Tomato yellow mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000904935.1 |
| Isolate | Costa Rica |
| Release date | 2015/2/22 |
| Submitter | Maliano,M.R., Melgarejo,T., Rojas,M., Barboza,N., Gilbertson,R.L. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
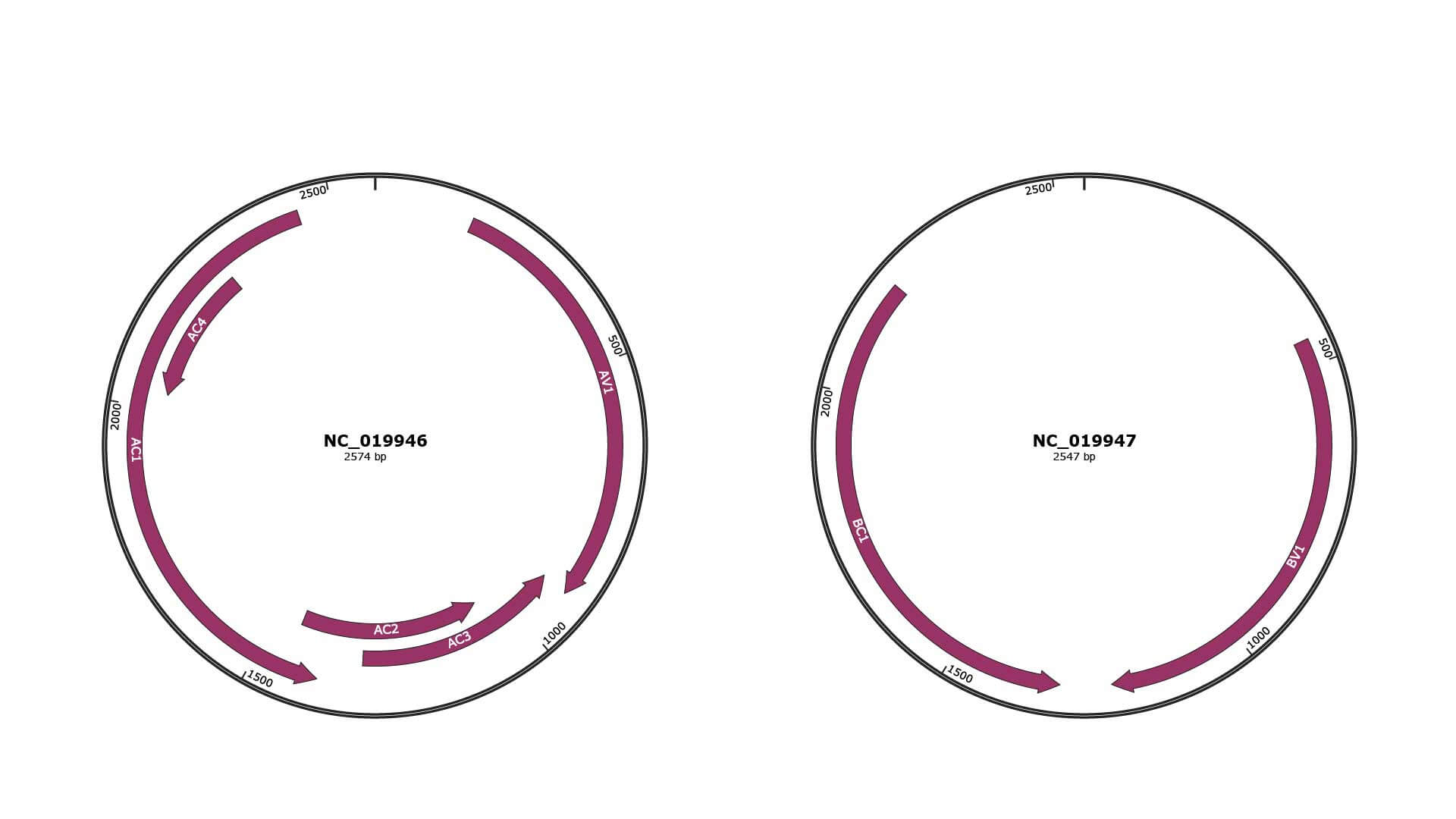
JBrowse
Genome
NC_019946
NC_019947
Gene Information
| NCBI Accession | YP_007250558.1 |
|---|---|
| Location | 169-915 |
| Gene Name | AV1 |
| Protein Name | capsid protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCTTGGCGTTTAAGCGCGGGGACCACTAAGGTCTCCCGCTCTAGTAATTATTCTCCAAATGGAGGTATGGGCCCTAAGGCCACTTCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGCACGTTGAGAGGCCCTGATGTGCCCAAAGGCTGCGAAGGTCCCTGTAAGGTCCAGTCCTACGAGCAGCGTCATGACGTCTCTCATGTTGGTAAAGTCATGTGCATCTCAGACATCACACGAGGTGGTGGTATTACCCACCGTGTAGGTAAACGTTTTTGCGTTAAGTCTGTTTACATTTTAGGGAAGGTATGGATGGACGATAACATCAAGTTGAAGAACCACACGAATAGTGTTATGTTCTGGCTGGTTAGAGACCGGAGACCCTATGGCACCCCTATGGATTTTGGTCAAGTGTTCAACATGTACGACAATGAGCCCAGTACAGCCACTGTTAAGAACGATCTTCGTGATCGTTTTCAAGTGCTACACAAGTTCTACGCCAAGGTCACGGGTGGACAGTATGCCAGCAATGAGCAGGCGTTGGTCAAGCGTTTCTGGAAGGTTAACAACCATGTCGTCTATAACCATCAAGAAGCAGGGAAATACGAGAATCACACTGAGAATGCTTTGTTATTGTACATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACATTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWRLSAGTTKVSRSSNYSPNGGMGPKATSWVNRPMYRKPRIYRTLRGPDVPKGCEGPCKVQSYEQRHDVSHVGKVMCISDITRGGGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVLHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_007250559.1 |
|---|---|
| Location | 912-1310 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAGAGCATCACTGCGCATCAGGCAGAGAATTCCGTTTTTATTTGGGATGTTCCAAATCCCCTCTATTTCAGGATGTGTCGAGTAGAAGAGCCACTTTACACATCGACCAGAATCTACCACATTCAAATCAGGTGCAACCACAACCTCAGGAGGGCACTGAATCTTCACAAAGCTTTTCTGAACTTCCAAGTCTGGACGACATCAATTCGAGCTTCTGGGAAGACTTACTTAAATAGATTTAAGTATTTAGTTTTACTGTATTTAGATAGAATAGGTGTTATTGGGATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAAGGCATATGTAAATCATGTACTTGAGAATCATGAAATAAAAGTAAATCTTTATTAA |
| Protein Sequence | MDSRTGESITAHQAENSVFIWDVPNPLYFRMCRVEEPLYTSTRIYHIQIRCNHNLRRALNLHKAFLNFQVWTTSIRASGKTYLNRFKYLVLLYLDRIGVIGINNVIRAVRFATDKAYVNHVLENHEIKVNLY |
| NCBI Accession | YP_007250560.1 |
|---|---|
| Location | 1057-1446 |
| Gene Name | AC2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCTCATCACAGGAACGCTAAGAGAAGAGCAATACGTAGGAAACGTATAGACCTAAACTGTGGCTGTTCAATATTCCTACACATCAACTGCTCCAACAATGGATTCACGCACAGGGGAGAGCATCACTGCGCATCAGGCAGAGAATTCCGTTTTTATTTGGGATGTTCCAAATCCCCTCTATTTCAGGATGTGTCGAGTAGAAGAGCCACTTTACACATCGACCAGAATCTACCACATTCAAATCAGGTGCAACCACAACCTCAGGAGGGCACTGAATCTTCACAAAGCTTTTCTGAACTTCCAAGTCTGGACGACATCAATTCGAGCTTCTGGGAAGACTTACTTAAATAG |
| Protein Sequence | MLNSSSSTPPSIKPHHRNAKRRAIRRKRIDLNCGCSIFLHINCSNNGFTHRGEHHCASGREFRFYLGCSKSPLFQDVSSRRATLHIDQNLPHSNQVQPQPQEGTESSQSFSELPSLDDINSSFWEDLLK |
| NCBI Accession | YP_007250561.1 |
|---|---|
| Location | 1388-2443 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCCCCGCCGAAAAAATTTAGACTATCGGCTAAAAATATATTCTTAACATATCCTCGCTGTTCTTTAACAAAAGAAGAGGCTCTCTTTCAACTCCAGAATATCTCTCTACCTTCGAATAAATTATTCATTCGTGTCGCAAGGGAACTCCACGAAGATGGGGAACCTCATCTCCATGTGCTTATACAACTCGAGGGTAAAGTCCAAATATACAACCAGAAACTCTTCGACCTCAGTTCCACAAGCAGATCAGCATATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGACGTTAAATCATACATGGAGAAAGACGGAGAATTCCTTGATTTTGGAGTTTTCCAGATCGATGGAAGATCAAGTAGAGGAGGTATACAGACAACCAATGATTCATATGCAAAAGCGTTAAACGCTGGGTCTGCTGAATCTGCACTACAAATTTTAAAAGAAGAACAACCTGCTCATTATTTTCTTCATTATCATAATTTGGTCAATAATGCAAATAGGATCTTTCAAAAGGCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCATCATTCAACGCTGTTCCTGACGAGATGCAGGAATGGGCTGATGATTATTTTGGAAGAGGTGCCGCTGCGCGGCCGGAAAGACCTATTAGTATCATCGTCGAGGGTGATTCAAGAACAGGGAAGACAATGTGGGCTCGTTCTTTAGGCCCACATAATTACTTGAGTGGTCATTTAGATTTCAATTCTAGGGTTTACTCGAACGAAGTGGAATATAACGTCATCGATGACGTCGCACCGCACTACTTAAAGTTAAAGCACTGGAAAGAGTTGATTGGGGCCCAGAAAGATTGGCAGTCCAACTGTAAGTACGGCAAGCCAGTTCAAATTAAAGGGGGCATACCATCAATCGTGCTGTGCAATCCAGGAGACGGGGGGAGCTATAAAGATTTCCTCGACAAAGAGGAAAATGCGTCACTAAAACAGTGGACTCTCAAAAATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCTCATCACAGGAACGCTAA |
| Protein Sequence | MPPPKKFRLSAKNIFLTYPRCSLTKEEALFQLQNISLPSNKLFIRVARELHEDGEPHLHVLIQLEGKVQIYNQKLFDLSSTSRSAYFHPNIQGAKSSSDVKSYMEKDGEFLDFGVFQIDGRSSRGGIQTTNDSYAKALNAGSAESALQILKEEQPAHYFLHYHNLVNNANRIFQKAPEPWVPPFQLSSFNAVPDEMQEWADDYFGRGAAARPERPISIIVEGDSRTGKTMWARSLGPHNYLSGHLDFNSRVYSNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGDGGSYKDFLDKEENASLKQWTLKNAKFIFLNSPLYQTSSQER |
| NCBI Accession | YP_007250562.1 |
|---|---|
| Location | 2029-2286 |
| Gene Name | AC4 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGGGAACCTCATCTCCATGTGCTTATACAACTCGAGGGTAAAGTCCAAATATACAACCAGAAACTCTTCGACCTCAGTTCCACAAGCAGATCAGCATATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGACGTTAAATCATACATGGAGAAAGACGGAGAATTCCTTGATTTTGGAGTTTTCCAGATCGATGGAAGATCAAGTAGAGGAGGTATACAGACAACCAATGATTCATATGCAAAAGCGTTAA |
| Protein Sequence | MGNLISMCLYNSRVKSKYTTRNSSTSVPQADQHISIRTFRELRAAQTLNHTWRKTENSLILEFSRSMEDQVEEVYRQPMIHMQKR |
| NCBI Accession | YP_007250563.1 |
|---|---|
| Location | 457-1227 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATCATTCTAGATACAGGCGCACCTGGTTATCTACACAACGTCGAGCATATAATCGACAACCACCGTTTAAGCGTCTATATACTTCGAGACGTAATGAACTTAAACGTCGTCCCATTAGCGATGTTATTGCTTATGACGATAAGAAGATGTCTGCTCAGCGTATACATGAGGATCAATTTGGACCAGAATTCGTTATGTTGCATAATACAGCTTTTTCAACTTATGTTACTTATCCCAGCATAGTGAAGAATGTACCTAACAGAGTTAAGTCATATATTAAGATAAAACGGTTACGTTTTAAGGGGACTTTGAAGATAGAACGTGTACATGCAGATGTTAACATGGACTGTCCAGTTTCTAAGATAGAAGGAGTGTTCTCTATGGTTATTGTGGTTGATCGTAAACCACATTTGAACGCAACAGGATGTCTACTGACGTTTGACGAGTTATTTGGGGCTAGGATTCATAGTCATGGTAATCTAGCTATAACTCCAGCCTTGAAAGATCGTTTTTATATTCGTCATGTATTGAAACGAGTATTATCGGTTGAGAAAGATAGCTTGATGGTGGACCTTGAAGGAACGACAACGTTTTCTAGCAAACGATTTAGTTGTTGGTCTTCTTTTAACGACCTTGAGCGAGATTCATGTAATGGTGTTTATGCTAATATTAGCAAGAACGCTATCTTGGTGTATTATTGCTGGATGTCAGACGTAATGTCTAAGGCATCAACATTTGTATCATTCGATCTCGACTATGTTGGCTAA |
| Protein Sequence | MYHSRYRRTWLSTQRRAYNRQPPFKRLYTSRRNELKRRPISDVIAYDDKKMSAQRIHEDQFGPEFVMLHNTAFSTYVTYPSIVKNVPNRVKSYIKIKRLRFKGTLKIERVHADVNMDCPVSKIEGVFSMVIVVDRKPHLNATGCLLTFDELFGARIHSHGNLAITPALKDRFYIRHVLKRVLSVEKDSLMVDLEGTTTFSSKRFSCWSSFNDLERDSCNGVYANISKNAILVYYCWMSDVMSKASTFVSFDLDYVG |
| NCBI Accession | YP_007250564.1 |
|---|---|
| Location | 1315-2196 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGATTCTCAGCTAGTCATTCCTCCTAATGCCTTTAATTACATAGACTCTCATCGTGAAGAGTATCAGCTTTCTCATGACCTAACTGAAATTGTCTTGCAGTTTCCGTCGACGGCGGCTCAGCTAAGTGCTCGATTGAGTCGCAGCTGTATGAAAATAGACCACTGCGTCATTGAATACAGGCAACAAGTGCCTATTAACGCATCTGGAACGGTGATAGTGGAGATCCATGACAAAAGGATGCAGGACAATGAGTCATTACAAGCGTCGTGGACATTTCCGATCAGATGTAACATAGATCTACATTATTTTTCATCGTCGTTCTTCTCGTTAAAAGATCCTATACCTTGGAAGTTATATTACAAGGTCAGTGACTCGAATGTACACCAAAGGACGCACTTCGCCAAGTTCAAAGGGAAACTCAAACTGTCTACTGCGAAAAATTCAGTGGATATACCTTTCCGAGCACCCACGGTCAGGATCTTGTCGAAACAGTTTACGGAGAAGGATATTGATTTCCATCACGTGGGTTTCGGAAAGTGGGAGAGAAGACTAGTCCGTTCCGCATCGTCACGAATAATTGGGCTACCAGGCCCAATAGAAATAAGGCCTGGGGAATCTTGGGCTAGTAGAAGTACCATAGGAACAGCCCATTCAAATGCGGAATCGGAGGTTACTGACGCACTATACCCTTACAGAGAGCTGAACAGATTAAGCACCCCTATTTTAGACCCAGGTGATTCTGCGTCAGTAATTGGGATTCAGCGAACGGAGTCCAACTTAACAATGTCTATGTCACAGTTAAATGACATTGTCAGGTCAACTGTTCAAGAGTGTATTAACACAAACTGTGTTCCTCCCGTGCCCAAATCTTTGAAATGA |
| Protein Sequence | MDSQLVIPPNAFNYIDSHREEYQLSHDLTEIVLQFPSTAAQLSARLSRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMQDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVSDSNVHQRTHFAKFKGKLKLSTAKNSVDIPFRAPTVRILSKQFTEKDIDFHHVGFGKWERRLVRSASSRIIGLPGPIEIRPGESWASRSTIGTAHSNAESEVTDALYPYRELNRLSTPILDPGDSASVIGIQRTESNLTMSMSQLNDIVRSTVQECINTNCVPPVPKSLK |
References More References in PubMed
| 1 |
Peng M, et al. Microbiol Resour Announc. 2022 Jun 16;11(6):e0029722. doi: 10.1128/mra.00297-22. Epub 2022 May 23. PMID: 35604141 |
|---|---|
| 2 |
Tomato mottle wrinkle virus, a recombinant begomovirus infecting tomato in Argentina. Vaghi Medina CG, et al. Arch Virol. 2015 Feb;160(2):581-5. doi: 10.1007/s00705-014-2216-y. Epub 2014 Sep 25. PMID: 25252814 |
| 3 |
Taino Tomato Mottle Virus, a New Bipartite Geminivirus from Cuba. Ramos PL, et al. Plant Dis. 1997 Sep;81(9):1095. doi: 10.1094/PDIS.1997.81.9.1095C. PMID: 30861977 |
| 4 |
Kon T, et al. Arch Virol. 2024 Apr 30;169(5):113. doi: 10.1007/s00705-024-06035-1. PMID: 38684570 |
| 5 |
Zhang S, et al. Mol Plant Pathol. 2022 Sep;23(9):1262-1277. doi: 10.1111/mpp.13229. Epub 2022 May 22. PMID: 35598295 |
| 6 |
Lett JM, et al. Arch Virol. 2015 Nov;160(11):2887-90. doi: 10.1007/s00705-015-2558-0. Epub 2015 Aug 9. PMID: 26255054 |
| 7 |
First Report of Tomato yellow leaf curl virus in Tomato in Costa Rica. Barboza N, et al. Plant Dis. 2014 May;98(5):699. doi: 10.1094/PDIS-08-13-0881-PDN. PMID: 30708517 |
| 8 |
Gill U, et al. Theor Appl Genet. 2019 May;132(5):1543-1554. doi: 10.1007/s00122-019-03298-0. Epub 2019 Feb 13. PMID: 30758531 |
| 9 |
Nava A, et al. Arch Virol. 2013 Feb;158(2):399-406. doi: 10.1007/s00705-012-1501-x. Epub 2012 Oct 14. PMID: 23064695 |
| 10 |
Ramos PL, et al. Arch Virol. 2003 Sep;148(9):1697-712. doi: 10.1007/s00705-003-0136-3. PMID: 14505083 |