Watermelon chlorotic stunt virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000837565.1 |
| Release date | 2015/2/12 |
| Submitter | Briddon,R.W., Banks,G., Bedford,I.D., Pinner,M.S., Jones,P., Markham,P.G. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
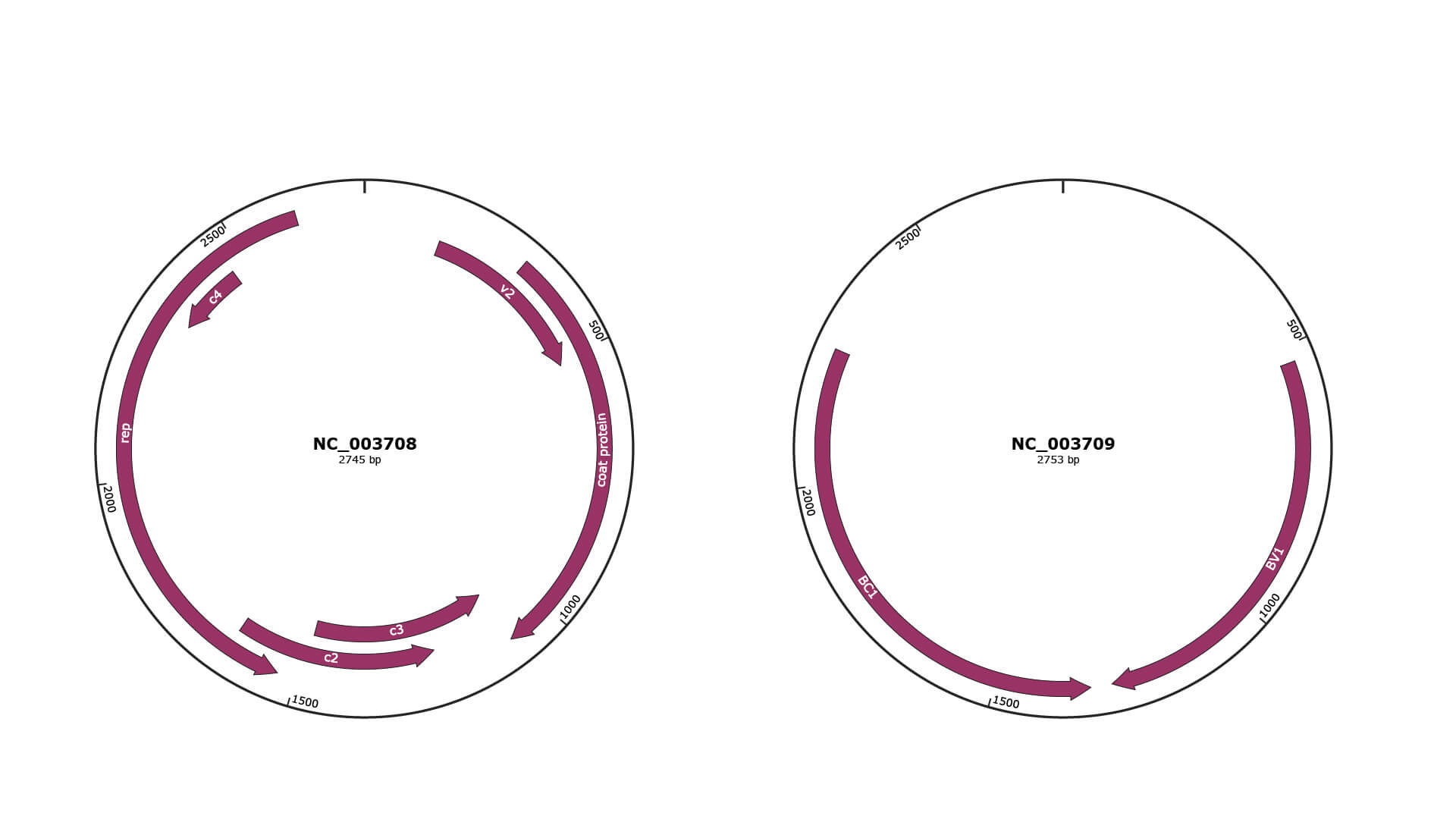
JBrowse
Genome
NC_003708
NC_003709
Gene Information
| NCBI Accession | NP_620293.1 |
|---|---|
| Location | 153-512 |
| Gene Name | v2 |
| Protein Name | V2 protein |
| Coding Region | ATGTGGGATCCATTGCTTAATGACTTTCCCGAGTCGGTTCACGGCTTTCGGTGTATGCTAGCTGTCAAGTACTTGCAGGCCGTTGAATCGACCTACGAGCCCAATACTTTGGGCCACGAATTGATCCGCGATCTGATTCTTGTCCTCCGGGCCCGTGATTATGGCGAAGCGAACAGGAGATATTCTCATTTCCACTCCCGTTTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCCTACATGAGCCGTGCTGTTGCCCCCACTGTCCTGGTCACAAGCAAGCGTCGACAATGGGCCAACAGGCCCATGTATCGAAAGCCCAGGATGTACAGGATGTATCGAAGCCCAGATGTCCCTAA |
| Protein Sequence | MWDPLLNDFPESVHGFRCMLAVKYLQAVESTYEPNTLGHELIRDLILVLRARDYGEANRRYSHFHSRFEGSSKTELRQPLHEPCCCPHCPGHKQASTMGQQAHVSKAQDVQDVSKPRCP |
| NCBI Accession | NP_620294.1 |
|---|---|
| Location | 313-1086 |
| Gene Name | coat protein |
| Protein Name | coat protein |
| Coding Region | ATGGCGAAGCGAACAGGAGATATTCTCATTTCCACTCCCGTTTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCCTACATGAGCCGTGCTGTTGCCCCCACTGTCCTGGTCACAAGCAAGCGTCGACAATGGGCCAACAGGCCCATGTATCGAAAGCCCAGGATGTACAGGATGTATCGAAGCCCAGATGTCCCTAAGGGCTGCGAAGGCCCATGCAAAGTTCAGTCGTACGAACAACGAGACGACGTTAAGCACACCGGTATCGTCCGGTGTGTCAGTGATGTTACTAGGGGGAGTGGAATCACTCATCGTGTCGGAAAAAGGTTTTGTGTGAAGTCTATATACATTCTTGGCAAGATCTGGATGGATGAGAACATAAAAAAACAAAATCATACGAATCAGGTCATGTTCTTTCTTGTTCGTGATCGTCGTCCAAATGGGTCCAGTCCACTGGACTTCGGACAGGTTTTTAATATGTTCGACAACGAGCCCAGCACTGCGACAGTTAAGAACGATCTGCGCGATCGTTTCCAAGTTATGCGAAAGTTTCATGCCACCGTGGTCGGTGGCCCCTCTGGGATGAAGGAGCAGGTGCTGGTAAAACGCTTCTTTCGTGTGTACAATCATGTGGTCTACAACCACCAAGAGGCTGCGAAGTATGAGAATCATACTGAGAATGCGATGTATGTATATGGCGTGACACACTTTTCGAATCCTGTGTATGCAACATTGAAAATTCGTATATACTTTTATGACTCAGTTACGAATTAA |
| Protein Sequence | MAKRTGDILISTPVSKVRRKLNFDSPYMSRAVAPTVLVTSKRRQWANRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSYEQRDDVKHTGIVRCVSDVTRGSGITHRVGKRFCVKSIYILGKIWMDENIKKQNHTNQVMFFLVRDRRPNGSSPLDFGQVFNMFDNEPSTATVKNDLRDRFQVMRKFHATVVGGPSGMKEQVLVKRFFRVYNHVVYNHQEAAKYENHTENAMYVYGVTHFSNPVYATLKIRIYFYDSVTN |
| NCBI Accession | NP_620295.1 |
|---|---|
| Location | 1083-1487 |
| Gene Name | c3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCTCGCACCGGGGAATACATTACTGCGGATCAAGCATGGAATGGCGTGTTTACCTGGAAGATAAACAACCCCCTATATTTCACGATAACAGAACACCACCAACGCCCCTTTCTTTGCCGTCACGACATAATACAAATGCAAATACGATTCAACCACAACCTTCGGAGGGCGTTGGGGATTCACAAAGCTTTCCTGAACTTCCGAATCTGGACGACTTTACGGCCTCAGACTGGTCGTTTCTTAAGGGTATTTAGAACGCAAGTTCTGAAATACCTCGATATGTTAGGTGTAATTAGTCTAAATTTGGTTGTTAGGGCCGTAAGTCATGTATTGGAAAATGTCCTTATTGGGACAATCGATGTACAAGAAAAACACGTAATAAAATTCGATCTTTATTAA |
| Protein Sequence | MDSRTGEYITADQAWNGVFTWKINNPLYFTITEHHQRPFLCRHDIIQMQIRFNHNLRRALGIHKAFLNFRIWTTLRPQTGRFLRVFRTQVLKYLDMLGVISLNLVVRAVSHVLENVLIGTIDVQEKHVIKFDLY |
| NCBI Accession | NP_620296.1 |
|---|---|
| Location | 1228-1635 |
| Gene Name | c2 |
| Protein Name | C2 protein |
| Coding Region | ATGCCGAATTCGTCTTCCTCACAGAACCTCTCTTCTCAGCCGAGCATCAAGATCAGACACAGACTCGCCAAAAAGAAGACGATTCGGCGACGACGCGTTGATCTAAAGTGCGGTTGCTCATATTACCTGCATATCTCGTGCCAGAATCATGGATTCTCGCACCGGGGAATACATTACTGCGGATCAAGCATGGAATGGCGTGTTTACCTGGAAGATAAACAACCCCCTATATTTCACGATAACAGAACACCACCAACGCCCCTTTCTTTGCCGTCACGACATAATACAAATGCAAATACGATTCAACCACAACCTTCGGAGGGCGTTGGGGATTCACAAAGCTTTCCTGAACTTCCGAATCTGGACGACTTTACGGCCTCAGACTGGTCGTTTCTTAAGGGTATTTAG |
| Protein Sequence | MPNSSSSQNLSSQPSIKIRHRLAKKKTIRRRRVDLKCGCSYYLHISCQNHGFSHRGIHYCGSSMEWRVYLEDKQPPIFHDNRTPPTPLSLPSRHNTNANTIQPQPSEGVGDSQSFPELPNLDDFTASDWSFLKGI |
| NCBI Accession | NP_620297.1 |
|---|---|
| Location | 1535-2620 |
| Gene Name | rep |
| Protein Name | rep protein |
| Coding Region | ATGAGGCCTCCCCGCTTTAGAATACAAGCGAAAAACATTTTCCTCACATATCCCAGGTGCTCTCTCTCCAAAGAAGAGCTACTTTCCTTTTTAGTCGGCCTCTCCCTTCCGTCGAACCTAAAATACGTCAAGGTGTGCAGAGAACTGCACCAGAATGGGGAACCTCATCTCCATGTGCTCCTGCAGTTCGCCGGAAAGATCACAATCACAGACAATCGCCTCTTCGATCACGTACACCCAAGCCGTAGCGCCTGTTTCCACCCCAACATACAAAGCGCTAAGTCCAGTACAGACGTGAAGTCTTACCTGGACAAGGACGGCGACATCGTCGAGTGGGGCAAGTTTCAAATCGACGGTCGATCTGCAAGGGGTGGACAACAGACAGCTAACGACGCTTACGCCACGGCGCTTAACATGAGTAATAAAGGGGAGGCTATGTCTGTGATCAAGGAGCTCGCACCGAAGGACTACGTCCTTCACTACCACAATATCAGGTCAAATTTGGATCGAATCTTCGAAGAACCTGTGGCTCCTTTCGTGTGTCCTTTTCCGATGTCGTCTTTCACGTTGCTACCGCCTGAGCTCGTTGATTGGGCATCAACGAACGTTTGTTCTTCCGCTGCGCGGCCGTGGAGACCGAAGAGTATCGTGGTAGAGGGTGAGAGTCGTACGGGAAAGACGATGTGGGCCCGATCATTAGGACCACATAATTACCTATGTGGTCACCTTGACCTGAGTCCAAAGATCTACAGCAACGATGCGTGGTACAACGTCATTGATGACGTCGACCCGCATTATCTAAAGCACTTCAAAGAGTTCATGGGGGCCCAGCGTGATTGGCAAAGCAACACGAAATACGGAAAGCCGATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTTTGCAATCCGGGCCCATCTTCTTCGTATAAAGAGTTTCTAGAGGAGGAAAAGAACTATGCACTAAAAGAGTGGGCGGAAAAGAATGCCGAATTCGTCTTCCTCACAGAACCTCTCTTCTCAGCCGAGCATCAAGATCAGACACAGACTCGCCAAAAAGAAGACGATTCGGCGACGACGCGTTGA |
| Protein Sequence | MRPPRFRIQAKNIFLTYPRCSLSKEELLSFLVGLSLPSNLKYVKVCRELHQNGEPHLHVLLQFAGKITITDNRLFDHVHPSRSACFHPNIQSAKSSTDVKSYLDKDGDIVEWGKFQIDGRSARGGQQTANDAYATALNMSNKGEAMSVIKELAPKDYVLHYHNIRSNLDRIFEEPVAPFVCPFPMSSFTLLPPELVDWASTNVCSSAARPWRPKSIVVEGESRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPSSSYKEFLEEEKNYALKEWAEKNAEFVFLTEPLFSAEHQDQTQTRQKEDDSATTR |
| NCBI Accession | NP_620298.1 |
|---|---|
| Location | 2323-2466 |
| Gene Name | c4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCTCATCTCCATGTGCTCCTGCAGTTCGCCGGAAAGATCACAATCACAGACAATCGCCTCTTCGATCACGTACACCCAAGCCGTAGCGCCTGTTTCCACCCCAACATACAAAGCGCTAAGTCCAGTACAGACGTGA |
| Protein Sequence | MGNLISMCSCSSPERSQSQTIASSITYTQAVAPVSTPTYKALSPVQT |
| NCBI Accession | NP_620299.1 |
|---|---|
| Location | 531-1286 |
| Gene Name | BV1 |
| Protein Name | BV1 |
| Coding Region | ATGCGTCGCTATGATGGGACACCTCAAAGTACGCGTGGACGAAAGCGGAAGCAGTTCTCTCGCCCGTTCAAGTCTGTGCTTTTTAGACGCCGTCAGGCGTCGAGGCGTCTGTTTGCCGAAAAGCCACGCGAGAAACTCTCACGCCGTTGCCTGGAGGATGTTCACAGTGGGCCGTCTTATGCACTGATGAATCAGTGCGACGTGACATCGTATGTGACGTACCCTATTCTTGGTCTAGAGGGCAACGGGGGACGTAGCAGGGACTTTATTAAGCTGATGAACGTGCGCGTTTCTGGCACGATCAACGTGACCCCTTTGCCTGCAGAGCCCATGTCCGATCGTTCTCCTATGAACGGTATATTTGTTCTACTTTTGATCGTGGATAGGAAACCATTCGTACCCGAAGGTGTGAACGTATTGCCCAGTTTCAAGGAACTGTTCGGGGAGTATGAATGCGTCTACGGCATTCCACGAGTGAAGGAAAATCAGCGTCATAGGTATAGGATTTTGGGCATGTGGAAGCAATACGTCAGCGGTGACGATAGTGCGGTGCAGAAGGACTTTACTTTGCGAAGGAACCTCAGTGGTCCTAGATACAACGTATGGGCAGCATTCAAAGACATTGATCAAATGTCCACAGGAGGAAATTACAAGAACGTGAGCAAGAATGCCATTCTTGCCTGTAATGTATGGGTCTCTACAGTTCGTTCGAAATGTGAAGTGTATTCGCAATTTGTACTGGATTATGTGGGCTGA |
| Protein Sequence | MRRYDGTPQSTRGRKRKQFSRPFKSVLFRRRQASRRLFAEKPREKLSRRCLEDVHSGPSYALMNQCDVTSYVTYPILGLEGNGGRSRDFIKLMNVRVSGTINVTPLPAEPMSDRSPMNGIFVLLLIVDRKPFVPEGVNVLPSFKELFGEYECVYGIPRVKENQRHRYRILGMWKQYVSGDDSAVQKDFTLRRNLSGPRYNVWAAFKDIDQMSTGGNYKNVSKNAILACNVWVSTVRSKCEVYSQFVLDYVG |
| NCBI Accession | NP_620300.1 |
|---|---|
| Location | 1326-2246 |
| Gene Name | BC1 |
| Protein Name | BC1 |
| Coding Region | ATGGAGGGAGCGTATACCGTCACAAACAAGTACATACATACCAAGAGGACTGAATATACACTCACTACAGACGCCACTCCTATAACCCTTCAGTTTCCCAGTTCGATCGAGCAGACAAGGGTGCGTCTGTTGGGAAGATGCATGAAGATCGACCACATTATCATTGAGTACAGAAACCAGGTCCCGTTTAACGCAACGGGATCAGTGATTATTGAGATACGGGACAACCGTATCTCCGACGAGGAAGCAGCACAGGCTGCCTTCACCTTCCCGATAGCTTGCAACGTCGATCTTCACTACTTCTCTTCGTCGTTTTTCTCAGTCGCCGAGCAGTGTCCCTGGGAGATCGTGTACAGAGTCGAGGACTCGAACGTCTTGAACGGGGTCCGGTTTGCTTCTTTCAAAGCCAAGTTGCGACTGAGTTCTGCACGACATTCAACGGACATCATGTTCAAGGCTCCGACAATCAAGATCCTGACAAAGGGTTACAAGGAGGACTGCATAGACTTCTGGTCCGTTGAACGAGGCGAAACACGACGAAGACTGCTCAACCCAACCCCGTCGGCCCAATCAAATCGGGCCCTGTCAAAGAGGCCAATTACGATTTTACCTGGAGAGACCTGGGCCACAAAGTCGCATGTTGGGTTGCCTTCTGAGTCGGACTCTCAAAGTCGCGACACATACAGATCCCAGTCGATGAGACTGGACCACACACGCAGTTTCACGGGGACCTCATATGAGTCCGACGACACGCCATACGCAGGGCTACACAGACTACAAACAGCCACACTAGACCCGGGAGACTCAGTCTCCCAGACAAGATCAGAGAATTTCTCGAGGCAGGACCTAGAATCTATTTTAGAAAATACGATTAATAAGTGCCTAATTAAGAACAAATCCGACAAGAATCAAATGCTGTAA |
| Protein Sequence | MEGAYTVTNKYIHTKRTEYTLTTDATPITLQFPSSIEQTRVRLLGRCMKIDHIIIEYRNQVPFNATGSVIIEIRDNRISDEEAAQAAFTFPIACNVDLHYFSSSFFSVAEQCPWEIVYRVEDSNVLNGVRFASFKAKLRLSSARHSTDIMFKAPTIKILTKGYKEDCIDFWSVERGETRRRLLNPTPSAQSNRALSKRPITILPGETWATKSHVGLPSESDSQSRDTYRSQSMRLDHTRSFTGTSYESDDTPYAGLHRLQTATLDPGDSVSQTRSENFSRQDLESILENTINKCLIKNKSDKNQML |
References More References in PubMed
| 1 |
Molecular characterization of watermelon chlorotic stunt virus (WmCSV) from Palestine. Ali-Shtayeh MS, et al. Viruses. 2014 Jun 20;6(6):2444-62. doi: 10.3390/v6062444. PMID: 24956181 |
|---|---|
| 2 |
First Report of Watermelon chlorotic stunt virus Infecting Watermelon in Saudi Arabia. Al-Saleh MA, et al. Plant Dis. 2014 Oct;98(10):1451. doi: 10.1094/PDIS-06-14-0583-PDN. PMID: 30703998 |
| 3 |
Al-Musa A, et al. Virus Genes. 2011 Aug;43(1):79-89. doi: 10.1007/s11262-011-0594-8. Epub 2011 Mar 12. PMID: 21399920 |
| 4 |
First Report of Watermelon chlorotic stunt virus in Watermelon in the Palestinian Authority. Ali-Shtayeh MS, et al. Plant Dis. 2012 Jan;96(1):149. doi: 10.1094/PDIS-08-11-0679. PMID: 30731868 |
| 5 |
Esmaeili M, et al. Virus Genes. 2015 Dec;51(3):408-16. doi: 10.1007/s11262-015-1250-5. Epub 2015 Oct 3. PMID: 26433951 |
| 6 |
Fontenele RS, et al. Viruses. 2021 Apr 30;13(5):810. doi: 10.3390/v13050810. PMID: 33946382 |
| 7 |
Iqbal Z. Viruses. 2025 Nov 30;17(12):1571. doi: 10.3390/v17121571. PMID: 41472242 |
| 8 |
Kollenberg M, et al. PLoS One. 2014 Nov 3;9(11):e111968. doi: 10.1371/journal.pone.0111968. eCollection 2014. PMID: 25365330 |
| 9 |
First Report of Watermelon chlorotic stunt virus in Cucurbits in Lebanon. Samsatly J, et al. Plant Dis. 2012 Nov;96(11):1703. doi: 10.1094/PDIS-04-12-0366-PDN. PMID: 30727474 |
| 10 |
Complete nucleotide sequence of watermelon chlorotic stunt virus originating from Oman. Khan AJ, et al. Viruses. 2012 Jul;4(7):1169-81. doi: 10.3390/v4071169. Epub 2012 Jul 24. PMID: 22852046 |