Wissadula golden mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000880135.1 |
| Isolate | Jamaica: St. Thomas parish |
| Release date | 2015/2/22 |
| Submitter | Collins,A.M., Roye,M.E. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
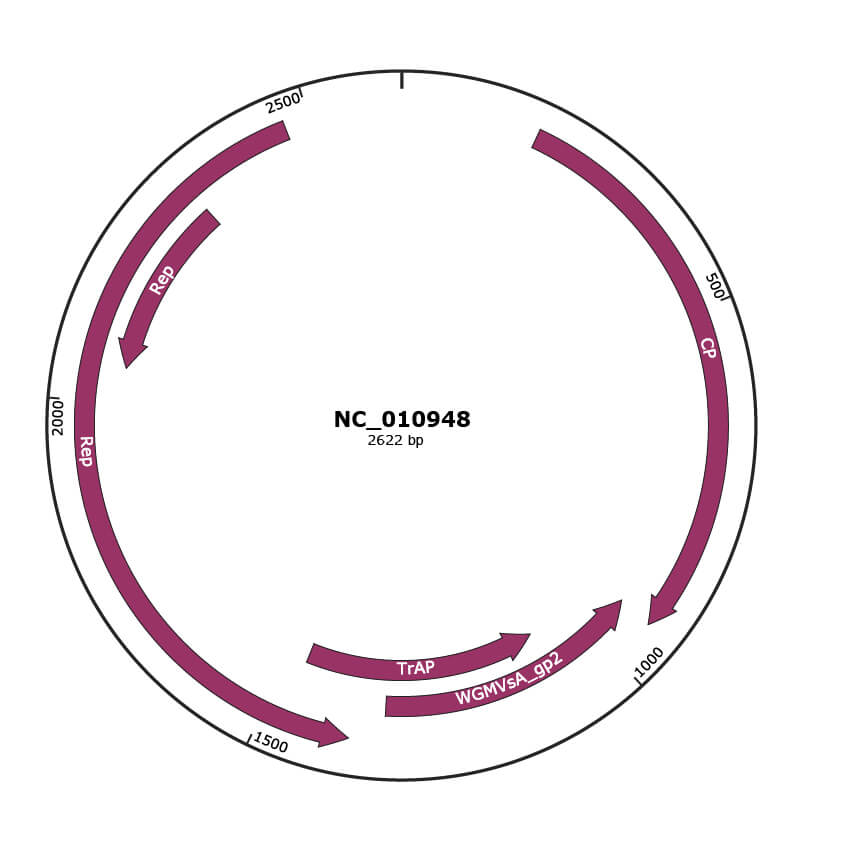
JBrowse
Genome
NC_010948
ACCGGATGGCCGCGTGCCCCCCCCCTTTTGCCGTACTATCACGCGCGCTCCCCTTTTCCTCACTCGCGCTCTCGTCCAATCATATTGCGTCTGCCGCGCCTAATTATTTTGAACAACTTGGGCCCTAAGTTGTTGAATGGTCTATAAATGAAAAGCTGATTGGCCCACGTACTTTAACTCAAAATGTCTAAGCGCGATGGCTCCTGGCGCTCGATCGCGGGAACCGCCAAGGTTAGGCGCATTTTGAATTTCTCCCCTCGTGGAGGTGGTGGTTTAAAACCGACCAGGGCCCAGGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAAGATATACCGGACGCTGAGAACCCCCGACATCCCAAGAGGATGTGAAGGCCCATGCAAGGTGCAGTCCTATGAACAGCGCCAGGATATCTCTCACGTGGGTAAGGTCATGTGTATATCCGATGTCACACGTGGTAACGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTTTAGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCATACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTCGACCGTATGGCACGCCTATGGATTTCGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCCACGGTTAAGAACGATCTCCGGGATCGTTACCAGGTTATGCACCGATTCTATGGGAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATTGTCAGGCGGTTCTGGAAGGTCAATAACCATGTGGTCTACAACCACCAGGAGGCTGGCAAATACGAGAACCACACGGAGAACGCTCTGTTATTGTATATGGCATGTACACATGCCTTTAATCCTGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGGTCATGAATTAATAAATTTTAAAATTTATTGAATGATTCTCCAGTACATGACTCACATACGATCTGGCTGTTGCAAAACGAACAGCTCTAATTACATTGTTAATGGAAATAACGCCTAACTGATCTAAGTACATGTTGACTAAGTGCATAAACCTAAGTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTATGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGGATGTGGTATACCCTTGTTCTGGTGTATAGCGGGTCCTCTACTCTGTATATCTTGAAATACAGGGGATTTTCGATCTCCCAGATATACACGCCATTCCCCGCCTGAGGTGCAGTGATGAGTTCCCCGGTGCGTGAATCCATGTCCCGTGCAGCCTATGTGGAAGTAGATGGAGCACCCGCACTCTATATCAATGCGTCTCCTCCTGATGGCCCTCCTCTTGGCCTGCCTGTGTGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGATCGCATTCTTGAGAGTCCAGTTCCTGAGGGATGCATTTTCCTCCTTGTCCAGGAACTCTTTATAGCTGGCACCCTCACCAGGATTGCATAGCACGATTGCTGGGATCCCTCCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTGGACTGCCAGTCTTTTTGGGCCCCCAGCAACTCTTTCCAGTGCTTTAGTTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCATTTCGTTTGAGAAGACCCGGGAATTGAAGTCTAAGTGTCCACTCAGGTAGTTATGTGGGCCTAACGCTCGAGCCCACATTGTCTTCCCTGTCCTCGAATCACCTTCGACTATGAGACTTACTGGTCTCTGTGGCCGCGCAGCGGAACCTCTTCCAAAATATTCATCTGCCCATTCAATCATCTCGTCCGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGAGCCCAAGGTTCCGGAGCCTTTGCGAATATTTTGGTAGCGTTATTAGTCAGGTTGTGATGTTGAAGGAAGAAATGTTGTGGTTGTTCTTCCTTTATTATTTGCAGAGCAGCCTCTGCTGAGCCTGCATTTAACGCCTTGGCATATGTATCGTTAACAGATTGCTGGCCTCCTCTAGCAGATCTGCCGTCGATCTGGAACTCTCCCCATTCCAGTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCGGGTTGAGGAAACCAGATCGAAGAATCTGTAATTCGTGCACTGGTACTTGCCCTCGAACTGGATGAGGACGTGGAGATGAGGCTCCCCATTTTCATGAAGTTCTCTGCAGATCTTGATGAACTTCTTGTTAACTGGAGTTGTTAGTTGTTGTAATTGGGAAAGTGTCTCCTCTTTGGTAAGAGAGCATTGGGGATATGTGATGAAATAATTTTTGGCTGAGACTTTAAAACGTTTAGCTGATGGCATTTTTGTAAAAAAGAGGTGTACCCCAGATGAGTTACCCCGATTGATCTCTCCAACTTCTGTGCTATGTATTGGGGTATGGGGTATTATATATACTAGAACCCTCAATAGGACTTTGGATCTCGTTCACACACGTGGCGGCCATCCGATATAATATT
Gene Information
| NCBI Accession | YP_001974399.1 |
|---|---|
| Location | 184-939 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGTCTAAGCGCGATGGCTCCTGGCGCTCGATCGCGGGAACCGCCAAGGTTAGGCGCATTTTGAATTTCTCCCCTCGTGGAGGTGGTGGTTTAAAACCGACCAGGGCCCAGGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAAGATATACCGGACGCTGAGAACCCCCGACATCCCAAGAGGATGTGAAGGCCCATGCAAGGTGCAGTCCTATGAACAGCGCCAGGATATCTCTCACGTGGGTAAGGTCATGTGTATATCCGATGTCACACGTGGTAACGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTTTAGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCATACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTCGACCGTATGGCACGCCTATGGATTTCGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCCACGGTTAAGAACGATCTCCGGGATCGTTACCAGGTTATGCACCGATTCTATGGGAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATTGTCAGGCGGTTCTGGAAGGTCAATAACCATGTGGTCTACAACCACCAGGAGGCTGGCAAATACGAGAACCACACGGAGAACGCTCTGTTATTGTATATGGCATGTACACATGCCTTTAATCCTGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGGTCATGAATTAA |
| Protein Sequence | MSKRDGSWRSIAGTAKVRRILNFSPRGGGGLKPTRAQEWVNRPMYRKPKIYRTLRTPDIPRGCEGPCKVQSYEQRQDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEQAIVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHAFNPVYATLKIRIYFYDSVMN |
| NCBI Accession | YP_001974400.1 |
|---|---|
| Location | 936-1334 |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACCGGGGAACTCATCACTGCACCTCAGGCGGGGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATATACAGAGTAGAGGACCCGCTATACACCAGAACAAGGGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCATACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTACTTAGGTTTATGCACTTAGTCAACATGTACTTAGATCAGTTAGGCGTTATTTCCATTAACAATGTAATTAGAGCTGTTCGTTTTGCAACAGCCAGATCGTATGTGAGTCATGTACTGGAGAATCATTCAATAAATTTTAAAATTTATTAA |
| Protein Sequence | MDSRTGELITAPQAGNGVYIWEIENPLYFKIYRVEDPLYTRTRVYHIQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSTYLLRFMHLVNMYLDQLGVISINNVIRAVRFATARSYVSHVLENHSINFKIY |
| NCBI Accession | YP_001974401.1 |
|---|---|
| Location | 1081-1470 |
| Protein Name | TrAP |
| Coding Region | ATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGATATAGAGTGCGGGTGCTCCATCTACTTCCACATAGGCTGCACGGGACATGGATTCACGCACCGGGGAACTCATCACTGCACCTCAGGCGGGGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATATACAGAGTAGAGGACCCGCTATACACCAGAACAAGGGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCATACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTACTTAG |
| Protein Sequence | MRSSSPSQPPSIKKAHRQAKRRAIRRRRIDIECGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPVFQDIQSRGPAIHQNKGIPHPDTVQPQPEESVASPQSIPELPSLDDIDDSFWVNLFT |
| NCBI Accession | YP_001974402.1 |
|---|---|
| Location | 1382-2467 |
| Gene Name | Rep |
| Protein Name | replication initiator |
| Coding Region | ATGCCATCAGCTAAACGTTTTAAAGTCTCAGCCAAAAATTATTTCATCACATATCCCCAATGCTCTCTTACCAAAGAGGAGACACTTTCCCAATTACAACAACTAACAACTCCAGTTAACAAGAAGTTCATCAAGATCTGCAGAGAACTTCATGAAAATGGGGAGCCTCATCTCCACGTCCTCATCCAGTTCGAGGGCAAGTACCAGTGCACGAATTACAGATTCTTCGATCTGGTTTCCTCAACCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAGTTCCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAATCTGTTAACGATACATATGCCAAGGCGTTAAATGCAGGCTCAGCAGAGGCTGCTCTGCAAATAATAAAGGAAGAACAACCACAACATTTCTTCCTTCAACATCACAACCTGACTAATAACGCTACCAAAATATTCGCAAAGGCTCCGGAACCTTGGGCTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCGGACGAGATGATTGAATGGGCAGATGAATATTTTGGAAGAGGTTCCGCTGCGCGGCCACAGAGACCAGTAAGTCTCATAGTCGAAGGTGATTCGAGGACAGGGAAGACAATGTGGGCTCGAGCGTTAGGCCCACATAACTACCTGAGTGGACACTTAGACTTCAATTCCCGGGTCTTCTCAAACGAAATGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAACTAAAGCACTGGAAAGAGTTGCTGGGGGCCCAAAAAGACTGGCAGTCCAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGGATCCCAGCAATCGTGCTATGCAATCCTGGTGAGGGTGCCAGCTATAAAGAGTTCCTGGACAAGGAGGAAAATGCATCCCTCAGGAACTGGACTCTCAAGAATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGA |
| Protein Sequence | MPSAKRFKVSAKNYFITYPQCSLTKEETLSQLQQLTTPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNYRFFDLVSSTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSVNDTYAKALNAGSAEAALQIIKEEQPQHFFLQHHNLTNNATKIFAKAPEPWAPPFPLSSFTNVPDEMIEWADEYFGRGSAARPQRPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSNEMEYNVIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKEFLDKEENASLRNWTLKNAIFITLTAPLYQEGTQAGQEEGHQEETH |
| NCBI Accession | YP_001974403.1 |
|---|---|
| Location | 2053-2316 |
| Gene Name | Rep |
| Protein Name | AC4 |
| Coding Region | ATGAAAATGGGGAGCCTCATCTCCACGTCCTCATCCAGTTCGAGGGCAAGTACCAGTGCACGAATTACAGATTCTTCGATCTGGTTTCCTCAACCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAGTTCCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAATCTGTTAACGATACATATGCCAAGGCGTTAA |
| Protein Sequence | MKMGSLISTSSSSSRASTSARITDSSIWFPQPGQHISIQTFRELNPAPTSSPTSTRTEIHWNGESSRSTADLLEEASNLLTIHMPRR |
References More References in PubMed
| 1 |
Collins AM, et al. Virus Genes. 2009 Dec;39(3):387-95. doi: 10.1007/s11262-009-0401-y. Epub 2009 Sep 20. PMID: 19768650 |
|---|---|
| 2 |
Collins A, et al. Virus Res. 2010 Jun;150(1-2):148-52. doi: 10.1016/j.virusres.2010.03.008. Epub 2010 Mar 25. PMID: 20347895 |
| 3 |
Roye ME, et al. Plant Dis. 1997 Nov;81(11):1251-1258. doi: 10.1094/PDIS.1997.81.11.1251. PMID: 30861729 |
| 4 |
Simmonds-Gordon RN, et al. Arch Virol. 2014 Oct;159(10):2815-8. doi: 10.1007/s00705-014-2112-5. Epub 2014 May 29. PMID: 24872185 |