French bean severe leaf curl virus
Basic Information
| Genus | Capulavirus |
|---|---|
| NCBI Assembly | GCF_000899975.1 |
| Isolate | India |
| Release date | 2015/2/22 |
| Submitter | Akram,M., Naimuddin |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
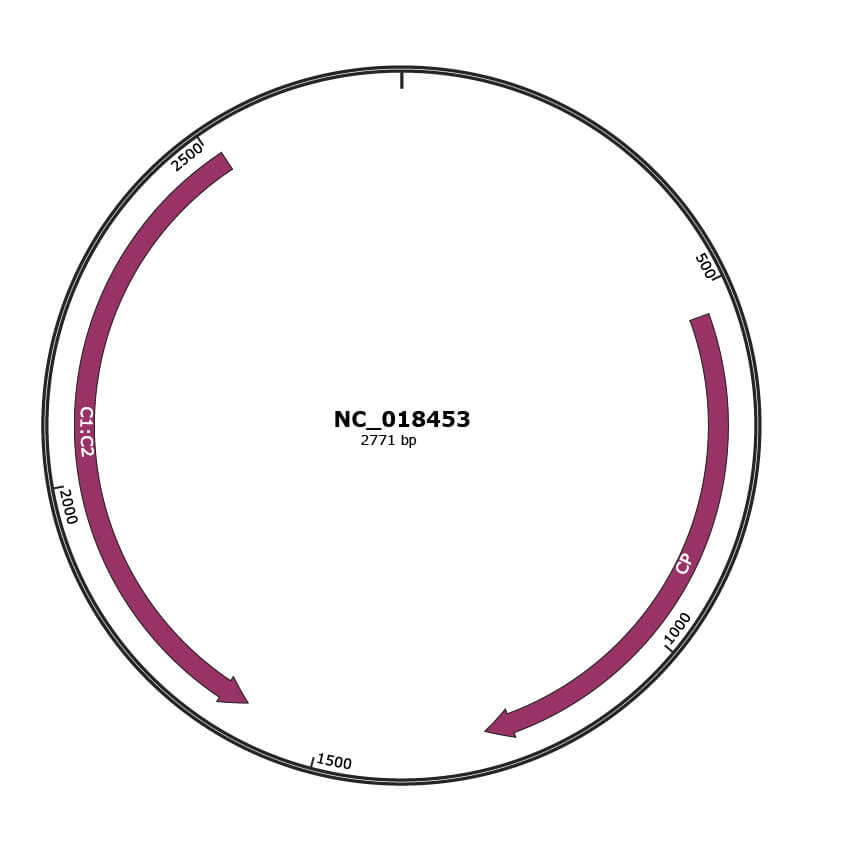
JBrowse
Genome
NC_018453
Gene Information
| NCBI Accession | YP_006590004.1 |
|---|---|
| Location | 540-1268 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGGCTCGCACAAGATCGGGGAGACAGTATTCGGCCCAGGCCCCATCTTGGGGCCGGAAGAAGACAAGAACACCCCGTTCGAGACCTACACTGATTGGGCCGATTCGAAGGCCCAATTACCAAATCAAGACCCGCTATGCCCCCCACAGACCTCAGACTAAGATACACTCCTTGTCTGCGGCAAGGGTTGTATCTGGGTCGGATAATGGTTATGGATGGCACATCTCGGACGTTCCTATTGGATCGGGCTTTGAAGATAGGCATAGTGATAAAATTAGAATTTTAAATTTTAATTTTAAGTTACAGATGAGGACTTCTCAACAGGGACAGAACACGTCATGCTGGCATAACGTGTATTTGTTTTTAGTTAGAGACAATAGTGGAGGAACAGCTGTTCCGAAATTTAATTCAATATGTATGATGGATAATTCCAACCCTTCCACTGCTGAGATTGACCATGATTCGAAGGATCGTTTCACGATTATGAGAAGATGGAGATTCCAGTTCAAAGGAAACAGCACATCTGGATCCGTTGCTTATGACTGTGCTAGGAATACTTATGATTTTAGGAAATTTGTTAAATTAAGTTCAATTACTGAATTTAAGAGTGCTACAAGTGGATCTTATGCTAATACGCAAAAGAACGCTTGGGTATTGTATTTTGTTCCTCAGACGTACGATATGACTGTTGACGGTCATTGTACGATCAAATATGTATCAATTGTGTAA |
| Protein Sequence | MARTRSGRQYSAQAPSWGRKKTRTPRSRPTLIGPIRRPNYQIKTRYAPHRPQTKIHSLSAARVVSGSDNGYGWHISDVPIGSGFEDRHSDKIRILNFNFKLQMRTSQQGQNTSCWHNVYLFLVRDNSGGTAVPKFNSICMMDNSNPSTAEIDHDSKDRFTIMRRWRFQFKGNSTSGSVAYDCARNTYDFRKFVKLSSITEFKSATSGSYANTQKNAWVLYFVPQTYDMTVDGHCTIKYVSIV |
| NCBI Accession | YP_006590005.1 |
|---|---|
| Location | 1609-2514 |
| Gene Name | C1:C2 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCTCGACGCAACAACAACTCCTTCCGTCTCCAGGGTAAGTCTATTTTTTTGACTTACCCAAAATGCCCCTTAACTCCACTTTTCGTAATTGATTACTTATATCAATTATTAAAGAATTTTAATCCTATATATGCTAGGGTCTGTACGGAGAATCACCAGGACGGTGAGCCACACCTTCACTGTCTTGTCCAACTGGACAAGAGGTTCAACACCACATCACAGAGATATTTTGACATCTCAGACCCAAACAGAACTGGGGTTTACCACCCCAATTGCCAGGTCCCAAGAAGAGATGCTGATGTGGCAGACTATATTGCCAAGGGAGGACAATTTGAGGAACGAGGAATACTTAGGGCAAGTAGAAGAAGCCCTAAGAAGAGCAGGGATTCAATATGGACAAACATCATCAATGAATCCACCTCCAAGTCCGAGTTTCTCGGTAGAGTCCAGATTGAGCAACCATATGTCTGGGCAACTCAATTACGAAATCTCGAATATGCAGCAAATAGTAAGTGGCCAGAGCAACCTAGTGTGTACATTCCCAAATGGACAGTGTTCAATAATGTACCCGAGCCCATTAGAGAATGGGCAGACACCAACTTATTCACAGTAAGTCTTCAATCCATGCAATTAGTTCAACCAGAAATATCAGTAACAGATATGCAATGGGCTCATAATTTAACAGAAGACTTTATTACTGATGAATGGATTGGTAATTCTGAAGATCCTGTTGTACAATCATTTTCAGGATCAGAGACCGGACCGCCCAGTGACTCTAATAATTGTTTGGCCCAACAAAAACAGGCAAAACAGCATGGGCCAGGAGCATGGGTCTACATAATTATTTTTGTGGGGGTGTTGATTTTAGTGTGTGGAATAATTTTGCTACTTACACCGTCATAG |
| Protein Sequence | MPRRNNNSFRLQGKSIFLTYPKCPLTPLFVIDYLYQLLKNFNPIYARVCTENHQDGEPHLHCLVQLDKRFNTTSQRYFDISDPNRTGVYHPNCQVPRRDADVADYIAKGGQFEERGILRASRRSPKKSRDSIWTNIINESTSKSEFLGRVQIEQPYVWATQLRNLEYAANSKWPEQPSVYIPKWTVFNNVPEPIREWADTNLFTVSLQSMQLVQPEISVTDMQWAHNLTEDFITDEWIGNSEDPVVQSFSGSETGPPSDSNNCLAQQKQAKQHGPGAWVYIIIFVGVLILVCGIILLLTPS |
References More References in PubMed
| 1 |
Navas-Castillo J, et al. Plant Dis. 1999 Jan;83(1):29-32. doi: 10.1094/PDIS.1999.83.1.29. PMID: 30845435 |
|---|---|
| 2 |
First Report of Tomato yellow leaf curl virus Infecting Common Bean (Phaseolus vulgaris) in Greece. Papayiannis LC, et al. Plant Dis. 2007 Apr;91(4):465. doi: 10.1094/PDIS-91-4-0465C. PMID: 30781210 |
| 3 |
Screening Common Bean (Phaseolus vulgaris) for Resistance to Tomato yellow leaf curl virus. Lapidot M. Plant Dis. 2002 Apr;86(4):429-432. doi: 10.1094/PDIS.2002.86.4.429. PMID: 30818720 |
| 4 |
Capulavirus and Grablovirus: two new genera in the family Geminiviridae. Varsani A, et al. Arch Virol. 2017 Jun;162(6):1819-1831. doi: 10.1007/s00705-017-3268-6. Epub 2017 Feb 17. PMID: 28213872 |
| 5 |
Pepper (Capsicum annuum) Is a Dead-End Host for Tomato yellow leaf curl virus. Morilla G, et al. Phytopathology. 2005 Sep;95(9):1089-97. doi: 10.1094/PHYTO-95-1089. PMID: 18943307 |
| 6 |
First Report of Tomato Yellow Leaf Curl Virus in Reunion Island. Peterschmitt M, et al. Plant Dis. 1999 Mar;83(3):303. doi: 10.1094/PDIS.1999.83.3.303B. PMID: 30845523 |
| 7 |
Ma Y, et al. Arch Virol. 2021 Sep;166(9):2573-2578. doi: 10.1007/s00705-021-05135-6. Epub 2021 Jun 20. PMID: 34148142 |
| 8 |
Maliano MR, et al. PLoS One. 2021 Apr 28;16(4):e0250066. doi: 10.1371/journal.pone.0250066. eCollection 2021. PMID: 33909644 |
| 9 |
A New Begomovirus Species Causing Tomato Leaf Curl Disease in Varanasi, India. Chakraborty S, et al. Plant Dis. 2003 Mar;87(3):313. doi: 10.1094/PDIS.2003.87.3.313A. PMID: 30812767 |
| 10 |
Ecology and management of whitefly-transmitted viruses of vegetable crops in Florida. Adkins S, et al. Virus Res. 2011 Aug;159(2):110-4. doi: 10.1016/j.virusres.2011.04.016. Epub 2011 Apr 28. PMID: 21549768 |