Passion fruit chlorotic mottle virus
Basic Information
| Genus | Citlodavirus |
|---|---|
| NCBI Assembly | GCF_004132865.1 |
| Isolate | Brazil |
| Release date | 2019/2/12 |
| Submitter | Fontenele,R.S., Abreu,R.A., Lamas,N.S., Alves-Freitas,D.M.T., Vidal,A.H., Poppiel,R.R., Melo,F.L., Lacorte,C., Martin,D.P., Campos,M.A., Varsani,A., Ribeiro,S.G. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
JBrowse
Genome
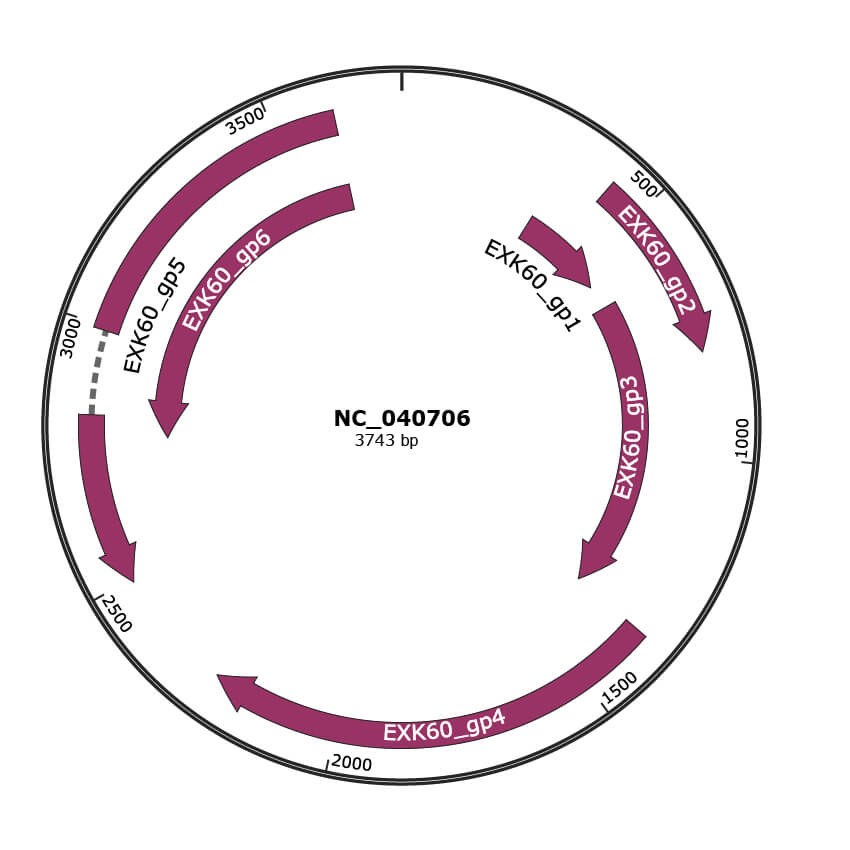
NC_040706
Gene Information
| NCBI Accession | YP_009553192.1 |
|---|---|
| Location | 334-561 |
| Protein Name | hypothetical protein |
| Coding Region | ATGAGCATATCTTCTGAAATATTTGAGGAGATAAAAGAAAATAAGGTGAGTATCACCGTTTTTTTTATTATTTTCTTTTGCGTATCTGTTATAAATGTCGTGTGCTGTGCCTTTGGATTTTGGCAATCTGCCGGACCACGTGGTGGGGCTGTTGTGTATGTTGGCGGTGAGGCTATTAATGATGGAGGAGAAGAGATATGTTCTGGAAAAAAGGCACAGCCTGGCTAA |
| Protein Sequence | MSISSEIFEEIKENKVSITVFFIIFFCVSVINVVCCAFGFWQSAGPRGGAVVYVGGEAINDGGEEICSGKKAQPG |
| NCBI Accession | YP_009553193.1 |
|---|---|
| Location | 428-793 |
| Protein Name | hypothetical v2 protein |
| Coding Region | ATGTCGTGTGCTGTGCCTTTGGATTTTGGCAATCTGCCGGACCACGTGGTGGGGCTGTTGTGTATGTTGGCGGTGAGGCTATTAATGATGGAGGAGAAGAGATATGTTCTGGAAAAAAGGCACAGCCTGGCTAACAGGCATAGGATTCTGATAAGAATTATTCGCAAATGGGGCAGGAAAAATCGCGTAAAGGCGAATGGTGACTACGCGGAGTGGAAGAACTTATGGGCCTCCTACGGCCCAGACAAGGAGAAGATTTCCGCCCATGAGAAGGAGGCCAGCTATGGACCGAGTGATTGGGCCGTCAAAAAAAACTGTGAAGCGGATGAAAAAGGGAAAGTCCGGCGGGATTCCGGTTGGATGTAA |
| Protein Sequence | MSCAVPLDFGNLPDHVVGLLCMLAVRLLMMEEKRYVLEKRHSLANRHRILIRIIRKWGRKNRVKANGDYAEWKNLWASYGPDKEKISAHEKEASYGPSDWAVKKNCEADEKGKVRRDSGWM |
| NCBI Accession | YP_009553194.1 |
|---|---|
| Location | 624-1361 |
| Protein Name | capsid protein |
| Coding Region | ATGGTGACTACGCGGAGTGGAAGAACTTATGGGCCTCCTACGGCCCAGACAAGGAGAAGATTTCCGCCCATGAGAAGGAGGCCAGCTATGGACCGAGTGATTGGGCCGTCAAAAAAAACTGTGAAGCGGATGAAAAAGGGAAAGTCCGGCGGGATTCCGGTTGGATGTAAGGGGCCTTGTAAAACCCATACAGTCGACGTTATTGCGACTGTAACTCATGATGGCAAGGGGCCAGGTTTAGTATCAAATATCAGCAAAGGTGATGACTTTGGTCAGCGTGAGGGTAGACGTATTCGGGTGACGAAATTATTACTGAGGGGTAAAGTATGGCTCCCTCAGGATAAGGCGACCATCGCTGGATCGAATATAATGAGACTGTGGGTTATGAAGGATAGGCGCCCTGGCAGTCAGCATGTTGCATTTGAGGCATTGTTTGACATGGCTGACAAAGAGCCCTCTACGGCATTAGTGAAGATGGATTATAGAGACAGATTTATTGTTATTAAGGATATGGAAATCGACCTGCATGGAGGGAGAGATTTCCGTGTGGACGAGGAAACATTTGATATAATGGTTCCGATAAATTGTGACGTGTTATTTGATCACAATGACGAGGGGTCTTTGACCACCACGTTAGAGAACGGGATTATCGTTTATTATGCTGTTACGGATCCCGCTCAAGTGATGCAACTCACAGCACAGTGTAGATTGTACTTTTTTGACTCTACGTCCAATTAA |
| Protein Sequence | MVTTRSGRTYGPPTAQTRRRFPPMRRRPAMDRVIGPSKKTVKRMKKGKSGGIPVGCKGPCKTHTVDVIATVTHDGKGPGLVSNISKGDDFGQREGRRIRVTKLLLRGKVWLPQDKATIAGSNIMRLWVMKDRRPGSQHVAFEALFDMADKEPSTALVKMDYRDRFIVIKDMEIDLHGGRDFRVDEETFDIMVPINCDVLFDHNDEGSLTTTLENGIIVYYAVTDPAQVMQLTAQCRLYFFDSTSN |
| NCBI Accession | YP_009553195.1 |
|---|---|
| Location | 1361-2251 |
| Protein Name | movement protein |
| Coding Region | ATGCAAATGTTGTTTTTTTTAATCAGGATGTCGGATTCACAAATTAAGGTGTTTAATGAGTATCACAGCAGTAAGCGTGTTGAGTATCCTCTGACAAATGAGAAGACAATGATAAAGCTGGAATTCCCCTCTATGGGAGATATAAGTTGGTCAAGACTTAAGGGTCATTGTTTAAAAATTGACCATTGTCAGATAAGTTACACCCCTCAGGTGCCAGCAAATGCTAGTGGCAATGTATGCTTTGAGATACATGATATGCGAATGGAAGCGGATAAAACGTTACAGGCAGAGTACACGGTGCCCATCAGGTGTGCGGTGGAGTTGAATTTTTTTTCAACTTCTTTTTTCAGTATGAAAGACGATGTGCCATGGGAAGTGTTTTATTCCGTAGAGAATAGTGATGTACGTTCTGGTACGAGATTCTGTAAGATGAAAGCAAGGGTTAAGCTGTCTAGTGCTAAGCACAGCACCCATATTAACTTTAGATCCCCGACGATAAAAATAATATCGAGGGGGTTTAGCGAACGTGATGTTGATTTTCATCACGTGGCAATACCTAAGGCAGAGAGGTTACTCTGCAGGGGTAGTTCTGTAATAACGAGCAGGCCTCGTTTTGAGATCGAGGCTGGTGATAGTTGGGCCAGTAAGTCCAGCATTGGTGGTAGCGACGTGGACTATCCGTATAAGGAACTGGGCCGATTAAACGCGGATGCATTAGAGATTGGGCCCAGTGCAAGCCAAGTTGGTATTGGGCCAGGTAATGAGCCCAATAAAGGAAAGGTTGTAATGGATGCAGTTGAATTTGCTGAGGTGGTGGCGGATGCAGTACGGCATGGAAGTGTAATAAACAATAATATTATTAATGATAATAAGAAAAAGGCTCCGGCATAA |
| Protein Sequence | MQMLFFLIRMSDSQIKVFNEYHSSKRVEYPLTNEKTMIKLEFPSMGDISWSRLKGHCLKIDHCQISYTPQVPANASGNVCFEIHDMRMEADKTLQAEYTVPIRCAVELNFFSTSFFSMKDDVPWEVFYSVENSDVRSGTRFCKMKARVKLSSAKHSTHINFRSPTIKIISRGFSERDVDFHHVAIPKAERLLCRGSSVITSRPRFEIEAGDSWASKSSIGGSDVDYPYKELGRLNADALEIGPSASQVGIGPGNEPNKGKVVMDAVEFAEVVADAVRHGSVINNNIINDNKKKAPA |
| NCBI Accession | YP_009553196.1 |
|---|---|
| Location | 2493-2828,2993-3616 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCTTCAACATCCAACTTCCGCTTCAGTGCAAAAAACATTTTCCTAACCTTCGCTCAATGCTTCCTCCCAAAGGAATATATCCTTAATTTCCTAAAATCAAAGCCCAGCAGCTTCGATATTTTTTTTATTTGCGTCTGTTTTGAAACTCATCAAAACGGAGACCCCCATATACATGCTATGGTCCAAATGCGACGTCGTCTTGATACGACTAACCCAAGGTTCTTCGACATAAAAGACGAATTGCACGATAACAGAATATTTCATCCGCCGTTCGAACCACTTAGATCACCAGCAGCTTCATACCGATATATCCGCAAGGATAACGACTTCATTGAGGAAGGTGATTTCTCCACCAGCAGGAGACCACCTTCTAGAGACTTACAGACAATCTGGAGAGACATACTCCAAATCTCTACGGACGAAGATACCTTCTACCGCATGGTGAAGGAACATCGTCCCATGGACTATGTTCTACGCTGGCCAGCAATTCAATCATTCGCAAGGGATCACTTCCAACGTAGATTTGTCCCTTACACTCCCCAGTTCATCGACTTCCCAAATCTACCACATCATGTCAGGGCATGGGCTAATCGCAACATATTATGCGTGAGTACAGAATTTACTTGCTGGGCCAGATCTATGGGATTACATAACTACTCCACCGGATCGTTGAAGTTTCATAATTATAATGATTTTGCTCTGTATAATGTAATAGACGACATAAGTTATAGCAAAATCACAACAGAAATAATGAAATCTTTATTGGGATGCCAAAAAGATTTCACAGTTAACATTAAGTATAAACCGGATAGGACCATCAACGGAGGTATTCCAACAATAGTTCTCTGCAATCCAGACATGGATTGGAGGGACATGATGTCACCTGACATCAGACTTTGGTGGGAAACAAACGTCGATGAGTACACCCTATCCCCAGAGGAAAAGTGGTTCGACTAA |
| Protein Sequence | MPSTSNFRFSAKNIFLTFAQCFLPKEYILNFLKSKPSSFDIFFICVCFETHQNGDPHIHAMVQMRRRLDTTNPRFFDIKDELHDNRIFHPPFEPLRSPAASYRYIRKDNDFIEEGDFSTSRRPPSRDLQTIWRDILQISTDEDTFYRMVKEHRPMDYVLRWPAIQSFARDHFQRRFVPYTPQFIDFPNLPHHVRAWANRNILCVSTEFTCWARSMGLHNYSTGSLKFHNYNDFALYNVIDDISYSKITTEIMKSLLGCQKDFTVNIKYKPDRTINGGIPTIVLCNPDMDWRDMMSPDIRLWWETNVDEYTLSPEEKWFD |
| NCBI Accession | YP_009553197.1 |
|---|---|
| Location | 2777-3616 |
| Protein Name | RepA |
| Coding Region | ATGCCTTCAACATCCAACTTCCGCTTCAGTGCAAAAAACATTTTCCTAACCTTCGCTCAATGCTTCCTCCCAAAGGAATATATCCTTAATTTCCTAAAATCAAAGCCCAGCAGCTTCGATATTTTTTTTATTTGCGTCTGTTTTGAAACTCATCAAAACGGAGACCCCCATATACATGCTATGGTCCAAATGCGACGTCGTCTTGATACGACTAACCCAAGGTTCTTCGACATAAAAGACGAATTGCACGATAACAGAATATTTCATCCGCCGTTCGAACCACTTAGATCACCAGCAGCTTCATACCGATATATCCGCAAGGATAACGACTTCATTGAGGAAGGTGATTTCTCCACCAGCAGGAGACCACCTTCTAGAGACTTACAGACAATCTGGAGAGACATACTCCAAATCTCTACGGACGAAGATACCTTCTACCGCATGGTGAAGGAACATCGTCCCATGGACTATGTTCTACGCTGGCCAGCAATTCAATCATTCGCAAGGGATCACTTCCAACGTAGATTTGTCCCTTACACTCCCCAGTTCATCGACTTCCCAAATCTACCACATCATGTCAGGGCATGGGCTAATCGCAACATATTATGCGTGAGTACAGAATTTGTACGCATTAATTTATGCTTTGACTGCAGAGCACATCTGCTAACAGAGTCTGAAATTCCCATACGCTCAATGCATTACTACTACTGTGATGCTTGCAGGAGCCCGACGCAAAGCCCAACAGGCCCAAGTCCATCTTCATCTGTGGACCTTCTCGCACGGGAAAGACTTGCTGGGCCAGATCTATGGGATTACATAACTACTCCACCGGATCGTTGA |
| Protein Sequence | MPSTSNFRFSAKNIFLTFAQCFLPKEYILNFLKSKPSSFDIFFICVCFETHQNGDPHIHAMVQMRRRLDTTNPRFFDIKDELHDNRIFHPPFEPLRSPAASYRYIRKDNDFIEEGDFSTSRRPPSRDLQTIWRDILQISTDEDTFYRMVKEHRPMDYVLRWPAIQSFARDHFQRRFVPYTPQFIDFPNLPHHVRAWANRNILCVSTEFVRINLCFDCRAHLLTESEIPIRSMHYYYCDACRSPTQSPTGPSPSSSVDLLARERLAGPDLWDYITTPPDR |
References More References in PubMed
| 1 |
Fontenele RS, et al. Viruses. 2018 Apr 2;10(4):169. doi: 10.3390/v10040169. PMID: 29614801 |
|---|---|
| 2 |
Complete genome sequence of a novel carlavirus infecting Passiflora edulis in China. Zheng L, et al. Arch Virol. 2026 May 28;171(6):193. doi: 10.1007/s00705-026-06663-9. PMID: 42207189 |
| 3 |
Genomics insight on passion fruit viral disease complexity. Munguti F, et al. Microbiol Spectr. 2025 Oct 7;13(10):e0034425. doi: 10.1128/spectrum.00344-25. Epub 2025 Aug 29. PMID: 40879375 |
| 4 |
Two Novel Geminiviruses Identified in Bees (Apis mellifera and Nomia sp.). Bandoo RA, et al. Viruses. 2024 Apr 13;16(4):602. doi: 10.3390/v16040602. PMID: 38675943 |
| 5 |
A New Potyvirus found in Passiflora incence in Florida. Baker CA, et al. Plant Dis. 2007 Feb;91(2):227. doi: 10.1094/PDIS-91-2-0227A. PMID: 30781012 |
| 6 |
Melzer MJ, et al. Plant Dis. 2014 Apr;98(4):571. doi: 10.1094/PDIS-06-13-0588-PDN. PMID: 30708703 |