Tomato yellow spot virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000865405.1 |
| Isolate | Brazil |
| Release date | 2015/2/13 |
| Submitter | Fernandes,J.J., Carvalho,M.G., Andrade,E.C., Brommonschenkel,S.H., Fontes,E.P.B., Zerbini,F.M., Calegario,R.F., Ferreira,S.S. |
| Download | Genome |GFF3 |PEP |CDS |
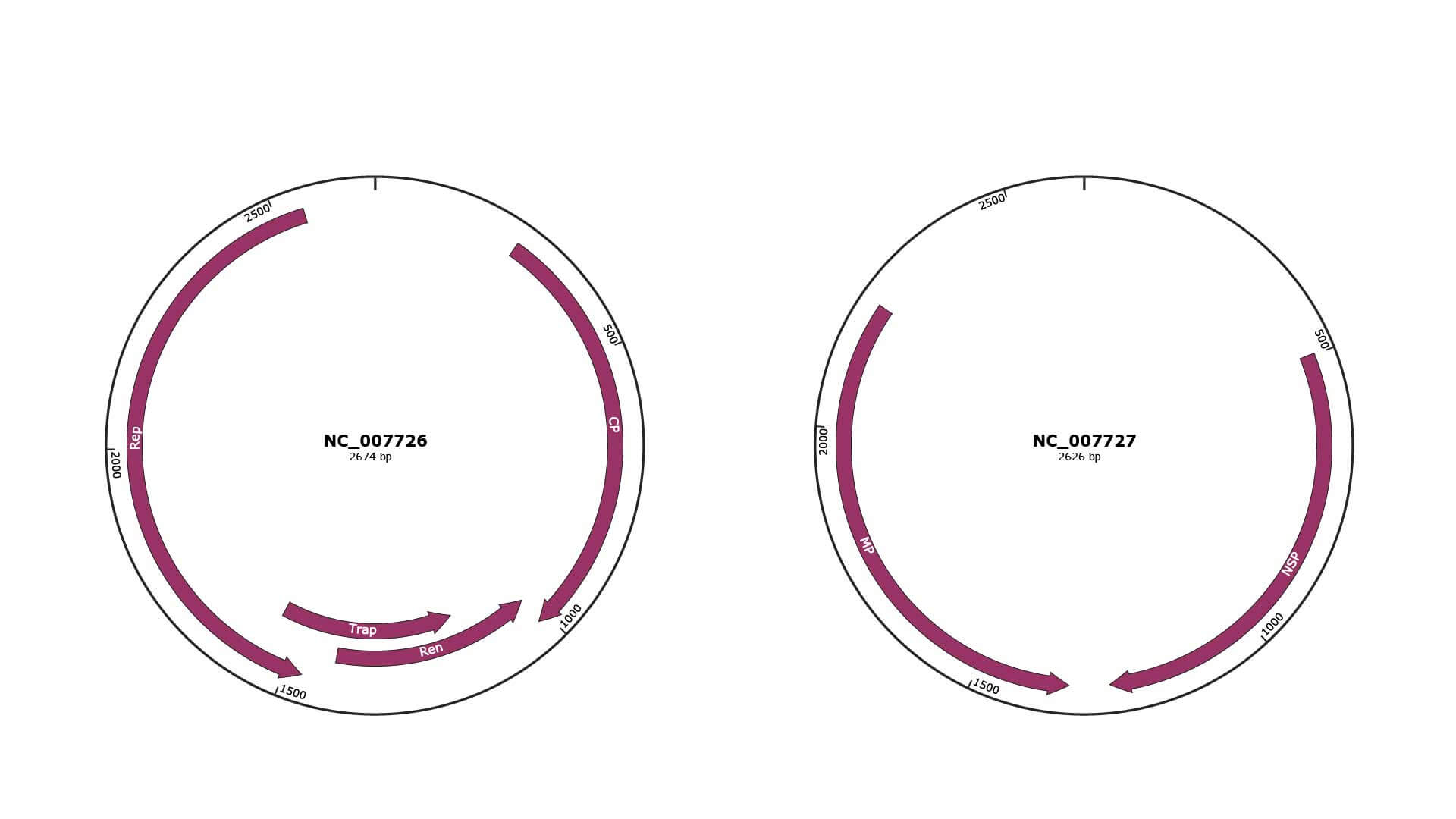
Genomic Organization
JBrowse
Genome
NC_007726
NC_007727
Gene Information
| NCBI Accession | YP_459913.1 |
|---|---|
| Location | 263-1018 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGGTCCCTCATGGCGCCCAATGGTGGGGACCTCAAAGGTAAGCCGCACTTCTAATTTCTCTCCTCGTGGAGGTATAGGCCCAAAATTCAACAAGGCCTCTGAATGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATATATCGTACGCTCAGAACGCCCGATGTTCCCAGAGGCTGTGAAGGGCCCTGTAAGGTCCAGTCTTACGAGCAACGTCACGATATCTCCCATGTTGGGAAGGTTATGTGTATATCCGATATTACGCGCGGCAACGGTATTACTCACCGGGTCGGTAAGCGTTTCTGTGTTAAGTCCGTGTATATTTTAGGCAAGGTATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTTGCATGTTCTGGTTGGTCAGAGACCGAAGACCCTATGGAACGCCAATGGATTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCCAGTACTGCAACCGTGAAGAACGATCTCCGTGATCGTTTCCAGGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGACAGTATGCCAGCAATGAGCAGGCGCTAGTCAAGCGGTTCTGGAAGGTCAACAACCATGTGGTCTACAATCACCAGGAGGCTGGCAAGTACGAGAACCACACGGAGAACGCATTATTATTGTATATGGCATGTACTCATGCATCTAACCCTGTGTATGCAACGCTGAAGATTCGAATCTATTTCTATGATTCAATCACAAATTAA |
| Protein Sequence | MPKRGPSWRPMVGTSKVSRTSNFSPRGGIGPKFNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDITRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSCMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_459914.1 |
|---|---|
| Location | 1015-1413 |
| Gene Name | Ren |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACCGGGGAACTCATCACTGTGCCTCAGGCAGAGAATGGCGTTTATATCTGGGAGATATCAAATCCCCTGTATTTCAAGATCTACCTAGTAGAAGAAATAATGTACACAACGACCAAAGTGTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACCAGGCATTCCTGAACTTCCAAGTCTGGACGACATCTCTGACAGCTTCTGGAACGACTTATTTGCATAGGTTTAGACACTTAGTCATGTTGTATTTAGACCGATTAGGCATTATTACGATAAACAATGTAATTAGAGCTGTTCGTTTTGCGACTGACAGATCATATGTAAATCATGTACTGGAAAATCATTCAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGELITVPQAENGVYIWEISNPLYFKIYLVEEIMYTTTKVYHIQIRFNHNLRRALDLHQAFLNFQVWTTSLTASGTTYLHRFRHLVMLYLDRLGIITINNVIRAVRFATDRSYVNHVLENHSIKFKIY |
| NCBI Accession | YP_459915.1 |
|---|---|
| Location | 1160-1549 |
| Gene Name | Trap |
| Protein Name | trans-activating protein |
| Coding Region | ATGCTAAATTCATCTTCATCGACTCCCCCCTCTATCAAACCACAACACAGGGCGGCGAAGAGAAGAGGAACTCGCCGTAGAAGGATAGATCTAGAGTGTGGATGCACTATATACGTCCACATCAGCTGCAGCAACCATGGATTCACGCACCGGGGAACTCATCACTGTGCCTCAGGCAGAGAATGGCGTTTATATCTGGGAGATATCAAATCCCCTGTATTTCAAGATCTACCTAGTAGAAGAAATAATGTACACAACGACCAAAGTGTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACCAGGCATTCCTGAACTTCCAAGTCTGGACGACATCTCTGACAGCTTCTGGAACGACTTATTTGCATAG |
| Protein Sequence | MLNSSSSTPPSIKPQHRAAKRRGTRRRRIDLECGCTIYVHISCSNHGFTHRGTHHCASGREWRLYLGDIKSPVFQDLPSRRNNVHNDQSVPHPDTVQPQPQESVGSPPGIPELPSLDDISDSFWNDLFA |
| NCBI Accession | YP_459916.1 |
|---|---|
| Location | 1470-2549 |
| Gene Name | Rep |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCATCAGCTCCTAAAAGATTTCGTATTTCTTCAAAAAACTACTTCCTCACATATCCTCGTTGTTCTCTCTCTAAAGAAGAGACACTTTCCCAATTACAAACCATAAATACTCCAACAAATAAGAAATTCATTAAAATCTGCAGAGAGCTTCACGAAGATGGGGAACCTCATCTCCACGTGCTTATCCAGTTCGAAGGGAAGTTCGTCTGCACAAATCAAAGACTCTTCGACCTGGTATCCCAAACAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGACAAAGACGGAGATACTCTCGAATGGGGGAAATTCCAGGTCGACGGACGAAGTGCTAGAGGAGGTCAGCATACGGCTAATGACGCTGCAGCTGAGGCGTTAAATGCTCCGGATAAACGAACGGCTCTTCAAATAATTAAAGAGAAGTTGCCGGAGAAATATCTTTTTCAATTTCATAATTTAAATTCTAATTTAGATAGAATTTTCTCAAAGGCTCCGGAGCCATGGGTTCCTCCGTTTCCCCTCTCCTCCTTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCCGATGAATATTTTGGGAGAGGTTCAGCTGCGCGGCCATTGAGACCTAAGAGTTTGATAGTCGAAGGTGATTCAAGGACAGGGAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTACTTGAGTGGCCATCTGGACTTCAACTCAAAGGTTTTCTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCATTATCTAAAGTTAAAGCACTGGAAGGAATTGATTGGTGCTCAAAAAGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTACAGTTGGCATCCCAGCAATCGTGCTCTGCAATCCTGGTGAGGGAGTCAGTTATAAAGATTTCCTCGACAAAGAAGAGAATGCAGCTTTAAAATCGTGGACACTTCACAATGCTAAATTCATCTTCATCGACTCCCCCCTCTATCAAACCACAACACAGGGCGGCGAAGAGAAGAGGAACTCGCCGTAG |
| Protein Sequence | MPSAPKRFRISSKNYFLTYPRCSLSKEETLSQLQTINTPTNKKFIKICRELHEDGEPHLHVLIQFEGKFVCTNQRLFDLVSQTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGKFQVDGRSARGGQHTANDAAAEALNAPDKRTALQIIKEKLPEKYLFQFHNLNSNLDRIFSKAPEPWVPPFPLSSFTNVPDEMQEWADEYFGRGSAARPLRPKSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQITVGIPAIVLCNPGEGVSYKDFLDKEENAALKSWTLHNAKFIFIDSPLYQTTTQGGEEKRNSP |
| NCBI Accession | YP_459917.1 |
|---|---|
| Location | 498-1268 |
| Gene Name | NSP |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATCAAGCCAAGTATAGACGTGGGTTATCTACAAATTATCGTCGTAATTACACGCGAAATGCCGTTCTCAAGCGTTCTTATGGCGTAAAGTTTAGCAATGTGAGACGACGTCCAAGTAATCATAACAGGGCCCATGAAGATGTTAAGATGGCAGCCCAGCGTATACATGAGAACCAGTTTGGGCCTGAGTTTGTTATGGGCCATAATTCAGCCATTTCAACGTTTATCACCTTTCCTAGCCTCGGTAAGATCGAACCTAATCGAACCAGGTCCTATGTCAAGCTAAAACGACTCCGATTTAAGGGCACTGTGAAGATTGAACGTGTTCAAAACGATGTCATCATGGATGGTTCAGCCCCGAAGATTGAAGGAGTCTTTTCACTAGTGGTCGTGGTGGATCGTAAACCCCACTTGGGATCATCTGGGTGTTTGTATACGTTTGACGAGTTATTCGGTGCCAGGATCAACAGTCATGGCAATCTAGCCATAACATCCTCACTGAAAGACCGGTTTTATATTCGACACGTGTTCAAACGTGTATTGTCTGTGGAGAAGGATACGTTAATGGTTGATCTTGAAGGGACTACATCTCTCTCTAACAGGCGTTTTAATTGTTGGTCTACGTTTAAGGATATAGACCGTGATTCATGTAACGGTGTTTATGCAAACATAAGCAAGAACGCCCTCTTAGTTTATTACTGCTGGATGTCGGACTCGTCGTCCAAGGCATCGACATTTGTATCGTATGATCTTGATTATATTGGTTAA |
| Protein Sequence | MYQAKYRRGLSTNYRRNYTRNAVLKRSYGVKFSNVRRRPSNHNRAHEDVKMAAQRIHENQFGPEFVMGHNSAISTFITFPSLGKIEPNRTRSYVKLKRLRFKGTVKIERVQNDVIMDGSAPKIEGVFSLVVVVDRKPHLGSSGCLYTFDELFGARINSHGNLAITSSLKDRFYIRHVFKRVLSVEKDTLMVDLEGTTSLSNRRFNCWSTFKDIDRDSCNGVYANISKNALLVYYCWMSDSSSKASTFVSYDLDYIG |
| NCBI Accession | YP_459918.1 |
|---|---|
| Location | 1340-2221 |
| Gene Name | MP |
| Protein Name | movement protein |
| Coding Region | ATGGATTCTCAGTTAGTTAATCCACCAAATGCCTTTAATTATATAGAATCTCAGCGTGATGAATATAAGCTTTCGCATGATCTAACTGAGATCGTTCTGCAGTTTCCTTCTGCAGCGGCTCATATAAGCGCCAGACTCAGCCGTAGCTGTATGAAGATAGACCACTGCGTCATAGAATACCGGCAACAGGTACCCATAAACGCCGCAGGTTCCGTTATCGTGGAGATTCACGACAAGAGAATGACGGACAATGAATCGTTACAGGCGTCATGGACATTCCCGATCAGATGCAACATAGATCTCCACTATTTCTCCTGTTCATTCTTCTCCCTCAAAGACCCAATACCGTGGAAATTGTACTACAGAGTGAGCGACACGAATGTTCACCAGAGCATCCACTTCGCGAAATTCAAGGGGAAGTTGAAACTGTCGACGGCTAAACATTCGGTGGATATTGCTTTCCGAGCACCGACGGTCAAGATCTTATCTAAACAGTTCACGGATAGAGATGTAGATTTCAGCCACGTGGGCTACGGGAAATGGGAAAGGAAATTGATCAGATCCGCTTCAACTGTCAAGTATGGGCTACCAAGCCCAATAACAATTGATCCAGGCGAGACATGGGCTTCGCGCAGTACGCTGGGGATCGGTCAATCGAGTACGGAATCAGAGGTGGAGAACGCAGCACACCCATATCGAGGACTACACAGATTGGGAACCACCATGTTAGACCCAGGCGACTCGGCCTCAATAGTTGCTGCGAGAAGGGCCCAATCGCATATAACCATGTCAGAGGCCCAAATAAACGACCTAGTGAGGAATGCGGTCCAAGAGTGTATAAAAACAAATTGTATTCCCCCAGAGSCCAAATCATTGAGTTAA |
| Protein Sequence | MDSQLVNPPNAFNYIESQRDEYKLSHDLTEIVLQFPSAAAHISARLSRSCMKIDHCVIEYRQQVPINAAGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSCSFFSLKDPIPWKLYYRVSDTNVHQSIHFAKFKGKLKLSTAKHSVDIAFRAPTVKILSKQFTDRDVDFSHVGYGKWERKLIRSASTVKYGLPSPITIDPGETWASRSTLGIGQSSTESEVENAAHPYRGLHRLGTTMLDPGDSASIVAARRAQSHITMSEAQINDLVRNAVQECIKTNCIPPEXKSLS |
References More References in PubMed
| 1 |
Fernandes-Acioli NAN, et al. Plant Dis. 2014 Oct;98(10):1445. doi: 10.1094/PDIS-11-12-1016-PDN. PMID: 30703991 |
|---|---|
| 2 |
Qiao N, et al. Genes Genomics. 2023 Jan;45(1):23-37. doi: 10.1007/s13258-022-01325-x. Epub 2022 Nov 12. PMID: 36371493 |
| 3 |
First Report of Tomato yellow spot virus Infecting Leonurus sibiricus in Brazil. Barbosa JC, et al. Plant Dis. 2013 Feb;97(2):289. doi: 10.1094/PDIS-07-12-0692-PDN. PMID: 30722321 |
| 4 |
Andrade EC, et al. J Gen Virol. 2006 Dec;87(Pt 12):3687-3696. doi: 10.1099/vir.0.82279-0. PMID: 17098986 |
| 5 |
Nava A, et al. Arch Virol. 2013 Feb;158(2):399-406. doi: 10.1007/s00705-012-1501-x. Epub 2012 Oct 14. PMID: 23064695 |
| 6 |
Leibman D, et al. Arch Virol. 2015 Nov;160(11):2727-39. doi: 10.1007/s00705-015-2551-7. Epub 2015 Aug 9. PMID: 26255053 |
| 7 |
First Report of Pelargonium zonate spot virus from Tomato in the United States. Liu HY, et al. Plant Dis. 2007 May;91(5):633. doi: 10.1094/PDIS-91-5-0633B. PMID: 30780718 |
| 8 |
Tospoviruses in the Mediterranean area. Turina M, et al. Adv Virus Res. 2012;84:403-37. doi: 10.1016/B978-0-12-394314-9.00012-9. PMID: 22682175 |
| 9 |
Sabra A, et al. Plants (Basel). 2022 Nov 18;11(22):3157. doi: 10.3390/plants11223157. PMID: 36432886 |
| 10 |
First Report of Tomato yellow ring virus (Tospovirus, Bunyaviridae) Infecting Tomato in Kenya. Birithia R, et al. Plant Dis. 2012 Sep;96(9):1384. doi: 10.1094/PDIS-05-12-0462-PDN. PMID: 30727189 |