Tomato yellow margin leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000843525.4 |
| Isolate | Venezuela: Merida |
| Release date | 2017/10/11 |
| Submitter | Nava,A., Londono,A., Polston,J.E., Nava,A.R., Patte,C.P., Hiebert,E., Palston,J.E. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
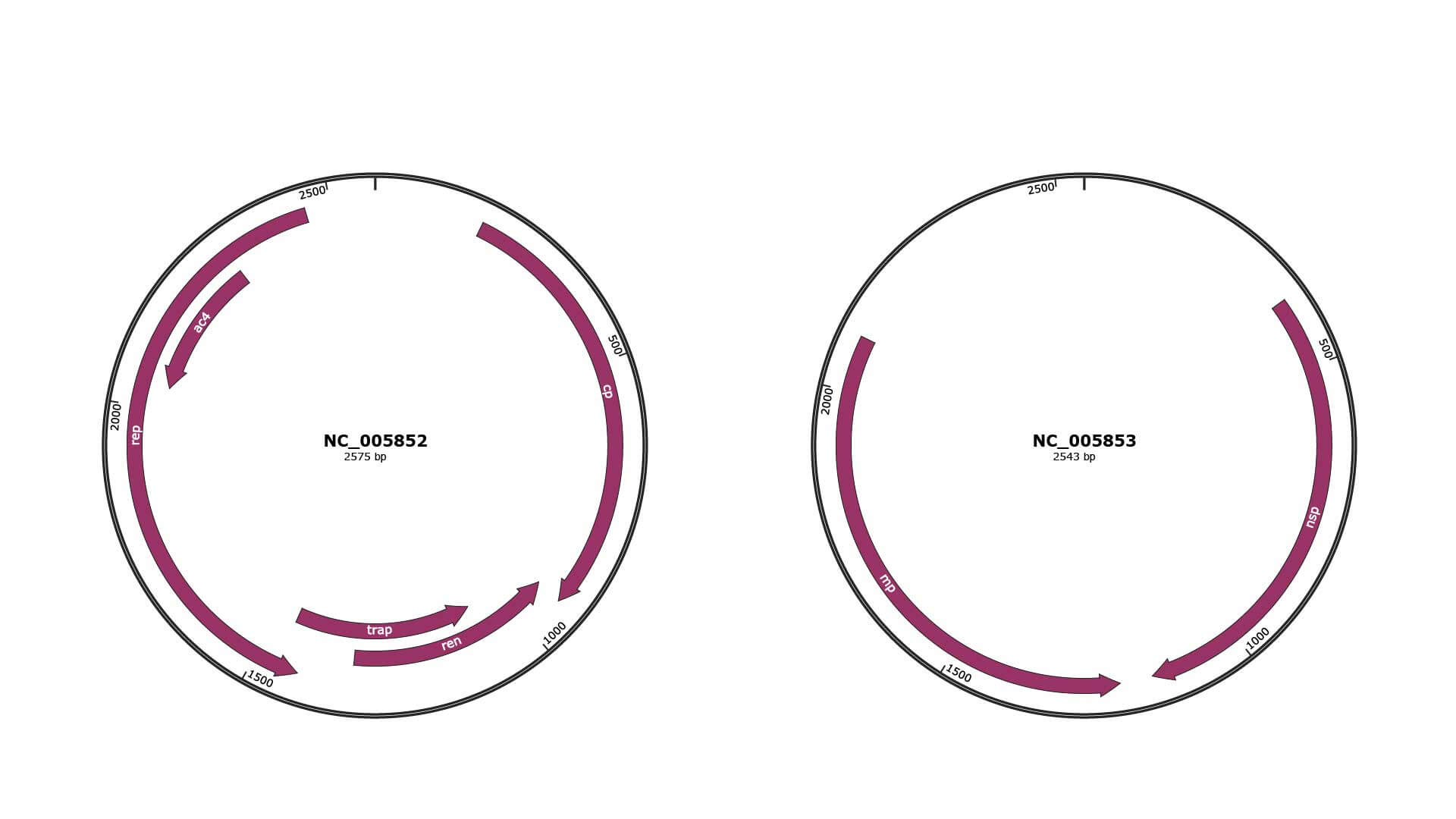
JBrowse
Genome
NC_005852
NC_005853
Gene Information
| NCBI Accession | YP_006456.1 |
|---|---|
| Location | 186-932 |
| Gene Name | cp |
| Protein Name | CP |
| Coding Region | ATGCCTAAGCGCGATGCTCCTTGGCGCTTATCGGCTGGGACCACTAAGGTCAGTCGTTCCTCCAATTATTCCCCTAGGAGTAATATGGGCCCAAAGGCCTCTGCTTGGGTTAATAGGCCCATGTACAGGAAGCCCAGAATTTACAGGACGTTAAGGGGGCCTGATATTCCTAAGGGTTGTGAAGGCCCATGTAAAGTTCAGTCCTTCGAGCAGAGGCATGATATTTCTCATGTTGGCAAGGTGCTTTGTGTTTCTGATGTGACACGTGGTAACGGTATTACCCACCGTGTAGGCAAGAGGTTCTGTGTCAAGTCTGTGTATATCTTAGGCAAGGTATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTCAGAGACCGGAGACCTTATGGAACCCCCATGGACTTTGGCCAAGTGTTTAACATGTTTGATAACGAGCCAAGTACTGCCACTGTGAAGAACGATCTCCGTGATCGTTTCCAGGTTATGCACAAGTTTTATGCTAAGGTTACCGGTGGACAATATGCCAGCAATGAGCAAGCCTTGGTCAGGAGATTCTGGAAGGTCAACAACCATGTGGTGTACAACCATCAAGAAGCAGGGAAATACGAGAACCACACTGAGAATGCTCTATTATTGTATATGGCATGTACCCATGCGTCTAATCCTGTGTATGCTACATTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWRLSAGTTKVSRSSNYSPRSNMGPKASAWVNRPMYRKPRIYRTLRGPDIPKGCEGPCKVQSFEQRHDISHVGKVLCVSDVTRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_006457.1 |
|---|---|
| Location | 929-1327 |
| Gene Name | ren |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAGGGGAAACCATCACTGCTCGTCAGGCACAGAATGGCGTTTTTATCTGGGAGGTGCCGAATCCCCTCTTTTTCAAGATTCAACGAGTGGAGGACCCTCTGTACACAACGACCAGAGTGTACCACATCCAAATCAGGTTCAACCACAACCTGAGGAAGGCATTGACTCTACACAAGGCCTATCTGAACTTCCAAGTCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAAATAGATTCAAACATTATGTCTTGTTGTATTTAGATCAGTTAGGAGTTATTTCAATAAACAATGTAATCAGAGCTGTTAGTTATGCAACAGACAGAAAATATGTAAACCATGTGCTTGAAGATCATGAAATAAAATTCAAACTTTATTAA |
| Protein Sequence | MDSRTGETITARQAQNGVFIWEVPNPLFFKIQRVEDPLYTTTRVYHIQIRFNHNLRKALTLHKAYLNFQVWTTSVQASGTTYLNRFKHYVLLYLDQLGVISINNVIRAVSYATDRKYVNHVLEDHEIKFKLY |
| NCBI Accession | YP_006458.1 |
|---|---|
| Location | 1074-1460 |
| Gene Name | trap |
| Protein Name | TrAP |
| Coding Region | ATGCAAAATTCATCTTCCTCGACTCCCCCCTCTATTAAACCAACACATCGTCTTGCAAAGAGAAGACCCCGACGTAAAAGAATAGACCTAAGCTGCGGGTGTACCATATACGTCCATCTCCTCTGCAGCAACTATGGATTCACGCACAGGGGAAACCATCACTGCTCGTCAGGCACAGAATGGCGTTTTTATCTGGGAGGTGCCGAATCCCCTCTTTTTCAAGATTCAACGAGTGGAGGACCCTCTGTACACAACGACCAGAGTGTACCACATCCAAATCAGGTTCAACCACAACCTGAGGAAGGCATTGACTCTACACAAGGCCTATCTGAACTTCCAAGTCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAAATAG |
| Protein Sequence | MQNSSSSTPPSIKPTHRLAKRRPRRKRIDLSCGCTIYVHLLCSNYGFTHRGNHHCSSGTEWRFYLGGAESPLFQDSTSGGPSVHNDQSVPHPNQVQPQPEEGIDSTQGLSELPSLDDISSSFWDDIFK |
| NCBI Accession | YP_006459.1 |
|---|---|
| Location | 1423-2457 |
| Gene Name | rep |
| Protein Name | REP |
| Coding Region | ATGCCTACTGCACGTGCCTTTAAAATTAATGCCAAGAATTATTTCCTTACATACCCCAAGTGCTCTCTATCCAAAGAAGAAGCACTTTCCCAATTACAAAACCTAATCACTCCGACAAACAAGAAATTCATTAAAGTGTGCAAAGAATTGCATGAAGATGGGGAACCGCATCTGCATGTGCTTATCCAGTTCGAAGGCAAGTACCAGTGCAAAAATAACAGATTCTTCGATCTGGTTTCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATTGATAAGGACGGAGACACAATTCAATGGGGGGAATTCCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAATCTGCTAATGACACATACGCAAAGGCATTAAATGCTAGGTCATCTGAAGAAGCGTTGCAGATTATAAAGGAAGAACAACCGCAACACTTCTTTCTTCAACATCATAACTTGTTAGCCAATGCAACCAAAATATTTCGTAAACCTCCTGAACCATGGGTCCCTCCTTTTCGACTATCGTCATTCATAAATGTTCCAGTTGATATGCAAGAATGGGCAGATGATTATTTTGGGAGGGATTCCGCTGCGCGGCCAGAAAGACCTATAAGTTTAATCGTTGAAGGTGATTCTAGAACAGGGAAAACAATGTGGGCACGTGCATTAGGTTCTCATAATTACCTAAGTGGTCACATGGATTTCAATTCTAGGGTTTACTCAAACGATGTAGAGTATAACGTCATTGATGATGTCAACCCACAATATTTAAAAATAAAGCACTGGAAAGAATTGATTGGGGCCCAGAAAGACTGGCAGTCCAACTGTAAATATGGAAAGCCTGTTCAAATTAAAGGTGGAATTCCCGCTATCGTGCTTTGCAATCCAGGGGAGGGGTCTTCCTATAAAAGGTACCTAGACAAAGAGGAAAATACATCTCTCAGAGCGTGGACACTCCATAATGCAAAATTCATCTTCCTCGACTCCCCCCTCTATTAA |
| Protein Sequence | MPTARAFKINAKNYFLTYPKCSLSKEEALSQLQNLITPTNKKFIKVCKELHEDGEPHLHVLIQFEGKYQCKNNRFFDLVSPTRSTHFHPNIQGAKSSSDVKSYIDKDGDTIQWGEFQIDGRSARGGQQSANDTYAKALNARSSEEALQIIKEEQPQHFFLQHHNLLANATKIFRKPPEPWVPPFRLSSFINVPVDMQEWADDYFGRDSAARPERPISLIVEGDSRTGKTMWARALGSHNYLSGHMDFNSRVYSNDVEYNVIDDVNPQYLKIKHWKELIGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGSSYKRYLDKEENTSLRAWTLHNAKFIFLDSPLY |
| NCBI Accession | YP_006460.1 |
|---|---|
| Location | 2043-2306 |
| Gene Name | ac4 |
| Protein Name | AC4 |
| Coding Region | ATGAAGATGGGGAACCGCATCTGCATGTGCTTATCCAGTTCGAAGGCAAGTACCAGTGCAAAAATAACAGATTCTTCGATCTGGTTTCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATTGATAAGGACGGAGACACAATTCAATGGGGGGAATTCCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAATCTGCTAATGACACATACGCAAAGGCATTAA |
| Protein Sequence | MKMGNRICMCLSSSKASTSAKITDSSIWFPQPGQHISIRTFRELNPAPMSSPTLIRTETQFNGGNSRSTEDLLEEVSNLLMTHTQRH |
| NCBI Accession | YP_006461.1 |
|---|---|
| Location | 382-1155 |
| Gene Name | nsp |
| Protein Name | NSP |
| Coding Region | ATGTATCCAGTTAGATATAAACCTGATGCTAATAATTATAAGAGGAGATATTATTCACGTTCTAATGTGTTTAAGAGATCATCTGGTGTTAAACGTGCAGATGGGAAACGTAGAGCTACCCAACAAAATAAGTCTCATGAAGAGCCCAAGATGTCAGCCCAACGTATTCATGAGAATCAATATGGACCTGAATTTGTAATGACTCATATATATCTGCTATTTCCACATATATTAACTACCCCCATTTGGGTAAGATTGAACCTAACCCGAAGCAGGTCGTATATTAAGTTGAAACGACTCAGGTTTAAGGGAACTGTTAAGATTGAACGAGTACATGCTGATGTTGCCATGGATGGTTTACCCCCTAAGATTGAAGGTGTTTTTTCACTTGTTATTGTGGTGGATCGTAAACCTCATTTGAGTCCTTCAGGATCTCTGCTCACATTTGATGAGTTATTTGGTGCAAGGATTAATAGTCATGGTAATTTAGCGATAGCTTCCTCCTTCAAAGACAGATTCTACATTCGTCATGTGTTGAAGCGTGTTTTATCTGTGGAGAAGGATAGTACAATGGTCGACCTTGAAGGATCAACGTCACTCTCTAATAGGCGTTATAATTGTTGGGCTAGTTTTAAGGACTTAGATCATGACTCTTGTAAGGGTGTTTATGATAATATAAGCAAGAACGCCCTATTAATTTATTATTGTTGGATGTCTGATGTCACTTCTAAGGCATCTACCTTTGTATCATTTGATCTTGATTATGTTGGATGA |
| Protein Sequence | MYPVRYKPDANNYKRRYYSRSNVFKRSSGVKRADGKRRATQQNKSHEEPKMSAQRIHENQYGPEFVMTHIYLLFPHILTTPIWVRLNLTRSRSYIKLKRLRFKGTVKIERVHADVAMDGLPPKIEGVFSLVIVVDRKPHLSPSGSLLTFDELFGARINSHGNLAIASSFKDRFYIRHVLKRVLSVEKDSTMVDLEGSTSLSNRRYNCWASFKDLDHDSCKGVYDNISKNALLIYYCWMSDVTSKASTFVSFDLDYVG |
| NCBI Accession | YP_006462.1 |
|---|---|
| Location | 1211-2092 |
| Gene Name | mp |
| Protein Name | MP |
| Coding Region | ATGGAGTCTCAGCTAGTTAATCCTCCGAGTGCTTTTAATTACATAGAGTCTCATAGAGATGAATACCAGTTATCTCATGACCTAACAGAGATTATTCTGCAGTTTCCTTCCACTGCTGCACAATTAACAGCAAGACTCAGTCGTAGCTGTATGAAGATAGACCACTGTGTCATAGAATACAGGCAACAGGTTCCGATTAACGCAACAGGGACTGTAATTGTGGAGATACATGATAAGAGAATGACAGACAATGAATCATTACAGGCGTCCTGGACATTCCCTATACGTTGTAACATAGATCTCCATTACTTCTCATCTTCCTTCTTCTCTCTTAAGGATCCTATACCATGGAAGTTATACTACAGAGTGTGTGACTCAAATGTTCATCAAAGAACACACTTTGCCAAATTCAAAGGCAAGCTCAAGATCTCAACAGCTAAACACTCTGTAGACATCCCATTCCGTGCACCAACAGTGAAGATTCATTCCAAACAATTCACAGAGAATGATGTTGATTTCTCACACGTGGACTACGGGAAATGGGATAGGAAACTCATAAGATCCACAACAATGTCAAGGGTTGGGTTAAAGACTCCACTGGAATTAAGACCAGGAGAATCATGGGCATCAAGAAGTACCATAGGAATGGGTCATACAGACACAGACTCTGAACTGGAGAACGCAATACACCCATACAGACATCTAAACAGACTGGGGTCCTGCACATTAGACCCTGGAGAGTCAGCTTCAGTGATAGGGGAACAAAGGGCTCAATCAAACATCACCATGTCAATGAACCAGCTTAACGAACTTGTTAAGGCAACAGTCCATGAATGTATTAACAATAATTGTAACCCAACACCACCAAAGTCATTGAAATAA |
| Protein Sequence | MESQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDSNVHQRTHFAKFKGKLKISTAKHSVDIPFRAPTVKIHSKQFTENDVDFSHVDYGKWDRKLIRSTTMSRVGLKTPLELRPGESWASRSTIGMGHTDTDSELENAIHPYRHLNRLGSCTLDPGESASVIGEQRAQSNITMSMNQLNELVKATVHECINNNCNPTPPKSLK |
References More References in PubMed
| 1 |
First Report of Tomato yellow leaf curl virus Infecting Tomato, Tomatillo, and Peppers in Guatemala. Salati R, et al. Plant Dis. 2010 Apr;94(4):482. doi: 10.1094/PDIS-94-4-0482C. PMID: 30754504 |
|---|---|
| 2 |
A New Tomato yellow leaf curl virus Strain in Southern Spain. Morilla G, et al. Plant Dis. 2003 Aug;87(8):1004. doi: 10.1094/PDIS.2003.87.8.1004B. PMID: 30812778 |
| 3 |
First Report of Tomato yellow leaf curl virus in Hawaii. Melzer MJ, et al. Plant Dis. 2010 May;94(5):641. doi: 10.1094/PDIS-94-5-0641B. PMID: 30754444 |
| 4 |
First Report of Tomato yellow leaf curl virus in Tomato in Mauritius. Lobin K, et al. Plant Dis. 2010 Oct;94(10):1261. doi: 10.1094/PDIS-01-10-0030. PMID: 30743598 |
| 5 |
Tomato yellow leaf curl virus, the intracellular dynamics of a plant DNA virus. Gafni Y. Mol Plant Pathol. 2003 Jan 1;4(1):9-15. doi: 10.1046/j.1364-3703.2003.00147.x. PMID: 20569358 |
| 6 |
First Report of Tomato yellow leaf curl virus in Tomato in the Netherlands. Botermans M, et al. Plant Dis. 2009 Oct;93(10):1073. doi: 10.1094/PDIS-93-10-1073C. PMID: 30754363 |
| 7 |
Navas-Castillo J, et al. Plant Dis. 1997 Dec;81(12):1461. doi: 10.1094/PDIS.1997.81.12.1461B. PMID: 30861805 |
| 8 |
First Report of Tomato Yellow Leaf Curl Virus in Tomato in South Georgia. Momol MT, et al. Plant Dis. 1999 May;83(5):487. doi: 10.1094/PDIS.1999.83.5.487C. PMID: 30845549 |
| 9 |
Nava A, et al. Arch Virol. 2013 Feb;158(2):399-406. doi: 10.1007/s00705-012-1501-x. Epub 2012 Oct 14. PMID: 23064695 |
| 10 |
First Report of Tomato Yellow Leaf Curl Virus in Reunion Island. Peterschmitt M, et al. Plant Dis. 1999 Mar;83(3):303. doi: 10.1094/PDIS.1999.83.3.303B. PMID: 30845523 |