West African Asystasia virus 3
Basic Information
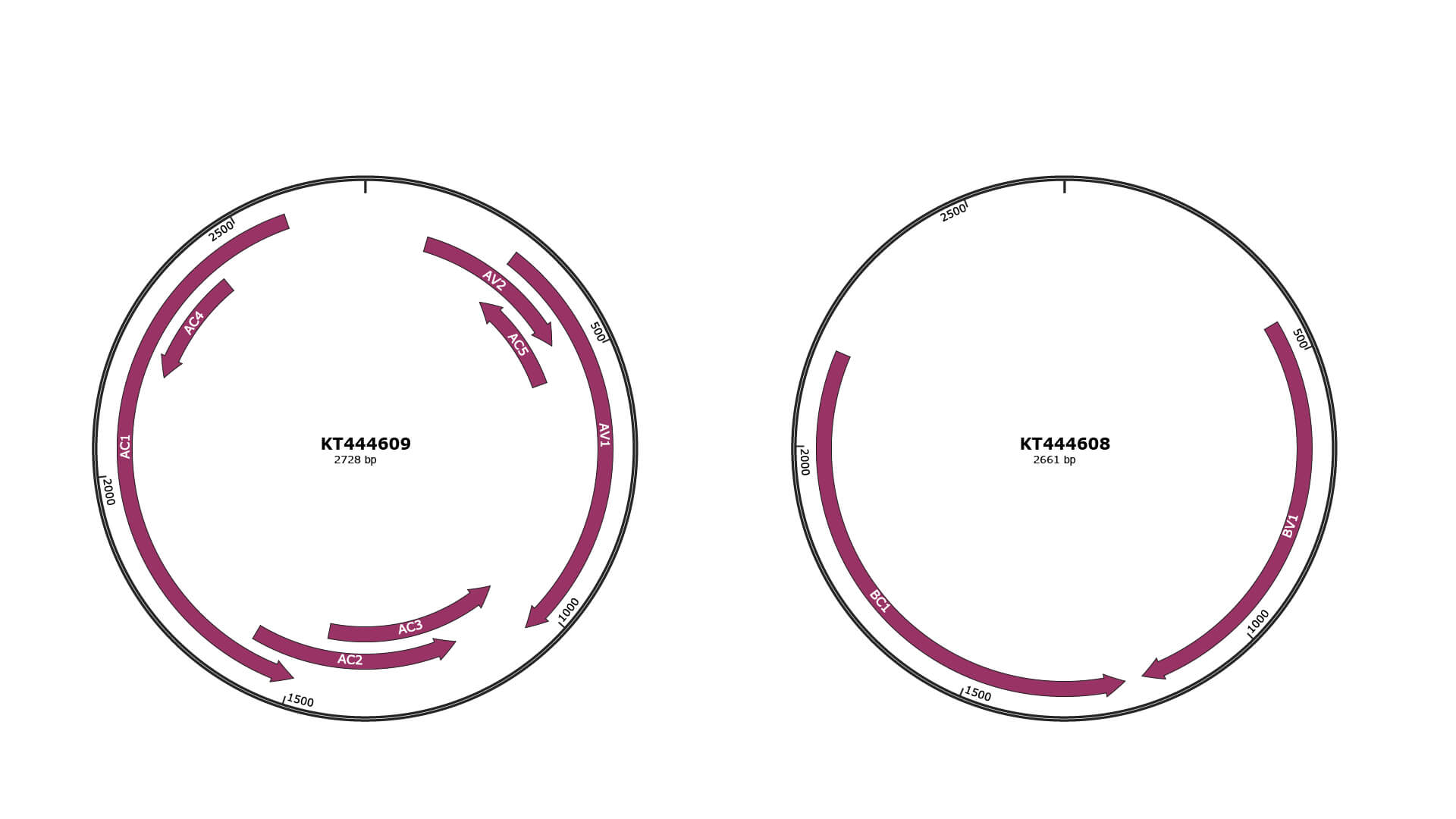
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCCCGCGCCGGGGTACACCTTTACACGTGGATTCCACCAATGAGGCTCCTCCATTATGCTTTAGCCATGTGCACCTGTCTATTTATTGGGGATGGTGTCGAGTCTTTTTCAAAGATGTGGGATCCACTACTGAATAGTTTCCCCCCCACTATTCATGGTTTCAGATGTATGCTTGCCCTAAAGTATCTTCTGCTGTTAGAGAATAATTACGAGGATAATTCCGTTGGTCAAGTGTACATCAGGGAATTGATTAGTGTGCTTCGTGCAGGAGATTATGTCAAAGCGTCCAGCAGATATTGTGATCTCTACCCCCGCATCCAAGGTACGTCGCCGCCTGAACTTCGACAGCCCTCGTGCCAGTGTACCAAATGTCCGCGTCACCAGAAGGAGAGTATGGGCGAACAGGCCCATGTATCGGAAACCAGCTCTGTACCGGAAGTATACCAGTCGTGATGTTCCCCGAGGTTGTGAAGGTCCGTGTAAGGTGCAGTCGTTTGATCAGCGTGATGATATTAAACATTTAGGTGTGGTTCGTTGTATTAGTGATGTTACTCGTGGTCCTGGTATAACACATCGCGTGGGGAAACGTTTCTGCATCAAGTCTGTATTGTTCACAGGCAAGATATGGATGGACGAGAACATCAAGAAGCAGAACCACACAAATATAGTTATATTCTTCCTCGTGCGAGATAGGAGACCGTATGGGAGCCCTCAGGATTTTGGTGATGTGTTTAATATGTTCGATAATGAGCCTAGTACTGCCACTGTGAAGAATGATTTGAGAGATAGGTATCAAGTGTTGAGGCGTTTCACATGCTCAGTTACAGGCGGACCTTCAGGATGCAAAGAACAGGCTTTAGTTCGTAGGTTTTATACGATTAATCATAATGTTGTTTACAACCATCAGGAAGCTGCTAAGTATGAGAACCACACTGAGAATGCTTTGCTGTTGTATATGGCATGTACTCATGCATCAAACCCTGTGTATGCCTCGATGAAAATCAGGATATATTTCTACGATTCCATTGGAAATTAATATAATTTAAATTTTATATCATGAGTACTGGCTACATCGATTGTTCCTTCCCATACATCATATAAAACATGGTCGACAGACCTGATTACATTGTTAATACTAATGACGCCTAATGCGTCTAGATATTTATGAACTTGTTCCGTGAAGGATCTCAGCAAGCTCGTACTCGAACTCGAGGAAGTCGTCCAGACCTGGAAGTTCATGTAGCATTTGTGAATTCCCAGGATCTTCCTGAGGTTGTGGTTGAACCGTATCTGCAGGTGTATGATGTTGTGTGACATGTTGAAGGGGGCTTGGTCGTATTGTGTTACTCTCATGTGTAGTGGATTCCTGATCTCCCAGGTGTATATGCCATTCCTTGCTTGAGGCGCAGTGATGTACTCCCCTGTGCGTGAATCCATAATTAGAACAGTTTCTAGAGATCAGGAATGAACACCCGCACTTCAAATTAATTGCTTGGCGTCTCTGACGCCTCTTCTTCGCCAGTCTGTGGCTCACTTTGATTGGAACTGGTGTAGAGAGGTGTTTCGAGACAAATGAAGGAGGCATTCTGATAGGCCCAAATTTTTAATTGTGCATTCCTAGGCTCCTCCAGGAATTCTTTATAGGAGGACTGTGGTCCTGGATTGCATAGGAAGATGGTGGGAATGCCTCCTTTAATTTGAACTGGTTTACTGTACTTGACATTGCTCTGCCAGTTATGCTGGGCCCCCATGAATTCTTTAAAGTGCTTCAGATAGTGCGGATCTACGTCATCAATGACGTTATACCAGGCATTATTATTGTATACCTTCAGTGATAGATCAATATGACCACACATATAGTTATGTGGTCCTAAAGATCTGGCCCACTTGGTCTTACCACTTCTTGTGGGCCCTTCTATTACAATTGATAATGGTCTATCTGGCCGCGCAGCGGGACCCATCACATTTTGCAGTGCCCATTCTTTCATAGCATCTGGAACATTGTTGAATGAGCTTGGATCGTAAGGGGATACATAAGGTATGGGCCTTGGAGCAAAAATGTGATTGGCATTAGCAGATATGTTGTGATATTGCAGAAAGAAGTTCTTAGGGTCTTTCTCTTTTATGATTTGCAATGCGGAATCTTTATCCGCTGCATTTAATGCTTCTGCATAAACATCTGCTAAACATTGACCCTCACCTCGTGCACTCCTTGGATCGATCTGGAACTGGCCATGGTCGATGAAATCGCCTCCCTTCTCGATGTATGATTTAACATCTGACGAGCTCTTAGCTCCCTGAATGTTTGGATGGTAAGGTGTTGGCCTGCTTGGGGATTCCAGGTCGAAGAATCTCTGATTTGTGCACTGGTATTTCCCTTCGAACTGGATGAGCACATGGAGATGAGGCATCCCATCTTGGTGTAATTCTCTGCAAACTCGGATGAATTTGATATTAGTTGGTGTAGGAAGGGAAATCAGTTTTTGTAATGCCTCTTCCTTTGGTATAGGGCACTGAGGATAAGTGAGGAAATAATTCTTGGCACTTATTTTAAAACGACCAGCCCTAGGCATATTTGGTTCTGGGGTACAAAACAAAGCTATATGAACTGGGGTAACTGGGGTACAATTTATATGGTGTACCCCAATGGCAAAATGGTAAATTATTAGACCTCCTTTAATTTGAATTTCCTTTTGGCGGCCATCCGTTCTAATATT
ACCGGATGGCCGCCCGCCCGGGGTACATGTGGGCCCCACTTAGTGGATTACACGTGGCATGTACGCTCCACGTGGTCCCCCCCTGTCGCTGTCAACATATCTACTTGGCCTCCAAGAAATTTCAAATTTGCCAAAATGTGTTATATATGGTGTTATGTACAGTAACCTCGTGTTCACACACTGTAGATATGTTGACTGGTCTTCGCCCGTACATTTTACCTACAAGTGCTAAAATGTGTTATTTTGGCTTAGTAGATGTCTATATATTTTGATTTATGTTAATCATCATGGTAAAATGCTGTGCTTCGAGCCTATAGTCCTGGTGTACATAGCCTTGAGTATTTATCTTTTCATAAATACATTGTGCTGGTCCTTTATATTTATATTTAGGCATATATATTCCCAGTAAGACGTCCTGTATTTCTGTGCATTTTCAAAATGTATTCTACGAAGAAACGTATGTATACTCCCTATAGGAATACCTCTTCAAGGAAATCGTATAGGCGTACGCCCTCGAGAATGCACATTCGTCCTCCTGTAAATCGTTCGTTAACCTTCGAGCAGCCTAAGAAAACCTATGTGCATCGCTCGTTGGAGGATATTCACTCTGTTAAGGAGATGTCAAACCAGGCTGATTATACTACTTTCGTGTCGTTTCCACCGTTATCCCATGATGGATCTACAGGTCGATCCTTCGACCACATAAAACTGTTAAGTCTCAAGATATCTGGGACACTACAGATAAAGCATGTGCCACAAGATCCTATGGATACATCGAATGCCTTCGAAGGTATTTTCATATGTTCAGTTTTACTGGACAAACGGCCCTTCTTGGCTGATGGAGTTAATGTGCTCCCTGCATTCCAGGAGGTATTCGGTGCCTATGAATGTGTTTACGGGACACCTCGCATTAAGGCAAATGTTGCCCACAGGTTTAGACTTCTTGGTTCGGTCAAGAAGTATGTGTCCGGTGATGGAACACGTTCCCAGGTCCCCTTTTTTTTCAGGAGACGCATCAGTGCTAGGAGATATCCGATATGGTCTTCGTTTAAAGACCCTGAGCCATCTCAGACCGGAGGAAATTATAGGAATGTAGTTAAGAACGCACTCATTGTAAATTACGCTTGGGTGTCTCTTCATTCAAGCAAGTGTACATTGTATGGGCAAAATGTATTGCATTATGTTGGATAATAAAATCATATTTTATTACTACATGTTTACATTACAACGCTTTGCTCTGGTGCTCTCTATTGTTTATGAGACATTTATTTATTGTCTCCTCTATGAGGGACGTTATATCTCTTCTTGTCATCGAACCCGATTGGACTTGTGATATCGAGTCACCCGGGTCCAATGCCGATGGGTCTAGTTTATTCAGTCTGGCGTATGGGTACTCCCTATTGGTGGTGCTCTCTCCCTCGAGATGCCTATCCCCGCCTATGTCGCTAGTGACTGGTCTGTCCAGTCTCATGGAGGCACATCTCAGGTTACTGGTTGTCATGATGTTTGCAGAGGATGACCCGATTGTTGACTTGGTTGCCCATGTTTCCCCTGGGAGAATGGTTATGGGTCGTGTGTTCCCCAGTATTCCCCTGCTTGCTGTTGGAGTTGGATTGAGTAATCGTCTTCTTGCCTCCCCTTTCTCGACTGACCAAAAGTCTACGCAATCCCTTGAGTACCCCTTAGATAGTATGTTTATTGTTGGGGGTTTGAATCTAATGTCAGTCGAGTGTTTAGCAGATGACAGTCTCAGTTTAGCTTTTATTGAGGCGAATTTAACGCCTTCGAGTATATTTGAGTCCTCTACTTTGTATACTATCTCCCATGGTGACTCATCTGCCACAGAGAAGAAAGAAGAAGAAAAATAGTGGAGATCCACGTTACATGCTATTGGGAATGTAAATGCTGCTTGTGCAGCCTCCTCCATGGATACTCTGTTGTCTCGTATCTCCACTATGACCGAACCAGTTGCATTGAATGGGACCTGATTCCTGTATTCTATTATTATATGGTCGATTTTCATACATCGACGCATAAGTCTGACCCTAGCCTGTTCTAGGGTTGATGGGAACTGCAGGTTTATTCTTGTTGCGTCATTAGTGAGGCTGTATTCAGCTCTTGCAGAGTCTATATACCTGTTATGTGTACCTGTATAGCTGGTATCCATACCTGTTAAGACGCAAGAAGAATTGAATTTATTTCCCAATGGCTGCGCAGCAGGTGTGACATGTGATTCAGCAATGGAACATGATTAATAAGCTCAGCAAACAGGACAATTTATTATATAAATTGTTAAATGAGAAGATTAATTAAAGTCACACATACCTTGAATTTCTCCTTCAATGCTGATAACTGATGAATATTAGGTTAAGCGATAGCAATATGAATATTTTATTCTCAGGGATCTGATATTTATAGGTGAATATTTTAGAGAGAGAAATTAGAGAGTTATTTCTGCAGGGGAAGGTAGAGAGAGAAAGTCCTGGGGGAAATGGAGAGGAAATGAGATCTGGGGTACAAAGCAAAATTATATGAACTGGGGTAACTGGGGTACAATTTATACCTTGTACCCCAAAGCCTTTATGGGCCTAAATGGGCCTTTAAAAAGCCCATTAGAAGCCCAAATGTCTTTTGTCCTATGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
ALQ10817.1
|
|
Location
|
126-464 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCACTACTGAATAGTTTCCCCCCCACTATTCATGGTTTCAGATGTATGCTTGCCCTAAAGTATCTTCTGCTGTTAGAGAATAATTACGAGGATAATTCCGTTGGTCAAGTGTACATCAGGGAATTGATTAGTGTGCTTCGTGCAGGAGATTATGTCAAAGCGTCCAGCAGATATTGTGATCTCTACCCCCGCATCCAAGGTACGTCGCCGCCTGAACTTCGACAGCCCTCGTGCCAGTGTACCAAATGTCCGCGTCACCAGAAGGAGAGTATGGGCGAACAGGCCCATGTATCGGAAACCAGCTCTGTACCGGAAGTATACCAGTCGTGA |
|
Protein Sequence
|
MWDPLLNSFPPTIHGFRCMLALKYLLLLENNYEDNSVGQVYIRELISVLRAGDYVKASSRYCDLYPRIQGTSPPELRQPSCQCTKCPRHQKESMGEQAHVSETSSVPEVYQS |
|
NCBI Accession
|
ALQ10816.1
|
|
Location
|
286-1047 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCAAAGCGTCCAGCAGATATTGTGATCTCTACCCCCGCATCCAAGGTACGTCGCCGCCTGAACTTCGACAGCCCTCGTGCCAGTGTACCAAATGTCCGCGTCACCAGAAGGAGAGTATGGGCGAACAGGCCCATGTATCGGAAACCAGCTCTGTACCGGAAGTATACCAGTCGTGATGTTCCCCGAGGTTGTGAAGGTCCGTGTAAGGTGCAGTCGTTTGATCAGCGTGATGATATTAAACATTTAGGTGTGGTTCGTTGTATTAGTGATGTTACTCGTGGTCCTGGTATAACACATCGCGTGGGGAAACGTTTCTGCATCAAGTCTGTATTGTTCACAGGCAAGATATGGATGGACGAGAACATCAAGAAGCAGAACCACACAAATATAGTTATATTCTTCCTCGTGCGAGATAGGAGACCGTATGGGAGCCCTCAGGATTTTGGTGATGTGTTTAATATGTTCGATAATGAGCCTAGTACTGCCACTGTGAAGAATGATTTGAGAGATAGGTATCAAGTGTTGAGGCGTTTCACATGCTCAGTTACAGGCGGACCTTCAGGATGCAAAGAACAGGCTTTAGTTCGTAGGTTTTATACGATTAATCATAATGTTGTTTACAACCATCAGGAAGCTGCTAAGTATGAGAACCACACTGAGAATGCTTTGCTGTTGTATATGGCATGTACTCATGCATCAAACCCTGTGTATGCCTCGATGAAAATCAGGATATATTTCTACGATTCCATTGGAAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPRASVPNVRVTRRRVWANRPMYRKPALYRKYTSRDVPRGCEGPCKVQSFDQRDDIKHLGVVRCISDVTRGPGITHRVGKRFCIKSVLFTGKIWMDENIKKQNHTNIVIFFLVRDRRPYGSPQDFGDVFNMFDNEPSTATVKNDLRDRYQVLRRFTCSVTGGPSGCKEQALVRRFYTINHNVVYNHQEAAKYENHTENALLLYMACTHASNPVYASMKIRIYFYDSIGN |
|
NCBI Accession
|
ALQ10822.1
|
|
Location
|
289-531 |
|
Protein Name
|
AC5 |
|
Coding Region
|
ATGTTTAATATCATCACGCTGATCAAACGACTGCACCTTACACGGACCTTCACAACCTCGGGGAACATCACGACTGGTATACTTCCGGTACAGAGCTGGTTTCCGATACATGGGCCTGTTCGCCCATACTCTCCTTCTGGTGACGCGGACATTTGGTACACTGGCACGAGGGCTGTCGAAGTTCAGGCGGCGACGTACCTTGGATGCGGGGGTAGAGATCACAATATCTGCTGGACGCTTTGA |
|
Protein Sequence
|
MFNIITLIKRLHLTRTFTTSGNITTGILPVQSWFPIHGPVRPYSPSGDADIWYTGTRAVEVQAATYLGCGGRDHNICWTL |
|
NCBI Accession
|
ALQ10820.1
|
|
Location
|
1044-1448 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGTACATCACTGCGCCTCAAGCAAGGAATGGCATATACACCTGGGAGATCAGGAATCCACTACACATGAGAGTAACACAATACGACCAAGCCCCCTTCAACATGTCACACAACATCATACACCTGCAGATACGGTTCAACCACAACCTCAGGAAGATCCTGGGAATTCACAAATGCTACATGAACTTCCAGGTCTGGACGACTTCCTCGAGTTCGAGTACGAGCTTGCTGAGATCCTTCACGGAACAAGTTCATAAATATCTAGACGCATTAGGCGTCATTAGTATTAACAATGTAATCAGGTCTGTCGACCATGTTTTATATGATGTATGGGAAGGAACAATCGATGTAGCCAGTACTCATGATATAAAATTTAAATTATATTAA |
|
Protein Sequence
|
MDSRTGEYITAPQARNGIYTWEIRNPLHMRVTQYDQAPFNMSHNIIHLQIRFNHNLRKILGIHKCYMNFQVWTTSSSSSTSLLRSFTEQVHKYLDALGVISINNVIRSVDHVLYDVWEGTIDVASTHDIKFKLY |
|
NCBI Accession
|
ALQ10819.1
|
|
Location
|
1174-1596 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCCTCCTTCATTTGTCTCGAAACACCTCTCTACACCAGTTCCAATCAAAGTGAGCCACAGACTGGCGAAGAAGAGGCGTCAGAGACGCCAAGCAATTAATTTGAAGTGCGGGTGTTCATTCCTGATCTCTAGAAACTGTTCTAATTATGGATTCACGCACAGGGGAGTACATCACTGCGCCTCAAGCAAGGAATGGCATATACACCTGGGAGATCAGGAATCCACTACACATGAGAGTAACACAATACGACCAAGCCCCCTTCAACATGTCACACAACATCATACACCTGCAGATACGGTTCAACCACAACCTCAGGAAGATCCTGGGAATTCACAAATGCTACATGAACTTCCAGGTCTGGACGACTTCCTCGAGTTCGAGTACGAGCTTGCTGAGATCCTTCACGGAACAAGTTCATAA |
|
Protein Sequence
|
MPPSFVSKHLSTPVPIKVSHRLAKKRRQRRQAINLKCGCSFLISRNCSNYGFTHRGVHHCASSKEWHIHLGDQESTTHESNTIRPSPLQHVTQHHTPADTVQPQPQEDPGNSQMLHELPGLDDFLEFEYELAEILHGTSS |
|
NCBI Accession
|
ALQ10818.1
|
|
Location
|
1496-2584 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCTAGGGCTGGTCGTTTTAAAATAAGTGCCAAGAATTATTTCCTCACTTATCCTCAGTGCCCTATACCAAAGGAAGAGGCATTACAAAAACTGATTTCCCTTCCTACACCAACTAATATCAAATTCATCCGAGTTTGCAGAGAATTACACCAAGATGGGATGCCTCATCTCCATGTGCTCATCCAGTTCGAAGGGAAATACCAGTGCACAAATCAGAGATTCTTCGACCTGGAATCCCCAAGCAGGCCAACACCTTACCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTTAAATCATACATCGAGAAGGGAGGCGATTTCATCGACCATGGCCAGTTCCAGATCGATCCAAGGAGTGCACGAGGTGAGGGTCAATGTTTAGCAGATGTTTATGCAGAAGCATTAAATGCAGCGGATAAAGATTCCGCATTGCAAATCATAAAAGAGAAAGACCCTAAGAACTTCTTTCTGCAATATCACAACATATCTGCTAATGCCAATCACATTTTTGCTCCAAGGCCCATACCTTATGTATCCCCTTACGATCCAAGCTCATTCAACAATGTTCCAGATGCTATGAAAGAATGGGCACTGCAAAATGTGATGGGTCCCGCTGCGCGGCCAGATAGACCATTATCAATTGTAATAGAAGGGCCCACAAGAAGTGGTAAGACCAAGTGGGCCAGATCTTTAGGACCACATAACTATATGTGTGGTCATATTGATCTATCACTGAAGGTATACAATAATAATGCCTGGTATAACGTCATTGATGACGTAGATCCGCACTATCTGAAGCACTTTAAAGAATTCATGGGGGCCCAGCATAACTGGCAGAGCAATGTCAAGTACAGTAAACCAGTTCAAATTAAAGGAGGCATTCCCACCATCTTCCTATGCAATCCAGGACCACAGTCCTCCTATAAAGAATTCCTGGAGGAGCCTAGGAATGCACAATTAAAAATTTGGGCCTATCAGAATGCCTCCTTCATTTGTCTCGAAACACCTCTCTACACCAGTTCCAATCAAAGTGAGCCACAGACTGGCGAAGAAGAGGCGTCAGAGACGCCAAGCAATTAA |
|
Protein Sequence
|
MPRAGRFKISAKNYFLTYPQCPIPKEEALQKLISLPTPTNIKFIRVCRELHQDGMPHLHVLIQFEGKYQCTNQRFFDLESPSRPTPYHPNIQGAKSSSDVKSYIEKGGDFIDHGQFQIDPRSARGEGQCLADVYAEALNAADKDSALQIIKEKDPKNFFLQYHNISANANHIFAPRPIPYVSPYDPSSFNNVPDAMKEWALQNVMGPAARPDRPLSIVIEGPTRSGKTKWARSLGPHNYMCGHIDLSLKVYNNNAWYNVIDDVDPHYLKHFKEFMGAQHNWQSNVKYSKPVQIKGGIPTIFLCNPGPQSSYKEFLEEPRNAQLKIWAYQNASFICLETPLYTSSNQSEPQTGEEEASETPSN |
|
NCBI Accession
|
ALQ10821.1
|
|
Location
|
2194-2427 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGATGCCTCATCTCCATGTGCTCATCCAGTTCGAAGGGAAATACCAGTGCACAAATCAGAGATTCTTCGACCTGGAATCCCCAAGCAGGCCAACACCTTACCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTTAAATCATACATCGAGAAGGGAGGCGATTTCATCGACCATGGCCAGTTCCAGATCGATCCAAGGAGTGCACGAGGTGAGGGTCAATGTTTAG |
|
Protein Sequence
|
MGCLISMCSSSSKGNTSAQIRDSSTWNPQAGQHLTIQTFRELRARQMLNHTSRREAISSTMASSRSIQGVHEVRVNV |