTCATATAAAGAATACTTGGACGAAGATAAGAATATCTCTCTGAAAGCCTGGGCTCTAAAGAATGCCGCCTTCTGCACGCTCACCCAGCCGCTCTACTCAAGTGCCGATCAAAGTTCAACACCGAATCGGGAAGAAGAAAGCCATTCGGCGCAAAAGGATTGA |
| Protein Sequence | MAPPKRFQINAKNYFLTYPQCSLTKEEALSQLRSLRTPTNQKYIKVCRELHEDGQPHLHALIQFEGKYKCQNQRFFDLVSPTRSTHFHPNVQGAKSCSDVKSYIEKDGDSIEWGEFQVDGRSARGGCHKANDAAAEALNAGSAEAALAIIKEKLPKDYIFQYHNIKANLDKIFQAPPEVYVSPFCASSFTQVPDELQRWASANVMDAAARPWRPSSIIVEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNSAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNISLKAWALKNAAFCTLTQPLYSSADQSSTPNREEESHSAQKD |
| NCBI Accession | NP_803409.1 |
|---|---|
| Location | 2233-2490 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGCAACCTCATCTGCATGCCCTCATTCAGTTCGAGGGCAAATACAAGTGCCAAAATCAGCGATTCTTCGATCTGGTCTCCCCAACTCGATCAACACATTTCCATCCAAACGTTCAGGGAGCTAAGTCGTGTTCCGACGTCAAGTCCTACATCGAGAAGGACGGTGATAGCATCGAGTGGGGAGAGTTCCAGGTCGACGGACGTAGTGCTAGAGGCGGCTGCCATAAGGCTAATGACGCAGCCGCCGAGGCGTTAA |
| Protein Sequence | MGNLICMPSFSSRANTSAKISDSSIWSPQLDQHISIQTFRELSRVPTSSPTSRRTVIASSGESSRSTDVVLEAAAIRLMTQPPRR |
References More References in PubMed
| 1 |
First Report of Squash leaf curl Philippines virus Infecting Chayote (Sechium edule) in Taiwan. Tsai WS, et al. Plant Dis. 2011 Sep;95(9):1197. doi: 10.1094/PDIS-04-11-0282. PMID: 30732043 |
|---|---|
| 2 |
Castro RM, et al. Plant Pathol J. 2013 Sep;29(3):285-93. doi: 10.5423/PPJ.OA.12.2012.0182. PMID: 25288955 |
| 3 |
A distinct seed-transmissible strain of tomato leaf curl New Delhi virus infecting Chayote in India. Sangeetha B, et al. Virus Res. 2018 Oct 15;258:81-91. doi: 10.1016/j.virusres.2018.10.009. Epub 2018 Oct 15. PMID: 30336187 |
| 4 |
Leke WN, et al. Arch Virol. 2016 Aug;161(8):2347-50. doi: 10.1007/s00705-016-2915-7. Epub 2016 Jun 4. PMID: 27262944 |