Catharanthus yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000928135.1 |
| Isolate | Pakistan:Islamabad |
| Release date | 2015/2/22 |
| Submitter | Mustujab,A., Tahir,M. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
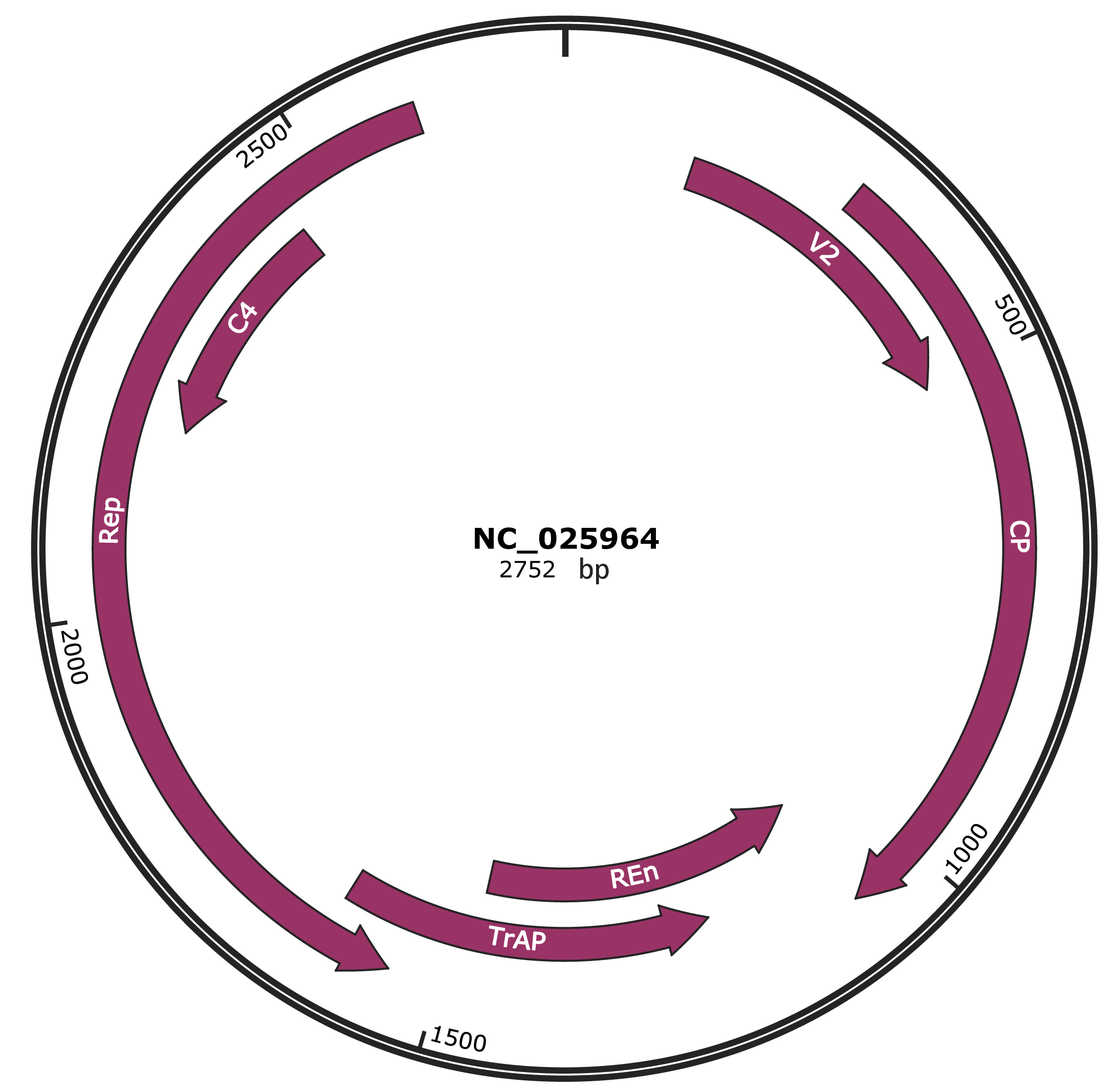
JBrowse
Genome
NC_025964
Gene Information
| NCBI Accession | YP_009112872.1 |
|---|---|
| Location | 142-507 |
| Gene Name | V2 |
| Protein Name | pre coat protein |
| Coding Region | ATGTGGGACCCACTAGTGAACGAGTTTCCMGAAACTGTTCATGGGTTTAGGTGCATGTTGGCAGTGAAATATCTCCAACTAGTTGCAGATACGTATTCTCCAGATACGGTGGGATACGATTTAATACGTGATTTAATTTCAGTAATAAGGGCCAGGAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTTCCGAGGGGATGTGA |
| Protein Sequence | MWDPLVNEFPETVHGFRCMLAVKYLQLVADTYSPDTVGYDLIRDLISVIRARNYVEATSRYNHFHARLEGTPPSELRQPICEPCCCPHCPRHKGKGMGEQAHEQKAQDVQDVQKSRCSEGM |
| NCBI Accession | YP_009112873.1 |
|---|---|
| Location | 302-1072 |
| Gene Name | CP |
| Protein Name | Coat Protein |
| Coding Region | ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTTCCGAGGGGATGTGAAGGCCCATGCAAGGTCCAGTCATTTGAGTCCAGACATGATATCCAGCACATTGGTAAAGTCATGTGTGTTAGTGATGTTACTCGTGGTATTGGGCTGACCCACAGGGTTGGCAAGAGGTTCTGTGTTAAGTCCGTTTATGTTCTGGGCAAAATCTGGATGGATGAGAACATCAAGACTAAGAATCATACGAATAGTGTCATGTTTTTTCTTGTTAGGGATCGTAGACCCGTTGACAAGCCTCAAGATTTTGGTGAGGTTTTTAACATGTTTGATAATGAGCCCAGCACGGCGACTGTGAAGAATGTTCATCGTGATAGATACCAGGTATTAAGGAAGTGGCACGCAACTGTGACAGGTGGTCTATATGCATCGAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGCAAGTATGAGAATCATACTGAGAATGCATTGATGTTGTATATGGCGTGTACGCACGCCTCTAACCCTGTGTATGCTACATTGAAGATACGGATCTATTTTTATGATTCAGTATCGAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPYASRAAAPIVRVTKARAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGIGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGLYASKEQALVKKFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
| NCBI Accession | YP_009112874.1 |
|---|---|
| Location | 1069-1473 |
| Gene Name | REn |
| Protein Name | Replication Enhancer Protein |
| Coding Region | ATGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATTCAAAATCCCCTCTACTTCAAGATAACAGAACACCACAGCAGGCCACTCAACATGAACCACGACATCATCAACATCAGGGTCCAGTTCAATCACAACCTCAGGAAGAGACTGGGGATAATGAAGTGTTACTTGGGCCTGAGGATCCACACTCGTTTACATCCTCAGACTGGGCATTTCTTAAGAGTCTTTAAGACTCAAGTTTTACGATATTTAGATAGTTTAGGCGTAATTAGTATAAATAATTGTATTAAGGCTTTCAGACATGTATTATATGATGTACTTGAGGGCACAATTAATGTAATTGAGAATCATGATATAAAATTCAATATTTATTAA |
| Protein Sequence | MDSRTGESITAAQAENGVYIWEIQNPLYFKITEHHSRPLNMNHDIINIRVQFNHNLRKRLGIMKCYLGLRIHTRLHPQTGHFLRVFKTQVLRYLDSLGVISINNCIKAFRHVLYDVLEGTINVIENHDIKFNIY |
| NCBI Accession | YP_009112875.1 |
|---|---|
| Location | 1214-1621 |
| Gene Name | TrAP |
| Protein Name | Transactivator Protein |
| Coding Region | ATGCAACCTTCATCTCCCTCGAAGGCCCACTATACTCAGGTTCCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAGAGCCATCCGGCGTAAGAGGGTTGATCTAAACTGTGGGTGCTCATACTACGTACACATCAACTGCCACAACCATGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATTCAAAATCCCCTCTACTTCAAGATAACAGAACACCACAGCAGGCCACTCAACATGAACCACGACATCATCAACATCAGGGTCCAGTTCAATCACAACCTCAGGAAGAGACTGGGGATAATGAAGTGTTACTTGGGCCTGAGGATCCACACTCGTTTACATCCTCAGACTGGGCATTTCTTAAGAGTCTTTAA |
| Protein Sequence | MQPSSPSKAHYTQVPIKVQHRAAKRRAIRRKRVDLNCGCSYYVHINCHNHGFTHRGIHHCSSSREWRVYLGDSKSPLLQDNRTPQQATQHEPRHHQHQGPVQSQPQEETGDNEVLLGPEDPHSFTSSDWAFLKSL |
| NCBI Accession | YP_009112876.1 |
|---|---|
| Location | 1551-2609 |
| Gene Name | Rep |
| Protein Name | replication associated Protein |
| Coding Region | ATGCCTCGTACACACCAGTTCCAAGTGAAGGCCAAAAATATCTTCCTCACTTATCCGAAATGTCCATTACCAAAGGAGCAAATGCTCGAACTCCTTAAAAACATTTCCTGTCCTTCTGATAAATTATTTATCAGAGTGTCACAAGAAAAACACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAAGGTAAATCCCAGTTCAGAAACCCCAGACATTTTGATGTCACTCACCCCTATACCTCAACTCAATTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCTGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGTTGCAGCAGAGGCGTTAAATGCCGGTTCTGCTGACGCAGCTTTAGCAATAATTAGGGAAAAACTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAATGTAATTTAGATAGGATTTTTACACCTCCTGTAGAGGTTTATGTTTCTCCTTTTTCGTCTTCTTCCTTTGATCAAGTTCCCGAAGAACTTGAGGAGTGGGCTGCCGAGAATGTTGTCAGTGCCGCTGCGCGGCCTTTGAGACCCATAAGTATAGTCATAGAGGGTGACAGTAGAACGGGAAAGACGATGTGGGCCAGATCACTTGGACCACATAATTATCTGTGTGGGCATCTAGACCTTAGCCCAAAGGTCTACAATAATGAGGCCTGGTACAACGTCATTGATGACGTTGATCCCCACTACCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCAAATACAAAGTACGGGAAGCCAGTTCAAATTAAAGGTGGTATTCCCACTATCTTCCTCTGCAATCCTGGGCCCAATTCCAGCTATAAGGAGTACCTGGACGAGGAGAAGAATAGCGCATTGAAAGCCTGGGCACTAAAAAATGCAACCTTCATCTCCCTCGAAGGCCCACTATACTCAGGTTCCAATCAAGGTCCAACACAGAGCTGCTAA |
| Protein Sequence | MPRTHQFQVKAKNIFLTYPKCPLPKEQMLELLKNISCPSDKLFIRVSQEKHQDGSLHIHALIQFKGKSQFRNPRHFDVTHPYTSTQFHPNFQGAKSSSDVKSYIEKDGDYIDWGEFQIDGRSARGGQQTANDVAAEALNAGSADAALAIIREKLPKDFIFQYHNLKCNLDRIFTPPVEVYVSPFSSSSFDQVPEELEEWAAENVVSAAARPLRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYNNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNSALKAWALKNATFISLEGPLYSGSNQGPTQSC |
| NCBI Accession | YP_009112877.1 |
|---|---|
| Location | 2195-2452 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAAGGTAAATCCCAGTTCAGAAACCCCAGACATTTTGATGTCACTCACCCCTATACCTCAACTCAATTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCTGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGTTGCAGCAGAGGCGTTAA |
| Protein Sequence | MGLCISMPSSSSKVNPSSETPDILMSLTPIPQLNSTQTSRELSPALMSSPTSRRTVITSTGVSFRSMEDLLEEVNRQLMMLQQRR |
References More References in PubMed
| 1 |
Khan A, et al. Plant Dis. 2015 Feb;99(2):292. doi: 10.1094/PDIS-08-14-0862-PDN. PMID: 30699593 |
|---|---|
| 2 |
Baker CA, et al. Plant Dis. 2004 Feb;88(2):223. doi: 10.1094/PDIS.2004.88.2.223B. PMID: 30812442 |
| 3 |
Ilyas M, et al. Arch Virol. 2013 Feb;158(2):505-10. doi: 10.1007/s00705-012-1498-1. Epub 2012 Oct 12. PMID: 23065111 |
| 4 |
First Report of a Tospovirus on Sunflower (Helianthus annus L.) from India. Subbaiah KV, et al. Plant Dis. 2000 Dec;84(12):1343. doi: 10.1094/PDIS.2000.84.12.1343B. PMID: 30831882 |
| 5 |
Alabi OJ, et al. Plant Dis. 2024 Aug;108(8):2494-2502. doi: 10.1094/PDIS-02-24-0459-RE. Epub 2024 Jul 29. PMID: 38568788 |
| 6 |
Identification of a new begomovirus infecting Duranta repens in Pakistan. Anwar S, et al. Arch Virol. 2018 Mar;163(3):809-813. doi: 10.1007/s00705-017-3672-y. Epub 2017 Dec 9. PMID: 29224128 |
| 7 |
First Report of Phytoplasma Infection in Freesia Plant. Kamińska M, et al. Plant Dis. 2001 Mar;85(3):336. doi: 10.1094/PDIS.2001.85.3.336B. PMID: 30832059 |