Spinach severe curly top virus
Basic Information
| Genus | Curtovirus |
|---|---|
| NCBI Assembly | GCF_000888695.1 |
| Isolate | USA |
| Release date | 2015/2/22 |
| Submitter | Hernandez,C., Brown,J.K., Hernandez-Zepeda,C. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
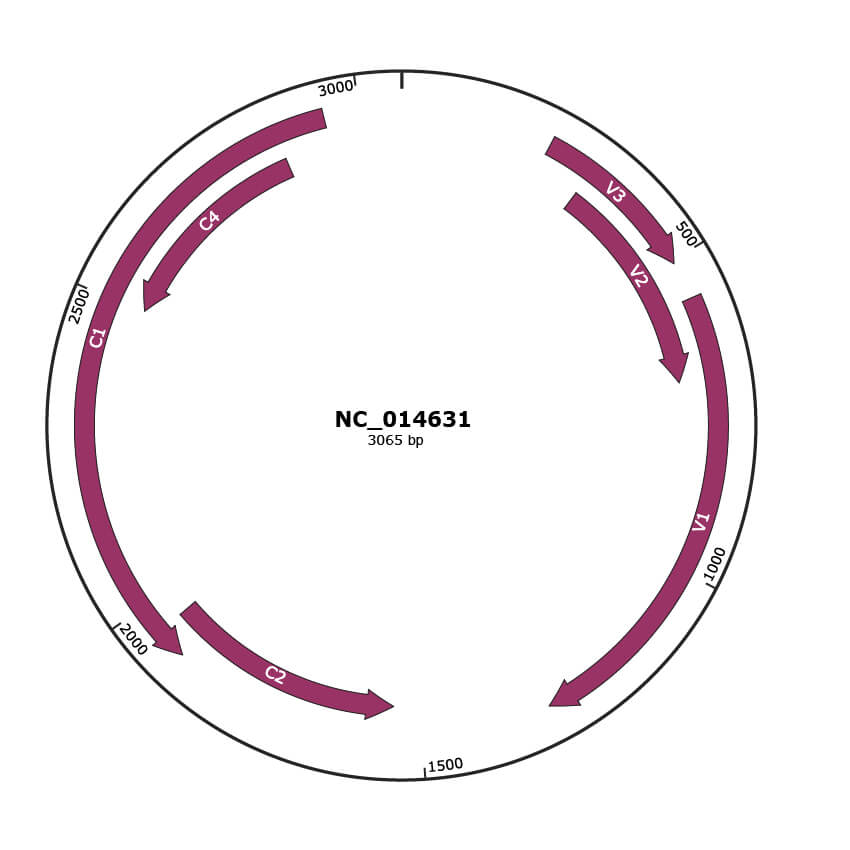
Genomic Organization
JBrowse
Genome
NC_014631
ACCGGATGGCCGCGATGATGCCACTTGTCACTTTTCTATTTGTTCTAAAAAAGTAACCGTTACTTTTGACCAGTCAAAAGAAGAATTATGGACCCCACAACAATTCCTTGCTGGGCAAGGAATTGAAATTTCCCGCCAAAATTCAAAATTTAAATAAAGTAAACCCGACTCTGACATAAAGTTATCTTATTTTTTTACTATATGTATCCTATTTATACATTTACAAATAAATGTATAAATGATGGTCTGCCTTCCTGATTGGCTCTTCCTCCTTTTTATTTTTGCCATCCTTCTTCAATCAGGAACAAACTTTTATGGGACCATTCAAAGTGGATCAATTTCCAGGAAACTATCCAGCCTTTCTAGCCGTTTCGACGAGTTGTTTCTTAAGATACAACAAGTGGTGTATATTAGGAGTAATACCAGAGATCGGGGAGTTGACACTAGAAGAAGGAGAGGTCTTTCTTCAATTCCAGAAGGAAGTGAAGAAGTTGCTGAGGCTTAATTGCAGTTTCGGTAGAAAGTGCATTTTGTATCAGGATATTTATAAAAAGTACGTGAAGGATGAGTCAGAAAAGAAAAATGCAGTCGCAGGCTGCTGGGAAGAAGAAGAAGAAGACAGTATATGGGAAGAAATACCAATGGAAGAGGTCTGTTCGAAAGAACAGAAAGATCAAACTCAAGATGTATGATGACATGCTTGGAGCTGGTGGTGTTGGTTCTGCCATCACAAATGATGGTATGATTACTATGCTGAACAACTATGTTCAGGGCATTGGTGATTCTCAAAGATCATCCAATGTGACTGTTACAAGGCATTTGAAGTATGACATGGCATTAATGGGTAGCACAGGTTTTTGGGAGGCTCCTAATTATATGACTCAATATCATTGGATCATTGTTGACCGTGATGTTGGTTCTGTTTTTCCAGATAAGCTTAGTATGATTTTTGATATTCCCTCCAACGGCCAAGCCATGCCTTCTACTTATCGCATCCGGAGGGACATGAATGAGCGGTTCATTGTTAAAAAGAAATGGACCACTCATCTCATGTCTACAGGTACTGATTATGGTGGGAAGCAGACTTACAAGGCTCCATCTATGCCTAATTATAAGAAGCCTCTCAATGTCAATGTTAGGAATATCAATGTTAAGACGGTATGGAAGGACACTGGAGGTGGAAAGTATGAAGATGTGAAGGAAAATGCTATATTATATGTTGTTGTCAACGATAATACAGATAACACAAATATGTATGCCACTTTATATGGCAATTGTAGATGTTATTTTTATTGATAGAAAAAAATTTTTCCAATGAGATTGTAGTTTATTCTAGAAACATTTTTGAAATAAAATGTTTATTCTTGATATAATGACAATGGAGACCTGTAAGGGTCTGGTATTCCTTGCACACACTTCTCAATTAACTACTCAAAACCCCCCCTATTTTCACTTGGGTAACGAACGATTAAAAAAATTTGCCGAAAAAAGATTATACTTTATTAATGAACCGCGAACCTGGGAGCGGAAACCCTTTTTACATTGATTAAAATGCGAATTTAATTGGCCACTCATAGAAATCACACATATCTAGAATCATAATCCTCTCGGTCATGAACATCATATCTATTACACTACATATCTGACCTTTATCAATGTCAGATAATTTACACTTACGAAAAAAACGCCACACAAAACCTATTAAGTGACTGATAAGCTTCTGGGTTGGCTCCTGATGCTCTTCTGTCTGGAACTGGAACTTCCACTTGATGAAGGTACCTGTTGGTATCTCTGGTGTATACTTTGCACTGACCTGCATAGTTAAAGTATACTTGAAATCATTAGTTTTTTTCACTTCTATTTTCCAATCACAGAAATAGCACCTAAGCGATGGCTTGAATATTTCAGTCATCTTTGTTGTACAATGGTTCACTGATGGAAATGAATACGGCATTATATAATGTCCATCTTTTAAGGCTTTCATTTTCATCTTTATCCAAAAAATCTTTAAAGCTGGATCCCTCACCAGGATTACATAAAATAATTGAGGGTATTCCACCTTTAATCTGAACAGGCTTTCCATATTTGCAGTTGCTTTGCCAATCATGTTGGGCCCCAATAAGCTCTTTCCAATGCTTTAATTTTAAATAAGATGGTGCTATGTCATCAATGACATTATATTCCACTTCATTACTGTACACACGTGGATTGAAATCAAGATGCCCAGACAAGTAATTATGCTTACCTAACGATCTGGCCCAGCATGTTTTACCTGTTCTACTATCACCTTCAATTATTAAAGATTTTGGTCTAATGGGCCTTGATTCAATTGGCTGTCCAAAATAATTATCAGCCCATTCCTGCATTTCATCCGGAACGTTGTTGAATGATGATAATGGAAATGGAGGTGTCCATGTCTCTTGAGGTTTCTTGAATATTCTTTCAAGGTTGGCAAGGACATTGTGATGTTGTATCACAAATGTCTTTGGATCCCCAGCCTTGATTATCTCAAGAGCCTCTTTGACACCTCCTGAGTTAACTGCGTTGTGGTAGACGTCGTCTTTATTGGCTTTTGAACTGCCAGAGACCTTGTATTGTCCGGATTCACAATAATCACCTTCTTTGGTGATGTAATTGTGGACTGCATTGGCGTCCTTGGCTGCTTGGACATTAGGATGGTAATTGGCACTCCTCCTGGGGTGAGTAATGTCGAAAAATCTGCAGTCCTTGATGTTGGACTTTCCGGATAATTGTATGAGACAGTGGAGATGTGGTGTTCCATCTGCATGTCTCTCTGAGGCGACTCTAATGTATGTTGGTTTGACGACTGACCATGGAAGGTTTTGAAGCAATTGAAGTACTTCATCTTTTGGTATATCACACTGTGGATATGTGAGAAAGATATTTTTTGATGATAGTCTAAATGATTTATTTTGTCGAGGCATTTAAAATGGGACACCAGGGGTTTTTCTCTTCAAACTTGCATAATTGCTGGTGTCCTGGTGTCCCATTTATACCAAAACCTCCTTAGGACACCAGGCTTCGCGGCCATCCGATTTAATATT
Gene Information
| NCBI Accession | YP_003966133.1 |
|---|---|
| Location | 239-505 |
| Gene Name | V3 |
| Protein Name | movement protein |
| Coding Region | ATGATGGTCTGCCTTCCTGATTGGCTCTTCCTCCTTTTTATTTTTGCCATCCTTCTTCAATCAGGAACAAACTTTTATGGGACCATTCAAAGTGGATCAATTTCCAGGAAACTATCCAGCCTTTCTAGCCGTTTCGACGAGTTGTTTCTTAAGATACAACAAGTGGTGTATATTAGGAGTAATACCAGAGATCGGGGAGTTGACACTAGAAGAAGGAGAGGTCTTTCTTCAATTCCAGAAGGAAGTGAAGAAGTTGCTGAGGCTTAA |
| Protein Sequence | MMVCLPDWLFLLFIFAILLQSGTNFYGTIQSGSISRKLSSLSSRFDELFLKIQQVVYIRSNTRDRGVDTRRRRGLSSIPEGSEEVAEA |
| NCBI Accession | YP_003966134.1 |
|---|---|
| Location | 315-692 |
| Gene Name | V2 |
| Protein Name | ss-dsDNA regulator |
| Coding Region | ATGGGACCATTCAAAGTGGATCAATTTCCAGGAAACTATCCAGCCTTTCTAGCCGTTTCGACGAGTTGTTTCTTAAGATACAACAAGTGGTGTATATTAGGAGTAATACCAGAGATCGGGGAGTTGACACTAGAAGAAGGAGAGGTCTTTCTTCAATTCCAGAAGGAAGTGAAGAAGTTGCTGAGGCTTAATTGCAGTTTCGGTAGAAAGTGCATTTTGTATCAGGATATTTATAAAAAGTACGTGAAGGATGAGTCAGAAAAGAAAAATGCAGTCGCAGGCTGCTGGGAAGAAGAAGAAGAAGACAGTATATGGGAAGAAATACCAATGGAAGAGGTCTGTTCGAAAGAACAGAAAGATCAAACTCAAGATGTATGA |
| Protein Sequence | MGPFKVDQFPGNYPAFLAVSTSCFLRYNKWCILGVIPEIGELTLEEGEVFLQFQKEVKKLLRLNCSFGRKCILYQDIYKKYVKDESEKKNAVAGCWEEEEEDSIWEEIPMEEVCSKEQKDQTQDV |
| NCBI Accession | YP_003966135.1 |
|---|---|
| Location | 565-1296 |
| Gene Name | V1 |
| Protein Name | capsid protein |
| Coding Region | ATGAGTCAGAAAAGAAAAATGCAGTCGCAGGCTGCTGGGAAGAAGAAGAAGAAGACAGTATATGGGAAGAAATACCAATGGAAGAGGTCTGTTCGAAAGAACAGAAAGATCAAACTCAAGATGTATGATGACATGCTTGGAGCTGGTGGTGTTGGTTCTGCCATCACAAATGATGGTATGATTACTATGCTGAACAACTATGTTCAGGGCATTGGTGATTCTCAAAGATCATCCAATGTGACTGTTACAAGGCATTTGAAGTATGACATGGCATTAATGGGTAGCACAGGTTTTTGGGAGGCTCCTAATTATATGACTCAATATCATTGGATCATTGTTGACCGTGATGTTGGTTCTGTTTTTCCAGATAAGCTTAGTATGATTTTTGATATTCCCTCCAACGGCCAAGCCATGCCTTCTACTTATCGCATCCGGAGGGACATGAATGAGCGGTTCATTGTTAAAAAGAAATGGACCACTCATCTCATGTCTACAGGTACTGATTATGGTGGGAAGCAGACTTACAAGGCTCCATCTATGCCTAATTATAAGAAGCCTCTCAATGTCAATGTTAGGAATATCAATGTTAAGACGGTATGGAAGGACACTGGAGGTGGAAAGTATGAAGATGTGAAGGAAAATGCTATATTATATGTTGTTGTCAACGATAATACAGATAACACAAATATGTATGCCACTTTATATGGCAATTGTAGATGTTATTTTTATTGA |
| Protein Sequence | MSQKRKMQSQAAGKKKKKTVYGKKYQWKRSVRKNRKIKLKMYDDMLGAGGVGSAITNDGMITMLNNYVQGIGDSQRSSNVTVTRHLKYDMALMGSTGFWEAPNYMTQYHWIIVDRDVGSVFPDKLSMIFDIPSNGQAMPSTYRIRRDMNERFIVKKKWTTHLMSTGTDYGGKQTYKAPSMPNYKKPLNVNVRNINVKTVWKDTGGGKYEDVKENAILYVVVNDNTDNTNMYATLYGNCRCYFY |
| NCBI Accession | YP_003966136.1 |
|---|---|
| Location | 1547-1954 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCCGTATTCATTTCCATCAGTGAACCATTGTACAACAAAGATGACTGAAATATTCAAGCCATCGCTTAGGTGCTATTTCTGTGATTGGAAAATAGAAGTGAAAAAAACTAATGATTTCAAGTATACTTTAACTATGCAGGTCAGTGCAAAGTATACACCAGAGATACCAACAGGTACCTTCATCAAGTGGAAGTTCCAGTTCCAGACAGAAGAGCATCAGGAGCCAACCCAGAAGCTTATCAGTCACTTAATAGGTTTTGTGTGGCGTTTTTTTCGTAAGTGTAAATTATCTGACATTGATAAAGGTCAGATATGTAGTGTAATAGATATGATGTTCATGACCGAGAGGATTATGATTCTAGATATGTGTGATTTCTATGAGTGGCCAATTAAATTCGCATTTTAA |
| Protein Sequence | MPYSFPSVNHCTTKMTEIFKPSLRCYFCDWKIEVKKTNDFKYTLTMQVSAKYTPEIPTGTFIKWKFQFQTEEHQEPTQKLISHLIGFVWRFFRKCKLSDIDKGQICSVIDMMFMTERIMILDMCDFYEWPIKFAF |
| NCBI Accession | YP_003966137.1 |
|---|---|
| Location | 1905-2945 |
| Gene Name | C1 |
| Protein Name | replication initiator protein |
| Coding Region | ATGCCTCGACAAAATAAATCATTTAGACTATCATCAAAAAATATCTTTCTCACATATCCACAGTGTGATATACCAAAAGATGAAGTACTTCAATTGCTTCAAAACCTTCCATGGTCAGTCGTCAAACCAACATACATTAGAGTCGCCTCAGAGAGACATGCAGATGGAACACCACATCTCCACTGTCTCATACAATTATCCGGAAAGTCCAACATCAAGGACTGCAGATTTTTCGACATTACTCACCCCAGGAGGAGTGCCAATTACCATCCTAATGTCCAAGCAGCCAAGGACGCCAATGCAGTCCACAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACAATACAAGGTCTCTGGCAGTTCAAAAGCCAATAAAGACGACGTCTACCACAACGCAGTTAACTCAGGAGGTGTCAAAGAGGCTCTTGAGATAATCAAGGCTGGGGATCCAAAGACATTTGTGATACAACATCACAATGTCCTTGCCAACCTTGAAAGAATATTCAAGAAACCTCAAGAGACATGGACACCTCCATTTCCATTATCATCATTCAACAACGTTCCGGATGAAATGCAGGAATGGGCTGATAATTATTTTGGACAGCCAATTGAATCAAGGCCCATTAGACCAAAATCTTTAATAATTGAAGGTGATAGTAGAACAGGTAAAACATGCTGGGCCAGATCGTTAGGTAAGCATAATTACTTGTCTGGGCATCTTGATTTCAATCCACGTGTGTACAGTAATGAAGTGGAATATAATGTCATTGATGACATAGCACCATCTTATTTAAAATTAAAGCATTGGAAAGAGCTTATTGGGGCCCAACATGATTGGCAAAGCAACTGCAAATATGGAAAGCCTGTTCAGATTAAAGGTGGAATACCCTCAATTATTTTATGTAATCCTGGTGAGGGATCCAGCTTTAAAGATTTTTTGGATAAAGATGAAAATGAAAGCCTTAAAAGATGGACATTATATAATGCCGTATTCATTTCCATCAGTGAACCATTGTACAACAAAGATGACTGA |
| Protein Sequence | MPRQNKSFRLSSKNIFLTYPQCDIPKDEVLQLLQNLPWSVVKPTYIRVASERHADGTPHLHCLIQLSGKSNIKDCRFFDITHPRRSANYHPNVQAAKDANAVHNYITKEGDYCESGQYKVSGSSKANKDDVYHNAVNSGGVKEALEIIKAGDPKTFVIQHHNVLANLERIFKKPQETWTPPFPLSSFNNVPDEMQEWADNYFGQPIESRPIRPKSLIIEGDSRTGKTCWARSLGKHNYLSGHLDFNPRVYSNEVEYNVIDDIAPSYLKLKHWKELIGAQHDWQSNCKYGKPVQIKGGIPSIILCNPGEGSSFKDFLDKDENESLKRWTLYNAVFISISEPLYNKDD |
| NCBI Accession | YP_003966138.1 |
|---|---|
| Location | 2504-2866 |
| Gene Name | C4 |
| Protein Name | cell cycle regulator |
| Coding Region | ATGAAGTACTTCAATTGCTTCAAAACCTTCCATGGTCAGTCGTCAAACCAACATACATTAGAGTCGCCTCAGAGAGACATGCAGATGGAACACCACATCTCCACTGTCTCATACAATTATCCGGAAAGTCCAACATCAAGGACTGCAGATTTTTCGACATTACTCACCCCAGGAGGAGTGCCAATTACCATCCTAATGTCCAAGCAGCCAAGGACGCCAATGCAGTCCACAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACAATACAAGGTCTCTGGCAGTTCAAAAGCCAATAAAGACGACGTCTACCACAACGCAGTTAACTCAGGAGGTGTCAAAGAGGCTCTTGAGATAA |
| Protein Sequence | MKYFNCFKTFHGQSSNQHTLESPQRDMQMEHHISTVSYNYPESPTSRTADFSTLLTPGGVPITILMSKQPRTPMQSTITSPKKVIIVNPDNTRSLAVQKPIKTTSTTTQLTQEVSKRLLR |
References More References in PubMed
| 1 |
Baliji S, et al. Phytopathology. 2004 Jul;94(7):772-9. doi: 10.1094/PHYTO.2004.94.7.772. PMID: 18943911 |
|---|---|
| 2 |
Hernandez C, et al. Plant Dis. 2010 Jul;94(7):917. doi: 10.1094/PDIS-94-7-0917B. PMID: 30743586 |
| 3 |
Baliji S, et al. Mol Plant Microbe Interact. 2007 Feb;20(2):194-206. doi: 10.1094/MPMI-20-2-0194. PMID: 17313170 |
| 4 |
Revisiting the classification of curtoviruses based on genome-wide pairwise identity. Varsani A, et al. Arch Virol. 2014 Jul;159(7):1873-82. doi: 10.1007/s00705-014-1982-x. Epub 2014 Jan 25. PMID: 24463952 |
| 5 |
Hernández-Zepeda C, et al. Arch Virol. 2013 Nov;158(11):2245-54. doi: 10.1007/s00705-013-1733-4. Epub 2013 May 26. PMID: 23708296 |