West African Asystasia virus 1
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000896655.1 |
| Release date |
2015/2/22 |
| Submitter |
Wyant,P., Strohmeier,S., Fischer,A., Schafer,B., Briddon,R.W., Krenz,B., Jeske,H., Wyant,P.S., Allinger,A. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
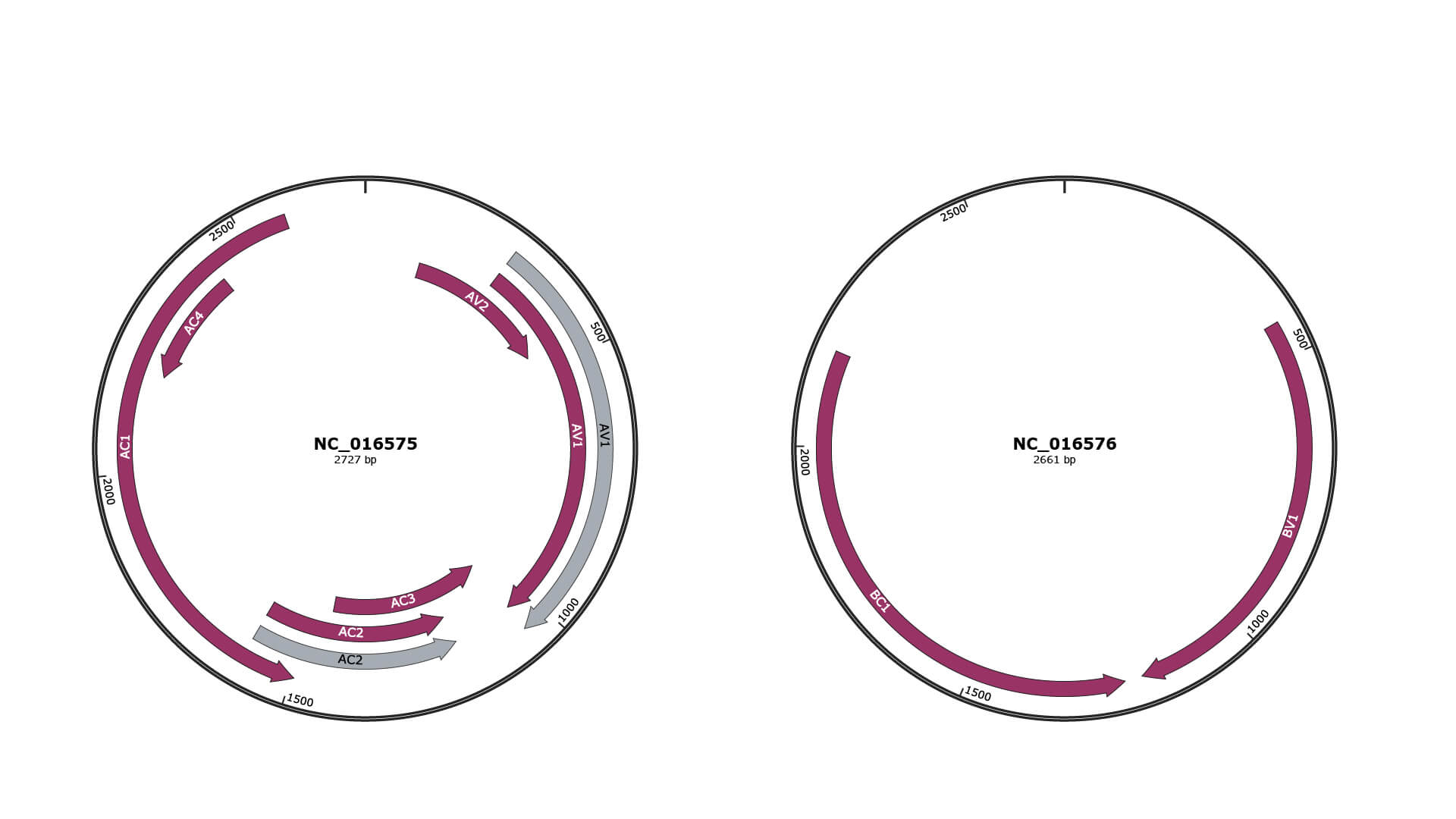
JBrowse
Genome
ACCGGATGGCCGCCCGCGCGGTGTACACCTTTACACGTGGATTCCACCAATCACGCTCCTGCATTATGCTTTTGCCATGTGCACTTGTCTATTTATTGGGTACTATGCATTGTCTTTTTCAAAGATGTGGGATCCACTGGTTAATAGTTTCCCCCCCACTATTCATGGTTTCAGATGTATGCTTGCCCTAAAGTATCTTCTGCTGTTAGAGAATAATTACGAGGATAATTCCGTTGGTCAAGTGTACATCAGGGAATTGATTAGTGTGCTTCGTGCAGGAGATTATGTCAAAGCGTCCAGCAGATATTGTGATCTCTACCCCCGCATCCAAGGTACGTCGCCGCCTGAACTTCGACAGCCCTCGTGCCAGTGTACCAAATGTCCGCGTCACCAGAAGGAGAGTATGGGCGAACAGGCCCATGTATCGGAAACCAGCTCTGTACCGGAAGTATACAAGTCGTGATGTCCCTCGTGGTTGTGAAGGTCCATGTAAGGTTCAGTCGTTCGATCAACGTGATGATGTTAAACATTTAGGTGTGGTTCGTTGCTTAAGTGATGTTACTCGTGGACCTGGTATTACTCATCGTGTGGGGAAACGGTTCTGCATTAAGTCTGTGTTATTTACAGGCAAGATATGGATGGATGACAACATTAAGAAGCAGAACCACACTAACATTGTCCTATTCTTCTTGGTGCGAGATAGGAGACCCTATGGAAGTCCTCAAGACTTTGGTGATGTGTTTAACATGTTCGACAATGAGCCAAGTACTGCAACTGTGAAGAATGATCTAAGAGATAGGTATCAGGTGTTGAGGCGTTTTTCTACATCTGTCACTGGTGGACCTTCGGCTTGTAAAGAGCAGGCATTAGTTCGTAGGTTTTTTACAATTAATCACAATGTCGTGTATAACCATCAGGAAGCTGCGAAATATGAGAATCACACTGAGAATGCACTGCTCTTGTATATGGCATGTACGCATGCTTCTAATCCTGTGTATGCGTCGCTTAAAGTCAGGATATATTTCTATGACTCTGTTGGGAATTAATAAATTTTAAATTTTATATCATGCGTACATATTACATCTATTGTTCCTTCCCATACATCATACAATACATGGTCTACAGACCTGATTACATTGTTTACACTAATGACGCCTAATGCGTCCAAATATCTATTAACTTGTATCTTGAAGGATCTCAGACAGCTCGTACTCGAACTCCAGGAAGTCGTCCAGACTTGGAAGTTCATGTAACATTTGTGTAGTCCCAATGCTTGCCTCAGGTTGTGGTTGAATCTGATCTGCAGGTGTATGATGTTGTACTGGTTGTTGAATGGTGTTTGGTCGTACTGTGTTACCCTCATGTGTAGTGGATTCCTGATCTCCCAGATGAATATGCCATTGTTTGCTTGATGTGCAGTGATGTACTCCCCTGTGCGAGAATCCATAATCTGTACAGCTTTCAGAGATCAGGAATGCACACCCGCACCTCAAATTAATTGTTTTGCGCCTCTGGCGCCTCTTCTTCGCCAGTCTGTGGCTCACTTTGATTGGTACTGGTGTAGAGAGGTGCTTCGAGGTATATGAAGGAGGCATTCTGTTCGGCCCAAATTTTTAATTGTGCATTTTTAGGCTCCTCCAGATATTCTTTATAGGAGGATTGTGGACCAGGATTGCAGAGGAAGATGGTGGGAATGCCTCCTTTAATTTGAACTGGTTTACTGTACTTGACGTTACTCTGCCAGTTATGCTGGGCCCCCATGAATTCTTTAAAATGCTTTAGATAGTGCGGATCTACGTCATCAATGACGTTATACCAGGCATTATTATTATAGACCTTCAATGATAGATCTATATGGCCACACATATAATTATGTGGCCCTAATGCACGGGCCCACTTTGTTTTACCACTCCTGCTGGGCCCCTCTATGACAATTGATAATGGTCTATCTGGCCGCGCAGCGGGTCCCATCACATTTTTTGATGCCCACTCCTTCATTGCTTCAGGAACATTGTCGAAAGAATTCGGATCGTAAGGGGATACATATGGTGTTATCTTTGGTGCAAAAATGTGATTAGCATTAGCAGATATGTTGTGATATTGCAGAAAGAAGTTTTTCGGGTCTTTCTCTTTTATAACCTGCAATGCGGAATCTTTATCCGCTGCATTTAATGCTTCTGCATAAACATCTGCTAAACATTGTCCCTCACCTCTTGCACTTCGTGGATCGACCTGGAATTGCCCATGGTCGATGAAATCGCCTCCCTTCTCGATGTATGATTTGACATCTGACGAGCTCTTAGCTCCCTGAATGTTTGGATGGTAAGGTGTTGGCCTGGTTGGGGATTCCAGGTCGAAGAATCTCTGATTTGTGCACTGGTATTTCCCTTCGAACTGTATGAGCACATGGAGATGAGGCTCCCCATCTTGGTGTAACTCTCTGCACACTCGAATGAATTTAATATTTGTTGGTGTACGAAGGGAAATAAGTTTCTGCAGAGCTTCCTCTTTAGATATAGAACACTGAGGGTAAGTGAGGAAATAATTCTTGGCGTTTATCTTAAAACGTCCAACACGAGGCATTTTTTGATCTGGGGTACAAACCAAAGTTATATGAACTGGTGTAACTGGGGTACAATTTATATGGTGTACTCCAATGGCAATATTGTAATTTTTGAAACCTCCTTTAATTCAAAATTCCCTTTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCCCGCGCGGTGTACATGTGGGCCCCACTTGGTGGATTACACGTGGCACTGTACGCTCCACGTGGTCCCCCCCTGTCGCTGTCAACATATCTACTTGGGCTCCAAGATATTTCAAATTCTGCTAAAATGTGTTATAATGTGTTATGTACAGTTACCTCGTGTTCACACACTGTAGATATGTTGACTGGTCGTCGCCCGTACATTTTACCCAAATGTGCTACAATGTGTTATATCTGGTTAGTAAATATCTATATATTTTGATTTATGTTAATCATCAGGGTAAAATGTTGTGTTTCGAAGCTATAGTCCTAGTGTACATAGCCTTGAGTATTTATCTCTTCATAAATACATTGTGCTGGTCATTTATATTTATATTTAGGCAAATATACTCGCAGTAAGACGTCCTGTATTTCTGTGCATTTTCAAAATGTATTCTACGAAGAAACGGTATTCTACGCCGTATAAGAATACGTTGTTGAAGAGACCATACAGGCGTACGCCCTCGAGAATGCACATTCGTCCTCCTGTAAATCGTGCGCTGACATTTGAGCAGCCTAAGAAGACCTATGTGAGTCGCAGCTTGGAGGATATTCACTCTGTGAAGGAAATGTCCAACCAGGCAGATTTCACTACGTTCGTGTCGTTTCCACCGTTATCCCATGATGGTACAACAGGTCGATCCTTCGACCACATAAAGCTCCTGAGTTTGAGGATTTCTGGTACTCTCCAGATTAAGCATGTATCGCAGGACCCTATGGATGCATCGAATGCTTTTGAAGGCATATTCATATGCTCGGTTCTCTTGGACAAGCGTCCGTTTCTCGCCGATGGAGTTAATTCATTGCCCGTTTTCCAGGAGTTATTCGGTGCTTATGAATGTGTTTACGGGACTCCTCGAATTAAGGCAAATGTTGCCCATAGGTTTAGACTTCTTGGTTCAGTCAAGAAGTATGTATCGGGTGATGGCACACGTTCTCAGCTCCCCTTTTCTTTCAGGAGACGCATTAGCACTAGGAGATATCCTATATGGTCTTCATTTAAAGACCCTGAACCAAATCAGACCGGAGGCAATTATAGGAATGTAGTTAAGAATGCGCTAATCGTTAATTACGCTTGGGTTTCTCTTAATTCAAGCAAGTGTACATTGTATGGCCAAAATGTATTGCATTATGTTGGATAATAAAATCATATTTTATTACTATATGTTTACATTACAATGCTTTGCTCTGGTGCTCTCTATTGTTTATCAGACATTTGTTTATGGTCTCCTCTATGAGGGACGTTATATCTCTTCTTGTCATCGAACCCGATTGGACTTGTGATATCGAGTCACCCGGGTCCAATGCCGATGGGTCTAGTTTATTTAGTCTGGCGTATGGGTACTCCCTATTGGTGGTGCTCTCTCCCTCGAGAATTCTATCCCCGCTGATGTCGCTAGTGAGTGGTCTGTCCATTCTCATTGAAGCACTTCGCAGGTTACTGGTTGTCATGATGTTTGCAGAGGATGAGCCGATTGTTGACTTGGTTGCCCATGTTTCCCCTGGCAGAATTGTTATGGGTCGTGTGTTTCCCAGTATTCCTCTGCTTGCTGTTGGAGTTGGATTGAGTAATCGTCTTCTTGCCTCCCCTTTCTCGACTGACCAAAAGTCTACGCAATCCCTTGAGTACCCCTTAGATAGTATGTTTATTGTTGGGGGTTTGAACCGTATGTCAGTCGAGTGCTTAGCAGATGATAGTCTTAGTTTAGCCTTGATTGAGGCGAATTTAACACCCTCGAGTATATTTGAGTCCTCAACCTTGTATACTATCTCCCATGGTGATTCATCTGCTACAGAGAAGAAAGAAGAAGAAAAATAGTGGAGATCTACGTTACATGCTATGGGGAATGTAAAAGCTGCTTGTGCAGCCTCCTCCATGGATACTCTGTTGTCTCTTATCTCCACTATTACCGAACCAGTTGCATTGAATGGGACTTGATTCCTGTATTCTATTATTATATGGTCGATTTTCATACATCGACGCATGAGTCTAACCCTAGTTTGTTCTAGGGTTGATGGGAACTGCAGGTTTATTCTTGTTGCGTCATTAGTGAGGCTGTATTCAGCTCTTGCAGAGTCTATATACCTGTTATGTGTACCTGTATAGCTGGTATCCATACCTGTTAAGACGCAAGAAGAATTGAATTTATTTTCAAAGGGCTGCGCAGCAGGTGTGACATGTGACTTAGCAATGGAACATGATTAATAAGCACAGCAAACAGGACAATTTATTATATAAATTGTTAAATGAGAAGATTAATTAAAGTCACACAGACCTTGAATTTCTCCTTCAATGCTGATAACTGATGAATATTAGGTTAAGCGATAGCAATATGAATATTTTATTATCAGGGATGGGATATTTATAGCAGAATTTTTTAGTGAGAGAAATTAGAGAGTTATTTCTGCAGGGGAAGGTAGAGAGAGAAAGTCCTGGGGGAAATGGAGAGGAAATGTGATCTGGGGTACAAACTAAAGTTATACGAACTGGTGTAACTGGGGTACAATTTATACTTGTACTCTAAACCCCTTTATGGGCCTATTTGGGCCTCATAAAAAGCCCATTAAAGCCCAAATGTCTTTTGTCCTATGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_004958229.1
|
|
Location
|
125-463 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCACTGGTTAATAGTTTCCCCCCCACTATTCATGGTTTCAGATGTATGCTTGCCCTAAAGTATCTTCTGCTGTTAGAGAATAATTACGAGGATAATTCCGTTGGTCAAGTGTACATCAGGGAATTGATTAGTGTGCTTCGTGCAGGAGATTATGTCAAAGCGTCCAGCAGATATTGTGATCTCTACCCCCGCATCCAAGGTACGTCGCCGCCTGAACTTCGACAGCCCTCGTGCCAGTGTACCAAATGTCCGCGTCACCAGAAGGAGAGTATGGGCGAACAGGCCCATGTATCGGAAACCAGCTCTGTACCGGAAGTATACAAGTCGTGA |
|
Protein Sequence
|
MWDPLVNSFPPTIHGFRCMLALKYLLLLENNYEDNSVGQVYIRELISVLRAGDYVKASSRYCDLYPRIQGTSPPELRQPSCQCTKCPRHQKESMGEQAHVSETSSVPEVYKS |
|
NCBI Accession
|
YP_004958230.1
|
|
Location
|
285-1046 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCAAAGCGTCCAGCAGATATTGTGATCTCTACCCCCGCATCCAAGGTACGTCGCCGCCTGAACTTCGACAGCCCTCGTGCCAGTGTACCAAATGTCCGCGTCACCAGAAGGAGAGTATGGGCGAACAGGCCCATGTATCGGAAACCAGCTCTGTACCGGAAGTATACAAGTCGTGATGTCCCTCGTGGTTGTGAAGGTCCATGTAAGGTTCAGTCGTTCGATCAACGTGATGATGTTAAACATTTAGGTGTGGTTCGTTGCTTAAGTGATGTTACTCGTGGACCTGGTATTACTCATCGTGTGGGGAAACGGTTCTGCATTAAGTCTGTGTTATTTACAGGCAAGATATGGATGGATGACAACATTAAGAAGCAGAACCACACTAACATTGTCCTATTCTTCTTGGTGCGAGATAGGAGACCCTATGGAAGTCCTCAAGACTTTGGTGATGTGTTTAACATGTTCGACAATGAGCCAAGTACTGCAACTGTGAAGAATGATCTAAGAGATAGGTATCAGGTGTTGAGGCGTTTTTCTACATCTGTCACTGGTGGACCTTCGGCTTGTAAAGAGCAGGCATTAGTTCGTAGGTTTTTTACAATTAATCACAATGTCGTGTATAACCATCAGGAAGCTGCGAAATATGAGAATCACACTGAGAATGCACTGCTCTTGTATATGGCATGTACGCATGCTTCTAATCCTGTGTATGCGTCGCTTAAAGTCAGGATATATTTCTATGACTCTGTTGGGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPRASVPNVRVTRRRVWANRPMYRKPALYRKYTSRDVPRGCEGPCKVQSFDQRDDVKHLGVVRCLSDVTRGPGITHRVGKRFCIKSVLFTGKIWMDDNIKKQNHTNIVLFFLVRDRRPYGSPQDFGDVFNMFDNEPSTATVKNDLRDRYQVLRRFSTSVTGGPSACKEQALVRRFFTINHNVVYNHQEAAKYENHTENALLLYMACTHASNPVYASLKVRIYFYDSVGN |
|
NCBI Accession
|
YP_004958231.1
|
|
Location
|
1043-1447 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAGTACATCACTGCACATCAAGCAAACAATGGCATATTCATCTGGGAGATCAGGAATCCACTACACATGAGGGTAACACAGTACGACCAAACACCATTCAACAACCAGTACAACATCATACACCTGCAGATCAGATTCAACCACAACCTGAGGCAAGCATTGGGACTACACAAATGTTACATGAACTTCCAAGTCTGGACGACTTCCTGGAGTTCGAGTACGAGCTGTCTGAGATCCTTCAAGATACAAGTTAATAGATATTTGGACGCATTAGGCGTCATTAGTGTAAACAATGTAATCAGGTCTGTAGACCATGTATTGTATGATGTATGGGAAGGAACAATAGATGTAATATGTACGCATGATATAAAATTTAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEYITAHQANNGIFIWEIRNPLHMRVTQYDQTPFNNQYNIIHLQIRFNHNLRQALGLHKCYMNFQVWTTSWSSSTSCLRSFKIQVNRYLDALGVISVNNVIRSVDHVLYDVWEGTIDVICTHDIKFKIY |
|
NCBI Accession
|
YP_004958232.1
|
|
Location
|
1176-1595 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCCTCCTTCATATACCTCGAAGCACCTCTCTACACCAGTACCAATCAAAGTGAGCCACAGACTGGCGAAGAAGAGGCGCCAGAGGCGCAAAACAATTAATTTGAGGTGCGGGTGTGCATTCCTGATCTCTGAAAGCTGTACAGATTATGGATTCTCGCACAGGGGAGTACATCACTGCACATCAAGCAAACAATGGCATATTCATCTGGGAGATCAGGAATCCACTACACATGAGGGTAACACAGTACGACCAAACACCATTCAACAACCAGTACAACATCATACACCTGCAGATCAGATTCAACCACAACCTGAGGCAAGCATTGGGACTACACAAATGTTACATGAACTTCCAAGTCTGGACGACTTCCTGGAGTTCGAGTACGAGCTGTCTGAGATCCTTCAAGATACAAGTTAA |
|
Protein Sequence
|
MPPSYTSKHLSTPVPIKVSHRLAKKRRQRRKTINLRCGCAFLISESCTDYGFSHRGVHHCTSSKQWHIHLGDQESTTHEGNTVRPNTIQQPVQHHTPADQIQPQPEASIGTTQMLHELPSLDDFLEFEYELSEILQDTS |
|
NCBI Accession
|
YP_004958233.1
|
|
Location
|
1495-2583 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCTCGTGTTGGACGTTTTAAGATAAACGCCAAGAATTATTTCCTCACTTACCCTCAGTGTTCTATATCTAAAGAGGAAGCTCTGCAGAAACTTATTTCCCTTCGTACACCAACAAATATTAAATTCATTCGAGTGTGCAGAGAGTTACACCAAGATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGGAAATACCAGTGCACAAATCAGAGATTCTTCGACCTGGAATCCCCAACCAGGCCAACACCTTACCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAATCATACATCGAGAAGGGAGGCGATTTCATCGACCATGGGCAATTCCAGGTCGATCCACGAAGTGCAAGAGGTGAGGGACAATGTTTAGCAGATGTTTATGCAGAAGCATTAAATGCAGCGGATAAAGATTCCGCATTGCAGGTTATAAAAGAGAAAGACCCGAAAAACTTCTTTCTGCAATATCACAACATATCTGCTAATGCTAATCACATTTTTGCACCAAAGATAACACCATATGTATCCCCTTACGATCCGAATTCTTTCGACAATGTTCCTGAAGCAATGAAGGAGTGGGCATCAAAAAATGTGATGGGACCCGCTGCGCGGCCAGATAGACCATTATCAATTGTCATAGAGGGGCCCAGCAGGAGTGGTAAAACAAAGTGGGCCCGTGCATTAGGGCCACATAATTATATGTGTGGCCATATAGATCTATCATTGAAGGTCTATAATAATAATGCCTGGTATAACGTCATTGATGACGTAGATCCGCACTATCTAAAGCATTTTAAAGAATTCATGGGGGCCCAGCATAACTGGCAGAGTAACGTCAAGTACAGTAAACCAGTTCAAATTAAAGGAGGCATTCCCACCATCTTCCTCTGCAATCCTGGTCCACAATCCTCCTATAAAGAATATCTGGAGGAGCCTAAAAATGCACAATTAAAAATTTGGGCCGAACAGAATGCCTCCTTCATATACCTCGAAGCACCTCTCTACACCAGTACCAATCAAAGTGAGCCACAGACTGGCGAAGAAGAGGCGCCAGAGGCGCAAAACAATTAA |
|
Protein Sequence
|
MPRVGRFKINAKNYFLTYPQCSISKEEALQKLISLRTPTNIKFIRVCRELHQDGEPHLHVLIQFEGKYQCTNQRFFDLESPTRPTPYHPNIQGAKSSSDVKSYIEKGGDFIDHGQFQVDPRSARGEGQCLADVYAEALNAADKDSALQVIKEKDPKNFFLQYHNISANANHIFAPKITPYVSPYDPNSFDNVPEAMKEWASKNVMGPAARPDRPLSIVIEGPSRSGKTKWARALGPHNYMCGHIDLSLKVYNNNAWYNVIDDVDPHYLKHFKEFMGAQHNWQSNVKYSKPVQIKGGIPTIFLCNPGPQSSYKEYLEEPKNAQLKIWAEQNASFIYLEAPLYTSTNQSEPQTGEEEAPEAQNN |
|
NCBI Accession
|
YP_004958234.1
|
|
Location
|
2193-2426 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGGAAATACCAGTGCACAAATCAGAGATTCTTCGACCTGGAATCCCCAACCAGGCCAACACCTTACCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAATCATACATCGAGAAGGGAGGCGATTTCATCGACCATGGGCAATTCCAGGTCGATCCACGAAGTGCAAGAGGTGAGGGACAATGTTTAG |
|
Protein Sequence
|
MGSLISMCSYSSKGNTSAQIRDSSTWNPQPGQHLTIQTFRELRARQMSNHTSRREAISSTMGNSRSIHEVQEVRDNV |
|
NCBI Accession
|
YP_004958235.1
|
|
Location
|
439-1191 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTCTACGAAGAAACGGTATTCTACGCCGTATAAGAATACGTTGTTGAAGAGACCATACAGGCGTACGCCCTCGAGAATGCACATTCGTCCTCCTGTAAATCGTGCGCTGACATTTGAGCAGCCTAAGAAGACCTATGTGAGTCGCAGCTTGGAGGATATTCACTCTGTGAAGGAAATGTCCAACCAGGCAGATTTCACTACGTTCGTGTCGTTTCCACCGTTATCCCATGATGGTACAACAGGTCGATCCTTCGACCACATAAAGCTCCTGAGTTTGAGGATTTCTGGTACTCTCCAGATTAAGCATGTATCGCAGGACCCTATGGATGCATCGAATGCTTTTGAAGGCATATTCATATGCTCGGTTCTCTTGGACAAGCGTCCGTTTCTCGCCGATGGAGTTAATTCATTGCCCGTTTTCCAGGAGTTATTCGGTGCTTATGAATGTGTTTACGGGACTCCTCGAATTAAGGCAAATGTTGCCCATAGGTTTAGACTTCTTGGTTCAGTCAAGAAGTATGTATCGGGTGATGGCACACGTTCTCAGCTCCCCTTTTCTTTCAGGAGACGCATTAGCACTAGGAGATATCCTATATGGTCTTCATTTAAAGACCCTGAACCAAATCAGACCGGAGGCAATTATAGGAATGTAGTTAAGAATGCGCTAATCGTTAATTACGCTTGGGTTTCTCTTAATTCAAGCAAGTGTACATTGTATGGCCAAAATGTATTGCATTATGTTGGATAA |
|
Protein Sequence
|
MYSTKKRYSTPYKNTLLKRPYRRTPSRMHIRPPVNRALTFEQPKKTYVSRSLEDIHSVKEMSNQADFTTFVSFPPLSHDGTTGRSFDHIKLLSLRISGTLQIKHVSQDPMDASNAFEGIFICSVLLDKRPFLADGVNSLPVFQELFGAYECVYGTPRIKANVAHRFRLLGSVKKYVSGDGTRSQLPFSFRRRISTRRYPIWSSFKDPEPNQTGGNYRNVVKNALIVNYAWVSLNSSKCTLYGQNVLHYVG |
|
NCBI Accession
|
YP_004958236.1
|
|
Location
|
1223-2167 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATACCAGCTATACAGGTACACATAACAGGTATATAGACTCTGCAAGAGCTGAATACAGCCTCACTAATGACGCAACAAGAATAAACCTGCAGTTCCCATCAACCCTAGAACAAACTAGGGTTAGACTCATGCGTCGATGTATGAAAATCGACCATATAATAATAGAATACAGGAATCAAGTCCCATTCAATGCAACTGGTTCGGTAATAGTGGAGATAAGAGACAACAGAGTATCCATGGAGGAGGCTGCACAAGCAGCTTTTACATTCCCCATAGCATGTAACGTAGATCTCCACTATTTTTCTTCTTCTTTCTTCTCTGTAGCAGATGAATCACCATGGGAGATAGTATACAAGGTTGAGGACTCAAATATACTCGAGGGTGTTAAATTCGCCTCAATCAAGGCTAAACTAAGACTATCATCTGCTAAGCACTCGACTGACATACGGTTCAAACCCCCAACAATAAACATACTATCTAAGGGGTACTCAAGGGATTGCGTAGACTTTTGGTCAGTCGAGAAAGGGGAGGCAAGAAGACGATTACTCAATCCAACTCCAACAGCAAGCAGAGGAATACTGGGAAACACACGACCCATAACAATTCTGCCAGGGGAAACATGGGCAACCAAGTCAACAATCGGCTCATCCTCTGCAAACATCATGACAACCAGTAACCTGCGAAGTGCTTCAATGAGAATGGACAGACCACTCACTAGCGACATCAGCGGGGATAGAATTCTCGAGGGAGAGAGCACCACCAATAGGGAGTACCCATACGCCAGACTAAATAAACTAGACCCATCGGCATTGGACCCGGGTGACTCGATATCACAAGTCCAATCGGGTTCGATGACAAGAAGAGATATAACGTCCCTCATAGAGGAGACCATAAACAAATGTCTGATAAACAATAGAGAGCACCAGAGCAAAGCATTGTAA |
|
Protein Sequence
|
MDTSYTGTHNRYIDSARAEYSLTNDATRINLQFPSTLEQTRVRLMRRCMKIDHIIIEYRNQVPFNATGSVIVEIRDNRVSMEEAAQAAFTFPIACNVDLHYFSSSFFSVADESPWEIVYKVEDSNILEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYSRDCVDFWSVEKGEARRRLLNPTPTASRGILGNTRPITILPGETWATKSTIGSSSANIMTTSNLRSASMRMDRPLTSDISGDRILEGESTTNREYPYARLNKLDPSALDPGDSISQVQSGSMTRRDITSLIEETINKCLINNREHQSKAL |