Verbena mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_018580625.1 |
| Isolate | Colombia |
| Release date | 2021/6/1 |
| Submitter | Lopez-Lopez,K., Jara-Tejada,F., Arguello-Astorga,G.R., Vaca-Vaca,J.C. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
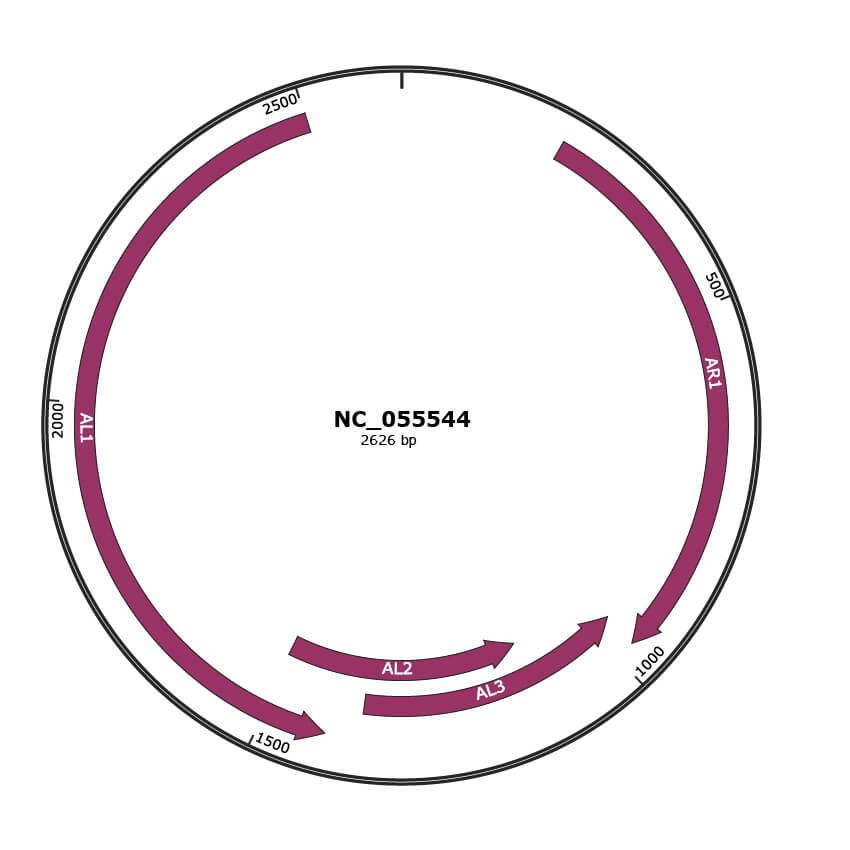
JBrowse
Genome
NC_055544
Gene Information
| NCBI Accession | YP_010087342.1 |
|---|---|
| Location | 218-973 |
| Gene Name | AR1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGCTTGTTGGCGGGAACCTCAAAGGTGAGCCGTAATGTCAATTATTCTCCTCGTGCAGGCAGTGGCCCAAAGTTAAACAGGGCCTCAGAATGGGTTAACAGGCCCATGTACAGAAAGCCCAGGATCTATCGAACGCTAAGGACTCCTGACGTGCCCAGAGGATGTGAAGGCCCGTGTAAGGTACAGTCCTACGAACAGCGCCATGACATTTCACATGTTGGCAAGGTAATGTGTATCTCTGATGTCACACGTGGTAATGGTATTACCCACCGTGTTGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTAGGGAAGATATGGATGGATGAAAATATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACTCCCATGGATTTTGGCCAGGTGTTTAACATGTTCGACAACGAGCCTAGCACTGCGACGGTGAAGAACGATCTCCGCGATCGTTTTCAGGTCATGCATAAGTTCTATGGGAAGGTGACAGGTGGACAATATGCCAGCAATGAACAGGCAATAGTCAAGCGTTTCTGGAAGGTCAACAATCATGTGGTGTACAATCATCAAGAGGCTGGCAAATATGAGAATCACACTGAGAACGCTTTGTTATTGTATATGGCATGTACGCATGCCTCTAATCCTGTGTATGCAACGTTGAAGATTCGAATCTATTTTTACGATTCGATCACGAATTAA |
| Protein Sequence | MPKRDAPWRLLAGTSKVSRNVNYSPRAGSGPKLNRASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_010087343.1 |
|---|---|
| Location | 970-1368 |
| Gene Name | AL3 |
| Protein Name | replication enhancement protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGCAGATAGAAAATCCCCTCTATTTCAGACTGTACAGAGTAGAGGATCCACTGTACACGAACACGAGGATATACAGCGTACAAATACGGTTCAATTACAACCTGAGGAAAGCGTTGCATCTCCACAAGGCCTACCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGCAGACCTATTTGAATAGGTTTAGACATCTAGTTAATATGTATTTAGATCAGGTAGGCGTTATTTCAATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGCCAGATCGTATGTAAATTATGTTCTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGELITAHQAENGVYIWQIENPLYFRLYRVEDPLYTNTRIYSVQIRFNYNLRKALHLHKAYLNFQVWTISMTASGQTYLNRFRHLVNMYLDQVGVISINNVIRAVRFATARSYVNYVLENHSIKFKFY |
| NCBI Accession | YP_010087344.1 |
|---|---|
| Location | 1115-1504 |
| Gene Name | AL2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCGGTCTTCATCACCCTCAACTCCCCCTTGTATCAAGAAGCAACACAGGGAGGCCAAGAAGAGATCAGTCAGACGACGCCGCATTGATCTGGAGTGCGGTTGCTCTATTTACTTCCACATAGGCTGCACTGGGCATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGCAGATAGAAAATCCCCTCTATTTCAGACTGTACAGAGTAGAGGATCCACTGTACACGAACACGAGGATATACAGCGTACAAATACGGTTCAATTACAACCTGAGGAAAGCGTTGCATCTCCACAAGGCCTACCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGCAGACCTATTTGAATAG |
| Protein Sequence | MRSSSPSTPPCIKKQHREAKKRSVRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRVYLADRKSPLFQTVQSRGSTVHEHEDIQRTNTVQLQPEESVASPQGLPELPSLDDIDDSFWADLFE |
| NCBI Accession | YP_010087345.1 |
|---|---|
| Location | 1416-2501 |
| Gene Name | AL1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCACGAAAGGGTTCATTCTCAGTTAAAGCCAAAAACTATTTCATCACTTATCCAGAGTGCTCTCTAACAAAAGAAGAGGCACTTTCCCAAATTCTAGCTCTGAAAACCCCAGTTAACAAGAAGTACATCAAGATTTGCAGAGAATTTCACGAAAATGGGAATCCCCATCTCCACATGCTTATCCAATTCGAAGGGAAATACAACTGCACGAATAACAGATTCTTCGATCTGGTTTCCCCATCAAGATCAGCACCTTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTACTACATTAACAAGGACGGAGACACCATTGAATGGGGAAAGTTCCAGATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCAATTAACGACACATATGCCAAGGCGTTAAATGCGACCTCTGCCGAAGAAGCTCTGCAAATCATAAAGGAAGAACAACCGCAACACTTCTTCCTTCAGCATCACAACCTGGTTGCTAACGCATCCAGAATTTTCAAAAAGGCTCCGGAGCCATGGTCTCCTCCGTTTCCACTATCCTCTTTCACTAACGTGCCCGACGAGATGCAAGAGTGGGCAGACGACTATTTTGGAAGGAGTGCCGCTGCGCGGCCATTGAGGCCAGTCAGTCTCATAGTAGAAGGTGACTCAAGAACAGGGAAGACGATGTGGGCTCGGTCATTAGGCCCACATAATTACATGAGTGGACACCTAGACTTCAATTCCAGAGTTTTCTCAGACGAAGTGGAATATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTAATCGGGGCCCAACAGATGTGGCAGTCAAATTGTAAGTACGGAAAGCCAGTCCTGATTAAAGGTGGGATACCATCAATCGTGCTCTGCAATTCTGGCGAGGGTGCCAGCTATAAAGATTTCCTGGACAAACAGGAAAACACAGCACTCAGGGACTGGACTTTGAAGAATGCGGTCTTCATCACCCTCAACTCCCCCTTGTATCAAGAAGCAACACAGGGAGGCCAAGAAGAGATCAGTCAGACGACGCCGCATTGA |
| Protein Sequence | MPRKGSFSVKAKNYFITYPECSLTKEEALSQILALKTPVNKKYIKICREFHENGNPHLHMLIQFEGKYNCTNNRFFDLVSPSRSAPFHPNIQGAKSSSDVKYYINKDGDTIEWGKFQIDGRSARGGQQSINDTYAKALNATSAEEALQIIKEEQPQHFFLQHHNLVANASRIFKKAPEPWSPPFPLSSFTNVPDEMQEWADDYFGRSAAARPLRPVSLIVEGDSRTGKTMWARSLGPHNYMSGHLDFNSRVFSDEVEYNVIDDVAPHYLKLKHWKELIGAQQMWQSNCKYGKPVLIKGGIPSIVLCNSGEGASYKDFLDKQENTALRDWTLKNAVFITLNSPLYQEATQGGQEEISQTTPH |
References More References in PubMed
| 1 |
Natural Infection of Vicia faba by Bidens mottle virus in Florida. Baker CA, et al. Plant Dis. 2001 Dec;85(12):1290. doi: 10.1094/PDIS.2001.85.12.1290C. PMID: 30831812 |
|---|---|
| 2 |
Bidens mottle virus Identified in Tropical Soda Apple in Florida. Baker CA, et al. Plant Dis. 2007 Jul;91(7):905. doi: 10.1094/PDIS-91-7-0905A. PMID: 30780404 |
| 3 |
Complete genome sequence of arracacha mottle virus. Orílio AF, et al. Arch Virol. 2013 Jan;158(1):291-5. doi: 10.1007/s00705-012-1473-x. Epub 2012 Sep 22. PMID: 23001696 |
| 4 |
A New Potyvirus sp. Infects Verbena Exhibiting Leaf Mottling Symptoms. Kraus J, et al. Plant Dis. 2010 Sep;94(9):1132-1136. doi: 10.1094/PDIS-94-9-1132. PMID: 30743723 |
| 5 |
Natural Infection of Verbena and Phlox by a Recently Described Member of the Carmovirus Genus. Assis Filho FM, et al. Plant Dis. 2006 Aug;90(8):1115. doi: 10.1094/PD-90-1115B. PMID: 30781336 |
| 6 |
Complete genome sequence of pepper yellow mosaic virus, a potyvirus, occurring in Brazil. Lucinda N, et al. Arch Virol. 2012 Jul;157(7):1397-401. doi: 10.1007/s00705-012-1313-z. Epub 2012 Apr 15. PMID: 22527869 |
| 7 |
First Report of Nemesia ring necrosis virus in North America in Ornamental Plants from California. Mathews DM, et al. Plant Dis. 2006 Sep;90(9):1263. doi: 10.1094/PD-90-1263C. PMID: 30781122 |