Cassava mosaic Madagascar virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000895455.1 |
| Isolate | Madagascar:Toliary |
| Release date | 2015/2/22 |
| Submitter | Harimalala,M.A., Lefeuvre,P., Hoareau,M., Villemot,J., Tiendrebeogo,F., Ranomenjanahary,S., Andrianjaka,A., Reynaud,B., Lett,J.M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
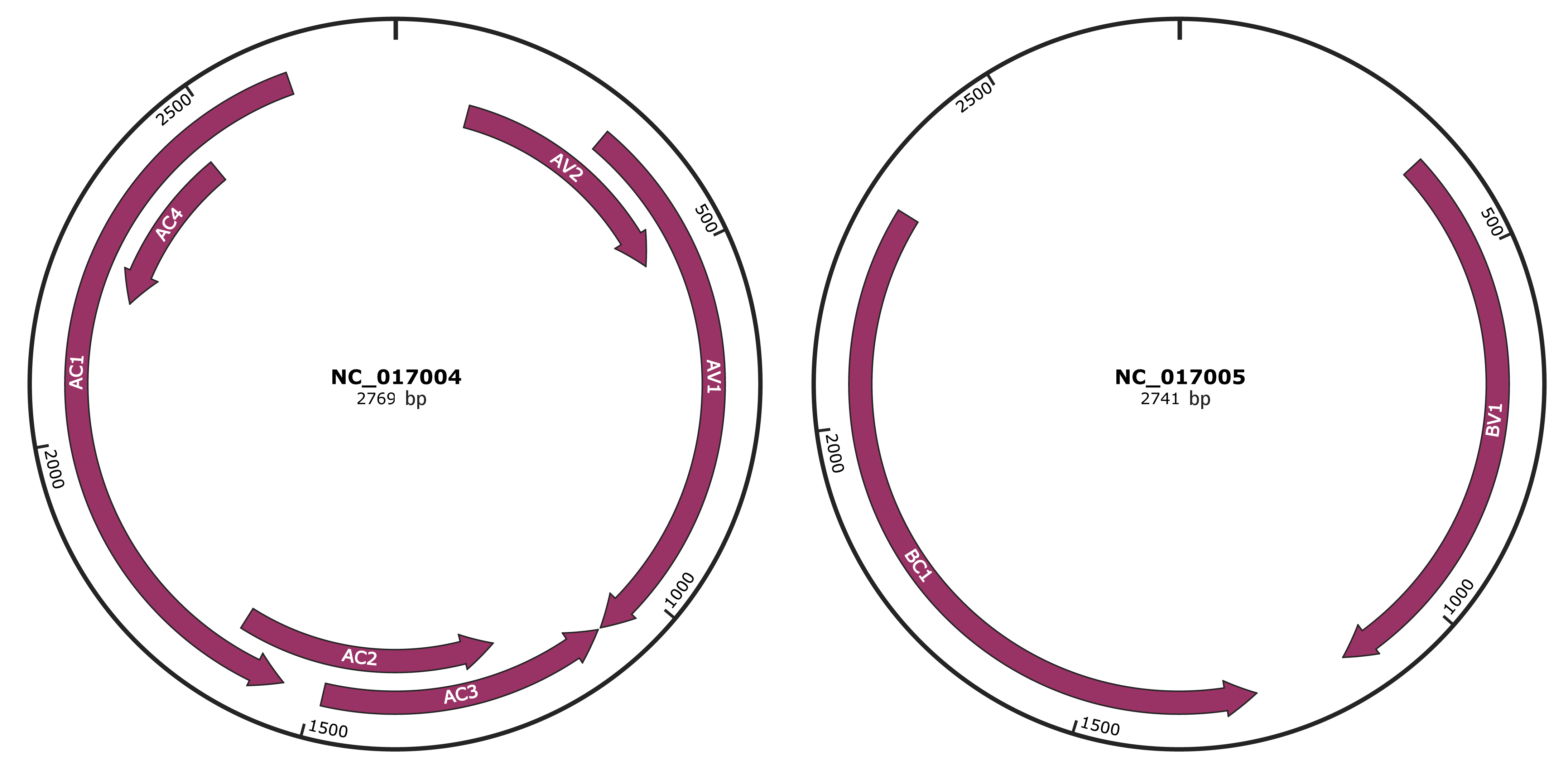
JBrowse
Genome
NC_017004
NC_017005
Gene Information
| NCBI Accession | YP_005352913.1 |
|---|---|
| Location | 116-499 |
| Gene Name | AV2 |
| Protein Name | AV2 protein (MP) |
| Coding Region | ATGCTTGTCCAACAAGTAGTTTTGCATTTCAAAATGTGGGATCCATTGTTAAATGAATTTCCTGACTCGGTTCATGGATTTCGTTGTATGCTAGCTATAAAATATTTGCAGGCTGTGGAGGTAACCTACGAGTCCAATACTTTGGGCCGCGATTTAATTCGGGATCTCATTTCTGTTATTAGGGCTCGTGACTATGTCGAAGCGTCCCGCCGATATAATAATTGCCACTCCCGCCTCGAAGGTGCGTCGGAAGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGTTGTCCCCATTGTCCCAGGCACAAGCAAGTTCAAATCATGGAAGTTCAGACCCATGTATCGGAAGCCCAGGATGTACAGGATGTTCAAAAGCCCTGA |
| Protein Sequence | MLVQQVVLHFKMWDPLLNEFPDSVHGFRCMLAIKYLQAVEVTYESNTLGRDLIRDLISVIRARDYVEASRRYNNCHSRLEGASEAELRQPIQQPCCCPHCPRHKQVQIMEVQTHVSEAQDVQDVQKP |
| NCBI Accession | YP_005352914.1 |
|---|---|
| Location | 309-1076 |
| Gene Name | AV1 |
| Protein Name | coat protein (CP) |
| Coding Region | ATGTCGAAGCGTCCCGCCGATATAATAATTGCCACTCCCGCCTCGAAGGTGCGTCGGAAGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGTTGTCCCCATTGTCCCAGGCACAAGCAAGTTCAAATCATGGAAGTTCAGACCCATGTATCGGAAGCCCAGGATGTACAGGATGTTCAAAAGCCCTGATGTTCCTCGTGGCTGTGAAGGCCCATGTAAGGTTCAATCATATGAACAGCGAGATGACGTCAAGCATACTGGCACTGTTCGTTGTGTGAGTGATGTCACGCGTGGTCCGGGAATTACGCATAGAGTGGGTAAAAGGTTTTGTATCAAGTCTATATATGTGTTAGGTAAGATATGGATGGATGAAAATATCAAGAAGCAGAACCATACTAACCAGGTCATGTTCTTCTTAGTCCGTGACAGAAGGCCCTATGGCACTAGCCCCATGGACTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCCAGTACAGCAACTGTGAAGAACGATCTTAGGGATAGGTATCAAGTTATGCGGAAGTTTCATGCCACCGTTGTTGGGGGTCCTTCTGGGATGAAGGAGCAGCTTTGGTTAGGAGATTTTTTAGGATTAATAATCATGTGGTGTATAATCACCAGGAGGCAGCTAAGTATGAGAATCATACAGAGAATGCGTTATTGTTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCTACGCTTAAAATACGCATCTATTTTTATGATGCAGTAA |
| Protein Sequence | MSKRPADIIIATPASKVRRKLNFDSPYSSRAVVPIVPGTSKFKSWKFRPMYRKPRMYRMFKSPDVPRGCEGPCKVQSYEQRDDVKHTGTVRCVSDVTRGPGITHRVGKRFCIKSIYVLGKIWMDENIKKQNHTNQVMFFLVRDRRPYGTSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMRKFHATVVGGPSGMKEQLWLGDFLGLIIMWCIITRRQLSMRIIQRMRYCCIWHVRMPLIQCMLRLKYASIFMMQ |
| NCBI Accession | YP_005352915.1 |
|---|---|
| Location | 1081->1485 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein (REn) |
| Coding Region | ATGGATTCACGCACAGGGGCACTCATCACTGCTCCTCAAGCGCAGAATGGCGTTTTTACCTGGGAGATAAACAATCCCCTTTATTTCACGATACCCAGACACGACTCGAGACCGTCCCACCTGAACCACGACATCATCACCATCCAAATACGCTTCAACCACAACATCCGGAAGGAATTGGGGATTCACAAATGTTTTCTGAACTTCCAGGTCTGGACGACCTTACACCCTCAGACTGGTCATTTCTTAAGCGTATTTAAGCGTCAAGTTCTTAAGTATTTAGATAATGTAGGCGTTATTTCAATAAACACTGTAATTCGCGCTGTTGATCACGTATTGTACAATGTACTTGTAAACACACTCCAAGTTATGGAGTCCCACGAAATAAAATTTAATTTGTATTAA |
| Protein Sequence | MDSRTGALITAPQAQNGVFTWEINNPLYFTIPRHDSRPSHLNHDIITIQIRFNHNIRKELGIHKCFLNFQVWTTLHPQTGHFLSVFKRQVLKYLDNVGVISINTVIRAVDHVLYNVLVNTLQVMESHEIKFNLY |
| NCBI Accession | YP_005352916.1 |
|---|---|
| Location | 1226->1633 |
| Gene Name | AC2 |
| Protein Name | transcription activator protein (TrAP) |
| Coding Region | ATGCAACCTTCGTCACCCTCAGCGAGCCATTGTTCACAGGTTCCCATCAAGGTCCTACACCGCATAGCCAAGACGAGACGCATCAGACGTAGACGTATCGACCTAAGCTGCGGCTGTTCATATTATCTCCACATCGACTGCATCAATCATGGATTCACGCACAGGGGCACTCATCACTGCTCCTCAAGCGCAGAATGGCGTTTTTACCTGGGAGATAAACAATCCCCTTTATTTCACGATACCCAGACACGACTCGAGACCGTCCCACCTGAACCACGACATCATCACCATCCAAATACGCTTCAACCACAACATCCGGAAGGAATTGGGGATTCACAAATGTTTTCTGAACTTCCAGGTCTGGACGACCTTACACCCTCAGACTGGTCATTTCTTAAGCGTATTTAA |
| Protein Sequence | MQPSSPSASHCSQVPIKVLHRIAKTRRIRRRRIDLSCGCSYYLHIDCINHGFTHRGTHHCSSSAEWRFYLGDKQSPLFHDTQTRLETVPPEPRHHHHPNTLQPQHPEGIGDSQMFSELPGLDDLTPSDWSFLKRI |
| NCBI Accession | YP_005352917.1 |
|---|---|
| Location | <1543->2621 |
| Gene Name | AC1 |
| Protein Name | replication associated protein (Rep) |
| Coding Region | ATGCCTCCTCCCAAGCGTTTTAAAATACAAGCCAAAAACTATTTCCTCACATATCCCAAATGCTCTCTATCTAAACACGACGCATTATCCCAAATCTTAAACATCCCAACTCCAACTAATAAGAAATACATCAAAGTGTGCCGAGAACTTCACGAAGATGGGCAACCTCATCTCCACATGCTTATTCAATTCGAAGGCAAATTCTCATGCACAAATAAGCGATTATTCGACCTGGTATCCCCAACAACGTCAACCCATTTCCATCCAAACATTCAAGGAGCCAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGATGGGGATACAACTGAGTGGGGCGAATTCCAGATCGACGCAAGATCTGCTAGAGGCGGCTGCCAAAATGCTAATGACGCATGTGCCGAAGCCTTAAACTCACGTTCGAAGGCAGCTGCACTTCTAATTATTAAGGAGAAACTCCCCAAAGAATTTATTTTTCAATATCATAACTTAAGTAGTAATTTAGATAGGATTTTTCAAGAGCCACCAGCTCCCTATGTTTCTCCATTTCTGTCTTCTTCATTCGACCAAGTTCCTGACGACCTTGAGGTCTGGGTGTCAGAAAACATTATGCATCCCGCTGCGCGGCCTTGGAGACCGAATAGTATTGTTATTGAGGGTGATAGTCGTACAGGGAAGACAATGTGGGCCAGATCATTGGGACCACATAATTATTTATGTGGTCATCTCGACCTCAGTCCCAAAGTCTTCACTAATGATGCATGGTACAACATTATTGATGATGTCGATCCGCACTATCTAAAGCACTTTAAAGAGTTCATGGGTGCACAACGAGACTGGCAAAGCAACACAAAATACGGAAAGCCAATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCGGGGCCGACTTCTTCATATAAAGAATATCTCGATGAAGAAAAGAATGCATCTCTCAAAGCGTGGGCACTGAAAAATGCAACCTTCGTCACCCTCAGCGAGCCATTGTTCACAGGTTCCCATCAAGGTCCTACACCGCATAGCCAAGACGAGACGCATCAGACGTA |
| Protein Sequence | MPPPKRFKIQAKNYFLTYPKCSLSKHDALSQILNIPTPTNKKYIKVCRELHEDGQPHLHMLIQFEGKFSCTNKRLFDLVSPTTSTHFHPNIQGAKSSSDVKSYIDKDGDTTEWGEFQIDARSARGGCQNANDACAEALNSRSKAAALLIIKEKLPKEFIFQYHNLSSNLDRIFQEPPAPYVSPFLSSSFDQVPDDLEVWVSENIMHPAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVFTNDAWYNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNASLKAWALKNATFVTLSEPLFTGSHQGPTPHSQDETHQT |
| NCBI Accession | YP_005352918.1 |
|---|---|
| Location | 2207->2464 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGCAACCTCATCTCCACATGCTTATTCAATTCGAAGGCAAATTCTCATGCACAAATAAGCGATTATTCGACCTGGTATCCCCAACAACGTCAACCCATTTCCATCCAAACATTCAAGGAGCCAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGATGGGGATACAACTGAGTGGGGCGAATTCCAGATCGACGCAAGATCTGCTAGAGGCGGCTGCCAAAATGCTAATGACGCATGTGCCGAAGCCTTAA |
| Protein Sequence | MGNLISTCLFNSKANSHAQISDYSTWYPQQRQPISIQTFKEPNPAPTSSPTSTKMGIQLSGANSRSTQDLLEAAAKMLMTHVPKP |
| NCBI Accession | YP_005352919.1 |
|---|---|
| Location | 359-1135 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein (NSP) |
| Coding Region | ATGTATTCTGTTAACAGACGTGGGTATAAGACTCCGTATAGGAGTCCGTATGTCGCTCGTGTAACACCATATGTTTATCGTAAGACGTCGTTTAAACATACGTCTAAATCTCGTGTACCTCGAAAGTTGGCGTATGAATCGCCAAAAGTGTTATATATGCGACGCTCAATGGAAGATGTCCATGATGGGGCTTCTTTGAAGTTGCCTCAACAGGGGGATCATACGTCCTACGTGACACTCCCGTGTCGTGGTATCGATGGTAATGGGGGTAGGTCTGTGGACCATATAAAATTATTAAGCTTGAGGGTTTCTGGGACCGTCAATGTCAGTCAATTCGGTGGTGATGACAATATGGGAGAGAAAACAACCATGATAGGTATCTTTTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTCAGCACATTGCCGACGTTCAAGGAGTTGTTCGGGGAATATGAATCCGTGTATGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGTTATCGCGTTATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCACATCCAGAAGCCTTTTAGTATACGTCGAAGACTCAGTGGAGGGAAATATCCTATTTGGTCTTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATGTAAATAAGAACGCTATACTAGTTAGTTATGTGTGGGTATCGCTATGTCGGAGCACCTGTGATGTGTATTCTCAGTTTGTACTTAATTACGTCGGCTGA |
| Protein Sequence | MYSVNRRGYKTPYRSPYVARVTPYVYRKTSFKHTSKSRVPRKLAYESPKVLYMRRSMEDVHDGASLKLPQQGDHTSYVTLPCRGIDGNGGRSVDHIKLLSLRVSGTVNVSQFGGDDNMGEKTTMIGIFFMACLVDKKPFVPEGVSTLPTFKELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSIRRRLSGGKYPIWSSFKDVDNSSTGGNYKNVNKNAILVSYVWVSLCRSTCDVYSQFVLNYVG |
| NCBI Accession | YP_005352920.1 |
|---|---|
| Location | 1264->2298 |
| Gene Name | BC1 |
| Protein Name | movement protein (MP) |
| Coding Region | ATGTTCATGTTACTGCATGTATGCTCATATGATTTGACCAATCTCATAATTATTACTGCATTTTATGTATACATTCTCACTTATAACGTCATTTGTCACAAACCACACAGGATGGAGGCCACATATACAGTTGACAACAACCGATACATCGACACCAAAAGGACCGAGTATGCACTGACAAATGACGCATCACCGATTTATCTTCAATTTCCCAGTTCATTCGAACAGGCCACCATGCGGCTTAAGGGCAGATGCATGAAGATCGATCACATCATAATAGAATACAATAACCAAGTCCCATTTAATGCAACGGGCTCAGTAATTGTGGAGATCAGGGATAATCGCGTGAGCCTCGAAGACGCAGCACAAGCTGCTTTCACATTCCCGATAACGTGTAACGTCGATCTCCATTACTACTCCTCCACTTACTTCTCAGTGTCAGAACCCTCACCATGGGAAATTATATACAAAGTCGAGGACTCGAACGTCGTAGAAGGGGTCAAATTCGCCTCCATCAAGGCAAGACTAAGATTATCGACTGCCAAGCATTCCACGGACATACGATTCAAGCCCCCTACGATCAACATACGATCCAAGGGATTCACAAAAGAATGCATAGACTTTTGGTCCGTGGAACGTGGAGAAACCAGACGGCGTCTCCTCAATCCAAATCCATCTGCTCAGACCCACAGAACAATATCCACTAGGCCCATTACCATAATGCCTGGAGAAACATGGGCCACAAAGTCTCAGATTGGGCTACCCAGCTCATCAAACCCAGCACGGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAACACCAACAGACTTAGACAACGAGTCCACAGAATATCCTTACCAGAGACTACACAGATTAAACACACCAGAGTTAGACCCAGGAGACTCAGTATCACAGGCCCCATCCGACTCAGTATCCAGAAAGGACCTCGAGACCCTGCTGGAGAGTACCATAAACAAGTGTCTCATCAAAATCAAATCCGAAGCCCCACGGCAATTGTAA |
| Protein Sequence | MFMLLHVCSYDLTNLIIITAFYVYILTYNVICHKPHRMEATYTVDNNRYIDTKRTEYALTNDASPIYLQFPSSFEQATMRLKGRCMKIDHIIIEYNNQVPFNATGSVIVEIRDNRVSLEDAAQAAFTFPITCNVDLHYYSSTYFSVSEPSPWEIIYKVEDSNVVEGVKFASIKARLRLSTAKHSTDIRFKPPTINIRSKGFTKECIDFWSVERGETRRRLLNPNPSAQTHRTISTRPITIMPGETWATKSQIGLPSSSNPARLEHFRSQSMRMDPSTTPTDLDNESTEYPYQRLHRLNTPELDPGDSVSQAPSDSVSRKDLETLLESTINKCLIKIKSEAPRQL |
References More References in PubMed
| 1 |
Cassava mosaic virus disease in East Africa: a dynamic disease in a changing environment. Legg JP, et al. Virus Res. 2000 Nov;71(1-2):135-49. doi: 10.1016/s0168-1702(00)00194-5. PMID: 11137168 |
|---|---|
| 2 |
Divergent evolutionary and epidemiological dynamics of cassava mosaic geminiviruses in Madagascar. De Bruyn A, et al. BMC Evol Biol. 2016 Sep 6;16(1):182. doi: 10.1186/s12862-016-0749-2. PMID: 27600545 |
| 3 |
A novel cassava-infecting begomovirus from Madagascar: cassava mosaic Madagascar virus. Harimalala M, et al. Arch Virol. 2012 Oct;157(10):2027-30. doi: 10.1007/s00705-012-1399-3. Epub 2012 Jul 10. PMID: 22777180 |
| 4 |
Harimalala M, et al. Arch Virol. 2013 Aug;158(8):1829-32. doi: 10.1007/s00705-013-1664-0. Epub 2013 Mar 23. PMID: 23525698 |
| 5 |
A New Tomato leaf curl virus from Mayotte. Lett JM, et al. Plant Dis. 2004 Jun;88(6):681. doi: 10.1094/PDIS.2004.88.6.681B. PMID: 30812598 |
| 6 |
First Report of East African Cassava Mosaic Begomovirus in Ghana. Offei SK, et al. Plant Dis. 1999 Sep;83(9):877. doi: 10.1094/PDIS.1999.83.9.877C. PMID: 30841053 |
| 7 |
First Report of East African Cassava Mosaic Begomovirus in Nigeria. Ogbe FO, et al. Plant Dis. 1999 Apr;83(4):398. doi: 10.1094/PDIS.1999.83.4.398A. PMID: 30845599 |
| 8 |
First Molecular Identification of a Begomovirus Isolated from Tomato in Madagascar. Delatte H, et al. Plant Dis. 2002 Dec;86(12):1404. doi: 10.1094/PDIS.2002.86.12.1404C. PMID: 30818457 |