Whitefly-associated begomovirus 1
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029115.1 |
| Isolate |
Guatemala |
| Release date |
2018/8/26 |
| Submitter |
Rosario,K., Seah,Y.M., Marr,C., Varsani,A., Kraberger,S., Stainton,D., Moriones,E., Polston,J.E., Duffy,S., Breitbart,M. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
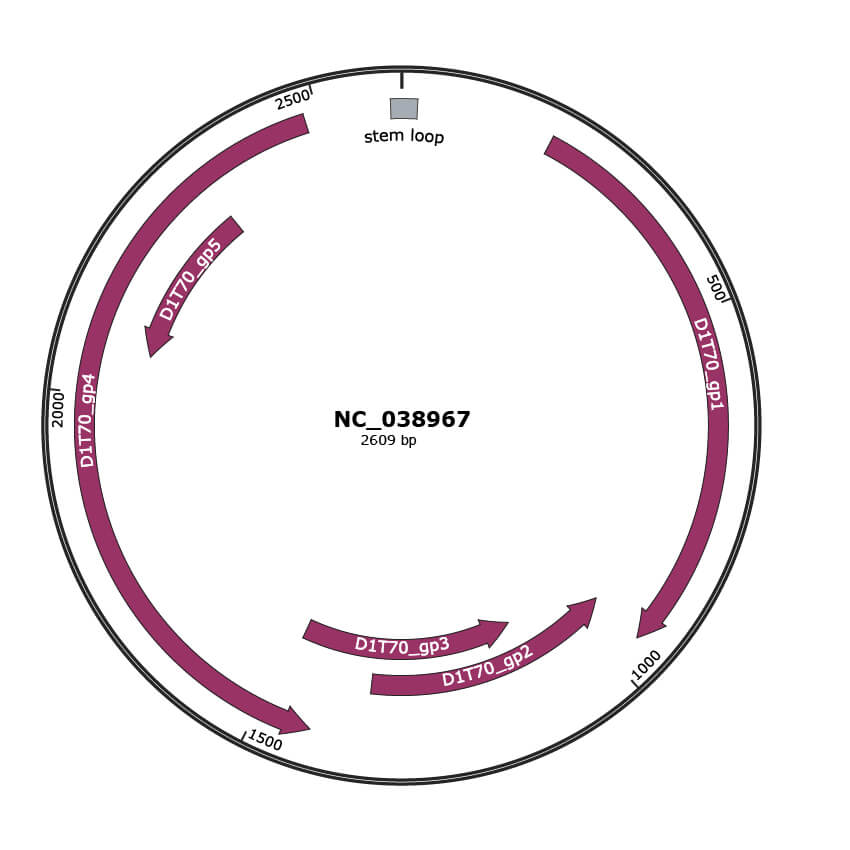
JBrowse
Genome
TAATATTACCGGATGGCCGCCCGCCCCGCCCGCTTTTTTTGACCCGTTCCTCGCGCGCAGACTGTATGGCCCCACATGCATAATGACAAAATCTACCGTCCAATCAGAACGCGCGTGTTAACCTTGATTGTCTACTCCTTCGCGCGTAAGTAGTCTATAAAGAGCTGCGCGCCCCACAAGACTCATTGTCTTTAACTCAAAATGCCGAAGCGGGAAGCCCCATGGCGCCTGGTGGAGACGCTCCCCAAGGTGAGTCGCAATGCCAACTACTCGCCCCTTCGCATATCGGGCCCAAAACCCGACAAGAGATCTGCCTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATCTACCGGATGATGAGAGGGCCCGACATTCCAAAGGGCTGCGAAGGGCCTTGTAAGGTCCAGTCTTACGAGCAGCGTCATGATATCTCCCACGTGGGAAAGGTCCTTTGCGTGTCTGATATCACCCGTGGTAATGGGCTCACCCATCGCGTCGGTAAGCGTTTCTGTATCAAGTCCATCTATATATTGGGCAAGGTCTGGATGGACGACAACATCAAGCTGAAGAACCACACGAACAGCGTCATGTTCTGGCTAGTTAGGGATAGGAGACCTTATGGCACCCCTTTGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACTGTTAAGAACGATCTCCGCGATCGTTTTCAAGTTATGCACAGGTTCTATGCCAAAGTCACAGGTGGTCAGTATGCCAGCAACGAGCAGGCTATAGTCAGGCGATTTTGGAAGATTAATAATTATGTTGTCTATAACCACCAGGAAGCTGGTAAATACGATAACCATACGGAGAACGCCCTTTTACTGTACATGGCATCTACGCATGCCTCTAACCCCGTGTATGCCACTTTGAAAATTCGGATCTATTTTTACGATTCGATATCCAATTAATAAAGTTTGAATTTTATTTCTTGAAATTCCAGTACATGACTTACATACGATCTGTCCGTTGCAAAATCAACGGCTCTAATGACATTGTTAATTCCTATTACGCCTAACTGATCTAAGTACAACATGACTAAATGTCTAAATCTAGCTAAATATGTCGTCCCAGAAGCTCGAAGCGACGTCGTCCAGACTTGGAAGTTCAGGAACGCCTTCTGTAGACCCAACTCCCTCCTGAGGTTGTGGTTGAACCGTATCTGGACGTGGTATATTCTTGTCCTGGTGTATGGTGGATCCTCTACTCTCTGTACCGTGAAATAGAGGGGATTGCGAATCTGCCAGATAAAAACGCCATTCTCTGCCTGAGGCGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCCGCGCAGTCTATGTGGAAGTAGATTGAACAGCCGCACTGCAAATCGATCCTCCTCCTGCGAGGCCTGGACTTAGCTATCCTGTGCCTGGTCTTGATAGAGGGGGGAGTCGAGGAAGACGAATTTAGCATTGTGTAATGTCCAGGCCTTTAATGATGCGTTTTCCTCTTTGTCGAGAAAATCTTTATAGCTGGCCCCCTCACCAGGATTGCAGAGCACGATTGAGGGTATTCCGCCTTTAATTTGAACTGGCTTACCGTACTTGCAGTTGCTTTGCCAGTCCTTCTGGGCCCCAATCAGCTCTTTCCAGTGCTTCATCTTTAGATATTGGGGGCTGATGTCATCTATGACGTTATATGACGCATCATTTGAATAGACCCTCGAGTTGAAGTCCAGGTGTCCACTGAGATAGTTATGTGGTCCCAACGAACGAGCCCACATCGTCTTTCCAGTTCTCGAATCACCTTCAACTATCAAACTAATAGGTCTTTCCGGCCGCGCAGCGGCATCGACACCGAAAAACTCATCCGCCCATTCCAGCATTTCTTCCGGCACTCTGTTAAAGGATGATAATGGAAAAGGAGAAGCCCATGGTTCCGGAGGCTTTGAGAAAATCCTGTCCAGGTTACTGGACAAGTTGTGATATTGAAATAGGAACTCTTTTGGGAGCTTCTCCCTTATGATCTGCATTGCCTCCTCCTTAGACGCGGCATTCAATGCCTCCGCTGCGGCGTCGTTAGCCGTCTGTTGACCTCCTCTAGCAGATCTACCGTCGACCTGGAATTCACCCCATTCGATAACATCTCCATCTTTGTCGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCGGTTTGGGGATACCAGGTCGAACTGTCTCTGATTCGTGCAGTTGTACTTCCCCTCGAATTGAAGAAGCACGTGGAGGTGAGGTTCCCCATTCTCGTGGAGTTCTCGACAGATTTTGATGAACTTCTTGTTCACAGGTGTTTGTATTTGCCTAATTTGCTCCAGTGCTTCTTCTTTTGGTAGACTGCAGTGCGGATAAGTGAGGAAATAGTTCTTGGCTTTAATTGAGAAAGAACCCTTTCGTGGCATTTTGGTAAATATGAGTGTTCCCCGATTGGGCTCTCTCACAAAACTCTGAGGAATTGGGGGAACTGGGGGAACATTTATAGTAAAAGCTCCTTCTCAGGATCTGGCAACACGTGGCGGCCATCCGTTA
Gene Information
|
NCBI Accession
|
YP_009508323.1
|
|
Location
|
202-957 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCCGAAGCGGGAAGCCCCATGGCGCCTGGTGGAGACGCTCCCCAAGGTGAGTCGCAATGCCAACTACTCGCCCCTTCGCATATCGGGCCCAAAACCCGACAAGAGATCTGCCTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATCTACCGGATGATGAGAGGGCCCGACATTCCAAAGGGCTGCGAAGGGCCTTGTAAGGTCCAGTCTTACGAGCAGCGTCATGATATCTCCCACGTGGGAAAGGTCCTTTGCGTGTCTGATATCACCCGTGGTAATGGGCTCACCCATCGCGTCGGTAAGCGTTTCTGTATCAAGTCCATCTATATATTGGGCAAGGTCTGGATGGACGACAACATCAAGCTGAAGAACCACACGAACAGCGTCATGTTCTGGCTAGTTAGGGATAGGAGACCTTATGGCACCCCTTTGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACTGTTAAGAACGATCTCCGCGATCGTTTTCAAGTTATGCACAGGTTCTATGCCAAAGTCACAGGTGGTCAGTATGCCAGCAACGAGCAGGCTATAGTCAGGCGATTTTGGAAGATTAATAATTATGTTGTCTATAACCACCAGGAAGCTGGTAAATACGATAACCATACGGAGAACGCCCTTTTACTGTACATGGCATCTACGCATGCCTCTAACCCCGTGTATGCCACTTTGAAAATTCGGATCTATTTTTACGATTCGATATCCAATTAA |
|
Protein Sequence
|
MPKREAPWRLVETLPKVSRNANYSPLRISGPKPDKRSAWVNRPMYRKPRIYRMMRGPDIPKGCEGPCKVQSYEQRHDISHVGKVLCVSDITRGNGLTHRVGKRFCIKSIYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPLDFGQVFNMFDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQAIVRRFWKINNYVVYNHQEAGKYDNHTENALLLYMASTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009508324.1
|
|
Location
|
954-1352 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTTTTTATCTGGCAGATTCGCAATCCCCTCTATTTCACGGTACAGAGAGTAGAGGATCCACCATACACCAGGACAAGAATATACCACGTCCAGATACGGTTCAACCACAACCTCAGGAGGGAGTTGGGTCTACAGAAGGCGTTCCTGAACTTCCAAGTCTGGACGACGTCGCTTCGAGCTTCTGGGACGACATATTTAGCTAGATTTAGACATTTAGTCATGTTGTACTTAGATCAGTTAGGCGTAATAGGAATTAACAATGTCATTAGAGCCGTTGATTTTGCAACGGACAGATCGTATGTAAGTCATGTACTGGAATTTCAAGAAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGVFIWQIRNPLYFTVQRVEDPPYTRTRIYHVQIRFNHNLRRELGLQKAFLNFQVWTTSLRASGTTYLARFRHLVMLYLDQLGVIGINNVIRAVDFATDRSYVSHVLEFQEIKFKLY |
|
NCBI Accession
|
YP_009508325.1
|
|
Location
|
1099-1485 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCTAAATTCGTCTTCCTCGACTCCCCCCTCTATCAAGACCAGGCACAGGATAGCTAAGTCCAGGCCTCGCAGGAGGAGGATCGATTTGCAGTGCGGCTGTTCAATCTACTTCCACATAGACTGCGCGGGACATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTTTTTATCTGGCAGATTCGCAATCCCCTCTATTTCACGGTACAGAGAGTAGAGGATCCACCATACACCAGGACAAGAATATACCACGTCCAGATACGGTTCAACCACAACCTCAGGAGGGAGTTGGGTCTACAGAAGGCGTTCCTGAACTTCCAAGTCTGGACGACGTCGCTTCGAGCTTCTGGGACGACATATTTAGCTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKTRHRIAKSRPRRRRIDLQCGCSIYFHIDCAGHGFTHRGTHHCASGREWRFYLADSQSPLFHGTESRGSTIHQDKNIPRPDTVQPQPQEGVGSTEGVPELPSLDDVASSFWDDIFS |
|
NCBI Accession
|
YP_009508326.1
|
|
Location
|
1427-2482 |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGCCACGAAAGGGTTCTTTCTCAATTAAAGCCAAGAACTATTTCCTCACTTATCCGCACTGCAGTCTACCAAAAGAAGAAGCACTGGAGCAAATTAGGCAAATACAAACACCTGTGAACAAGAAGTTCATCAAAATCTGTCGAGAACTCCACGAGAATGGGGAACCTCACCTCCACGTGCTTCTTCAATTCGAGGGGAAGTACAACTGCACGAATCAGAGACAGTTCGACCTGGTATCCCCAAACCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAAGATGGAGATGTTATCGAATGGGGTGAATTCCAGGTCGACGGTAGATCTGCTAGAGGAGGTCAACAGACGGCTAACGACGCCGCAGCGGAGGCATTGAATGCCGCGTCTAAGGAGGAGGCAATGCAGATCATAAGGGAGAAGCTCCCAAAAGAGTTCCTATTTCAATATCACAACTTGTCCAGTAACCTGGACAGGATTTTCTCAAAGCCTCCGGAACCATGGGCTTCTCCTTTTCCATTATCATCCTTTAACAGAGTGCCGGAAGAAATGCTGGAATGGGCGGATGAGTTTTTCGGTGTCGATGCCGCTGCGCGGCCGGAAAGACCTATTAGTTTGATAGTTGAAGGTGATTCGAGAACTGGAAAGACGATGTGGGCTCGTTCGTTGGGACCACATAACTATCTCAGTGGACACCTGGACTTCAACTCGAGGGTCTATTCAAATGATGCGTCATATAACGTCATAGATGACATCAGCCCCCAATATCTAAAGATGAAGCACTGGAAAGAGCTGATTGGGGCCCAGAAGGACTGGCAAAGCAACTGCAAGTACGGTAAGCCAGTTCAAATTAAAGGCGGAATACCCTCAATCGTGCTCTGCAATCCTGGTGAGGGGGCCAGCTATAAAGATTTTCTCGACAAAGAGGAAAACGCATCATTAAAGGCCTGGACATTACACAATGCTAAATTCGTCTTCCTCGACTCCCCCCTCTATCAAGACCAGGCACAGGATAGCTAA |
|
Protein Sequence
|
MPRKGSFSIKAKNYFLTYPHCSLPKEEALEQIRQIQTPVNKKFIKICRELHENGEPHLHVLLQFEGKYNCTNQRQFDLVSPNRSAHFHPNIQGAKSSSDVKSYIDKDGDVIEWGEFQVDGRSARGGQQTANDAAAEALNAASKEEAMQIIREKLPKEFLFQYHNLSSNLDRIFSKPPEPWASPFPLSSFNRVPEEMLEWADEFFGVDAAARPERPISLIVEGDSRTGKTMWARSLGPHNYLSGHLDFNSRVYSNDASYNVIDDISPQYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENASLKAWTLHNAKFVFLDSPLYQDQAQDS |
|
NCBI Accession
|
YP_009508327.1
|
|
Location
|
2068-2325 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCTCACCTCCACGTGCTTCTTCAATTCGAGGGGAAGTACAACTGCACGAATCAGAGACAGTTCGACCTGGTATCCCCAAACCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAAGATGGAGATGTTATCGAATGGGGTGAATTCCAGGTCGACGGTAGATCTGCTAGAGGAGGTCAACAGACGGCTAACGACGCCGCAGCGGAGGCATTGA |
|
Protein Sequence
|
MGNLTSTCFFNSRGSTTARIRDSSTWYPQTGQHISIRTFRELNPAPTSSPISTKMEMLSNGVNSRSTVDLLEEVNRRLTTPQRRH |