Tomato yellow vein streak virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000874525.1 |
| Isolate | Brazil |
| Release date | 2015/2/13 |
| Submitter | Albuquerque,L.C., Martin,D.P., Avila,A.C., Inoue-Nagata,A.K., Ribeiro,S.G., Daniels,J., Fernandes-Carrijo,F.R. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
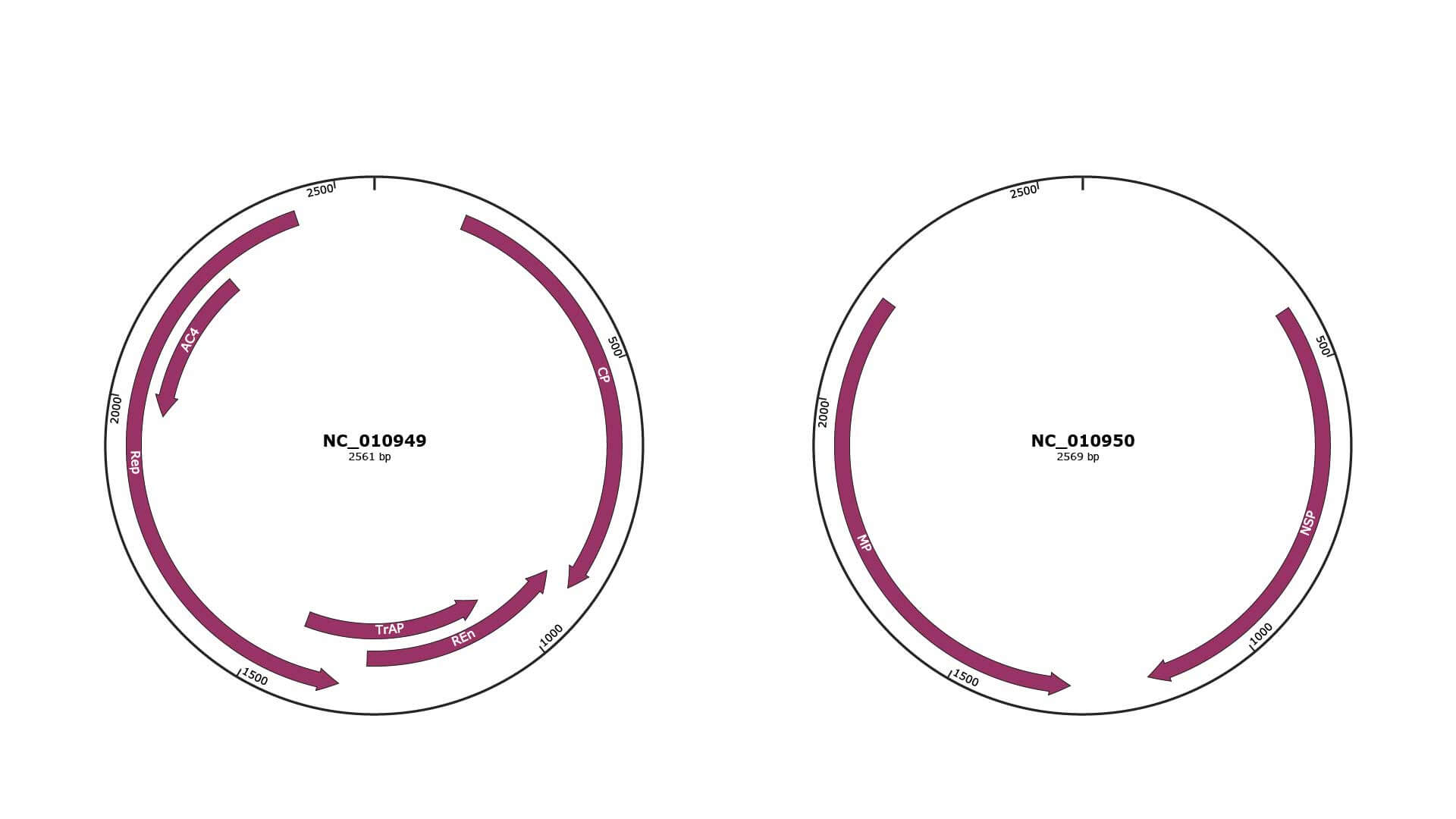
JBrowse
Genome
NC_010949
NC_010950
Gene Information
| NCBI Accession | YP_001974404.1 |
|---|---|
| Location | 156-899 |
| Gene Name | CP |
| Protein Name | AV1 |
| Coding Region | ATGCCAAAGCGGGATGCCCCATGGCGTATAATGGCGGGGACCACTAAAGTGTCCCGCTCTTCCAATTATTCACCTCGTGGAGGTATTTCCAAGCGGGATGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGAACGTTGAGAGGCCCTGATGTTCCTAAAGGGTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAGCGTCATGACATTTCTCATCTTGGCAAGGTGATGTGTATCTCTGATATCACACGTGGTAATTGTATTACACACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCCGTATACATTTTAGGGAAGATATGGATGGACGAAAATATTAAATTGAAAAACCACACGAACAGCGTCATCTTCTGGTTGGTAAGGGATCGGAGACCGTATGGGACACCTATGGATTTTGGCCAAGTGTTTAATATGTTTGATAATGAGCCTAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGGTTTCAAGTCATGCATAGGTTTAATGCTAAGGTTACGGGTGGACAGTATGCTAGCAACGAGCAAGCTCTTGTGCGGCGTTTCTGGAAGGTCAACAATCATGTGGTCTACAACCATCAGGAAGCAGGGAAATATGAGAATCACACGGAGAACGCTTTGTTATTGTATATGGCATGTACACATGCTTCTAACCCACTGTATGCAACTTTGAAAATTCGGATCTATTTTTATGATTCGATTACAAATTAA |
| Protein Sequence | MPKRDAPWRIMAGTTKVSRSSNYSPRGGISKRDAWVNRPMYRKPRIYRTLRGPDVPKGCEGPCKVQSYEQRHDISHLGKVMCISDITRGNCITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHRFNAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPLYATLKIRIYFYDSITN |
| NCBI Accession | YP_001974405.1 |
|---|---|
| Location | 896-1294 |
| Gene Name | REn |
| Protein Name | AC3 |
| Coding Region | ATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAAGCAGCGAATGGCGTCTTTATTTGGGAGATTACCAATCCCCTCTATTTCAAGATAATCAACGTAGAGGACCCCCTCTACACAACGACACGGATATACCATCTACAGATACGTTTCAACCACAACCTGCGGAAAGCGTTGGATCTCCACAAGGCTTTTCTCAATTTCCAAGTCTGGACGACATCCCTGAGAGCTTCTGGGATGACATATTTAAGTAGATTTAAGTATTTAGTCTTATTGTATTTAAACCAATTAGGTGTTATTTCCGTTAATAATGTAATCAGAGCTGTTCGTTTCGCAACAGACAAATCTTATGTAAATTATGTACTTGAAAATCATTCAATAAAATTTAGACTTTATTAA |
| Protein Sequence | MDSRTGELITAPQAANGVFIWEITNPLYFKIINVEDPLYTTTRIYHLQIRFNHNLRKALDLHKAFLNFQVWTTSLRASGMTYLSRFKYLVLLYLNQLGVISVNNVIRAVRFATDKSYVNYVLENHSIKFRLY |
| NCBI Accession | YP_001974406.1 |
|---|---|
| Location | 1041-1430 |
| Gene Name | TrAP |
| Protein Name | AC2 |
| Coding Region | ATGCTAAATACATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGAGCAGCCAAACGGAAGGTAATTCGCCGAAGACGCATTGACCTAAACTGCGGCTGCTCCATTTACATCCATCTCAACTGTCGCAACAATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAAGCAGCGAATGGCGTCTTTATTTGGGAGATTACCAATCCCCTCTATTTCAAGATAATCAACGTAGAGGACCCCCTCTACACAACGACACGGATATACCATCTACAGATACGTTTCAACCACAACCTGCGGAAAGCGTTGGATCTCCACAAGGCTTTTCTCAATTTCCAAGTCTGGACGACATCCCTGAGAGCTTCTGGGATGACATATTTAAGTAG |
| Protein Sequence | MLNTSSSTPPSIKPRHRAAKRKVIRRRRIDLNCGCSIYIHLNCRNNGFTHRGTHHCASSSEWRLYLGDYQSPLFQDNQRRGPPLHNDTDIPSTDTFQPQPAESVGSPQGFSQFPSLDDIPESFWDDIFK |
| NCBI Accession | YP_001974407.1 |
|---|---|
| Location | 1342-2427 |
| Gene Name | Rep |
| Protein Name | AC1 |
| Coding Region | ATGCCCCTTCCAAAGCGTTTCTTAGTAAATGCAAAAAATTTCTTCCTTACATATCCTCATTGTTCATTAACTAAAGACGAAGCTCTTTCACAATTACAGGCACTTCAAACACCTACCAACAAGAAATTTATTCGCGTAACCAGAGAACTTCACGAAGATGGGGAACCTCATCTCCACGTGCTTATACAGTTCGAAGGCAAATTCAAATGCCACAATCAACGATTCTTCGATTTGGTATCCCCAACCAGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCAGACGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAACTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCAAACGACACTTATGCCAAGGTTCTCAACGCAGATAATCCAACCACGGCACTCAATATATTAAAAGAAGAGCAACCTCGAGATTATGTTCTACATCTGGATAAAATAAGAACACATGTCCAGAGAATATTTGCAAAGGCTCCAGAGCCATGGGTTTCTCCGTTTCAACTTTCCTCCTTCACTAATGTTCCTGACGAGATGCAAGAGTGGGCTGACGAATATTTCGGAAGGGGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATTATAATTGAGGGTGATAGTCGTACAGGAAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTATCTGAGTGGACATCTAGATTTTAATTCTAGGGTTTATTCAAATGAGGTGCATTATAACGTCATTGATGATGTCACTCCGCAATACCTAAAGCTAAAACATTGGAAAGAGCTCATTGGGGCCCAACGTGACTGGCAAAGCAACTGCAAATACGGGAAGCCAGTTCAAATTAAAGGAGGAATCCCATCAATCGTGCTCTGCAATCCAGGAGAGGGGGCTAGTTATAAAGACTTCCTAGACAAACATGAAAATATATCTTTAAAAACGTGGACACTGCATAATGCTAAATACATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGAGCAGCCAAACGGAAGGTAATTCGCCGAAGACGCATTGA |
| Protein Sequence | MPLPKRFLVNAKNFFLTYPHCSLTKDEALSQLQALQTPTNKKFIRVTRELHEDGEPHLHVLIQFEGKFKCHNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDFIDFGTFQIDGRSARGGCQSANDTYAKVLNADNPTTALNILKEEQPRDYVLHLDKIRTHVQRIFAKAPEPWVSPFQLSSFTNVPDEMQEWADEYFGRGAAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNEVHYNVIDDVTPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKHENISLKTWTLHNAKYIFLNSPLYQTTTQSSQTEGNSPKTH |
| NCBI Accession | YP_001974408.1 |
|---|---|
| Location | 1977-2270 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGGAACCTCATCTCCACGTGCTTATACAGTTCGAAGGCAAATTCAAATGCCACAATCAACGATTCTTCGATTTGGTATCCCCAACCAGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCAGACGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAACTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCAAACGACACTTATGCCAAGGTTCTCAACGCAGATAATCCAACCACGGCACTCAATATATTAA |
| Protein Sequence | MGNLISTCLYSSKANSNATINDSSIWYPQPDQHISIQTFRELKARQTSRPTWRKTETSLILELSRSMEDQLEEVANLQTTLMPRFSTQIIQPRHSIY |
| NCBI Accession | YP_001974409.1 |
|---|---|
| Location | 402-1172 |
| Gene Name | NSP |
| Protein Name | BV1 |
| Coding Region | ATGTATATTAATAAGTATAGACGTGGCTGGATATCTAATCAACGACGAGGCTATTCACGTCAGTCTTTCTTCAAGCGTTCTTATTATGTTAAACGTACAGATGGGAAACGTCGATCGAGTAGCACGACTCAAGTCAATGAGGAGAGCAGATTGTCACAACAGCGAATTCATGAGAACCAGTTTGGTCCAGAATTTGTAATGGTTCATAATACAGCCGTATCAACCTTTATTACTTTCCCCAATCTTGGTAAAACTGAACCGAATCGATCTAGGTCATATATAAAGTTGAAACGTTTGCGTTTCAAAGGTACTGTTAAAATTGAACGTTTGCATACTGATATGAAAATGGACTGTATAATTCCAAATATCGAAGGAGTGTTTTCGTTGGTCATCGTAGTTGATCGTAAACCCCATTTGAATCCAACAGGATGTCTACATACATTTGATGAGCTATTTGGTGCACGAATACACAGTCATGGCAATTTAGCTATAACCGCATCTCTGAAAGACCGATTTTACATACGTCATGTTTGGAAGAAAGTAATATCTGTTGAGAAAGATAGCATGATGGTTGATCTTGAAGGAACGACATCACTATCTAACAAGCGTTATAATTGTTGGTCAGCTTTTAAGGATCTTGATCATGATTCATGTAATGGGGTTTATGCGAATATAAGCAAGAACGCCCTTTTAGTTTACTATTGTTGGATGTCTGATACCATGTCTACAGCATCCTCATTTGTATCGTTTGATCTTGATTATGTGGGTTAA |
| Protein Sequence | MYINKYRRGWISNQRRGYSRQSFFKRSYYVKRTDGKRRSSSTTQVNEESRLSQQRIHENQFGPEFVMVHNTAVSTFITFPNLGKTEPNRSRSYIKLKRLRFKGTVKIERLHTDMKMDCIIPNIEGVFSLVIVVDRKPHLNPTGCLHTFDELFGARIHSHGNLAITASLKDRFYIRHVWKKVISVEKDSMMVDLEGTTSLSNKRYNCWSAFKDLDHDSCNGVYANISKNALLVYYCWMSDTMSTASSFVSFDLDYVG |
| NCBI Accession | YP_001974410.1 |
|---|---|
| Location | 1306-2187 |
| Gene Name | MP |
| Protein Name | BC1 |
| Coding Region | ATGGATTCTCAAATAGTTTGCCCACCAAACGCCTTTAATTATATAGAATCTCGTCGTGATGAATATCAGCTATCTCACGACCTTACGGAAATCATATTGCAGTTTCCTTCAAAAGCGACTCAATTAAGTGCAAGACTAAATAGAAGCTGTATGAAGATTGACCATTGCGTCATAGAATATAGGCAACAGGTACCCATAAACGCAACAGGATCAGTAATTGTGGAGATTCATGACCAGAGGATGACTGAAAATGAATCATTACAGGCGTCATGGACTTTTCCTATAAGATGCAACATAGATCTCCACTATTTCTCATCGTCATTCTTCTCCCTCAAAGACCCAATTCCATGGAAGCTATATTATAAGGTTTGTGATTCAAATGTTCATCAGATGACACACTTCGCAAAATTCAAAGGGAAGCTGAAGCTATCAACTGCAAAACATTCGGTTGATATACCTTTCAGAGCACCCACAGTAAAGATAATGTCCAAACAATTTACCGTAAATGACATCGACTTTTCTCATGTGGGTTATGGGAAGTGGGAGAGGAAATTGATAAGATCCGCATCCACTTCTAGATTTGGGCTTCCCGGCCCAATAGAATTAAACCCAGGAGAGTCTTGGGCCACACGGAGTACAATAGGGCCGGCCCAGTTAGAAGCAGAATCAGATATTGCTGAAGTGTTACATCCATACAAGGATCTTAACAGGTTGGGCACTGCCATCTTAGACCCAGGTGATTCGGCTTCAATAATTGGGGCCCAAAGAACGCAATCGAATATAACACTATCAATGGCCCAATTAAACGATCTTGTTAGGACGACGGTCCAAGAATGTATTAAAACTAATTGTATTCCTTCACAGCCCAAATCTTTGAAATAA |
| Protein Sequence | MDSQIVCPPNAFNYIESRRDEYQLSHDLTEIILQFPSKATQLSARLNRSCMKIDHCVIEYRQQVPINATGSVIVEIHDQRMTENESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQMTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIMSKQFTVNDIDFSHVGYGKWERKLIRSASTSRFGLPGPIELNPGESWATRSTIGPAQLEAESDIAEVLHPYKDLNRLGTAILDPGDSASIIGAQRTQSNITLSMAQLNDLVRTTVQECIKTNCIPSQPKSLK |
References More References in PubMed
| 1 |
Characterization of tomato yellow vein streak virus, a begomovirus from Brazil. Albuquerque LC, et al. Virus Genes. 2010 Feb;40(1):140-7. doi: 10.1007/s11262-009-0426-2. Epub 2009 Nov 24. PMID: 19937269 |
|---|---|
| 2 |
Dos Reis LNA, et al. Virus Genes. 2021 Feb;57(1):127-131. doi: 10.1007/s11262-020-01810-z. Epub 2020 Nov 19. PMID: 33211226 |
| 3 |
Tomato mottle wrinkle virus, a recombinant begomovirus infecting tomato in Argentina. Vaghi Medina CG, et al. Arch Virol. 2015 Feb;160(2):581-5. doi: 10.1007/s00705-014-2216-y. Epub 2014 Sep 25. PMID: 25252814 |
| 4 |
Bornancini VA, et al. Viruses. 2020 Feb 11;12(2):202. doi: 10.3390/v12020202. PMID: 32054104 |
| 5 |
Rapid detection of fifteen known soybean viruses by dot-immunobinding assay. Ali A. J Virol Methods. 2017 Nov;249:126-129. doi: 10.1016/j.jviromet.2017.09.003. Epub 2017 Sep 6. PMID: 28887190 |
| 6 |
Scientific Opinion on the pest categorisation of the tospoviruses. EFSA Panel on Plant Health (PLH). EFSA J. 2012 Jul 6;10(7):2772. doi: 10.2903/j.efsa.2012.2772. eCollection 2012 Jul. PMID: 42016075 |
| 7 |
Souza-Dias JAC, et al. Plant Dis. 2008 Mar;92(3):487. doi: 10.1094/PDIS-92-3-0487C. PMID: 30769698 |
| 8 |
Reyna PG, et al. Arch Virol. 2021 May;166(5):1409-1414. doi: 10.1007/s00705-021-05002-4. Epub 2021 Feb 28. PMID: 33646405 |
| 9 |
Diversity and prevalence of Brazilian bipartite begomovirus species associated to tomatoes. Fernandes FR, et al. Virus Genes. 2008 Feb;36(1):251-8. doi: 10.1007/s11262-007-0184-y. Epub 2008 Jan 4. PMID: 18175211 |
| 10 |
A New Geminivirus Associated with Tomato in the State of Sao Paulo, Brazil. Faria JC, et al. Plant Dis. 1997 Apr;81(4):423. doi: 10.1094/PDIS.1997.81.4.423B. PMID: 30861828 |